
 起点课堂会员权益
起点课堂会员权益国内10款大语言模型测评-竞品分析
国内大公司现在基本上都研发了自己的大模型,都支持很多功能。之前也有不少人对这些模型进行了分析,但都是单一的产品。这篇文章,我们从多个维度,以竞品分析的方式对国内的几个大模型进行比较一下。

一、竞品分析目的与意义
AI 大模型的英文含义是:Large AI Models。他的的定义通常指的是具有大量参数和复杂结构的人工智能模型,这些模型利用深度学习技术,通过大规模的数据训练,能够在多个任务上表现出优越的性能。
由于市面上涌现了各种各样的大模型,对于我们用户来说,并不知道哪种大模型比较适合我们,或者说哪种比较好用,这次我用六个维度来测评一下国内十款大模型,让大家可以根据自己的需求,来选择适合自己的模型来使用。
二、在研究大模型之前,让我们来简单了解一下这些大模型里面的一些基本的定义
1)大语言模型(Large Language Model, LLM)是一种专门用于处理和生成自然语言文本的人工智能模型,它有大量参数和复杂结构,能够理解、生成和翻译自然语言。大语言模型通常通过在大规模文本数据上进行训练,学习语言的各种模式和特征。
2)多模态大模型(Multimodal Models)是指能够处理和理解多种类型数据(如文本、图像、音频、视频等)的人工智能模型。这些模型通过集成不同模态的数据,能够更全面地理解和生成复杂信息。这种能力使多模态大模型在各种应用场景中表现出色,例如自然语言处理、图像识别、语音识别和生成、以及多模态交互等。
3)通用语言模型(General Language Models)是一个广泛的术语,通常用来描述能够处理多种语言任务的模型,而不论其规模大小。GLM可以包含从小型到大型的各种模型,关键在于它们具备处理自然语言的通用能力。这些模型可能专注于特定类型的任务,如问答系统、文本分类或语言生成,但它们通常设计得足够灵活,以适应多种不同的应用场景。
三、竞品分析
1、模型选择
本次主要分析国内使用率比较高的通义千问、文心一言、kimi等10个左右的大模型,通过日常生活、工作流程等方式做对比和总结说明,分析出几款相对比较好用的大模型。

2、调研维度
为了更直观测试这些模型在实际场景下的表现,我们收集整理一套场景数据集,主要包括:
是否能够联网获取信息、知识理解、上传文本分析、文生图、逻辑推理、休闲问答(多伦对话能力)等六个方向进行调研
3、调研过程
给每个分析角度一个规则,分析这些模型的回答是否能按照这些规则输出相对稳定的回答,并对这些回答给出一个相对合理的分数。
