
 起点课堂会员权益
起点课堂会员权益AI落地工程的三次进化:Prompt→Context→Agent
从Prompt到Context再到Agent,AI工程正经历三次范式跃迁。本文通过合同提取、催缴推荐和员工助手三个实战案例,揭示每次跃迁如何解决上一阶段的遗留问题。当行业焦点从措辞优化转向上下文架构,再到系统控制,模型能力与工程范式的螺旋上升正在重塑AI开发生态。

2024 年,有个朋友找我说:帮我把合同里的关键字段自动提取出来吧。
几百份 PDF,要抽签约方、金额、起止日期、服务条款等。做法很直接——写个 prompt,扔给大模型,解析返回结果。项目做完了,效果还行。
但我很快发现一个尴尬的事:合同模板一变,prompt 就得重新调。 同一个模型,同一个任务,就因为表述变了几个词,输出就不稳定了。
当时我没细想,觉得这就是 AI 开发的常态。
2025 年,又来了个项目:根据欠费清单和历史缴费记录,自动生成催缴推荐名单。这次我发现,问题根本不是 prompt 怎么写,而是模型得先“看到”那些缴费数据,才能做判断。
2026 年,我开始做员工智能助手。这个东西不再只是回答问题,而是要去查数据、配知识、调工具——替人干活。
回看这三年,这三个项目刚好踩在了 AI 工程的三次范式跃迁上:Prompt → Context → Agent。
有意思的是,每一次跃迁,都在解决上一轮留下的烂摊子。
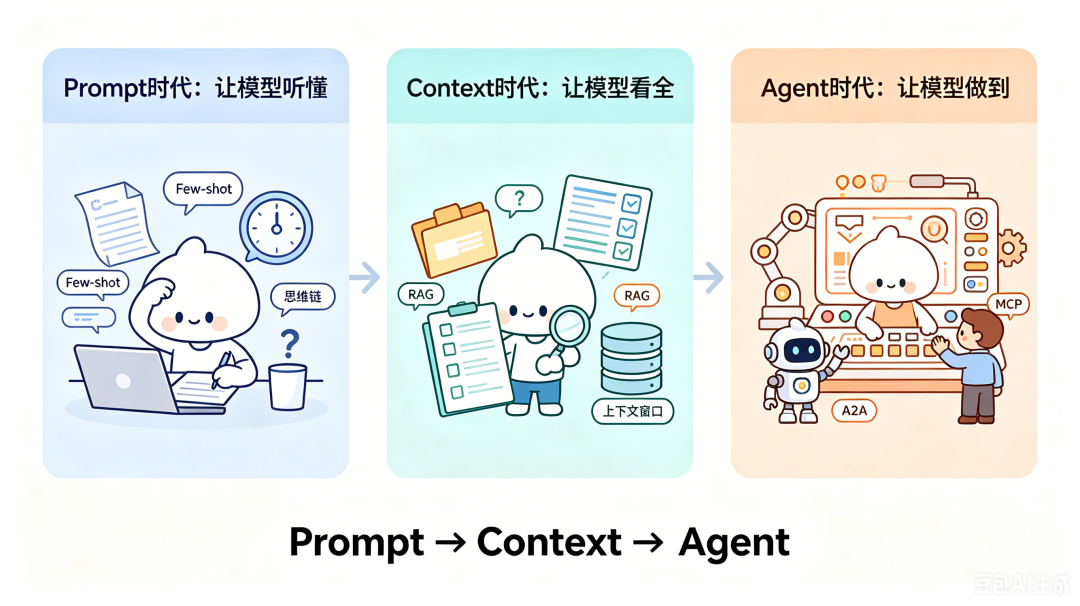
第一轮:让模型“听懂”
最早那会儿,大家的核心焦虑是:怎么说,模型才能懂?
