
 起点课堂会员权益
起点课堂会员权益B端产品经理如何将AI融入到产品设计(智能BI平台)
本文深入探讨了B端产品经理如何将AI技术融入智能BI平台的产品设计中,提供了实用的指导和建议。阅读本文,你将了解到如何利用AI提升产品的智能化水平,希望这些内容能为你的产品创新提供有价值的参考。

传统B端/数据产品经理如何将AI融入到产品中,如何用AI为产品赋能,帮助业务提效降本,本文从传统BI分析平台如何转化为对话式的智能BI分析平台的产品设计全流程来讲。
首先,我认为AI产品经理要做的事情主要就是清楚产品在什么场景下,什么环节中,能用什么样的模型/算法来帮助产品降本提效。
一、BI分析平台
1. 做BI分析平台的初衷
想通过私有化部署的一个数据分析平台,通过拖拽的方式来创建分析图表,通过不断的通过筛选,选择维度,指标来创建不同的分析报表,提供数据分析,数据看板,数据管理等,目的是解决数据孤岛问题,沉淀数据资产,提供数据看板及分析能力。
2. 做BI分析平台时遇到的问题
主要还是在于非专业的数据分析人员,各个门店/营业部老板,需要关注数据的一线销售人员/组长·BI分析平台虽然能提供拖拉拽的数据分析看板,但是他们没有数据意识,不知道如何组装数据,面对大量数据无从下手;
