
 起点课堂会员权益
起点课堂会员权益对话机器人平台智能问答技术拆解
笔者对智能问答机器人技术进行了分析,从实际场景切入,阐释其功能逻辑。

个人计算机的发展史要追溯到上个世纪90年代末,人们用键盘和鼠标向购物网站发送请求,购买心仪的商品,随后的十多年间,互联网飞速发展,智能手机应运而生,人们开始习惯用触摸的方式更加灵活地操纵手机、Pad等设备,可与之进行交互的产品也稳步落地在数以百万计APP中,这些产品都是基于GUI (Graphical User Interface)设计的。
鉴于人类向外界发送指令的方式除了用手做(以键盘鼠标、触摸为代表),还可以用嘴说,因此语音控制设备进行人机交互也开始进入人类探索的领域。
然而,让机器听懂人类的语言是一件十分困难的事,近几年随着深度学习的崛起,语音识别和自然语言理解的快速发展,为这一交互模式的流行创造了可能,相信不久的将来,人类会逐步迈入CUI (Conversational User Interface)时代。
智能问答简介
在我们的生活中,智能对话被广泛应用在客服、营销等重复性对话频繁发生的场景,或者作为GUI的补充,为用户提供高效、个性化的体验,甚至是直接集成到智能音箱、智能家居、智能导航等硬件设备中,独立承载人机交互的重担。
按照对话的智能程度,我们可以把智能问答分为5个阶段:单轮问答、多轮会话、意图推理、个性化以及情感互动。
而从问答的种类来讲,我们又可以将其分为Community QA、KBQA、TableQA、PassageQA、VQA这5大类。
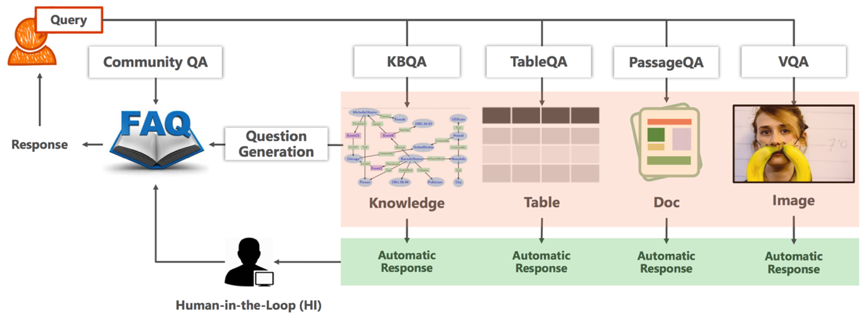
图1 智能问答领域分类[Duan 2017]
- KBQA:基于知识图谱的问答,所有的知识被组织成三元组的形式,比如<姚明、妻子、叶莉>这个三元组是知识图谱里的一条知识,当用户询问“姚明的妻子是谁”的时候,问答模型会将答案定位到“叶莉”;
- TableQA:知识是用表格的形式组织的,商家的产品信息用表格的形式存储,当用户询问关于某个产品的具体属性时,问答模型可以把用户的自然语言转化成SQL查询语句,直接从数据库里定位答案;
- PassageQA:阅读理解,它是基于文档的问答,我们的问答模型会基于用户的问题,将答案定位在文档的某个段落、某句话甚至是某个短语;
- VQA:基于图像或视频的问答,以上图为例,用户问“这个女孩儿的脸被什么挡住了”,问答模型会告诉我们答案是“香蕉”;
