
 起点课堂会员权益
起点课堂会员权益DSL是什么,为什么在AI时代很重要
AI生成的问题从来不是"生成不了",而是"生成了但不可控"。根源在于自然语言作为约束介质的根本缺陷——模糊性。DSL不是新系统,是维度拆解工作的结构化表达,它让分析层的数据洞察能自动注入生成层,飞轮才能真正闭合。

AI生成的问题从来不是“生成不了”,而是“生成了但不可控”。你告诉AI”写一段有冲突感的开场”,它确实写了一段——但那个冲突是你的冲突还是它理解的冲突?拐点在哪?强度多大?转换速度多快?全是黑箱。你以为你在驾驭AI,实质上你在掷骰子。
这个问题的根源不在于模型能力不够,而在于你用来约束AI的介质是自然语言。自然语言是人类之间妥协的产物,它的设计目标是被”大致理解”,而不是被”精确执行”。当你用自然语言写prompt时,你传递的是一个模糊意图,而不是一个可执行的规格说明。AI填补模糊空间的方式是概率采样——它从训练分布里采样一个”看起来符合描述”的结果,但这个结果是否落在你真正想要的那个区间内,没有任何机制保证。
这就产生了一个断裂:你的分析层已经知道最优解长什么样,但你的生成层根本无法执行这个最优解。你通过数据分析发现”某种特征组合会产生最优结果”,你把这个发现写成一段prompt描述交给AI,AI自由发挥,要素遗漏、比例失调、节奏偏移——所有分析洞察在生成环节蒸发殆尽。
你需要的是一张图纸,不是一段描述。这张图纸就是DSL。
一、为什么AI生成不可控:自然语言作为约束介质的根本缺陷
先回到第一性原理。
AI生成模型的本质是什么?是一个条件概率分布。给定输入x,输出y服从P(y|x)。你写的prompt就是那个x。问题是,当x是自然语言时,这个条件约束太”软”了。
你写”开场要有冲突”。这句话在自然语言里的语义是清楚的——人类听到这句话,会调动大量共享语境来理解:什么类型的冲突?冲突的呈现方式是什么?冲突强度大概在什么量级?这些信息不在”开场要有冲突”这五个字里,在人类共享的文化语境和经验常识里。但AI没有这些共享语境。它有的只是训练数据中的统计共现模式。”冲突”这个词在训练数据里和什么共现?可能是打架、争吵、意外事件、心理挣扎——一个巨大的语义空间。AI从中采样一个,你怎么保证它采的是你想要的那个?
自然语言约束的缺陷不是“不够详细”,而是“无法被精确执行”。你可以写更详细的prompt——”开场30秒内要出现一个意外事件,让主角陷入困境,情绪从平静转为震惊,震惊强度7/10″——但这本质上是在用自然语言模拟结构化描述,就像用嘴巴描述一张工程图纸。木匠能听懂大致意思,但他手上拿的仍然是自己脑补的图纸,不是你脑中的那张。
更深一层:即使AI恰好生成了你想要的内容,你也不知道怎么复现。因为自然语言prompt到生成结果之间的映射是黑箱——你改了一个词,输出可能完全变化;你不改任何词,输出也可能因为采样随机性而完全不同。没有复现性就没有迭代,没有迭代就没有优化。
这就是AI生成不可控的根本原因:
自然语言是模糊约束,不是精确规格
AI填补模糊空间的方式是概率采样,不是确定执行
prompt到结果之间的映射是黑箱,不可复现、不可迭代
你可能会想:那我把prompt写得足够详细不就行了?不行。因为详细程度和可控性之间不是线性关系。自然语言的详细化有一个天花板——当你试图用自然语言描述所有约束时,prompt本身变得比内容还长,而且约束之间会互相冲突、互相稀释。你不能用模糊的介质构建精确的系统,这是介质层面的限制,不是技巧层面的限制。