- 想要查看数据分析的时候不知道选择什么图标能更好的展现数据;
- 数据操作流程不懂,如果去进行大量培训,效果不一定好,而且耗费人力物力也太大;
3. 对话式智能BI数据平台
由于B端系统,特别是数据平台操作是需要一定的学习成本的,但是对话是符合人类直觉,基本是零成本的,所以我们就想基于AI的能力,通过引入多轮对话,智能查询的方式来对图表进行智能推荐,对话式分析查询,实现所要即所得,降低产品使用门槛。
二、需求实现设想
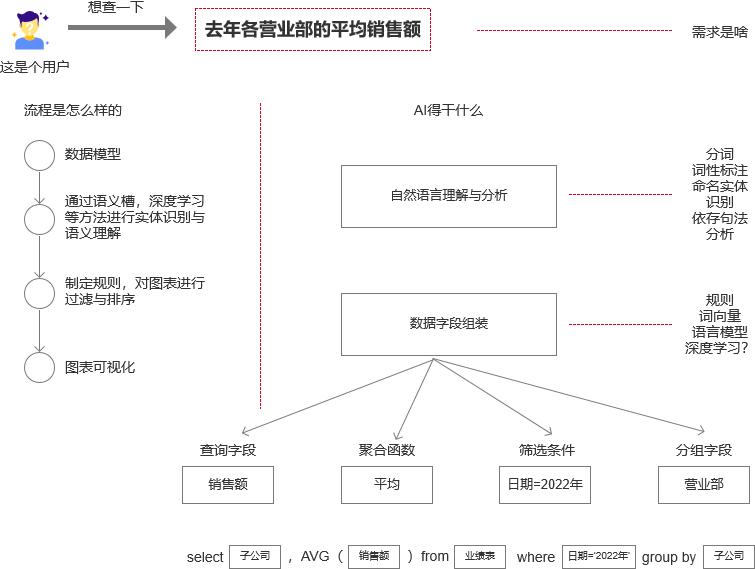
如果一个用户想通过自然语言来查询“去年各营业部的平均销售额”那么就应该是通过分词的方式,将“去年”“各”“营业部”“平均”“销售额”通过分词的方式来进行sql组装来查询,然后后给用户推送可视化的图表。
那么这个需求实现的步骤应该是:
- 分词:分词主要是通过将用户输入的内容进行词语的拆分,一般是用Python的jieba的分词库。分词匹配的词向量中需要注意相近词但意义不同的词(例:销售总额;销售总量;笔单价;客单价;人效;人均时效等);比如我想查销售额,但是有没有可能会匹配成销售量,一般可以根据余弦相似度进行匹配以及用户错别字的纠错(一般分为:弱纠错;中纠错;强纠错)
