
 起点课堂会员权益
起点课堂会员权益风控之术:策略和模型
编辑导语:风控之本,是策略和模型。如今市场变化多端,策略和模型都是需要快速迭代不断调整的,本文作者讨论了策略和模型之间的联系。策略和模型该怎么做?作者对此进行了通俗易懂的描述,话不多说,跟着作者的思路走吧!

风控之术是什么呢?很多人都知道,策略规则和模型呗。其实这个问题很简单,风险管理部门就是在做策略和模型,自然这就是术。大数据风控怎么做,本质就是大数据怎么用的问题,两个用法。
简单地用,是策略规则;复杂地用,是模型。
一、策略和模型的关系
简单规则是策略,模型规则其实也是策略。这里我们按照惯例,把模型组和策略组的工作分开来。
1. 模型重,策略轻
实际上,初进入一个领域,是不需要建模型的。政策和运营就可以进行冷启动了,做什么客群,怎么去触达,设置什么额度和息费,这些问题一开始跟模型都没关系。
另外,有些时候也来不及做模型,策略可能就会使用一些变量来做强规则或者软规则。那么,后续做模型变量筛选时,就要考虑到策略因素的影响,尽量不使用同类变量,避免策略调整对模型稳定性产生强干扰。
有时你会发现,策略往往选用区分度强的变量,而其他变量不足以让模型有一个好的表现。策略用变量毕竟只用极端,通常是这样,为了追求更好的效果,模型往往还是会什么都用。
因此,如何协调和改善模型策略构建流程,是我们需要思考的业务问题,同时也是技术问题。
一般来说,金融机构会先制定准入规则,可以是基于经验的规则,也可以是基于数据的可变规则。经验规则很少调整,可变规则则需要定期分析动态调整。
通过分析各类数据源的变量对风险的排序性,挑出其中 IV 值高风险区分性好的,设置合适的阈值作为准入标准。或者通过组合多个变量,采用决策树进行最优组合的查找,可得到多变量组合规则。这些都是可变规则。
在大数据的背景下,有时简单的规则并不能很好地区分借款人的好坏,通过建立机器学习模型减少误判越来越重要。尤其是当客群逐渐下沉,策略已经很难找出高收益客群,必须依赖模型从矮个里面拔高个。
2. 模型准,策略稳
可变规则,因为用到的变量少,规则简单可解释,一般都会比较稳。即使数据发生波动,分箱处理天然就进行了缓释。
大数据模型,变量少说上百个,多则上千上万维,更不要说他们的交叉组合,可以更精准地对好坏用户区分。数据的波动基本都会反应到模型分的波动。
风控在于应用简单或复杂技术从多个视角对用户进行风险排序,策略和模型分属这两类。
二、策略
策略的三板斧:客群细分、触达客户、额度息费。
我不是做策略的,但我常想,策略做的事情到底是在干什么呢?想来想去,就上面 12 个字。
客群细分说的是不同的人走的策略肯定是不一样的。那第一步就是把相同的人分在一起,不同的人不分在一起。
怎么分?用数据去分。
因为外部数据是有成本的,数据的使用原则就是先内部后外部,先低价后高价。根据可得的用户数据,可以分这么个象限。
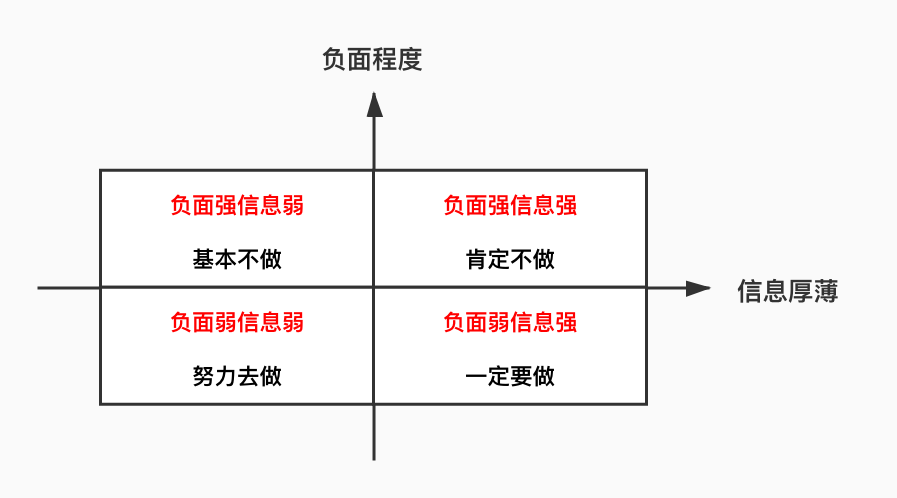