基本的规则为:
由于已经上线的大模型已经属于相对完善的模型,所以我根据模型的回答,分析回答后得出:回答是否“不满足预期”、“符合预期”和“高于预期”
- 不满足预期的标准为:需求不满足(包括:部分满足和部分不满足)、内容质量相关(包括:内容不全面、语句前后不通、信息前后不一致、有危害性的信息、还有一些不太符合要求的格式)
- 高于预期的标准为:语意正确、格式美观、没有那些危险有害偏激的信息、有提炼的总结、有一些推理的过程等等。
评分标准:(满分10分)
- 不满足预期:需求不满足的比如回答与问题无关的直接0分、有高危害信息内容:0分、内容不全面:-1分、语句前后不通顺:-1分、信息前后不一致:-1分、有偏见性的行为:-1分、格式不符合:-1分
- 高于预期:语意正确:+1分、格式分段/分点合理美观:+1分、有提炼总结:+1分、有推理过程等:+1分
1)是否能够联网获取信息
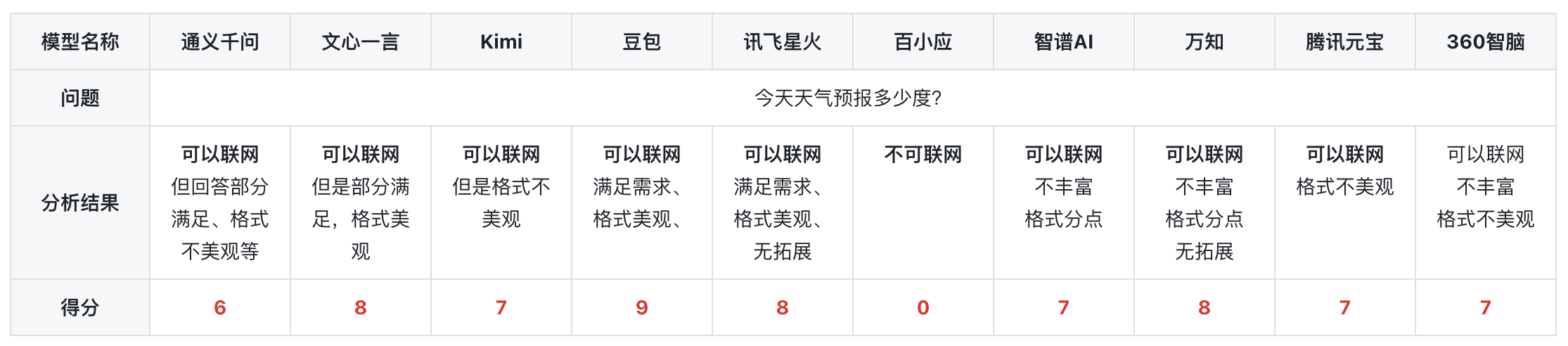
总结:在进行了一系列的测试之后,测试结果显示,除了百小应未能联网外,其他所有模型都有联网功能,豆包、文心一言、万知在格式是也比较美观合理。豆包在需求之外还进行了问题拓展,所以分数较高。
