
 起点课堂会员权益
起点课堂会员权益RAG 平台 V2:切换智普大模型、补全企业级能力,一次真实升级的全过程
从原型到生产级,RAG系统升级背后的技术抉择与实战陷阱。当国产大模型GLM-4.5-Air替代通义千问,2048维向量替代1024维,开发者需要直面的不仅是性能提升——SDK兼容性陷阱、企业级能力补全、零向量静默失败等5大典型坑位正等待填平。本文将揭秘从裸API到全功能平台的完整升级路径,特别聚焦Embedding模型切换时那些比报错更危险的「正常假象」。
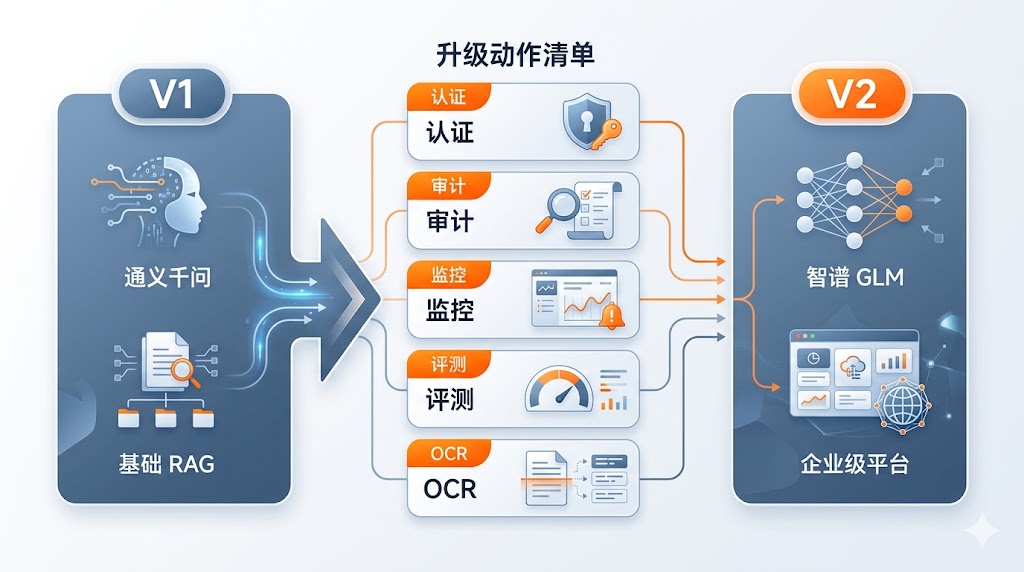
上一篇文章记录了用 Claude Code + 通义千问从零搭建生产级 RAG 的全过程(14 个 Bug、约 100 元 API 成本)。这次我们把那个「能跑但差口气」的系统做了一次完整升级:把推理模型从通义切换到智谱 GLM-4.5-Air、把向量模型从 1024 维升到 2048 维、绕过 LangChain SDK 的零向量 Bug 直接调用 API、补上了 JWT 认证、审计日志、Prometheus 监控、端到端评测管道、用户反馈系统和 GLM-OCR 图片解析。本文重点讲述:切换国产大模型时 Embedding SDK 的兼容性陷阱、从裸 API 到企业级平台需要补哪些能力模块、以及升级过程中遇到的 5 个典型坑。
一、背景:V1 跑通了,但离「能上线」还差什么
上一篇文章结束时,RAG 平台已经可以:
- 上传文档 → 解析 → 分块 → 向量嵌入 → Milvus 索引
- 通过对话界面提问 → LangGraph 十节点管道 → SSE 流式回答 + 引用来源
- 在评估面板上查看命中率、MRR 等指标
- 但拿到企业客户面前,对方会问五个问题:
- 谁在用? 没有 login,任何人访问后端端口就能操作所有 API
- 谁做了什么? 没有操作日志,出了问题无法追溯
- 系统健康吗? 没有 metrics,不知道延迟多少、错误率多少