- 匹配词条:把用户的内容放到词条库里面去进行匹配,然后根据知识图谱网络关系来匹配,根据语料,依存句法,进行词表映射,去识别实体,理解语意。一般我们会在语料库里面有大量的词可以匹配,但是由于不同的业务可能会产生不同的词条,这种是在词库里面没有的,那一般有两种方法,一种是内置词条,这种事需要花费一些时间把高频关键词内置到词条库里面,还有一种就是根据余弦相似度或者皮尔逊相似度这种算法来进行近似词的训练和匹配。
- 规则:比如排序,加权,分类,数据权限控制,结合业务情景等,例如最近刚过双十一,用户:我要查双十一的销量情况,你就可以主要推送今年双十一和去年双十一对比。
- 组装sql进行可视化推送,可视化推送的时候要注意不同指标类型,不同量级,不同分析情况要采用的默认推荐样式(比如饼图设计原则是顺时针从大到小;柱状图注意节点标注等,设计原则就不在这里说了)。
三、系统流程
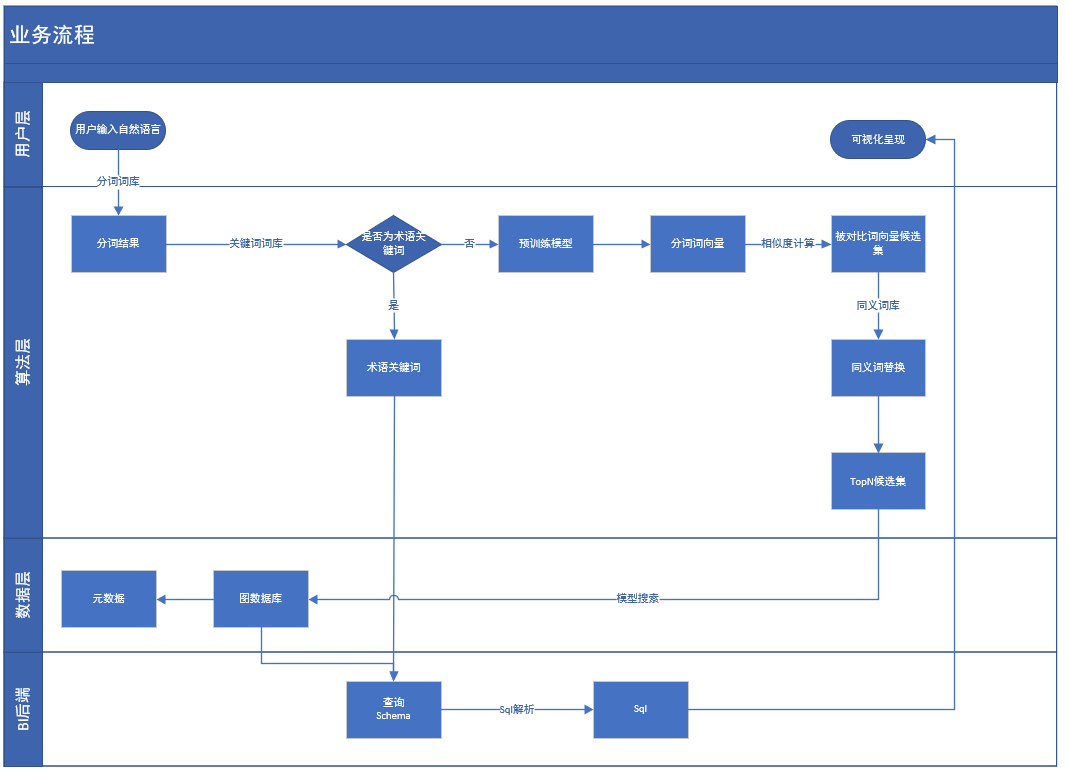
基于需求的设想,整体业务流程可以分为:
- 用户层:用户层的功能可以包括查询窗口;可视化展示界面(一般只对用户开放),运营管理(针对数据运营人员展示,一般是数据管理人员)
- NLP服务:主要是将元数据抽取到neo4j图数据库中,来形成知识图谱
