
 起点课堂会员权益
起点课堂会员权益AI PM跳槽实录:半个月38场面试 + 一套Claude工作流 = 13个offer
在半个月内密集面试38家AI产品公司后,这位面试狂人将海量实战转化为一套高效复盘系统。从Claude驱动的真题库构建到本地化H5工具开发,他揭示了如何将面试转化为免费行业调研,并提炼出AI产品经理核心能力——技术翻译力。这套方法论不仅产出13个offer,更重塑了职业准备的全新范式。

先报数据
这是我iPhone日历上部分约面记录的截图。
我数了下,过去半个月左右我一共面了38家AI产品公司。
加上周末,平均每天2-3场,最离谱的一天面了6场。晚上第6场结束我对着摄像头说谢谢面试官的时候,已经有点记不清早上前几家是谁了。
面完之后我没急着躺平。
我把每一场的录音录屏,全都喂给了Claude。
半个月之后我手里多了几样东西。
- 一份154道的真题库,按14个维度分好类。
- 一份Claude给我写的答崩名单,精确到哪句话答得稀烂。
- 一个能本地浏览的可视化H5,可以面试前快速过一遍。
当然offer也拿了13个。但今天不聊offer。我想分享更有意义的一个心得。
当我真的在一个行业里面够38家的时候,我发现“面试”这个词的含义会变。心态上,面试不再是我被人挑的过程,而是变成我薅了38场免费的、对方还得说真话的、强制陪我聊1小时的——AI产品行业咨询。
我每天大量接触的这些面试官,都是离市场前沿需求最近的人。他问出口的每一个问题,背后都在告诉每个AIPM你当下最需要具备的能力。前提是得有点办法把对话沉下来。不然两周后就只记得”那个面试官好像戴眼镜”。
下面就是我的办法。
为什么我敢半个月海投上百家,面38家
这个问题被我朋友问了无数次。
不做准备就直接面,你不是浪费机会吗。
我的回答分两层。
- 表面那层是装的——面试是最好的市场调研,刷题刷不出来。
- 里面那层是真的——我一开始也是想准备的。
买了课。看了”AI产品经理100问”。把豆包Qwen的模型参数背了一遍。准备了两周。
某天晚上我盯着PDF发呆,突然意识到一件特别破的事。
我其实连市场到底在招什么样的AI PM都没有真的弄清楚,因为我没真的接触过,背那种网上的通用准备资料,万一背了根本没用咋办。
招聘JD全是一个模板抄出来的——懂大模型、有项目经验、能跨团队协作。这话约等于没说。
去找文章看。文章都是半年前甚至更早写的,AI圈半年等于半个世纪。
去问前辈。前辈他入行的时候GPT image 2也还没出来。
二手信息全部不可信。
唯一能拿到一手数据的办法,是把自己投进去。
所以我做了一个有点疯的决定。
不准备了。直接面。
把面试当成一个免费的、能强制对方陪我聊1小时的、对方还得说真话的——市场调研。
事后证明这把赌对了。
我面到第8场的时候,”为什么选RAG不选微调”这道题已经被问了5次。
这意味着什么。
意味着这道题是行业共识,不是某家公司的偏好。所有候选人都会被问。
我立刻停下来打磨这道题的答案。后面30场,这道题再也没翻过车。
如果我闷头准备2个月再开始面,我可能要面到第40场才意识到这题这么重要。
但密度也有代价。
代价是人会变成驴。