- 回答到底靠不靠谱? 评估面板是空壳,指标数据是假的
- 用户觉得好不好? 没有反馈收集,无法量化模型表现
与此同时,V1 使用通义千问时遇到的 LangChain OpenAIEmbeddings 兼容性问题(baseUrl vs configuration.baseURL)虽然绕过了,但 SDK 对非 OpenAI API 的兼容性始终是个隐患。
二、升级全景:从「能跑」到「能用」变了什么
V1(能跑) V2(能用)
┌──────────────────────┐ ┌──────────────────────┐
│ 通义 qwen3.6-plus │ ──切换──→ │ 智谱 GLM-4.5-Air │
│ text-embedding-v3 │ │ embedding-3 (2048维) │
│ (1024维) │ │ │
├──────────────────────┤ ├──────────────────────┤
│ 无认证 │ ──新增──→ │ JWT + 角色控制 │
│ 无审计 │ │ 完整审计日志 │
│ console.log │ │ Prometheus 指标 │
│ 无用户反馈 │ │ 用户反馈系统 │
├──────────────────────┤ ├──────────────────────┤
│ 评测面板(空壳) │ ──实现──→ │ 端到端评测管道 │
│ │ │ 6 项指标 + A/B 测试 │
├──────────────────────┤ ├──────────────────────┤
│ LangChain Embeddings │ ──重写──→ │ 原生 fetch 调 API │
│ (兼容性不可控) │ │ (绕过 SDK) │
├──────────────────────┤ ├──────────────────────┤
│ 5 种文档解析器 │ ──新增──→ │ + GLM-OCR 图片解析 │