- 算法层:主要是负责处理自然语言的解析过程,类似nl 2 sql的过程
- BI后端:负责解析算法,并组装成sql schema执行查询,并在前端展示view
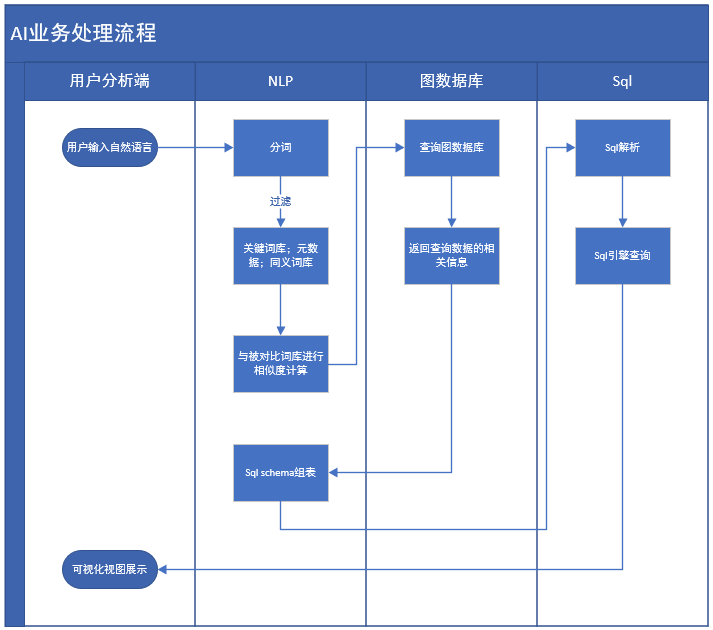
用户端在输入要查询的自然语言之后,NLP根据预先构建的词库进行分词,分词处理的时候会过滤出关键词,剩余的词会与被对比词库进行相似度的计算,并且根据元数据同义词库,对相应的词进行替换,相似度较高的词语会到图数据库中进行搜索,图数据库的搜索结果返回给NLP,NLP按照sql引擎的查询,需要的sql schema进行数据组装。
四、功能架构
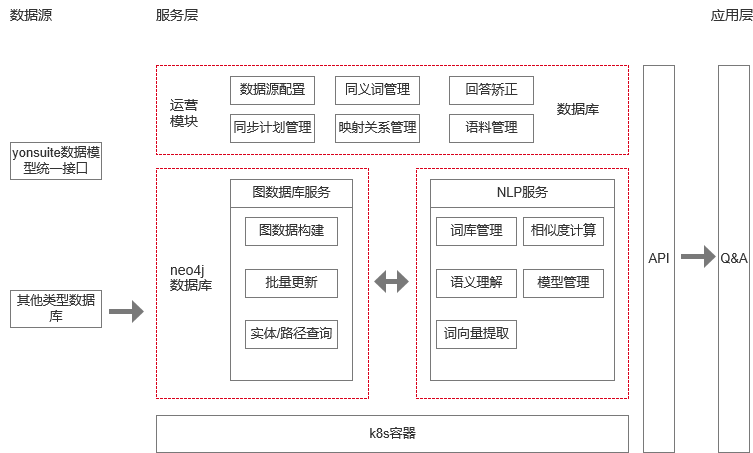
- 图数据服务:负责构建图数据库,提供实体查询,提供根据维度度量文本搜索,返回现在已经构建的模型及其相关信息
- NLP服务:负责对用户输入的文本进行理解,对维度,度量,维度值,过滤条件等类别的文本进行分类,结合图数据库存储关系数据构建sql查询用的schema,实现nl 2 sql的功能
- 运营模块:负责管理和监控图数据库的构建过程,对用户历史输入数据进行管理,管理用户自定义关键词和元数据同义词,管理映射关系数据