每天2-3场高强度对话灌进脑子。48小时之后你只剩”那家公司面试官挺凶的”这种感觉。你想复盘,根本想不起来对方问了啥。一周之后回头看,你不知道自己面过谁。
不沉淀,38场就是38场原地踏步。
所以我搞了套东西。
整套东西长什么样
我先把这套流程画出来。
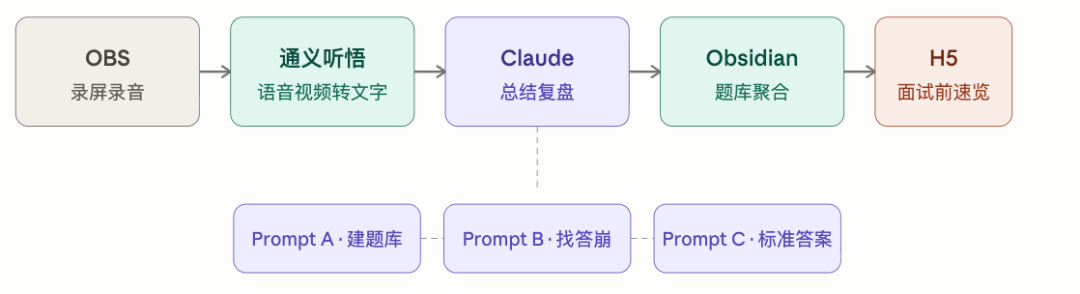
单场面试的复盘时间,控制在40分钟以内。
下面拆开讲,附我真在用的prompt。
录屏录音这一步——5分钟设置
线上视频面试用QuickTime或者Mac自带的屏幕录制。电话面试用手机录音,配合电脑通义听悟实时记录。
这里有个特别多人踩的坑。
Mac原生屏幕录制默认不录系统声音。你录出来只听得见自己。听不见面试官提问。得装一个BlackHole或者用OBS才能录到系统声音。
我第一场面试就栽在这上面。下午面完信心满满,晚上打开录屏一听——一片寂静。只有我尴尬的自言自语。
还有一个小细节。
每场录音开头我会对着麦克风说一句”今天是X月X日,面试X公司X轮”。后期整理素材的时候,这一句话能帮我省10分钟找文件的时间。
伦理上我自己有条线。这些东西全程自用,不外传,不公开,不挂网上。
转文字这一步——不要亲自读,直接发Claude
录屏文件拖进通义听悟网页版,自动转写,自动区分发言人,自动出摘要。免费额度对一个月38场的频率刚好够用。
转写出来的文本我不读。
一场1小时的面试,转写出来大概1.5万字。读完得20分钟。我直接进下一步。
这里是反直觉的地方。很多人以为复盘就是”把面试再听一遍”。错了。听一遍是没有信息增量的,基本只是让你重温尴尬。真正有价值的是让Claude站在第三方视角,告诉你哪里答崩了。
Claude三件事——本文核心
我把同一份转录文本,让Claude跑三轮,每轮只做一件事。
关键是分开跑。不分开跑Claude会偷懒,三件事混在一起做,每件都做得不深。
Prompt A:让Claude给我建题库
你是一名资深AI产品经理。下面是我面试[公司名/匿名代号]的完整转录。请你完成两件事:
1. 提取面试官问的所有问题,原样列出,不要改写
2. 给每道题打两个标签
– 类别:从【AI产品认知 / 项目深挖 / 技术理解 / 数据指标 / 商业判断 / 行为面 / 价值观 / 反问】中选
– 频率推测:基于这道题的开放性和通用性,判断它在其他公司被问到的可能性高/中/低请用表格输出。[粘贴转录文本]
跑完之后,我把输出表格复制进Obsidian的题库文件,按类别分目录归档。
一个月攒下来,154道题就是这么来的。
Prompt B:让Claude骂我
这一步是整个流程里最有用的,没有之一。
你是一名严格的AI产品面试官,刚刚面完我。
下面是我的简历/项目[粘贴简历/项目],和刚才的面试完整转录[粘贴转录]。
请你针对其中我答得最差的5道题,做以下分析:
1. 我的回答里,哪一句话/哪一段是答崩的关键?精确引用原话
2. 面试官真正想听的是什么?请站在他的角度还原他的考点
3. 基于我的简历项目,正确的回答应该怎么组织?
请用STAR结构注意:不要安慰我,不要说”整体回答不错”。直接指出问题。
这个prompt的关键有两个。