所以问题的解法不是”写更好的prompt”,而是换一个约束介质。从自然语言切换到结构化约束。
二、DSL的本质:不是新系统,是维度拆解工作的结构化表达
DSL,Domain-Specific Language,领域特定语言。这个词在软件工程领域已经存在几十年了。但在这里,我说的不是传统意义上的编程语言。我说的是一种更朴素的东西:把你对“好内容”的理解,拆解成一组可量化、可约束、可迭代的参数,然后用结构化格式(JSON、YAML、甚至Excel表格)表达出来。
实质上,DSL不是你新建的一套系统。它是你已经做过的工作的结构化表达。
什么工作?维度拆解。任何做过内容分析的人都在做这件事:你拿一批好的结果和一批差的结果做对比,发现好结果有一些共同特征——开场有钩子、情绪有曲线、结尾有留存设计。你把这些特征列出来,每个特征给一个取值范围,这就是一张维度拆解表。
维度拆解表就是DSL v0。
你以为DSL是一套需要从零搭建的技术系统?不,DSL是你已经脑子里有的那张表的格式化版本。区别在于:你脑子里的表是隐性的、口头的、每次写prompt时手动翻译的;DSL是显性的、结构化的、可以被程序读取和自动填充的。
举个抽象层面的例子。假设你通过数据分析发现,优质内容在结构上有以下特征:
- 开场阶段:在前N秒内出现一个注意力锚点,强度参数α
- 发展阶段:情绪曲线呈现“上升-转折-下降”模式,转折点位置参数β
- 收尾阶段:留存钩子强度参数γ,类型参数δ
如果这些参数只存在于你的脑子里,每次生成时你用自然语言把它们翻译成prompt描述,那么:
- 翻译过程有信息损失
- 每次翻译不一致
- 翻译结果无法被程序读取
- 数据分析的结果无法自动回流到这些参数上
把这张表写成结构化格式:
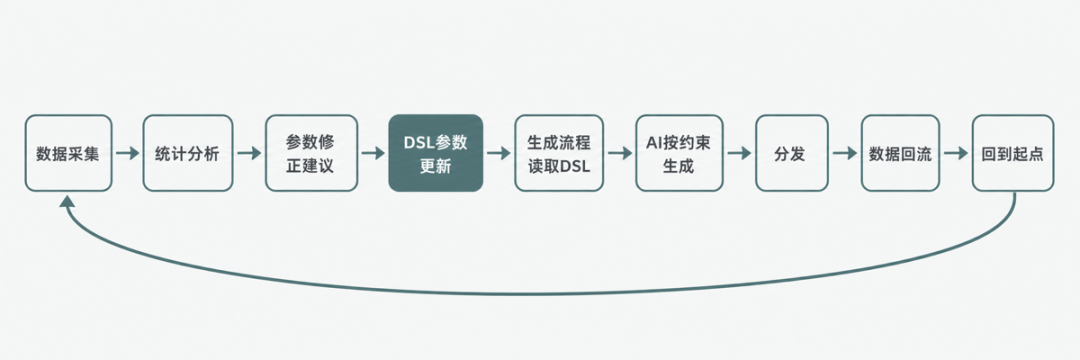
没有DSL时,这个循环中“参数修正建议→生成流程”这一步是断的,需要人手动搬运。有了DSL,这一步是自动的,飞轮可以自己转。
再强调一个关键点:飞轮靠数据结构对齐驱动,不靠技术栈复杂度驱动。你的AI模型可能很强,你的数据分析可能很深,但如果两者之间的数据结构不对齐——分析层输出的参数和生成层接收的约束不是同一种格式——飞轮就转不起来。DSL做的事情就是数据结构对齐:让分析层的输出格式和生成层的输入格式统一。
这个洞察很重要,因为它意味着:你不一定需要更好的模型或更深的分析,你可能只需要一个对齐层。很多团队的飞轮转不起来,不是因为分析不够深或生成不够好,而是因为两者之间没有对齐机制。他们花大量精力优化分析算法和生成模型,却忽略了连接两者的管道。DSL就是这个管道。
五、数据量与参数收敛:飞轮加速的内在逻辑
飞轮不是匀速转的。它有加速过程,加速的驱动力是数据量。
数据量有三个阶段,每个阶段参数收敛的精度不同:
阶段一:小数据量,粗规律。数据少,只能发现粗粒度规律——”有开场钩子的比没有的好””情绪有波动的比平铺直叙的好”。这些规律对应的是不可变维度的确认:骨架结构是否正确。在这个阶段,可变维度的参数取值范围很宽,因为你没有足够的数据来判断0.7和0.8哪个更好。你只能确认”这个维度重要”,但不知道最优取值。
阶段二:中数据量,多维度交叉。数据积累到一定程度,可以做多维度交叉分析了——不只是”开场钩子有没有用”,而是”开场强度0.8配合冲突类型X时效果最好,但配合冲突类型Y时反而下降”。这个阶段,可变维度开始收敛——某些参数组合表现出统计显著性,取值范围从”0.5-0.9全范围”收敛到”0.7-0.8窄区间”。飞轮开始加速,因为每一轮修正都在缩小搜索空间。