五、原型演示
1. 移动端
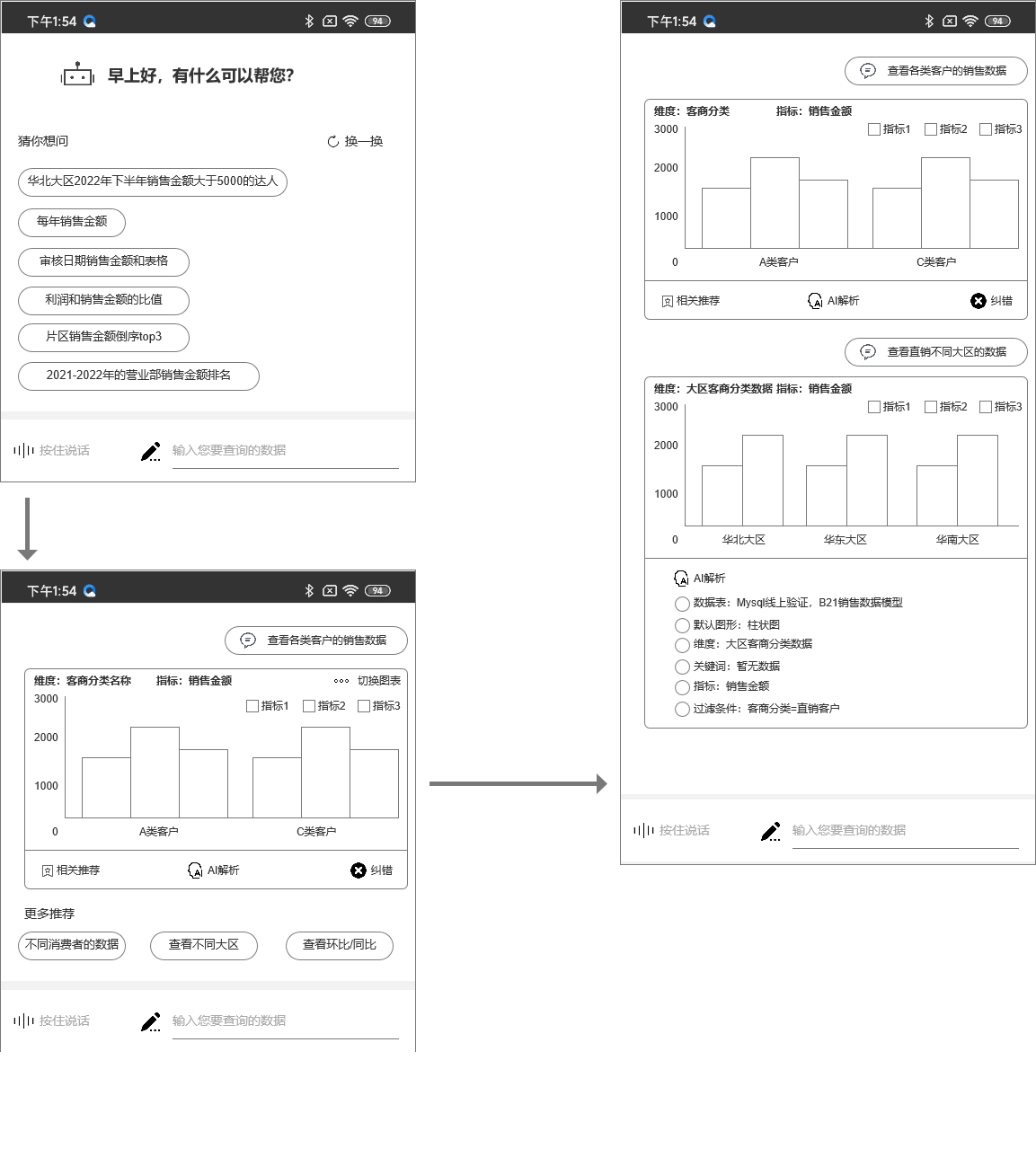
移动端的能力(部分):
- 支持移动端的快速查询数据,方便用户通过移动端快速查询和输出相关数据及报表
- 支持自然语言查询,减少使用数据的成本
- 支持多轮对话,智能推荐,通过知识图谱的方式来进行数据连锁建议
- 支持数据图表解析,帮助用户解读数据
- 支持用户反馈,用户反馈能帮助模型持续训练,也能收集用户需求
移动端来说会更加的简单,移动端主要的作用是面向用户能快速的查询数据的能力。
2. pc端
2.1 pc端对话分析
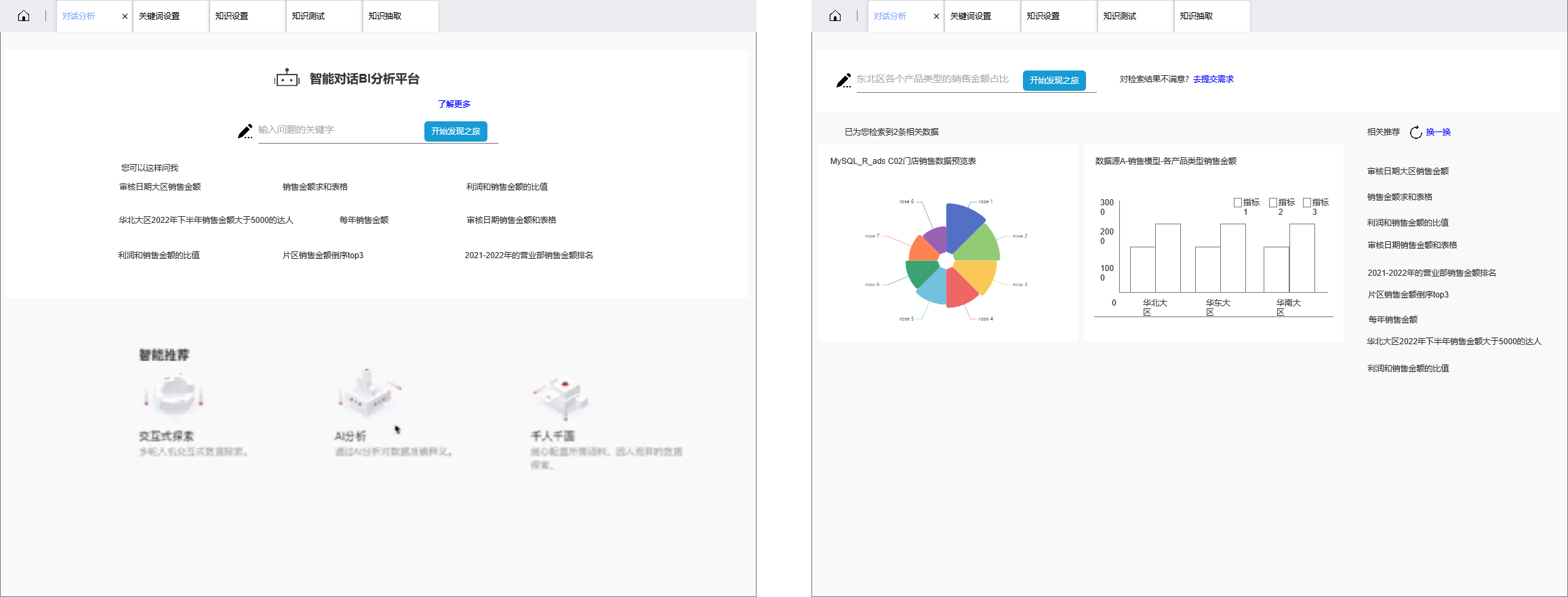
PC端的能力(部分):
- 支持pc端用户通过自然语言查询
- 支持pc端用户快速配置想要的数据模型
- 支持pc端多维度的数据组合产出
- 支持数据推荐,通过知识图谱关联推荐
- 支持AI数据解析,收藏等操作
2.2 知识抽取
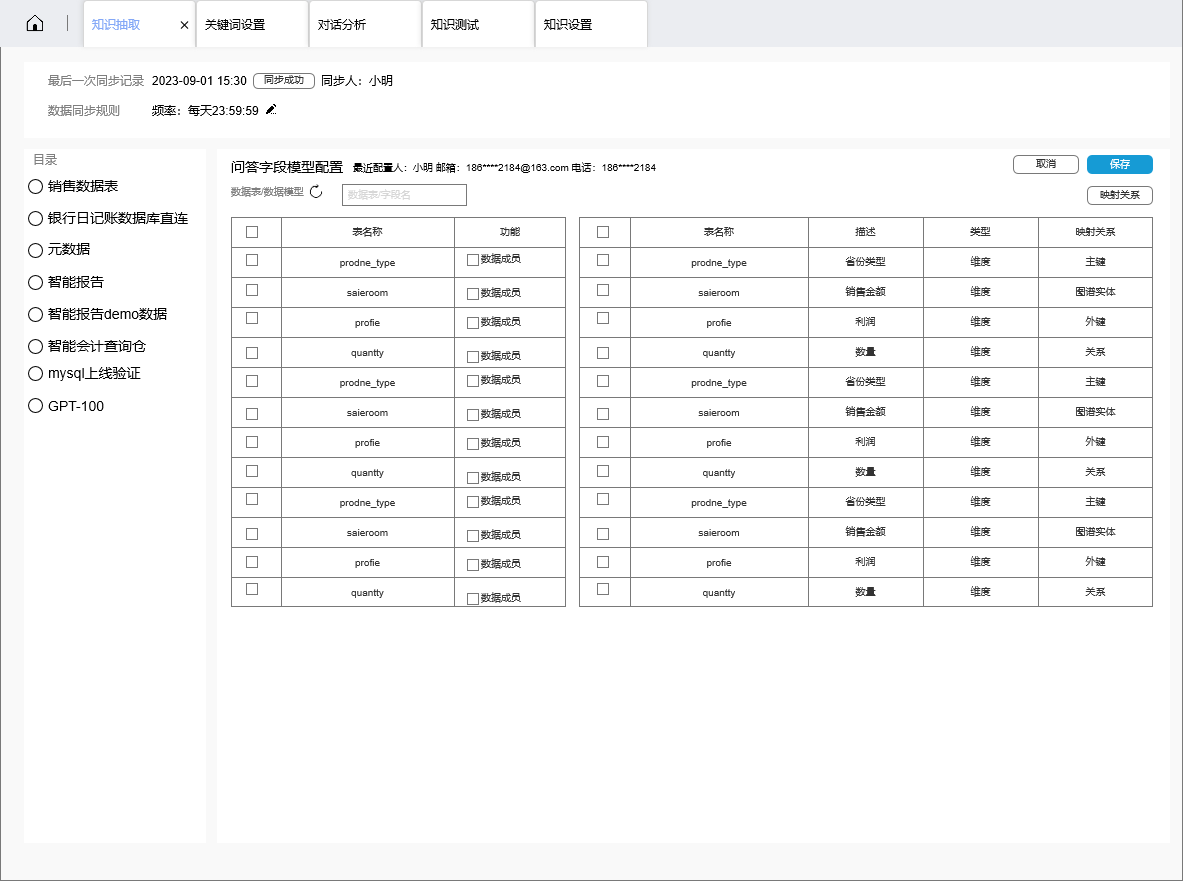
知识抽取主要是对链接的Mysql数据库表进行抽取,应支持对应数据,对应的表,选择之后同步,生成图数据库,包含字段,数据库表,数据成员,表与表之间的关系,做映射,然后通过知识映射关系的配置,来支持数据同步到线上模型。