第一个关键,必须喂简历。
不喂简历的话,Claude给的答案是网络通用模板——”你应该用STAR结构,先讲背景再讲行动”。这种废话有手就能写。
喂了简历,Claude会精确指出:”你刚才那段答得不行。其实你的XX项目里有现成的例子——从48%提到61%的留存数据——但你没拿出来。你应该把这个数据当成回答的锚点,前面铺背景,后面收价值。”
这种诊断才有用。
第二个关键,不要让Claude安慰你。
“注意:不要安慰我,不要说整体回答不错。”——这一句一定要加。不加的话Claude默认温柔模式,会说”你这个回答其实挺有亮点的,但如果能再补充一些XX就更好了”。这种废话比没有还糟糕,因为它让你以为自己答得不错。
要让它直接指错。”你这句答崩了。”——就要这种高效的反馈。
Prompt C:让Claude给我标准答案
基于Prompt B的诊断,请把这3道题的”我应该这么答”版本,写成可背诵的回答稿。
要求:
– 每道题不超过200字
– 用第一人称
– 必须带至少1个数据
– 必须带至少1个我简历里的项目细节
– 结尾要有一个反问句或开放点,给面试官追问的钩子
最后这条”结尾留钩子”特别重要。
很多人答完最后一句是”嗯,我大概就是这么做的”——句号一打,对话结束。面试官只能再憋一个问题。
但如果你结尾留个钩子——”这里其实有个我自己也没想清楚的点,您怎么看?”——面试官会顺着你的钩子追问,而你已经准备好了下一段。
整场面试的节奏感就出来了。
这3版标准答案,让Claude给你复制进Obsidian同一道题的条目下,标注”标准答案v2″。下次面到类似题,开口前心里有底。
题库聚合这一步——每周做一次
跑了一周之后,我会把所有Prompt A的产出汇总,让Claude再跑一次:
下面是我这一周面试沉淀的47道题。请:
1. 找出被不同公司重复问到的题(频率≥2),标为”高频”
2. 找出问法不同但本质相同的题,合并归一
3. 重新做一次类别分布统计[粘贴所有题]
跑完之后我知道几件事。
这一周我的弱项类别在哪里。哪些题被反复问,需要立刻打磨。哪些题虽然新奇,但只有一家公司问——可能是面试官的个人偏好,性价比低,剔除。
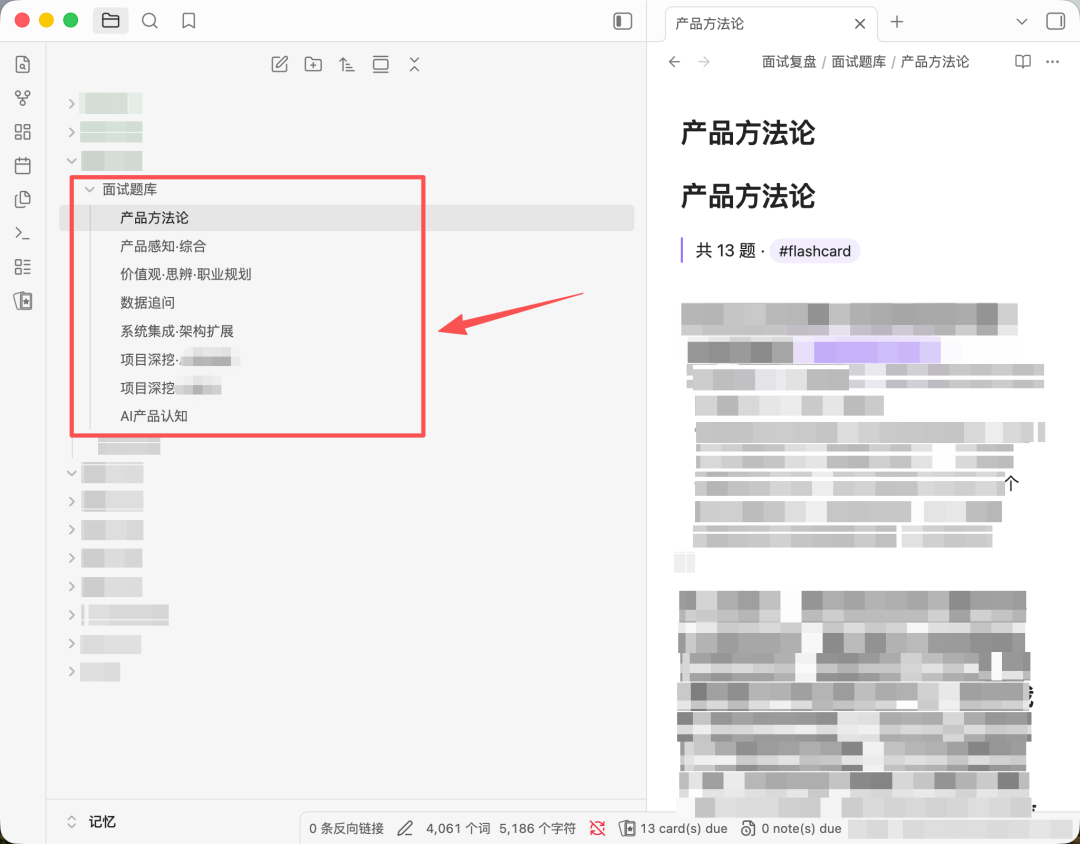
跑到这一步,154道题已经躺在Obsidian里了。
每道题都有原题、有我答崩的关键句、有Claude给的标准答案、有它在哪场面试出现过、被问了几次。
这个题库对我自己来说够用了。
为啥做H5页面,以及我具体怎么做出来的
154道题在Obsidian里躺着,对我有用,但马上有了下一个问题。
154道题、14个分类、每道题底下还挂着我答崩的句子、Claude给的标准答案、它出现在哪场面试。这些东西在Obsidian里是一堆md文件。文件之间靠链接互相跳转。我用着没问题。
但有几个具体的痛点,Obsidian解决不了。
第一个,面试前的咖啡店里、地铁上,我没法快速翻题。Obsidian对我来说不够顺手——打开慢、找文件慢、跳转慢。我需要的是一个能在90秒内扫过20道高频题的东西。