│ │ │ (保留表格/公式/版式) │
├──────────────────────┤ ├──────────────────────┤
│ 前端四面板 │ ──扩展──→ │ + 登录/注册 │
│ │ │ + 管理员审计日志 │
│ │ │ + 实时监控面板 │
└──────────────────────┘ └──────────────────────┘
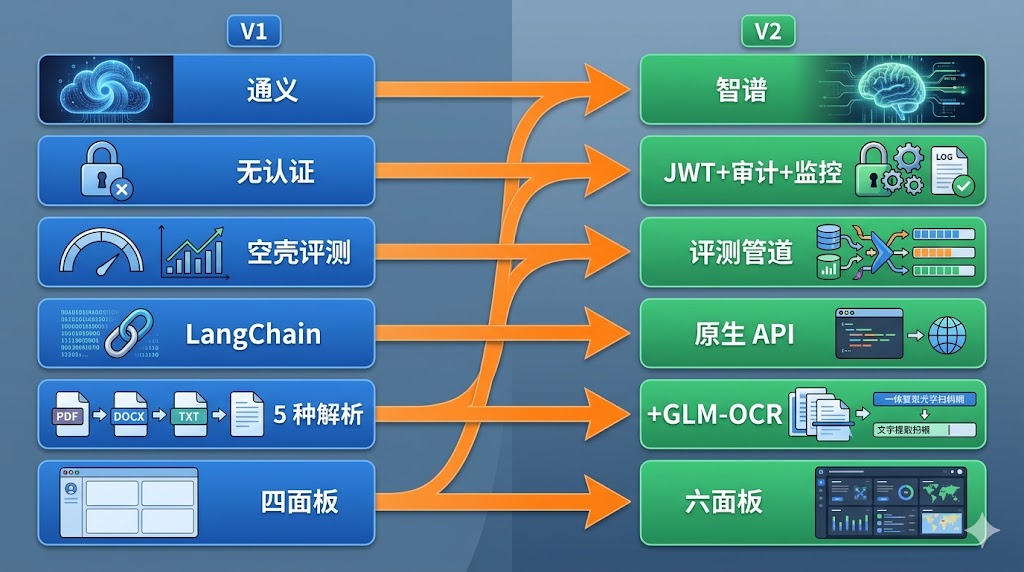
三、模型切换:Embedding 零向量——比 V1 更隐蔽的静默失败
3.1 切换原因
从通义切换到智谱 AI 的考虑:
- GLM-OCR 能力:智谱提供布局解析 API,输出保留表格、公式、版式的 Markdown——对文档解析场景价值显著
- 统一账号管理:LLM + Embedding + OCR 走同一个智谱账户
- Embedding 兼容性:V1 时 OpenAIEmbeddings 对通义 API 的 baseUrl 处理已有问题,切换后这个问题更严重了
3.2 零向量 Bug:最危险的静默失败
这是本次升级中耗时最长、隐蔽性最高的问题。
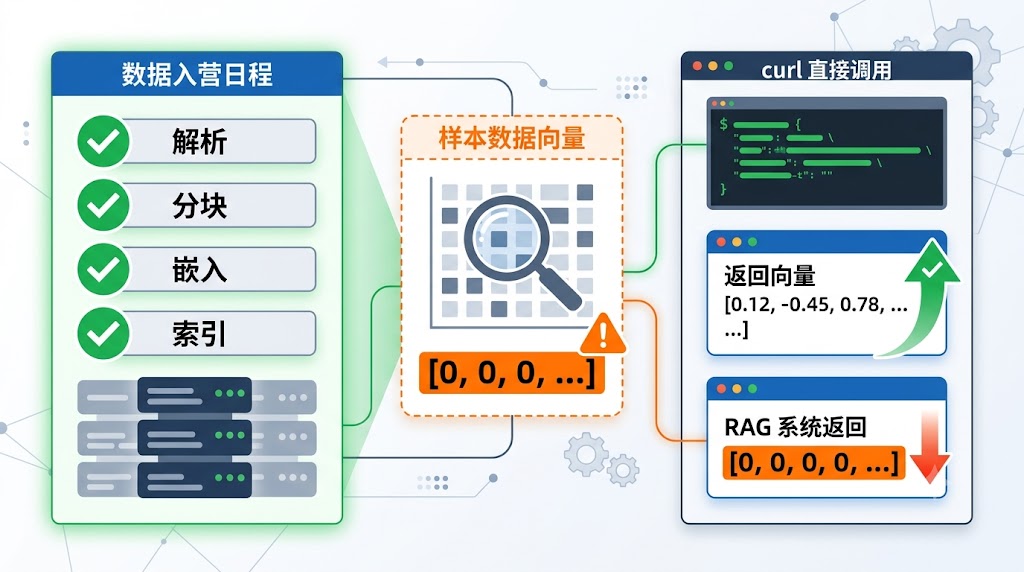
切换到智谱后,文档入库链路表面一切正常:
- 解析成功 → 5868 characters ✓
- 分块成功 → 8 chunks ✓
- 嵌入成功 → “Generated 8 embeddings” ✓
- 索引成功 → “Indexed 8 chunks in Milvus” ✓
但对话检索永远返回 0 条结果。
排查过程:
第一步——确认 Milvus 有数据(和 V1 一样的套路):
# Milvus count 查询
node -e “…” # 输出: count = 8 ✓
第二步——采样向量(这一步发现了问题):
# 查看实际存储的向量
node -e “… sample dense_vector …”