2.3 知识设置
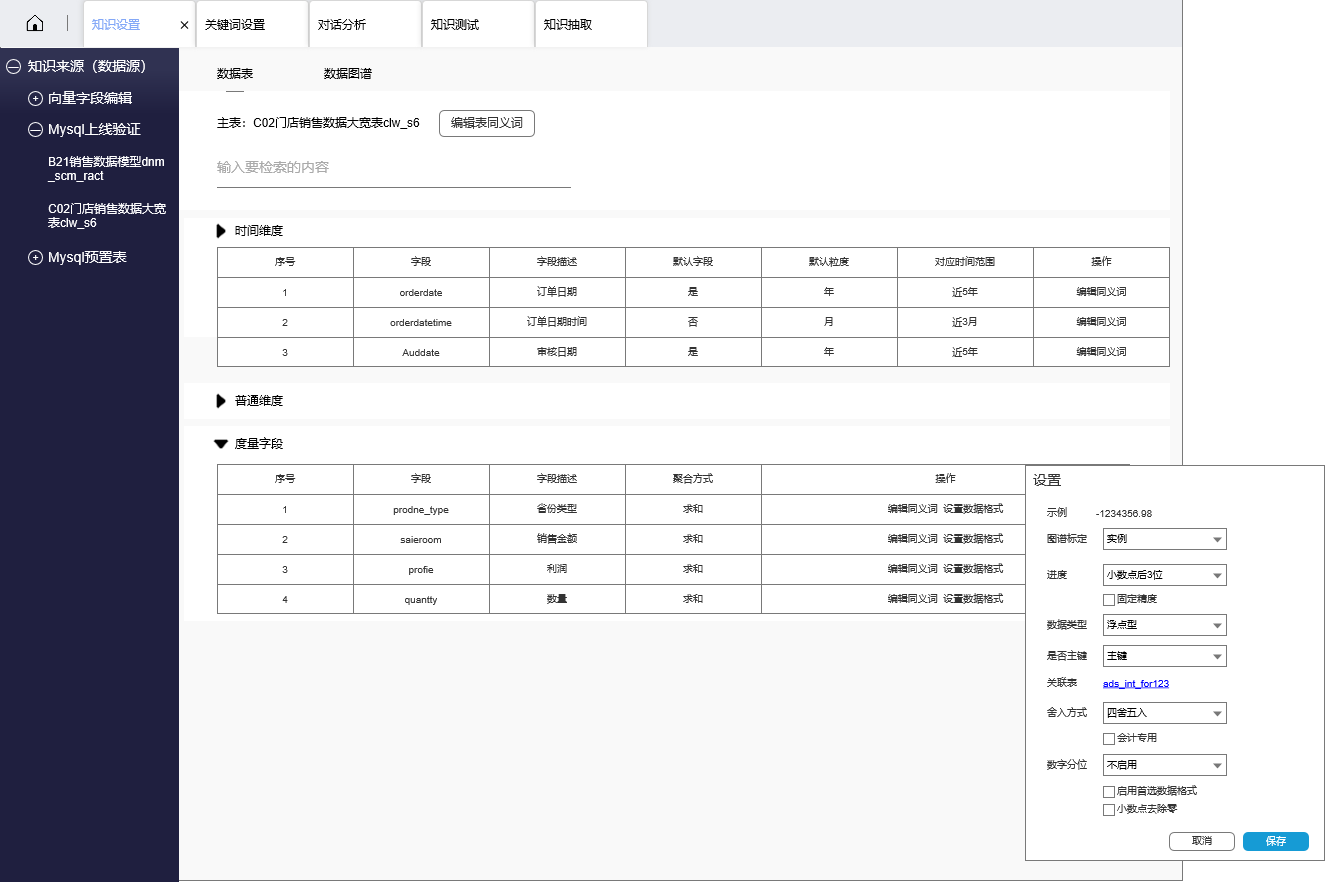
知识设置支持的能力(部分):
- 通过设置数据字段和数据成员的同义词,添加到知识图谱中,提高关键词模型的泛化程度
- 支持设置数据模型时间的默认字段,让用户在查询数据的时候返回相对合理的时间范围(比如:销售金额应看不同业务场景,是默认近7天,还是1个月,还是3个月,还是近一年)
- 支持设置时间的默认粒度,让用户查询数据的时候返回合理的时间粒度
- 设置度量字段的聚合方式,是求和,还是计数,还是求平均值,还是找最大最小值,还是分组聚合等
- 支持度量字段的数据格式,比如是int,还是浮点型,还是日期型等
2.4 知识测试
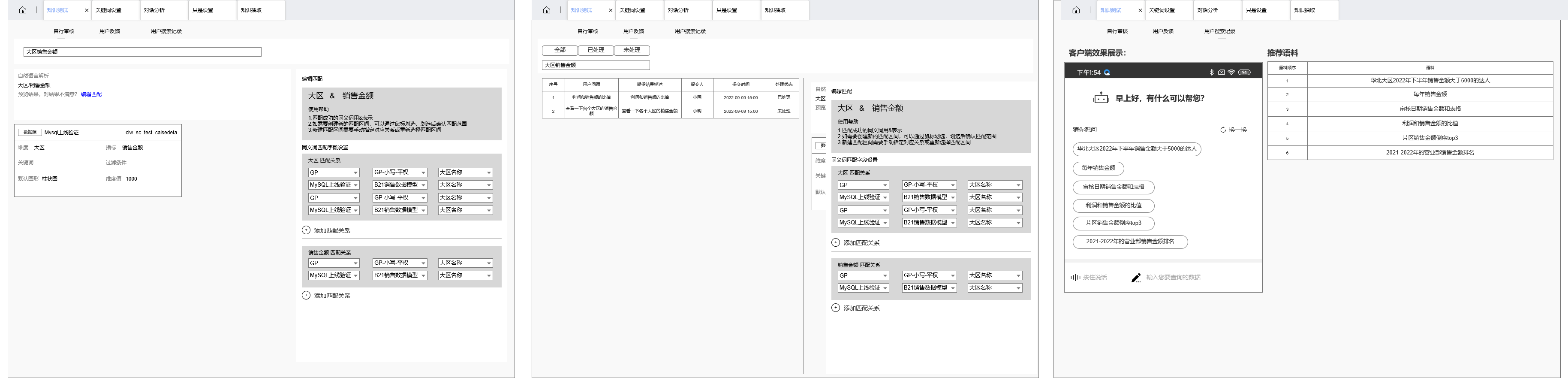
知识测试支持的能力(部分):
- 支持运营端的自然语言查询结果,让运营端可以自主测试目前模型跑出来的情况是怎么样的,相当于一个测试服,并且可以随时调整参数
- 支持运营端配置推荐语料,也可以由机器自动进行配置或者推荐,可以用协同过滤的方式进行千人千面推荐(看实现成本和收益)