- Community QA:从命名上来看,它是基于社区知识的问答,比如一个读书论坛,底下有人在交流值得一读的人工智能书籍,在母婴论坛有人在讨论宝宝发烧了怎么办?需要吃药吗?那么这些对话内容都可以沉淀为知识,我们定义的Community QA就来源于这些场景,在不同的领域,我们通过挖掘、或者收集、标注的方式沉淀了一批知识,用问答对的形式把它们组织起来,在这批知识集合下,用户提问一个领域相关的问题,问答模型会告诉我们答案到底是什么。
智能问答工程实践
面对智能问答的广泛应用,本篇文章以如何搭建一套智能问答系统为切入点,深入浅出介绍一下在Community QA上所做的尝试。
1. 业务简介
我们再基于几个实际的例子看一下问答的使用场景:
- 第一类是常见的客服场景,询问产品、询问业务、询问经验,这类场景比较泛,他会衍生在生活中的各个方面,客服机器人相比传统的客服,他永不打烊,回答永远标准,而且面对各种刁钻甚至不友好的问题,都会永远积极正面地给出响应。
- 同时,该类问答机器人进一步深化拓宽到领域,会孵化出某些领域通用的机器人,比如HR领域,相信不同公司的HR,很大程度上面临的问题集合都是固定的,也就是说,垂直领域的问答机器人是可以有效渗透并横向复制给不同企业使用的。
- 在英语学习相关产品上,我们想给小孩报名英文课,但是不清楚课程内容和价格,那我们会问相关的问题。对于商家来讲,我们不仅是提问的人,还是潜在的商机,可能我们仅仅只想问一个问题,但是商家却希望能获得我们更多的信息,电话、小孩年纪、上课意向等,进而让我们留存下来最后能成功消费,类似的场景还有很多,我们把这一类应用场景叫营销机器人,它是商务团队的好帮手,能在多个平台自由切换,回答问题标准且及时,最终往往能通过更小的人力投入,获取更多的有效线索。
2. 问答建模
基于前面的例子,我们对问答场景有了更具体的画像,需要做什么已经很清晰了,那么怎么做呢,我们开始尝试对该问题进行建模。
首先是对知识的结构化表示:
- 用户问题我们用q表示;
- 一个问答对表示一条领域知识,我们把它叫做一个知识点ki;
- 答案我们定义为ai;
- 由于一个语义的问题可能有多种不同的表述方式,因此一个知识点的问题由多个不同的表述组成,这些表述都叫相似问pij;
- 一个领域的知识库,由多个知识点构成。
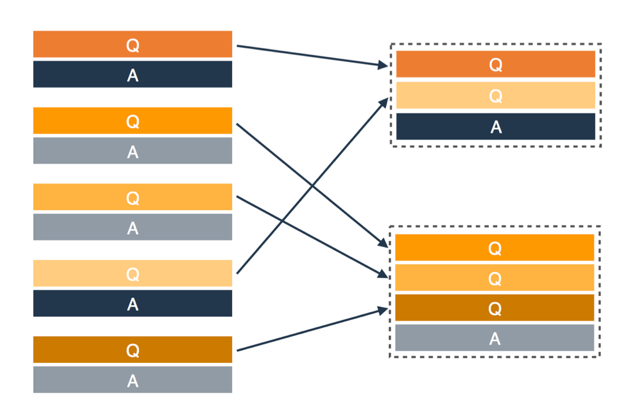
图2 知识库表示
我们为什么要用这种方式来管理知识,不用图表、也不用表格?