阶段三:大数据量,精准公式。数据足够大时,参数收敛到接近最优的取值。飞轮的修正幅度越来越小——不是不修正,而是修正的增量越来越小,参数在最优值附近微调。这时候飞轮的”转速”最快,因为每一轮循环产生的数据都能被高精度地映射到参数修正上。
数据量决定参数收敛精度,参数收敛精度决定飞轮转速。这就是为什么飞轮需要时间——不是因为技术不成熟,而是因为参数收敛需要数据积累。你能做的不是跳过这个过程,而是让这个过程尽可能自动化、无摩擦。DSL的作用就是减少摩擦:让每一轮数据采集的结果都能无损地传递到参数修正环节,让每一次参数修正都能无损地传递到生成环节。
没有DSL时,每一轮循环都有人工翻译造成的信息损失,相当于飞轮每转一圈就漏气。有DSL时,每一轮循环都是无损的,飞轮越转越快。
六、渐进式落地:为什么不能一步到位
到这里,逻辑已经很清楚了:DSL是飞轮闭环的关键管道。那么问题来了:为什么不直接搭建完整的DSL系统?
因为DSL不是一个可以一次性设计完成的东西。它的参数体系需要通过数据验证来迭代,而数据验证需要生成和分发流程先跑起来。你不可能在没有验证过维度体系有效性的情况下直接上自动修正——万一你拆出来的维度根本不能区分好结果和坏结果呢?自动修正一个无效的维度体系,只会加速产出错误的结果。
所以DSL的落地必须是渐进式的,三个阶段,每个阶段验证一个核心假设:
阶段一:维度拆解表(DSL v0)
用Excel或表格描述每个维度的最优参数。人手动把参数写进生成prompt。
验证什么?验证维度体系是否有效。
这个阶段的核心问题是:你拆出来的维度,是否真的能区分好结果和坏结果?如果你按照维度拆解表的参数手动调prompt,生成的内容是否确实比不调的时候更好?
这个验证是必要的,因为维度拆解本身是一个假设——你假设这些维度是影响结果的关键因素。但假设需要验证。可能你拆出来的某些维度其实是噪声,对结果没有显著影响;也可能你遗漏了某些重要维度。在表格阶段,验证成本最低——改一个Excel单元格比改一段代码便宜得多。
阶段一的意义不是效率,是校准。你不是在追求自动化,你是在确认你的维度地图画对了。如果地图画错了,后面所有自动化都是在错误的方向上加速。
阶段二:DSL v1(结构化格式 + 生成管道打通)
表格变成结构化JSON/YAML,生成流程直接读DSL参数自动填充prompt。
验证什么?验证生成管道是否可靠。
这个阶段的核心问题是:当DSL参数自动注入生成流程时,AI是否按参数约束生成了内容?生成结果是否可复现?改一个参数,输出是否发生对应的可预测变化?
这是从”人手动调prompt”到”程序自动填充参数”的跨越。技术上不难——把参数从JSON读出来填进prompt模板而已。但这个跨越的意义在于:生成流程变成了参数驱动的,而不是人驱动的。改参数不需要人去理解和翻译,程序直接执行。
阶段二打通的是”DSL参数→生成”这一段管道。打通之后,你可以批量改参数、批量生成、批量对比——这是阶段三自动修正的前提。如果生成管道不通,分析层即使输出了修正建议,也无法自动执行。
阶段二的意义是管道打通,不是智能。你不是在追求自动修正,你是在确保”参数变了,生成结果会跟着变”这个基础机制是可靠的。
阶段三:DSL v2 + 自动修正
分析层输出直接改DSL参数,批量测试自动生成不同参数组合的变体,人只审核不手动调。
验证什么?验证飞轮是否能自动转。
这个阶段的核心问题是:分析层的输出是否能被正确映射到DSL参数修正上?修正后的参数组合是否确实产生了更优的结果?飞轮转一圈之后,结果是否比上一圈更好?