# 输出: [0, 0, 0, 0, 0, …] ✗ 全零!
第三步——对比验证:
# LangChain SDK 调用 → 零向量
node -e “new OpenAIEmbeddings({…}).embedDocuments([‘test’])”
# 输出: [[0, 0, 0, …]]
# curl 直接调智谱 API → 正常 2048 维向量
curl -X POST https://open.bigmodel.cn/api/paas/v4/embeddings \
-H “Authorization: Bearer sk-…” \
-d ‘{“model”:”embedding-3″,”input”:[“test”]}’
# 输出: [[0.0123, -0.0456, …]] ✓
根因:LangChain OpenAIEmbeddings 内部对非 OpenAI API 的响应格式解析有 Bug——API 返回了正确向量,但 SDK 将其丢弃后填充了零值。没有报错,没有警告,只是静默地把所有向量变成零。
这比 V1 的 baseUrl 问题更危险:V1 至少会超时或返回 0 条结果,而零向量是「入库成功、索引成功、检索不报错但永远不匹配」。
3.3 解决方案:绕过 LangChain SDK
// 完全绕过 LangChain,直接用 fetch 调用智谱 API
export async function callEmbeddingAPI(
input: string[],
apiKey: string,
baseURL: string,
model: string,
): Promise<number[][]> {
const res = await fetch(`${baseURL}/embeddings`, {
method: ‘POST’,
headers: {
‘Authorization’: `Bearer ${apiKey}`,
‘Content-Type’: ‘application/json’,
},
body: JSON.stringify({ model, input }),
});
const data = await res.json();
return data.data
.sort((a, b) => a.index
– b.index)
.map(d => d.embedding);
}
这个函数不依赖任何第三方 SDK,只用了 Node.js 内置的 fetch。封装为 OpenAIEmbeddingProvider 类后,提供单批嵌入(embed)、分批嵌入(embedMany,每批 50 条)和单条查询嵌入(embedQuery)三种调用方式。
3.4 向量维度 1024 → 2048
智谱 embedding-3 输出 2048 维(通义 text-embedding-v3 是 1024 维),Milvus 集合需要重建:
#
1. 删除旧集合(维度不可修改)
node -e ”
const client = new MilvusClient({ address: ‘localhost:19530’ });
await client.dropCollection({ collection_name: ‘rag_chunks’ });
”
#
2. 修改 .env: EMBEDDING_DIMENSION=2048
#
3. 重启后端 → 自动重建集合
#
4. 重新上传文档
教训:维度变更 = 全量重建。生产环境应在设计阶段考虑「维度可变」策略(如版本化集合名),或在切换模型前评估重建成本。
业务验证点
切换 Embedding 模型时必须三步验证:① curl 直接调 API 确认向量非零 ② 确认维度匹配 ③ Milvus 重建集合后重新入库。缺任何一步都可能踩静默失败的坑。
四、认证与审计:补上企业级的第一道门
4.1 JWT 认证流程
注册/登录 → 签发 Access Token (15分钟) + Refresh Token (7天)
↓
每次请求携带 Access Token → 中间件验证 → 设置 request.user
↓