实际上,知识的管理方式是来源于实际业务场景的,这种方式非常易于维护,多个同义问题用一个知识点管理,也能减轻维护答案工作量,同一知识点下的问题也将会是很好的训练数据。
现在有了领域内知识库,用户提问后,我们还需要一个问答模型,这个模型能找到和用户query最匹配的问题,进而给出对应的答案,这里我们采用检索+匹配+排序的架构。
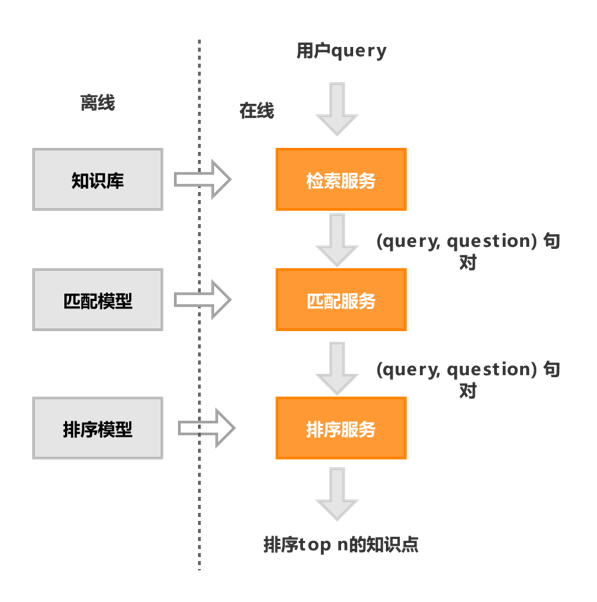
图3 问答建模流程
下图是基于知识库和问答模型在母婴场景的应用举例:
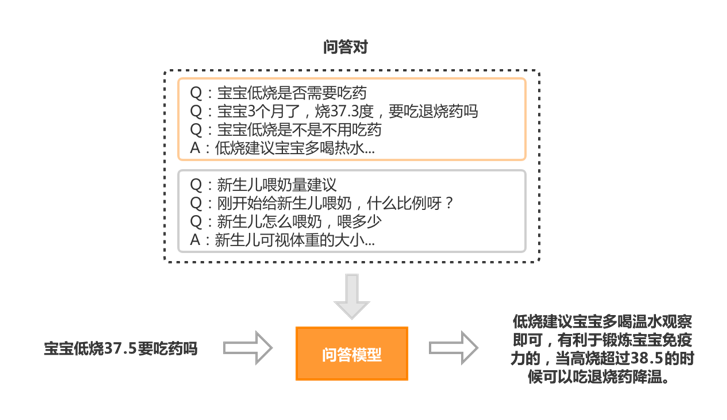
图4 QA应用举例
3.数据储备
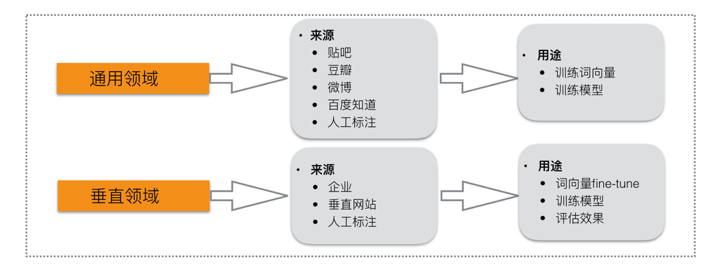
图5 数据类型分布
在正式开始问答模型构建之前,我们需要思考目前有哪些数据可被我们使用,以及我们需要什么数据来支撑后续的工作。
通用领域的贴吧、豆瓣、微博、知道等问答数据,可被用来训练词向量,或是统计共现、互信息词典;人工标注的q/p对,可被用来训练有监督的分类模型;垂直领域的知识库可被用来训练领域相关的分类模型,也可用作词向量的fine-tune,当然也是有效的评估数据。
4. 模型迭代
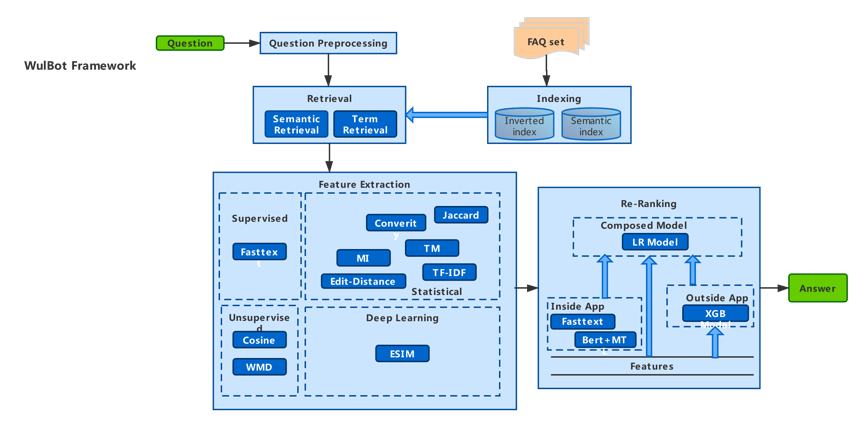
图6 QA架构图
整体的QA架构图如图6所示,下面我们简单介绍一下历次迭代的思路。
1. BoW+LR
第一次迭代我们只引入了词袋(Bag of Words)模型,5维代表特征。
- Jaccard:q和p词交集个数与词并集个数的比值;
- Coverity:最长公共子串特征,q和p最长公共子串在p中的占比;
- Edit-Distance:最小编辑距离,q和p的最小编辑距离除以q、p长度的平均值;
- TM:共现特征,基于bigram/trigram词典,计算q、p共现词平均score、共现词最高score的平均值、共现词去除相同词后最高score的平均值共3维特征;
- MI:互信息特征,基于互信息词典,计算q、p两两词的互信息平均值。
上述特征集合,均由大数据文本的统计特征衍生而来,对句子的语义表示能力较弱。
2. BoW+WE+LR
第二次迭代我们给模型引入了一定的语义表示能力,对于了解深度学习、自然语言处理的同学来讲,word2vec在很多任务上都有着非常杰出的贡献,这一模型从不同角度刻画了周围词和当前词的关系。经过训练后,我们能得到一份词汇的向量表示。