这是飞轮的完整闭环。分析层自动输出参数修正建议→DSL参数自动更新→生成流程自动读取新参数→批量生成变体→分发→采集数据→回流到分析层。人在循环中只做审核——检查修正方向是否合理,不做手动调参。
阶段三的验证是系统性的:不是验证单个环节,而是验证整个闭环的协同效果。飞轮是否在加速?参数是否在收敛?结果是否在改善?如果飞轮转了三圈参数没有收敛趋势,说明要么维度体系有问题(阶段一没校准好),要么生成管道有偏差(阶段二没打通好),要么分析层的修正逻辑有bug。
阶段三的意义是飞轮自动化。不是人在调参数让结果变好,是数据在调参数让结果变好。人从”操作者”变成”审核者”,这是质变。
为什么不能跳过阶段一和阶段二?
因为每个阶段验证的假设是下一个阶段的前提。
阶段一验证维度体系有效→阶段二的前提是”维度体系是对的,现在把它自动化”→阶段三的前提是”管道是通的,现在让飞轮自己转”。
跳过阶段一直接上DSL v1?你可能在一套错误的维度体系上搭建了自动化管道——自动生成错误结构的内容。
跳过阶段二直接上自动修正?你可能让飞轮在一个不通的管道上自动运转——分析层输出了修正建议,但生成流程无法可靠执行这些修正。
渐进式落地的本质是假设验证的顺序性:先验证维度对不对,再验证管道通不通,最后验证飞轮转不转。每一步都建立在前一步的验证结果上。这不是保守,这是工程严谨性。
七、关键判断:DSL的真正价值不是格式化,是让飞轮能自动转
说了这么多,最后要把核心判断讲清楚。
很多人理解DSL,停留在”把prompt格式化”这个层面。觉得DSL就是用JSON替代自然语言写prompt,好处是更规范、更清晰、可复用。
这个理解是对的,但只对了10%。
格式化是DSL的表层特征,不是核心价值。如果DSL只是让prompt更规范,那它的价值就是一个工程效率工具——省点时间、减少手写错误。这不足以解释为什么DSL在AI时代是重要的。
DSL的真正价值是:它让飞轮在分析层到生成层之间的断裂点消失,使数据洞察可以自动注入生成流程。
没有DSL时:分析层发现”参数组合A更优”→人看到这个发现→人把参数翻译成自然语言prompt→AI生成→结果可能偏离参数约束→数据回流→下一轮。每一轮都有人工翻译造成的信息损失和延迟,飞轮转得慢、漏气多。
有DSL时:分析层发现”参数组合A更优”→DSL参数自动更新→生成流程自动读取新参数→AI按约束生成→结果符合参数约束→数据回流→下一轮。全程无损、全自动,飞轮越转越快。
DSL不是在优化飞轮的某个环节,它是在连接飞轮的两个环节。它是分析层和生成层之间的数据对齐层、格式统一层、自动传输层。没有它,飞轮在分析层和生成层之间断裂——分析层的输出到不了生成层,生成层的输入不来自分析层,两个环节各自运转但无法协同。
这就是为什么DSL在AI时代特别重要。
在AI时代,内容生成的边际成本趋近于零。这意味着生成的瓶颈不再是”能不能生成”,而是”生成的对不对”——是否按最优参数生成,是否持续优化,是否让数据洞察驱动生成决策。
在AI时代,谁能把数据洞察自动注入生成流程,谁就拥有真正的飞轮。而实现这种自动注入的前提,就是分析和生成之间的数据结构对齐——就是DSL。
反过来说:没有DSL的AI生成系统,不管模型多强、分析多深,它的飞轮都是断的。分析层和生成层各自为战,数据洞察无法自动转化为生成约束,每一步优化都需要人介入。人介入意味着慢、意味着有损、意味着不可规模化。
有DSL的AI生成系统,飞轮可以自动转。数据驱动参数修正,参数驱动内容生成,生成产生新数据,新数据驱动下一轮修正。人从循环中退出,只做方向性审核。飞轮靠数据自己加速。
八、从更大的视角看:DSL是AI时代的”接口协议”
如果把视角拉得更高,DSL实际上是在定义一种接口协议——人类经验与AI生成之间的接口协议。
