
 起点课堂会员权益
起点课堂会员权益初写SKILL随记
用Claude Code写SKILL的几点心得:保持上下文长度不超过50%,用/btw处理临时话题;SKILL本身即需求&代码一体化,但仍需配套PRD保留原始信息;知识库是静态内容,SKILL是SOP,两者分离管理。沉淀知识库本质是在清空大脑,构建第二大脑。

这几周开始使用CC尝试开始写SKILL,做了一个小的培训系统。
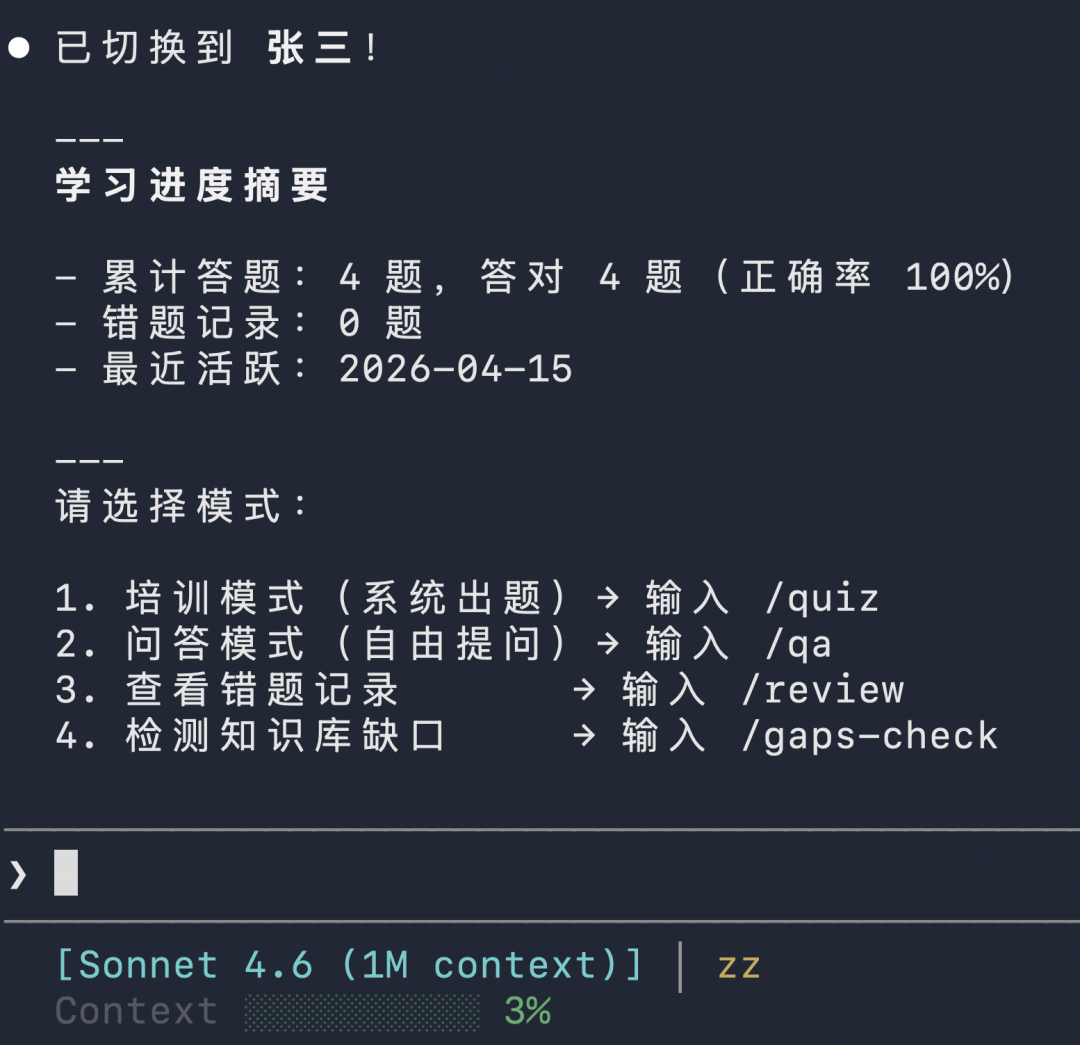
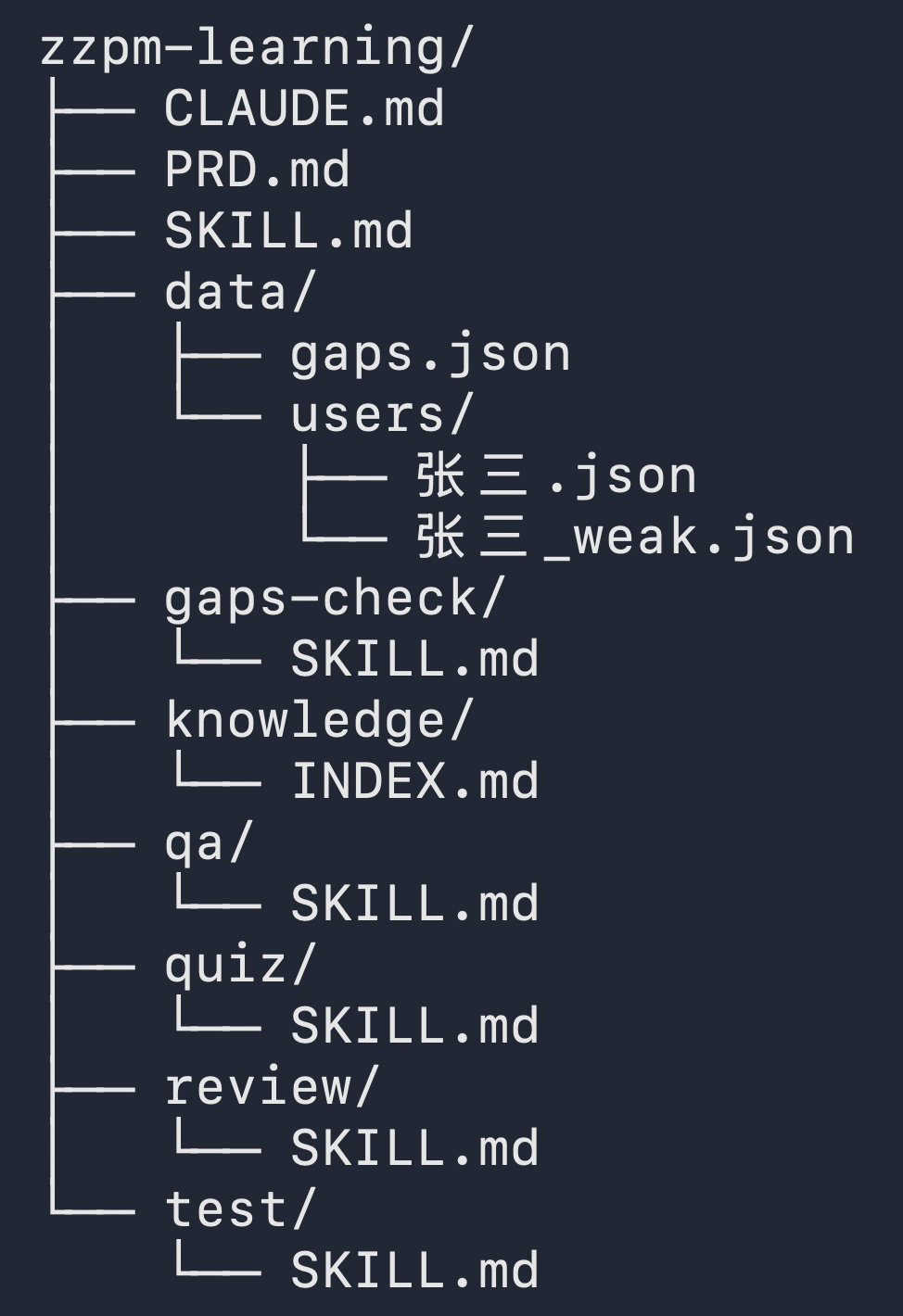
功能不复杂,也不是重点,有几点心得记录下:
01 几个关于使用CC的小经验
① 认真对待上下文
- 保持上下文长度在一定的安全范围(可以装一个hub监控),避免模型响应质量下降,我一直不超过50%。然后要不就是/clear,要不就是/compact。
- /clear不是简单的直接清理,本质要归档,要不沉淀到md,要不就是丢弃内容,要不就是放到缓存区(下次接着用)。
- 要沉淀md的内容,一定要谨慎确认。
- 尽量不要在一个窗口聊多个话题,临时的话题用/btw,其他新开窗口。
② 写SKILL要配套创建PRD
SKILL本身即需求&代码一体化,为啥还单独要有PRD?我理解自己SKILL是一个最新截面,但是PRD是原始+过程信息。保留这些信息后续SKILL迭代会有历史信息,因为我们不可能一直保留着上下文。