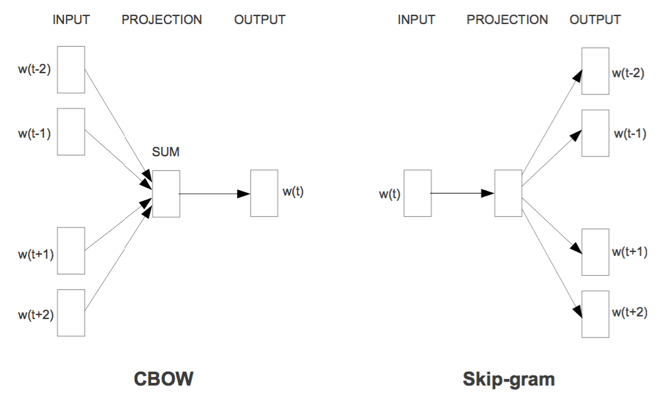
图7 word2vec的2个模型
基于训练得到的词向量,我们采用IDF对词向量进行加权平均,以此得到q、p词粒度的句向量表示,并最终通过余弦相似度来度量两者的语义相关性。
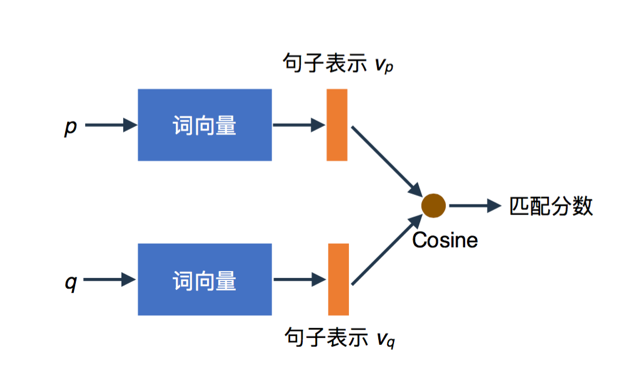
图8 基于句子表示的w2v特征
通过余弦相似度给出的相似,本质上描述的还是两个词的相对一致,而且word2vec不考虑词序,余弦相似度大表示两个词搭配出现、或者和同一批词搭配出现的可能性较大,这一特征所显示出来的弊端就是往往相似度高的2个词具有可替换性但却语义不完全相同。
比如q=“宝宝感冒怎么办”,p=”宝宝发烧怎么办”,”感冒”和”发烧”互相替换,句子依然具有合理性,而且由于他们经常在同一批词汇中搭配出现,具有比较相似的分布特征,相关性比较高,然而他们语义并不同。
接下来我们引入另一种语义度量方法:WMD (the Word Mover’s Distance),它刻画了如何用最小的代价将q中的每个词以不同权重匹配到p中每个词上,这是一种基于句子间的交互来表示语义的方法。
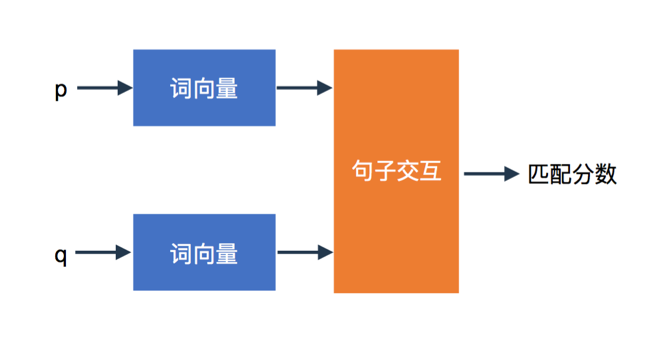
图9 基于句子交互的WMD特征
在利用WMD计算q/p的相关性时,我们会对句子进行切词、去停,对于q中的每个词,找到p中的另一个词,进行语义转移,转移的代价我们用两个词汇间的word2vec余弦相似度来度量。
当2个词语义较相近时,我们可以多转移一点,如果语义相差很大,我们可以选择少转移或者不转移,最后使得所有转移的加权和最小,这里加权采用词频作为特征,具体示例如图10所示。
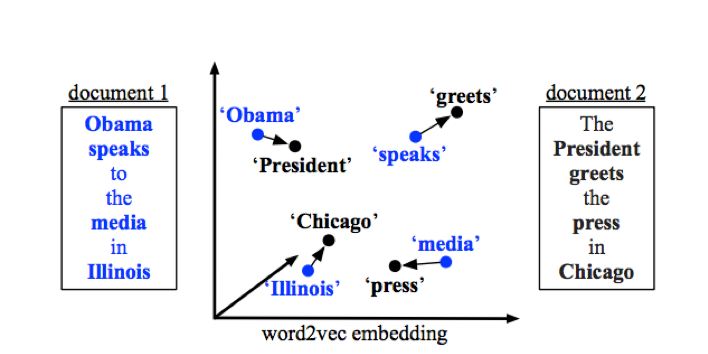
图10 the Word Mover’s Distance (WMD)
由于WMD也高度依赖word2vec词向量,因此上文提到的word2vec cosine特征所有的不足,WMD特征依旧存在,既没有考虑语序信息,同时对OOV (Out of Vocabulary)情况也很不友好,语义泛化能力弱,相似意图区分能力差。
3. BoW+WE+SE+fine-tune
前两次迭代都没有考虑知识库内的数据,比较适用于无语料或者语料较少的知识库,当知识库具有一定的规模后,正如前面提到的,同一个知识点下的相似问,将是很好的训练数据。