传统的软件系统中,接口协议定义了模块之间如何交换数据。HTTP定义了Web服务之间如何通信,SQL定义了应用和数据库之间如何交互。没有这些协议,每个模块都得自己发明通信方式,系统无法规模化。
在AI时代,人类经验和AI生成之间也需要一种接口协议。人类通过维度拆解积累的经验——什么结构好、什么参数优、什么组合有效——需要以一种AI可以精确执行的方式传递给生成流程。这个接口协议就是DSL。
自然语言不是接口协议,因为自然语言不可靠、不可复现、不可自动化。你不能把一个系统的关键数据通路建立在一个模糊介质上。就像你不能用”大概把数据传过去”来代替TCP协议。
DSL就是这个层面的东西:它是人类经验到AI生成的结构化传输协议。它保证了经验可以被精确传递、自动执行、持续修正。
一旦这个协议建立起来,整个系统的架构就变了:
- 分析层不再需要人去解读和翻译它的输出——输出直接是DSL参数修正
- 生成层不再需要人去手动调参——参数直接从DSL读取
- 人不再处于数据流的关键路径上——人退到审核位,数据流自动运转
这就是AI时代的内容工程化:不是让AI更聪明,而是让数据流更通畅。DSL是让数据流通畅的那个关键管道。
九、几个常见的认知误区
最后澄清几个常见的认知误区,它们都是理解DSL时的典型陷阱。
误区一:”DSL就是prompt模板”
不是。Prompt模板是静态的文本框架,有变量插槽。DSL是动态的参数体系,有约束逻辑、有取值范围、有修正机制。Prompt模板解决的是”prompt怎么写更快”,DSL解决的是”参数怎么从数据中来自动驱动生成”。前者是效率工具,后者是飞轮管道。
误区二:”DSL限制了AI的创造力”
恰恰相反。DSL限制的是AI的自由发挥空间,释放的是AI的精准执行能力。没有DSL时,AI在模糊约束下”自由发挥”,产出不可控、不可复现——这不是创造力,这是随机性。有DSL时,AI在精确约束下执行,每次生成都符合参数规格,可以对比、可以迭代、可以优化。真正的创造力来自迭代优化,不是来自一次性随机产出。
误区三:”等模型够强了就不需要DSL了”
不会。模型越强,越需要DSL。原因很简单:更强的模型在模糊约束下的”自由发挥”空间更大——它能生成更多样的结果,但其中符合你真实意图的比例不一定更高。就像一个更聪明的木匠,如果你只口头描述需求,他可能做出一个更精致但更不符合你需求的椅子——因为他有更多能力去”脑补”你没说出来的东西。模型越强,结构化约束的价值越大,因为强模型能更好地执行精确约束,而不是更好地猜测模糊意图。
误区四:”DSL太重了,小团队用不了”
DSL v0就是一张Excel表。你不需要任何技术基础设施就能开始——列出维度、填上参数值、手动把参数写进prompt。这不重,这就是你本来就在做的事情的结构化版本。重的是阶段三的自动修正系统,但那是后面的事。DSL的起点是一张表,不是一套系统。任何在做内容分析的人都已经有了那张表,只是没有把它格式化而已。
收束
DSL不是格式化工具,不是prompt模板,不是技术系统。
DSL是飞轮的传动轴——它让数据洞察的动能无损传递到生成流程,让飞轮从“人推着转”变成“自己转”。
在AI生成边际成本趋近于零的时代,竞争的壁垒不在生成能力——人人都能生成。壁垒在”谁的生成更受数据驱动”——谁的数据洞察能更快、更无损地注入生成流程,谁的飞轮就转得更快。
没有DSL,飞轮在分析和生成之间断裂;有了DSL,飞轮闭环。差别就这一步,但这一步决定了你是在手动驾驶AI,还是在让数据自动驾驶AI。
在AI时代,谁能把数据洞察自动注入生成流程,谁就拥有真正的飞轮。DSL就是那个”自动注入”的管道。
本文由 @冲量AI 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