第二个,我没法按“今天面的这家公司”去过滤题库。比如下午面一家做教育AI的,我想看一下“AI产品认知 + 项目深挖 + 数据归因”这3类的高频题。Obsidian里我只能一个一个文件夹翻。
我需要的是一个3分钟扫完、双视图(项目维度+问题类型维度)、可搜索可筛选的载体。
H5就是答案。
具体怎么做的——直接让Claude生成HTML文件,存在本地,需要的时候直接在浏览器打开。
那么具体H5上有什么。看下图。
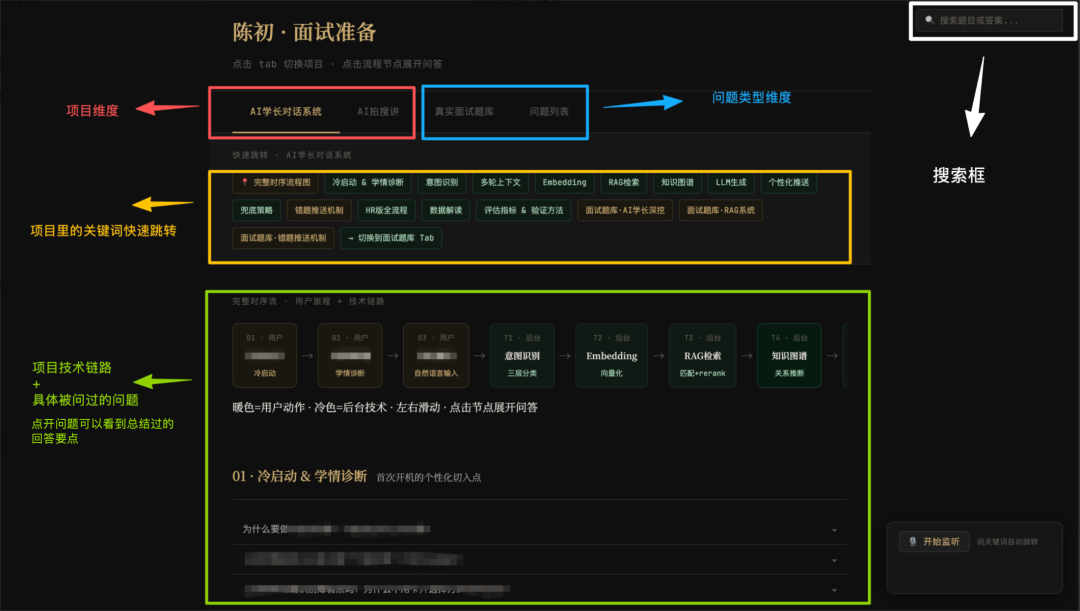
视图一:按问题类型浏览
154道题按14个分类折叠展开,每道题标好频率。我想看哪类点哪类。
视图二:按项目维度浏览
我的两个项目AI学长和AI拍搜讲,每个项目一个独立模块,里面装着完整的时序图、技术架构、关键数据解读、项目深挖问答。
顶部搜索框
随口想到一个关键词——”RAG”——秒定位到对应问答。
H5真正改变的不是面试现场,是面试之前的那15分钟。
之前我面试前15分钟,是在地铁上翻Obsidian、翻简历PDF、翻聊天记录里的JD要点,手忙脚乱。
有H5之后,我面试前15分钟只做一件事——打开H5,按”今天这家公司可能问的类别”筛一遍高频题,每道题花30秒过一遍我的标准答案。
15分钟,覆盖15-20道高频题。
进面试间的时候,我脑子里是热的。
这是H5对我最大的价值。
它不是用来给别人看的。它是用来让我自己在面试前的最后15分钟,把过去沉淀的所有东西,快速重新加载到大脑里的工具。
而且,做H5这件事本身,还顺便逼着我做了一遍系统化整理。
我从Claude生成HTML,到迭代视图、加交互、做搜索——整个过程逼我把所有项目、所有真题、所有答崩点结构化梳理了一遍。
做H5的过程,比H5本身更值钱。
这是我后来才意识到的。
写到最后我想说三件事
写到这里我自己也累了。
但我想把这半个月月38场面试的最大收获,写成三句话吧。
第一句——不要刷题,要刷被问的密度
刷题的本质是用低质量的二手信息做准备。
而面试现场被问3次以上的同一道题,是市场真实信号。
前者ROI低。后者ROI高。
密度本身就是最好的准备。
这一点我之前不信。
我一开始也是那种”准备好了再投”的人。背模型参数、背产品框架、背案例分析。结果发现,背的东西很多都用不上。真正用得上的,是面试现场被问到的真实问题——而这些问题,你不亲自下场永远不会遇见。
后来我把”准备”的定义改了。
准备不是闭关刷题。准备是让自己进入一个能持续被问真问题的状态,然后用流程把每次被问的真问题,沉淀成下一次的准备材料。
这是一个自我加强的循环。
面得越多,你越知道市场要什么。你越知道市场要什么,你下一场就答得越准。下一场答得越准,你越能拿到offer或者更深入的对话。越深入的对话,给你越多的真问题。
闭关刷题刷不出这个循环。
第二句——简历不是终点,是Claude的输入
绝大多数人写完简历,扔进招聘软件,就忘了它的存在。
但你的简历应该有第二个生命。
它是你后续所有AI辅助复盘的上下文。
Claude没有你的简历,给的建议永远是网络通用模板。喂了简历,Claude才能告诉你”你这个项目里其实有现成的答案,你刚才没用上”。
写完简历不是结束。写完简历,才是Claude的开始。
这件事换一个角度看——