我们采用了fastText模型,充分利用知识点中的问题语义相同/相近这个事实作为监督信号,训练一个分类模型,直接用一个问题的词去预测问题所属的知识点。
FastText是Tomas Makolov为了弥补word2vec的某些不足而提出的改进方案,和word2vec中CBOW不同的是,它的输入不再是上下文,而是一整个句子,同时它接收子词和ngram特征,能捕捉到更多的信息。
比如单词的前后缀,以及词的语序特征等。相比其它深度学习模型,fastText结构简单,本质上是一个线性模型,不太适合处理较长或者线性不可分的样本,而对于偏线性的短文本分类任务却比较合适,能在较少训练集合的基础上,非常快速地得到不错的效果。
图11 fastText模型结构
同时fastText在训练过程中也会产生一份词向量,经实验验证,基于知识库训练fastText的词向量对基于大数据训练的word2vec词向量进行fine-tune,能一定程度上提升该领域的问答效果。
4. BoW+WE+SE+DM+fine-tune
前面我们利用一个知识库的相似问语义相近作为监督信号,从中抽取出了一个知识点的语义信息,但我们最终的目标是判断用户输入和相似问之间的相关性,这里我们使用一个深度学习的模型ESIM (Enhanced LSTM for Natural Language Inference),利用要比较的两句话的监督信号来训练模型,观察句对的交互对模型的影响。
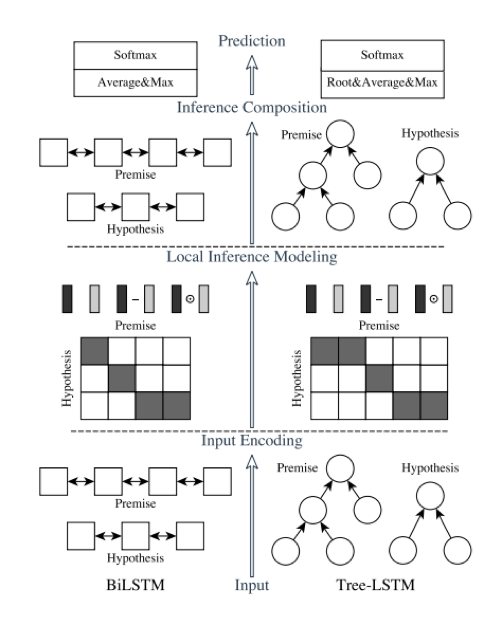
图12 ESIM模型架构(左侧)
上图是ESIM的网络结构,它在众多短文本分类任务中都有不错的表现,主要在于输入2句话分别接embedding+BiLSTM, 利用BiLSTM学习一句话中的word和它上下文的关系后,在进行inference之前,会利用attention操作计算2个句子word之间的相似度来更新embedding,也就是说比较的两句话在模型训练中产生了交互,相比其它的类似网络只在最后一层求距离来讲,这种交互的影响能学到更全局的信息。
5. BERT+MTL+fine-tune
当然,学术界是在不断变化的,对于效果较好的模型,我们也需要进行尝试,寻找适合在工业界落地的条件和场景。
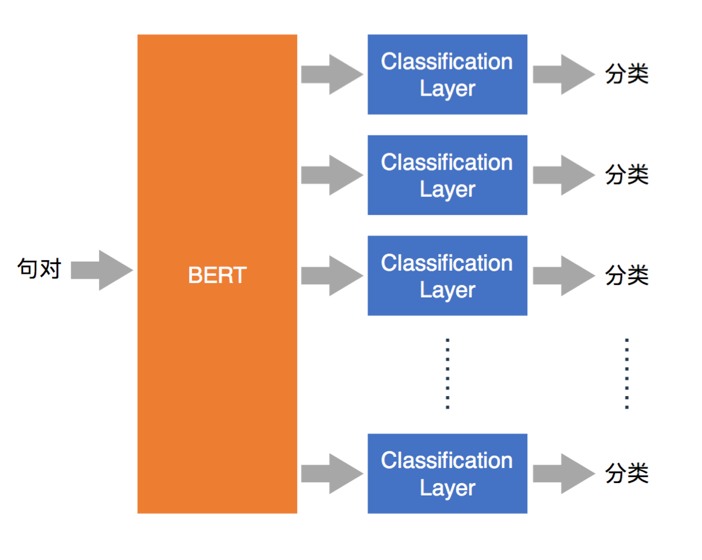
图13 BERT+多任务学习MTL框架图