- 支持运营端对不准确的语料进行人工手动维护
- 处理用户反馈
六、技术实现
NLP服务与词库识别技术结构:
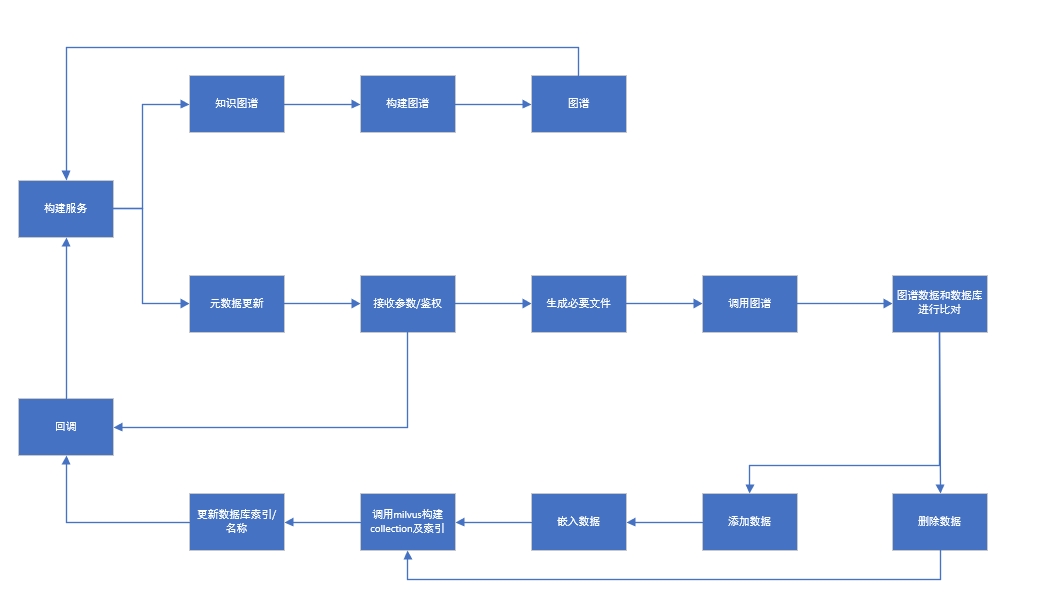
1. 词库与数据同步逻辑
词库模块的主要实现方式是通过接受后端对源数据同步的请求,调用知识图谱的接口,获取用户对数据同步的所有源数据,来对比之前的源数据信息,对数据进行增删,对新的数据源在进行词嵌入,再构建milvus索引,以便搜索服务做词向量相似度的搜索。
2. 数据存储结构
一个表可能出现在多个数据源中,一个维度可能出现在多个表中,一个维度值也可能出现在多个维度中。
Node Labels:tenant、数据源datasource、表/模型table、字段/成员值column
Property Keys:
name(en):记录实体名称
comment(cn)):实体的中文名称
data_type:实体类型,分为dalasource数据源,table表、dimension维度、ENTITY实体,measure座量、datetime时间、d_value维度值
value;维度值的映射值