你的简历其实是你自己的”个人知识库”的第一份语料。
很多AI PM都在帮公司做RAG知识库。但极少有AI PM意识到,自己应该给自己也建一个RAG知识库。
- 你的简历是第一份语料。
- 你的项目复盘文档是第二份语料。
- 你的面试转录是第三份语料。
- 你的Obsidian笔记是第四份语料。
当这些语料喂给Claude,它就不再是一个通用助手,它变成你的个人面试教练。
这个教练知道你做过什么项目、踩过什么坑、答崩过哪道题、被反复追问过哪个数据。
它给的建议,比任何线下mentor都要精准,而搭这个教练的成本是0元。
第三句——AI PM的核心能力不是懂技术,是翻译
154道题里,纯技术题不到40道。
剩下100多道,全是”为什么选这个不选那个”、”怎么证明你的改动有效”、”跨部门怎么推”、”数据怎么解读”、”用户痛点怎么挖”。
这些题,传统PM也会被问。
区别只在于,AI PM要在AI这个新变量下重答一遍。
你不需要变成算法工程师。
你需要的是——能听懂算法工程师在说什么,并把它翻译成业务能听懂的语言、用户能感受到的体验、老板能算得出的账。
这是AI PM在2026年真正稀缺的能力。
我本科刚毕业的时候是审计出身,后来才转了PM。其实审计的工作本质也是翻译——把企业的财务行为,翻译成符合会计准则的语言;把会计准则,翻译成审计意见;把审计意见,翻译成投资人能看懂的报告。
最后转AI PM的时候,我以为我要重新学一遍——学大模型、学Transformer、学Python。
学了一阵发现不对。
我真正要做的,还是翻译。
只是翻译的语言变了——从财务变成了AI,从准则变成了模型能力边界。但翻译的本质没变——把一个领域里精确但晦涩的东西,转换成另一个领域能用的东西。
这个本质一旦想清楚,AI PM就没那么难做了。
写在最后
其实我做这套流程的初衷,根本不是为了写这篇文章。
我做它就是因为——这半个月的事儿我不记下来、不输出我真的会忘。我面完第二天就会忘。我必须有点办法把记忆固化下来。
最开始这套流程很糙。
开始我只有录屏,没有Claude介入。
后来才加进Prompt A,开始让Claude帮我归类题目。
再到后来才发现Prompt B必须喂简历,否则Claude给的全是通用废话。
最后才意识到题库需要每周聚合,否则会变成一个无序的文件堆。
它不是一开始就长这样的。
它是面着面着,长出来的。
如果你也在找AI PM的工作,我希望你别学我具体的流程——你应该长出你自己的。
但你可以学这个心法——把每一场对话都当资产,而不是消耗。每一场都是你未来某场面试的预备材料,也都是你给Claude的训练样本。这事比你刷100道题都有用。
写完了,希望对每个AIPM都有用,谢谢~
本文由 @AI观察者陈初 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议









感谢,提供了一个很好的思路
我好想夸夸你,你很棒!也给我提供了一个自我进化和提升的思路哈
加油
能分享一下154道题吗
小白跪求大佬面试题,谢谢了。malongzhao@gmail.com
能分享一下154道题吗 哈哈
每个人简历不一样遇到的面试问题不一样