在BERT横扫了11项NLP测评任务的效果后,我们把它应用在知识点分类任务上,期望利用BERT本身的优势,来提升分类任务的效果。同时我们还基于知识库数据,在BERT的基础上,通过MTL进行fine-tune,再以BERT-MTL为基础,通过单个任务分别进行fine-tune。
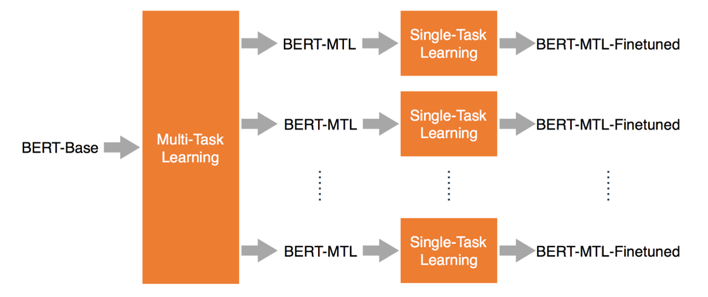
图14 BERT+MTL的fine-tune过程
5. 评估
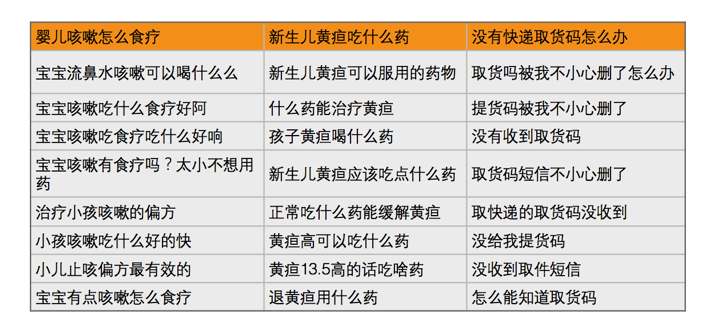
图15 评估数据举例
效果变好了,有多好?肉眼可见显然不能作为一个反馈的指标,所以我们需要去科学地评估这些改进,评估这一环节我们选了6个不同领域,每个领域50个知识点,每个知识点12个相似问作训练,3个作评估测试,示例数据见图15,在此数据集基础上去评估准召和F1。具体结果见图16,大家可以看到在不卡阈值的情况下,准确率从0.8提升到了0.968。
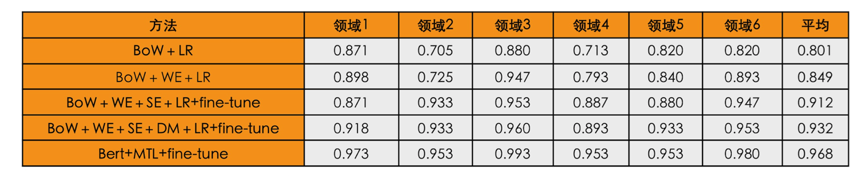
图16 历次迭代评估数据表
迭代是一个循序渐进的过程,可能有人会有疑惑,我怎么知道要用什么特征、选哪个模型,从多次迭代的经验来讲,Badcase分析很重要,特征的设计一方面来源于你对问题的直观感知。
比如我们需要从多方面(统计层面、词汇表示、句子表示、句子间交互等)来设计方法对句子进行语义表示,另一方面来源于对模型现有Badcase的弥补,通过分析case表现出来的规律或者倾向来设计有针对性的特征。
同时学术界也在不断更新新的模型,3年前时兴的技术,到现在被完全替代的可能性是非常大的,因此我们需要与时俱进。
结语
整个智能问答系统升级的过程,主要围绕四个步骤进行,首先面对任务要理解问题的本质,对问题进行合理的建模,然后评估选择合适的语言工具去实现它,再由浅入深稳步迭代,形成数据、模型、反馈的闭环,最后就是要持续性学习,拥抱变化,拥抱技术。
参考文献:
[1] Nan Duan. Building Informational Bot (InfoBot) with Question Answering & Generation. In Association for Computational Linguistics (ACL). 2017.
[2]Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013b. Distributed representations of words and phrases and their compositionality. In NIPS, pages 3111–3119.
[3] Qian Chen, Xiaodan Zhu, Zhenhua Ling, Si Wei, Hui Jiang, Diana Inkpen. “Enhanced LSTM for Natural Language Inference”. In Association for Computational Linguistics (ACL). 2017.
[4] Le, Quoc, and Tomas Mikolov. “Distributed representations of sentences and documents.” International Conference on Machine Learning. 2014.
[5] Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. Bert: Pretraining of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
[6] Xiaodong Liu, Pengcheng He, Weizhu Chen, and Jianfeng Gao. 2019a. Improving multi-task deep neural networks via knowledge distillation for natural language understanding. arXiv preprint arXiv:1904.09482.
[7] Xiaodong Liu, Pengcheng He, Weizhu Chen, and Jianfeng Gao. 2019b. Multi-task deep neural networks for natural language understanding. arXiv preprint arXiv:1901.11504.
本文由 @吾来 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议









检索匹配排序那块能详细说说不
大大大大叔大婶打算大所多群无大所大所大所大
打死