Token 过期 → 前端自动用 Refresh Token 刷新 → 获取新 Access Token
↓
角色检查:普通用户只能操作自己的数据,管理员可查看全部
实现要点:
- 后端:bcryptjs 密码哈希 + jsonwebtoken 签发验证
- 中间件:requireAuth(验证 Bearer Token)+ requireRole(角色检查)
- 前端:authStore.ts 管理 Token 生命周期 + api/client.ts 拦截器自动注入和刷新
- 多租户隔离:documents、chunks、eval_results 等表都添加了 user_id 字段,API 层通过 request.user.id 过滤。
4.2 审计日志
通过 Fastify onResponse 钩子自动记录所有 API 请求——开发者不需要在每个路由手动写日志。
// 自动记录,不影响业务逻辑
app.addHook(‘onResponse’, async (request, reply) => {
// 记录:用户、操作、资源、IP、耗时、状态码
await auditService.log({ userId, action, resource, ip, duration, statusCode });
});
踩了一个坑:审计中间件会记录「写入审计日志」的请求,形成循环写入。解决方式是排除审计和健康检查路由。
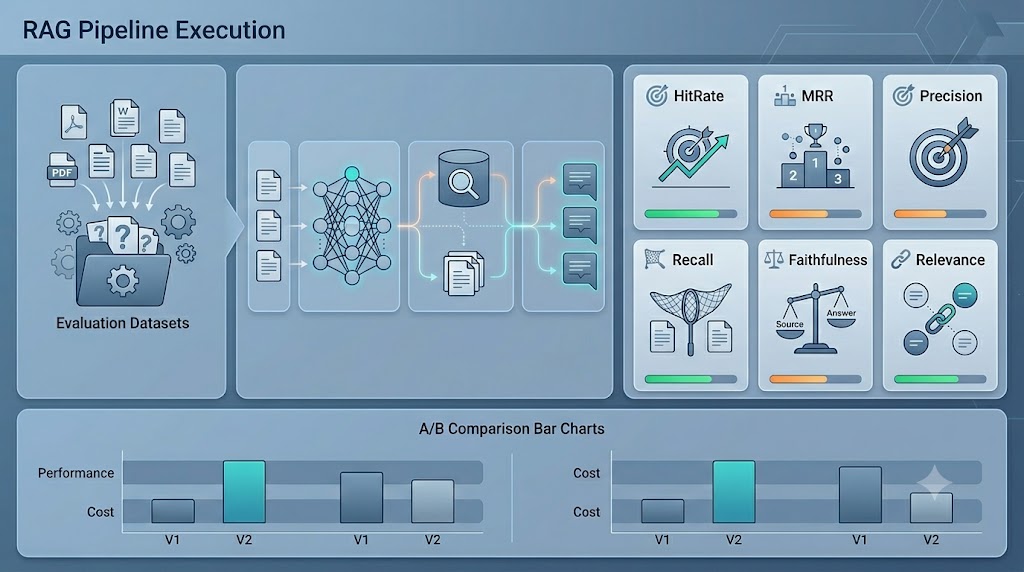
五、端到端评测管道:从「感觉能答」到「数据说话」
V1 的评估面板是个空壳——UI 有了,但指标数据是假的。V2 补上了完整的评测管道。
5.1 评测指标体系
检索指标(不需要 LLM,基于文档 ID 匹配):
HitRate@K
含义:检索结果是否包含正确文档
计算方式:有 = 1,无 = 0
MRR
含义:正确文档的排名倒数
计算方式:1 / (排名位置)
生成指标(需要 LLM 评估,调用 GLM-4.5-Air 打分):
Context Precision
含义:检索到的上下文是否包含关键信息
LLM 评估提示:”评估上下文是否包含回答问题所需的关键信息”
Faithfulness
含义:答案中的论断是否都有上下文支持
LLM 评估提示:”评估答案中的每个论断是否都能被上下文支持”
Answer Relevance
含义:答案是否直接回答了问题
LLM 评估提示:”评估答案是否直接、完整地回答了问题”
Context Recall
含义:上下文是否覆盖了标准答案的关键信息
LLM 评估提示:”评估上下文是否覆盖了标准答案中的所有关键信息”
每个指标返回 0.0–1.0 的分数 + 评估理由。
5.2 A/B 测试
同一评测数据集,分别用两组不同配置运行,对比指标差异:
const { metricsA, metricsB } = await evaluationService.abTest(
dataset,
{ topK: 5, chunkSize: 512, chunkingStrategy: ‘recursive’ },
{ topK: 10, chunkSize: 1000, chunkingStrategy: ‘markdown’ },
);
这解决了「改了参数不知道效果变好还是变差」的痛点。
六、Prometheus 监控:实时知道系统在干什么
6.1 自动采集的指标
- http_requests_total(Counter):请求总数
- http_request_duration_seconds(Histogram):请求延迟分布
- http_errors_total(Counter):错误请求数
- cache_hits_total / cache_misses_total(Counter):缓存命中/未命中
- process_uptime_seconds(Gauge):进程运行时间
暴露 GET /metrics 端点返回 Prometheus 文本格式,前端监控面板每 10 秒刷新。
6.2 前端监控面板
管理员可以看到:
- 总请求数、错误率(颜色编码:绿 < 1%,黄 1-5%,红 > 5%)
- 缓存命中率
- 系统运行时间
- 请求路径分布
业务验证点