这事儿在今天听起来有点好笑,但在 GPT 刚出来的时候,真是个难题。那会儿模型虽然大(1750 亿参数),但你要不会“说话”,它就给你胡编。后来大家发现,给几个例子(few-shot),或者让它“一步一步思考”(Chain-of-Thought),效果会好很多。
所以那时候,整个行业都在研究措辞。角色扮演、例子排列、语气拿捏——全是为了让模型准确理解你的意图。
我那会儿做的合同提取和图片识别,就是这种路子。核心能力就是写 prompt,核心瓶颈也是写 prompt。
为什么?
因为模型虽然听懂了,但它身上带着四个硬伤:
第一,没记忆。 每次对话都是从头开始。你跟它聊了十轮,它也不记得第一轮你说了什么。
第二,没知识。 它脑子里只有训练时学过的东西。你公司的业务数据、行业规范、历史记录——一概不知。
第三,吃不了长的。 输入一长,中间段它就“失忆”。后来学界还专门给起了个名,叫“Lost in the Middle”。
第四,只能动嘴。 它输出文字,然后呢?没了。它不能操作任何系统,不能改数据,不能发通知。
模型听懂了,但它对你的业务一无所知,也没法帮你干任何实际的事。
这就引出了第二轮。
第二轮:让模型“看全”
Prompt 时代留下的核心问题是:你说了什么很重要,但你没说的东西——模型一无所知。
所以 Context 时代的命题变成了:在模型开口之前,你得先把正确的信息放到它眼前。
这不再是措辞问题,而是信息架构问题。
那段时间主要在干嘛呢?两件事。
第一,疯狂堆上下文窗口。Claude出100K,Gemini出1M,Llama 从 8K 一口气拉到 128K。各家都在比赛“谁家模型能一次吃更多”。
第二,RAG(检索增强生成)爆发。与其把所有东西都塞进去,不如动态找到最相关的那几块内容放进去。这样既省窗口,又准。
有个事我记得很深。2025年,有家电商平台的技术负责人公开说:“我们已经淘汰了提示词工程师岗位。”他需要的不是会写prompt 的人,而是会设计上下文架构的人。
我那个催缴清单的项目,就是在这个背景下做的。
复杂的根本不是prompt,而是怎么让模型“看到”正确的数据。 要考虑的东西变成了:哪些数据要放进去?欠费金额、逾期天数、历史缴费记录……怎么组织?是按户聚合还是按时间线排?窗口不够怎么办?要不要分批?
我当时最大的感受是:我不再花时间调 prompt 的措辞了,我在画上下文的结构图。
模型还是那个模型,但因为它“看到了”缴费历史,它做的判断比之前准确太多了。
但做着做着,新的问题又冒出来了:
模型能看全了,但它只能看,不能干。
它理解了业务,但它不能改数据、不能发通知。每一次都是“你喂它一口,它答一句”——你不推,它不动。
说白了,模型像是一个什么都知道但什么活都不干的顾问。
这就到了第三轮。
第三轮:让模型“做到”
Context 时代留下的核心问题是:你让模型看到了全部信息,但它只能“动口不动手”。
所以 Agent 时代的命题变成了:怎么让模型从“理解”变成“执行”,从“回答”变成“完成”。
这不是信息架构问题了,这是系统控制问题。
2025 年,几个关键节点让这个事成为可能:
Anthropic 出了 MCP 协议,模型终于有了标准化的方式去调用外部工具——相当于给它装上了“手”。
Google 出了 A2A 协议,不同的Agent 可以互相通信——相当于给了它们“社交能力”。
2025 年被称为 “AI Agent 元年”。许多公司开始建设自己的 Agent 系统。
有个趋势很值得关注:随着系统越来越复杂,选哪个模型已经没那么重要了,重要的是你怎么搭这个系统。有分析指出,模型本身对最终效果的“边际贡献”在持续下降,系统工程能力——上下文管理、工具编排、容错机制——正在成为决定成败的关键。
我做员工智能助手的时候,感受特别深。
它的核心不再是“写 prompt”或“设计context”,而是搭一个能让模型自主做事的闭环:
- 感知:员工问“帮我查一下上个月的任务执行情况”
- 规划:模型得自己拆解——先查任务执行数据 → 再比对考核规则 → 然后整理异常列表
- 执行:调用 API 拿数据 → 调规则引擎做判断 → 生成报告
- 反馈:把结果呈现出来,再追问一句“要不要采取补救措施?”