2)知识理解
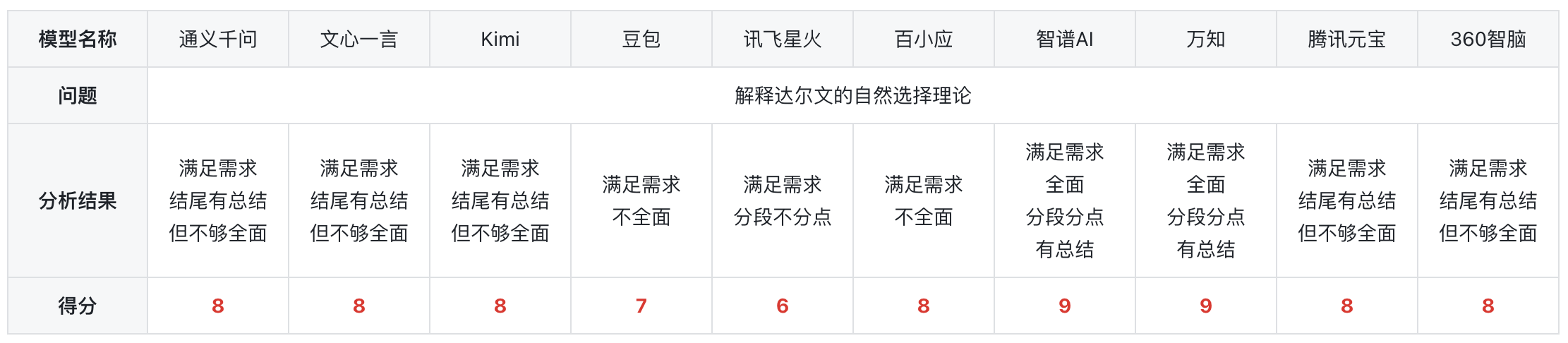
总结:在进行了一系列的测试之后,测试结果显示,所有模型均能回答出所提出的问题,但是,智普AI和万知可以在需求满足,分段分点有总结的情况下,全面的回答出了问题。所以分数较高
3)上传文本分析
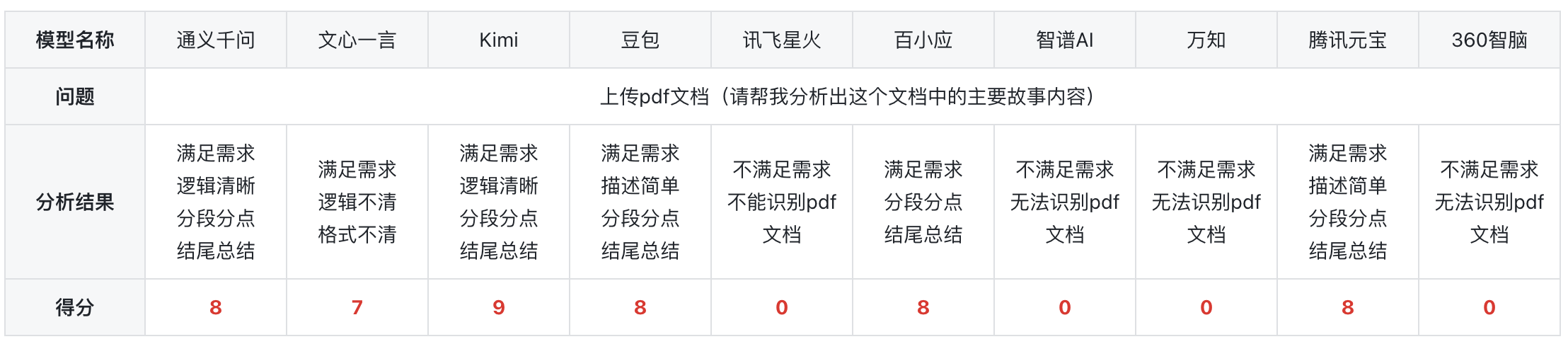
总结:在进行了一系列的测试之后,测试结果显示,除了讯飞星火、智普AI、万知、360智脑基本都能满足需求,而kimi大模型逻辑清晰、分段分点回答、结尾也有对全文的总结,所以分数较高。
4)文生图
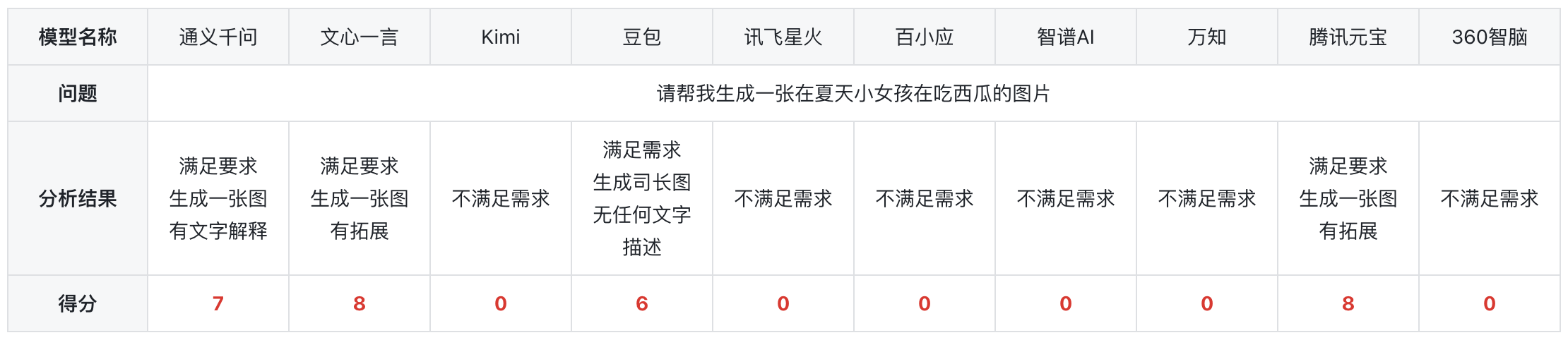
总结:在进行了一系列的测试之后,测试结果显示,除了通义千问、文心一言、豆包和腾讯元宝其余模型均不能直接生成图片。
5)逻辑推理
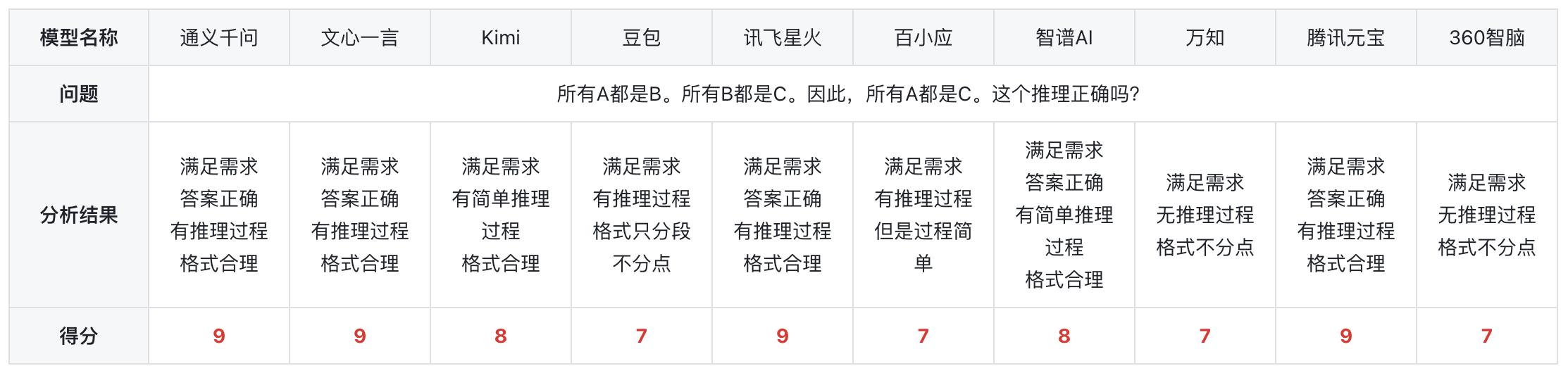
总结:在进行了一系列的测试之后,测试结果显示,所有模型均能回答正确,通义千问、文心一言、讯飞星火、腾讯元宝的答案既满足需求答案正确、也有推理过程格式分点、分段有合理性,所以分数较高。