V1 的「可观测性」全靠 console.log,出了问题只能去翻临时文件。V2 补上 Prometheus 指标后,系统运行状态可量化、可告警。
七、GLM-OCR:让 RAG 能「看懂」图片和扫描件
V1 支持 5 种文本格式(PDF、DOCX、Excel、HTML、Markdown),但遇到扫描件 PDF 或图片就无能为力。
V2 接入智谱 GLM-OCR 布局解析 API:
- 输入:图片(JPEG/PNG/BMP/TIFF/WebP,≤ 10MB)或扫描件 PDF(≤ 50MB,最大 100 页)
- 输出:保留表格、公式、版式的 Markdown 文本
- 多页 PDF:逐页渲染为 PNG → 逐页调用 GLM-OCR → 合并为带页码标记的 Markdown

八、前端企业级改造:从四面板到六面板
8.1 新增的三个面板
- 登录/注册(公开):登录注册合一界面,密码可见切换
- 监控面板(管理员):实时请求/错误/缓存指标,10 秒刷新
- 审计日志(管理员):操作记录时间线,按类型过滤
8.2 配置面板增强
V2 的配置面板支持更精细的调参:
检索策略(4 种):standard / adaptive / corrective / multi-hop
分块策略(4 种):recursive / markdown / semantic / hierarchical
LLM 模型可选(智谱系列):GLM-4.5-Air / GLM-4-Plus / GLM-4-Flash
8.3 权限与导航
┌─ 侧边栏 ──────────────────────────────────┐
│ [对话] → 多会话 · SSE 流式 · 引用面板 │
│ [文档] → 统计卡片 · 拖拽上传 · 双视图 │
│ [评测] → 真实指标 · 7 天趋势 · A/B 测试 │
│ [配置] → 三 Tab · 4 种检索/分块策略 │
│ ─── 管理员 ─── │
│ [监控] → 实时指标(10 秒刷新) │
│ [审计] → 操作日志 · 类型过滤 │
├────────────────────────────────────────────┤
│ 用户状态 · Admin 徽章 · 退出 │
└────────────────────────────────────────────┘
- 未登录 → 显示登录页
- 普通用户 → 隐藏管理员菜单项
- 管理员 → 显示全部菜单
九、升级过程中的 5 个典型坑
坑 1:LangChain OpenAIEmbeddings 返回零向量
表现:入库全绿,检索 0 条,采样发现向量全零。 根因:SDK 对非 OpenAI API 响应格式的解析 Bug。 解决:绕过 SDK,用原生 fetch 直接调 API。 教训:非 OpenAI 兼容 API 不要信任 LangChain 封装,先 curl 验证。
坑 2:向量维度变更后 Milvus 集合不兼容
表现:改了维度配置后插入报错。 根因:Milvus 集合一旦创建,维度不可修改。 解决:删集合 → 改配置 → 重启 → 重新入库。 教训:切换 Embedding 模型 = 全量重建,提前评估成本。
坑 3:JWT 密钥长度不足
表现:jsonwebtoken.sign() 报错 “secret must be at least 16 characters”。 解决:Zod schema 加 .min(16) 校验,.env.example 中写明要求。 教训:配置校验要在启动时完成,不要等到运行时才报错。
坑 4:审计日志自我审计(循环写入)
表现:审计表疯狂增长,每秒写入数条。 根因:审计中间件在记录「写入审计日志」的请求。 解决:排除审计和健康检查路由。 教训:任何「全量记录」的中间件都必须排除自身。
坑 5:前端 Token 刷新竞态
表现:多个并发请求同时 401,各自刷新 Token,第二个刷新因旧 Token 失效而报错。 解决:前端刷新逻辑加锁——只发一次刷新请求,其他请求排队等待。 教训:Token 刷新是经典的并发问题,必须在客户端实现串行化。
十、升级前后对照
推理模型
V1:通义 qwen3.6-plus
V2:智谱 GLM-4.5-Air