每一步都可能出问题:
- 系统超时了怎么办?
- 数据权限不够怎么办?
- 模型判断错了怎么办?
所以我关心的不再是“模型答得对不对”,而是整个系统能不能可靠地走完一整个流程——还要考虑怎么容错、怎么重试、什么时候让人工介入。
当然,Agent 也带来了全新的头疼问题:
- 模型现在能动手了,但如果它动错了呢?
- Prompt 注入攻击的杀伤力指数级上升。多步推理链里一步错就步步错。它自主做了决策,出了问题能不能追溯?
- 多个 Agent 一起干活,谁来管?
模型终于能做事了,但你还不敢让它放手去做。
所以这三轮到底在干嘛?
把它们放一起看,其实特别清楚:
第一轮(Prompt): 解决“模型听不懂人话”的问题。
→ 留下的新问题:它听懂了,但它记不住、不知道、干不了。
第二轮(Context): 解决“模型对你的业务一无所知”的问题。
→ 留下的新问题:它终于知道了,但它只能看不能干。
第三轮(Agent): 解决“模型只能动口不能动手”的问题。
→ 留下的新问题:它能干了,但安全、可靠、治理这些事还没跟上。
三轮的核心命题分别是:怎么说 → 给什么 → 能做什么。
它们不是彼此取代的关系,是层层叠加的。Agent 系统里要有 Context 管理,Context 系统里要有 Prompt 设计。每一层都在解决上一层的遗留问题,同时暴露出新的问题。
这跟软件工程的演进很像——汇编 → 高级语言 → 框架。后来的不是替代前者,而是在前者上面加了一层新的抽象。
这条线背后是什么规律?
回头看,每一次跃迁,都需要两个条件同时到位:
场景复杂度到了,模型能力也到了。
2023 年让你做员工智能助手,做不出来——模型推理能力不够,工程生态也不成熟。
2026 年你还在调prompt 做合同提取,也不是不行,但你的天花板已经不在这里了。
这事其实挺残酷的:你不进化,但行业在进化。去年你还在研究怎么写 prompt 才能让模型输出 JSON 格式,今年已经有人在搭多 Agent 协作系统了。
有个判断我觉得挺有参考价值的:Gartner 预测到 2026 年底,40% 的企业应用将集成 AI Agent。 这已经不是“要不要做”的问题,而是“怎么做得比别人好”的问题。
那你现在在哪个阶段?
如果你还在纯写prompt,是时候抬头看看 context 和 agent 了。
如果你已经在搭Agent 系统,恭喜你踩在了节点上——但安全和治理的硬骨头很快会啃到你。
如果你跟我一样是从prompt 一路干过来的,那这篇文章应该帮你理清了一点:这三年你没白干,每一步都是下一层的基础。
最后说一句:
模型在迭代,场景在变复杂,但底层逻辑一直没变——每一次都是“模型的能力往前走了一步,然后工程范式追上去,把这种能力锁死在系统里。”
认清你在哪一层,比你用什么模型重要得多。
本文由人人都是产品经理作者【王耑】,微信公众号:【职场产品人】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。









从运营角度看,Agent引入后需要考虑人机协作流程——什么环节让模型自动做,什么节点需要人工复核。过于自动化可能导致失控,过于人工又浪费模型价值。
用户其实不在乎背后是Prompt还是Agent,他们只关心结果准不准、快不快、会不会捅篓子。所以每次跃迁最终得落到体验上,不能只炫技术。
这三轮跃迁有点像从教一个人听懂指令,到给他一份完整背景资料,再给他一双手去干活。但给手之后,还得教会他什么该碰什么不该碰。