6)休闲问答(多伦对话能力)
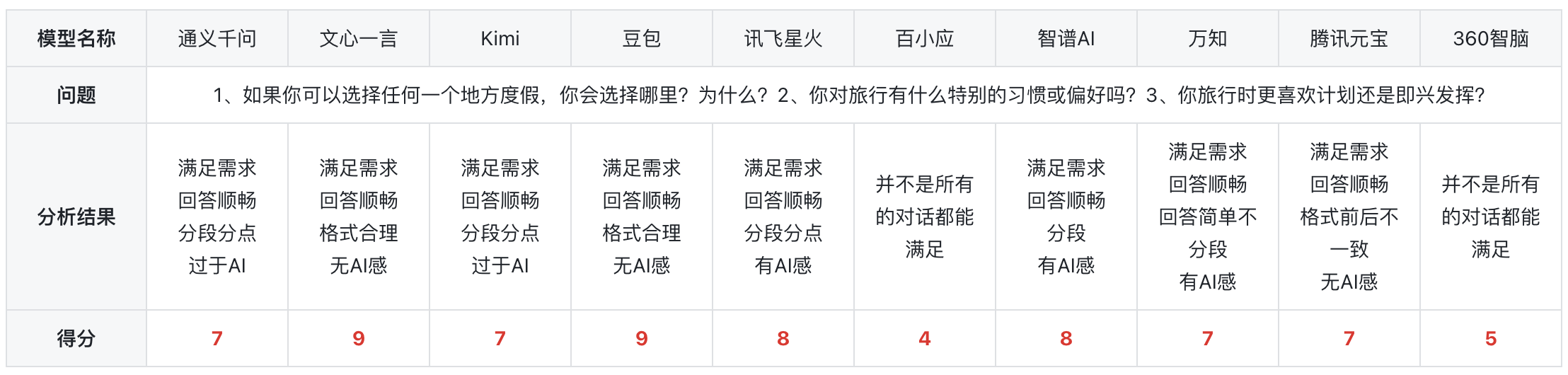
总结:在进行了一系列的测试之后,测试结果显示,大多数模型都能满足需求,有很多模型都自称AI,非常有AI感,少数模型,比如文心一言、豆包与之对话,让人感觉对面是您的朋友,没有AI的距离感,让人感觉很舒适。所以得分较高。
四、总结分析
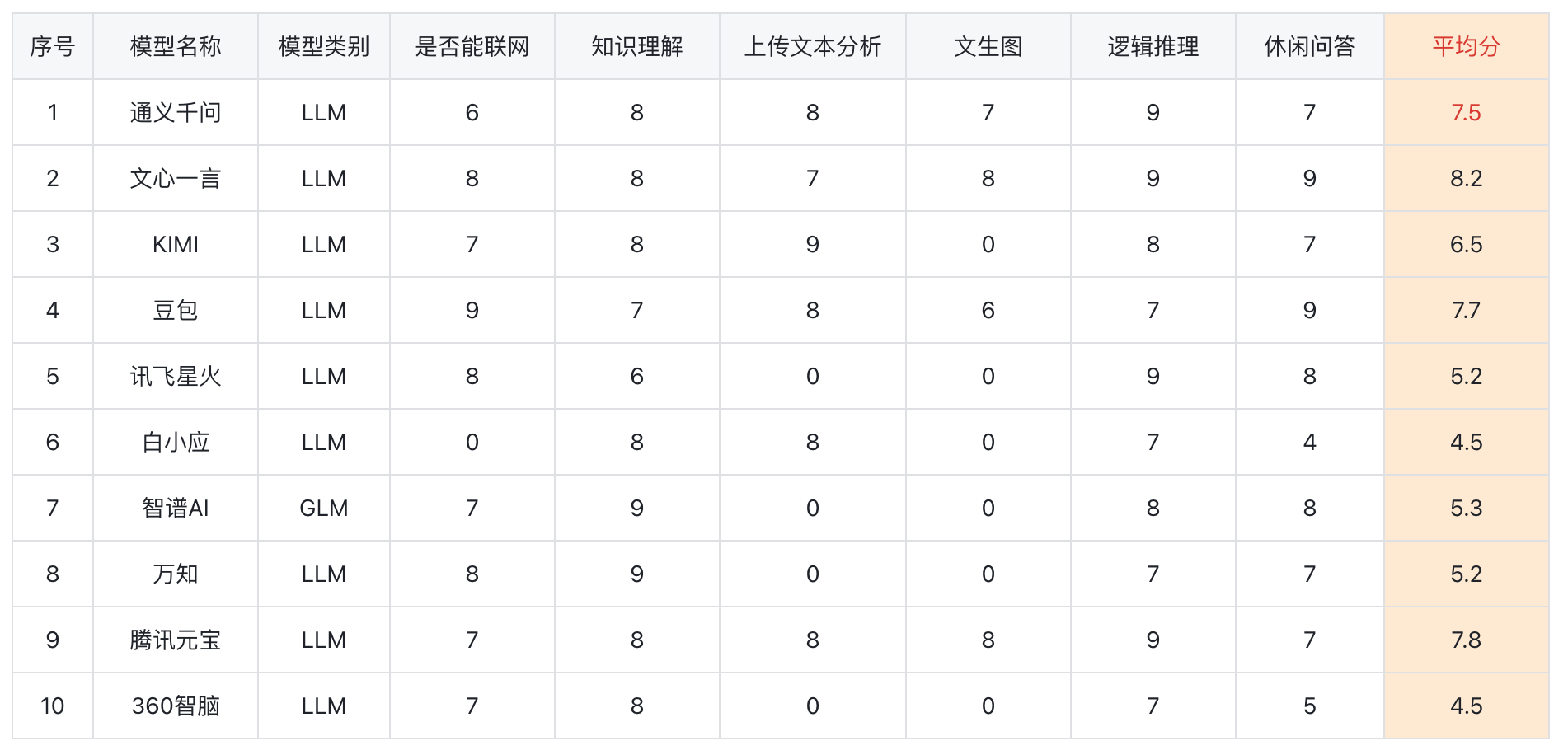
总的排名为:
1、文心一言(8.2) 2、腾讯元宝(7.8) 3、豆包(7.7) 4、通义千问(7.5) 5、kimi(6.5) 6、智谱AI(5.3) 7、讯飞星火(5.2) 万知(5.2) 9、白小应 360智脑。(4.5)
以上排名均为本人对大模型的主观判断,谨代表自己。不代表任何官方和别人哈。
最后,我们期待国内AI企业能持续引领技术创新,深化行业应用,为社会创造更多价值。展望未来,让我们共同期待AI技术带来的无限可能,携手开启智能新时代的大门。
本文由 @贝琳_belin 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务






- 目前还没评论,等你发挥!