inks:节点之间的关系,分为relale 租户和数据源的关系、tablelnDalaSourca表和数据源的关系、columninTabie字段和表的关系、entyinTable实体和引用表的关系(元数据)、valuelnDimension维度值和维度的关系、re1表和表之间的关系
3. 词匹配
基于milvus相似度检索和同义词替换后的词语,通过设定的不同阈值采取精确匹配和模糊匹配的策略,重新生成真正要查询的词语,排列组合并根据综合打分进行排序形成所需6组语料,每组语料通过最短路径查询,把实体关联到相关的表,再关联所属的数据源,从而搜索出多条路径,最后返给np端所需要的结果形式。
七、产品能力
1. 机器多轮对话的部分场景和能力
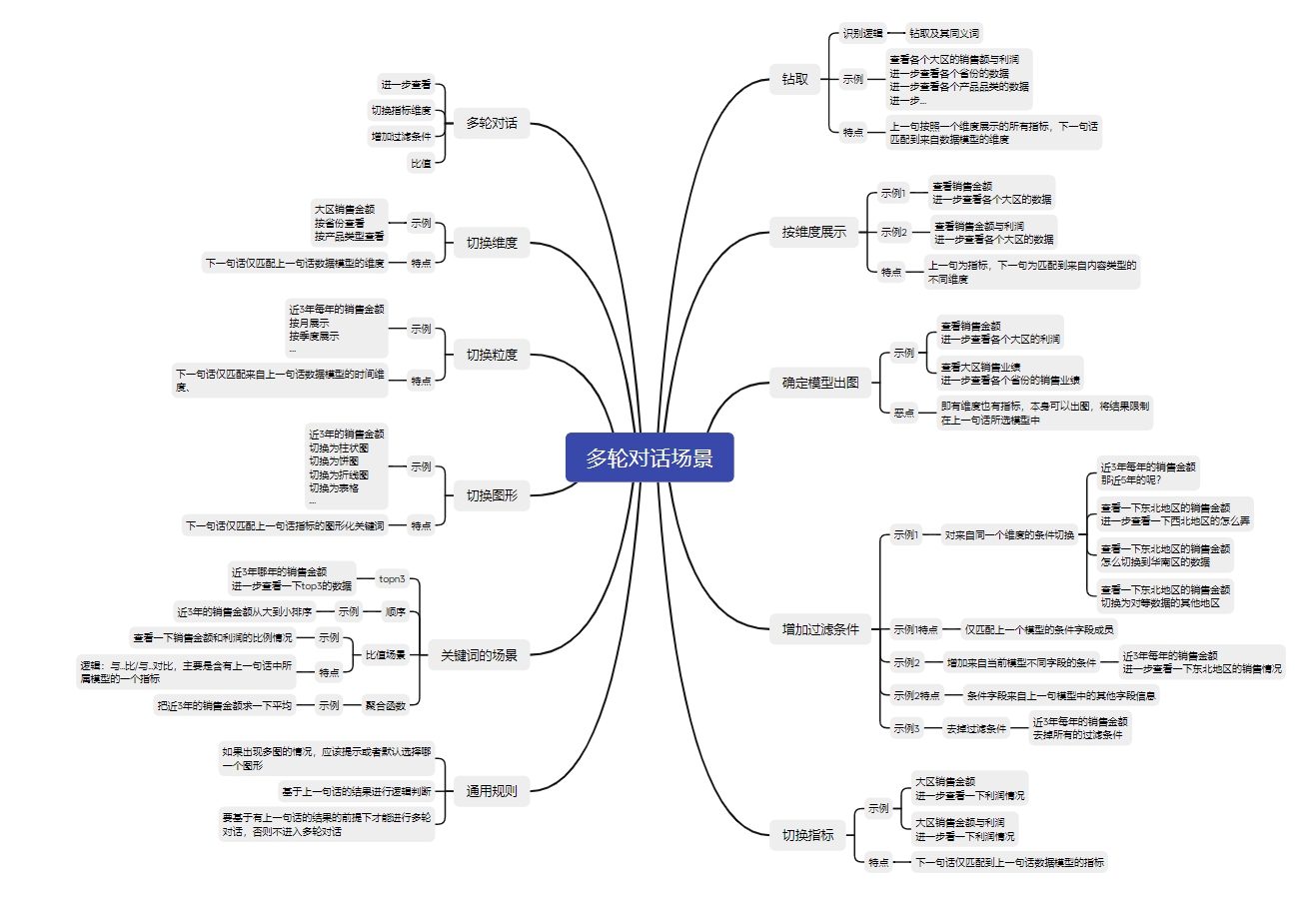
2. 智能BI的部分版本能力构思
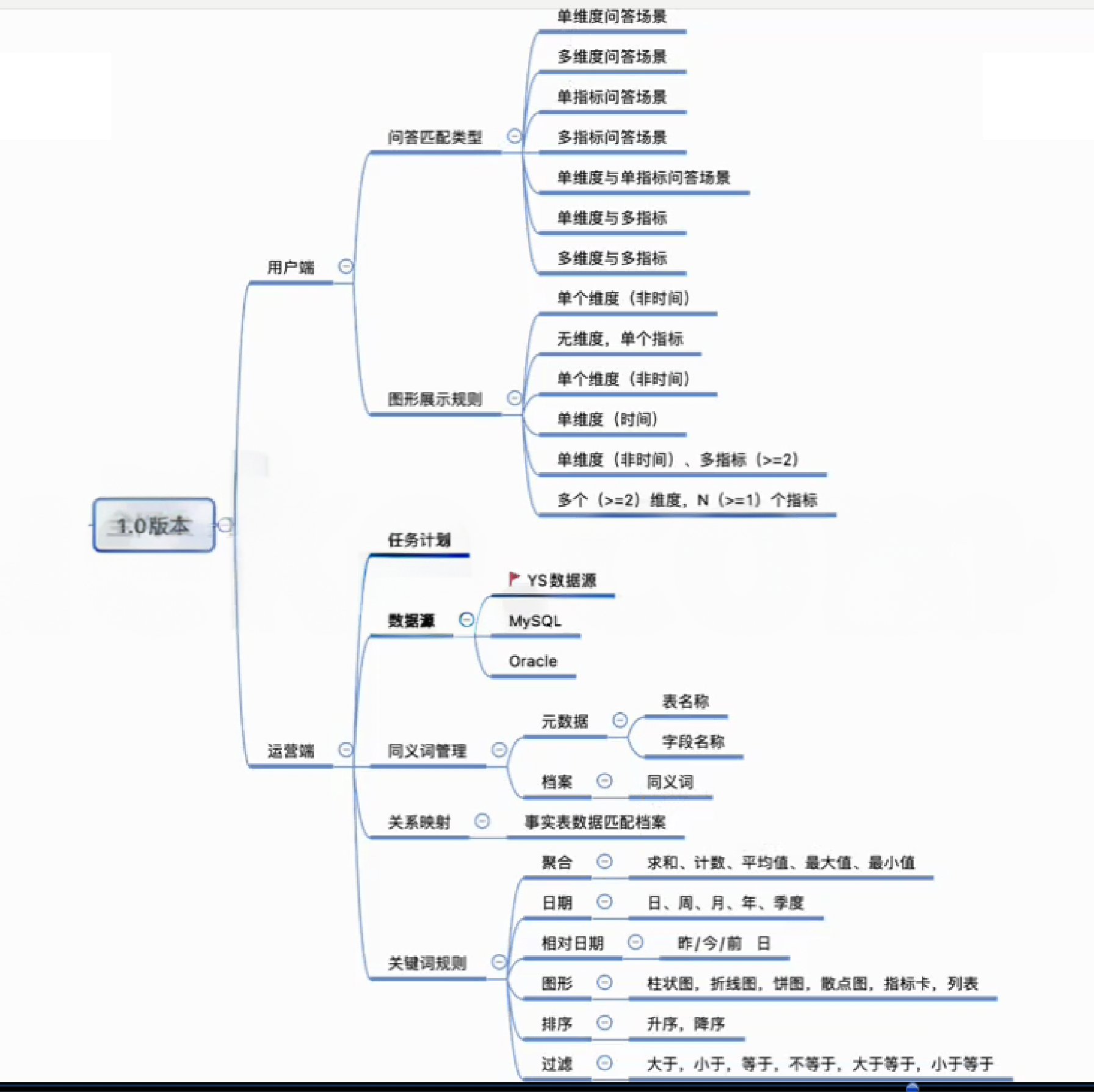
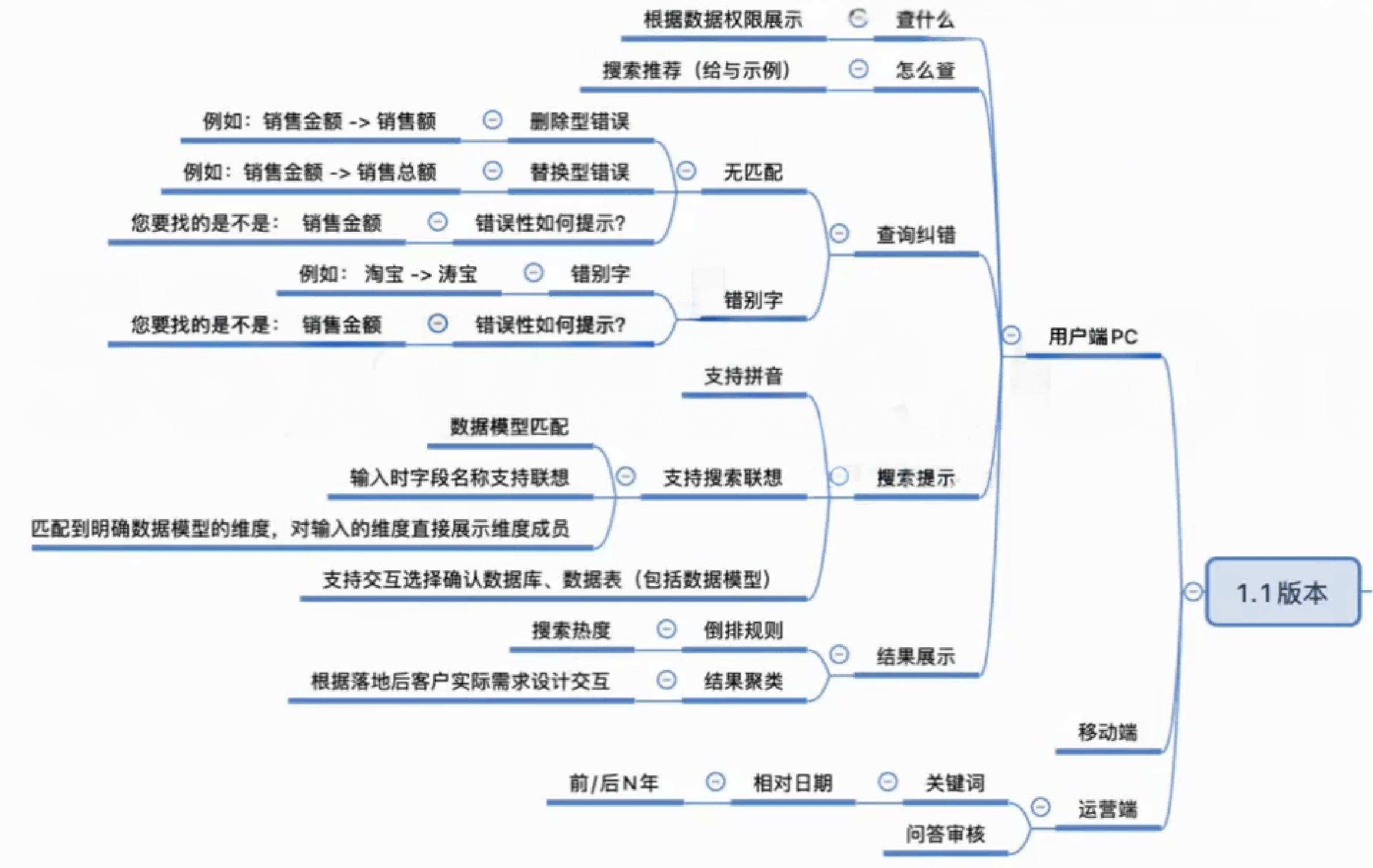
以上就是我在做BI数据平台时,通过思考产品价值,探究如何结合AI自然语言对话,意图理解,机器学习,知识图谱等能力的整体产品设计参考。
本文由 @生产队的产品人 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