负面强信息强,意思是说负面行为非常明确,例如在很多平台逾期,肯定就不能做;负面强信息弱,是说负面的置信度没那么高,基本也不做;负面弱信息强,拿到了用户很多信息都没发现是坏人,肯定得做;负面弱信息弱,啥也不知道,就努力去做吧。
用反欺诈、黑名单等能找出的负面用户,好办,直接拒绝就行。用内外部数据能高效识别风险的也好办,低风险的通过,高风险的就拒绝。除了授信通过与否这个策略外,再有的就是额度和息费。
差异化也是根据风险。难办的其实就一个象限,信息薄也没有负面的客群。这其实是最主要的获客客群。
这样的客群,要尽可能细分,再差异化触达。
之所以要差异化触达,是风控很求稳,不管前端流量如何,全靠策略模型去防控风险是很危险的。相同的策略,不同的流量来源,风险差异可能都很大。
信息厚的可以预授信的客群越多越好,想方设法吸引他们来申请就可以了。信息薄的要精挑细选,让那些稍微好的来申请,对那些不好的先看看能不能让他们变成好的,能的话就再触达。
具体点:在商城买很多东西的人,让他们赶紧来借款;在商城不买东西的人,可以先运营他们来买东西;买完东西后还不能判断的人,不主动触达用户了,用户自己来了,策略模型能通过但可信度不高的,给他低额度试用就行;等他表现好了,暧昧关系稳了,就提额接着玩。
三、模型
模型是应用多方数据源建模拟合风险标签,从多个维度对用户风险进行预估。也可以对数据源或者数据维度单独建模,得到多个单一维度的评分,再上层融合成最终评分。子评分和主评分可以弹性地被应用于策略。
例如互金行业的三方数据就集中在多头这个维度,三方数据源就有很多家,把这些数据源的多头变量汇总在一起建模,就可以叫一个多头共债模型。对单一数据源的建模,就是定制化联合建模。
模型怎么建,一部分取决于模型团队的开发部署能力,另一部分取决于策略的应用水平。
大数据风控模型和传统评分卡模型相比,本质区别就在于特征多不多。随着模型从 LR 到 XGB 甚至深度学习的发展,一般会用上尽可能多的变量,变量维度也不予设限。
数据越多不一定效果越好,但数据越多样,越多越好这句话一般就没错。
少数头部平台有一些有效的自有数据,如京东、淘宝的电商,腾讯的社交,百度的搜索数据在信用评估里有效性都很低。
数据不自有,就要依托于第三方。尤其是多头数据,极大程度地依托于第三方征信数据服务商。于是,数据存在较大的接入成本,而数据源之间又存在一定的共性。
模型团队的开发能力,就包括三方数据源的评估能力,特征开发的能力和快速建模能力。
一个模型分肯定比多个模型分用起来更简单,精细化运营又使得业务就需要多个模型解决问题。模型可以往复杂方向设计,策略也要有能力去落实应用。
最常见的模型是 LR 评分卡模型和 XGB 模型,需要解释性强就用 LR,不需要都可以上 XGB。额度定价模型可能需要采用深度学习的解决方案。
最后,由于信贷产品的多样化和市场的多变性,策略和模型都是需要快速迭代不断调整的,往往追求效果比追求稳定更重要。策略和模型之上,要做好监控。
本文由@雷帅 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