③ 写SKILL要配套创建测试SKILL
尽管可以在SKILL里面写测试校验逻辑,但我感觉还是最好有一个单独的测试SKILL,尤其是SKILL是一个复杂SKILLS矩阵,一个单独的SKILL可以管理整体性校验。
④ 放MEMORY?还是CLAUDE?
有时候你强调一个要求,CC会进行强化记忆。很多时候,CC自然会往MEMORY里面放,这时候你一定要判断一下。如果是项目级(某个SKILL本身)影响,则建议放到对应的CLAUDE,如果是全局级才能放MEMORY。
02 知识库和SKILL的关系
- 知识库是静态的内容,SKILL是SOP,SKILL会依赖知识库。
- 如果某些知识是SKILL专属依赖的,且不太会有较强的复用性,则可以放在对应SKILL文件夹内。否则可以放在单独的文件夹管理,SKILL进行路径引用。
- 构建知识库体系,一定要从顶层设计好文件夹结构,不要完全依赖AI。
- 沉淀知识库,本质是在清空大脑,同时构建第二大脑。所以你会有上瘾的感觉。
- 结合到工作场景,有2大类SKILL,一种是结合工作应用的SKILL(工作知识库+工作SOP),一种是通用的工具SKILL(不要自己造轮子,看GitHub上多星的直接copy)。
继续氪金,继续实践。。。
本文由人人都是产品经理作者【减形简远】,微信公众号:【产品杂谈】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






评论
- 目前还没评论,等你发挥!