向量模型
V1:text-embedding-v3 (1024维)
V2:embedding-3 (2048维)
Embedding 客户端
V1:LangChain SDK(兼容性差)
V2:原生 fetch(可控)
认证
V1:无
V2:JWT + 角色控制
审计
V1:无
V2:自动审计日志
监控
V1:console.log
V2:Prometheus 指标
评测
V1:空壳面板
V2:端到端管道 + A/B 测试
用户反馈
V1:无
V2:赞/踩 + 评论 + 配置快照
文档解析
V1:5 种文本格式
V2:+ GLM-OCR 图片/扫描件
多租户
V1:无
V2:user_id 隔离
前端面板
V1:4 个
V2:6 个(+ 监控 + 审计)
Bug 数量
V1:14 个(V1 阶段)
V2:5 个(V2 升级阶段)
升级耗时最长的 Bug
V1:向量维度不匹配
V2:Embedding 零向量
十一、给正在做 RAG 平台升级的团队的建议
先验证 Embedding,再写代码
切换向量模型之前,先用 curl 或原生 fetch 测试 API 返回的向量是否正常。不要信任任何 SDK 封装——LangChain 对非 OpenAI API 的兼容性不可控,V1 的 baseUrl 问题和 V2 的零向量问题都是 SDK 层面的 Bug。
维度变更 = 全量重建
Milvus 不允许修改已存在集合的向量维度。切换 Embedding 模型前必须评估「重建集合 + 重新入库」的成本。生产环境可以考虑版本化集合名(如 rag_chunks_v1、rag_chunks_v2)来做无缝切换。
评测先于上线
V1 的教训是「没有评测就无法证明效果」。V2 补全评测管道后,每次调参都有了数据依据,不用再凭感觉说「好像好了一点」。
审计日志要防循环
任何「全量记录」的中间件都必须排除自身路由,否则会自我审计导致写入爆炸。这是一个很容易忽略但后果很严重的问题。
Token 刷新加锁
前端并发请求遇到 401 时,只发起一次刷新请求,其他请求排队等待。这是 JWT 认证的经典并发问题。
十二、结语
如果说 V1 证明了「Claude Code 写规格 + 国内大模型做推理」这条路走得通(约 100 元 API 成本、14 个 Bug),那 V2 证明了另一件事:从能跑的原型到能用的平台,差的是认证、审计、监控、评测和反馈这五个模块。
这些模块的代码量并不大(认证 + 审计 + 监控 + 评测 + 反馈合计约 1500 行),但它们解决的是「敢不敢上线」的问题:
- 没有认证 → 不敢部署到公网
- 没有审计 → 不敢说「谁做了什么」
- 没有监控 → 不敢说「系统现在正常」
- 没有评测 → 不敢说「回答靠谱」
- 没有反馈 → 不敢说「用户满意」
另一个重要收获是:切换国产大模型时,Embedding SDK 兼容性是最容易踩坑的环节。零向量比报错更危险——它让系统看起来一切正常,但检索永远不匹配。解决方式很朴素:绕过 SDK,直接用 fetch 调 API。
两篇文章加起来,从零到企业级 RAG 平台的完整路径就是:先有方案文档 → 生成代码 → 逐模块调试(14 个 Bug)→ 切换模型(5 个坑)→ 补全企业级能力(认证/审计/监控/评测/反馈)。希望这些实操记录能帮到正在走类似路线的团队。
本文由 @天涯轩 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自AI生成,由作者提供









零向量这个坑太真实了,静默失败比报错难搞一万倍。
国产模型生态正在补企业级缺口,但SDK的兼容性和文档的完整性仍然是硬伤。未来半年,原声API调用会比框架封装更受后端团队偏爱。
如果是一个客服场景的RAG,用户反复问同样的问题,缓存命中率会很高,但审计日志里看到的是重复操作,反而可能暴露知识库覆盖不足的问题。
建议在评估数据集里加入一些边界case,比如空文档、纯图片、超长文本,不然评测管道可能只覆盖了happy path。
零向量那个坑确实隐蔽,但LangChain的兼容性问题在V1就已经暴露了,V2才彻底绕开,实际代价是前期信任了SDK的“正常”假象。早该在V1就检查向量非零的。