
 起点课堂会员权益
起点课堂会员权益知识图谱与机器学习如何结合?
编辑导读:知识图谱和机器学习,这两个看似不相关的事物,放在一起会发生什么样的化学反应?本文将从五个方面,阐述机器学习如何与机器学习相互作用,希望对你有帮助。

某天中午吃完饭,和一位做大数据分析、机器学习建模相关的朋友聊天,谈及到智能决策领域的增长点和突破口,目前智能决策领域已经基本业界标准化成型的,由产品&技术各组件组成的决策引擎体系,这套完整体系包括智能决策平台、批流化一体决策引擎、实时指标计算平台、风险核查平台、用户画像、数据服务、设备指纹等。
这些产品&技术已趋于成熟,均很难成为智能决策领域的突破口,机器学习、深度学习可以带来一定增长点,不过要成为突破口比较难,毕竟模型对业务来说是个黑盒子,无法解释。
就目前现状而言,模型更多用于辅助决策,还无法放心地仅通过模型预测值就真正否决掉一个用户或判断是否欺诈、是否逾期等。人们往往更相信直观可见的“证据”、人为积淀的经验、亦或通过现有知识基础推理衍生出的可解释性结论,从这个角度上看,知识图谱更可能成为突破口。
虽然图谱目前还是个新手,距离真正成为突破口还有很大差距,特别是实时决策场景,毫秒级别内决策的要求对知识图谱的性能将是个巨大的考验,不过这不妨碍大家对她的青睐和期待。
通过关系进行风险传导、智能通知预警和新营销推荐,图的可视化天然优势、基于已有知识推理出新知识,通过图表征得出异常结构和异常点等,这些都是图谱的优势。基于现阶段图谱的优势,结合上述提及的图实时计算、实时决策的短板,笔者梳理出知识图谱与机器学习结合的使用场景,并分析其如何赋能业务产生业务价值。
近3年从事智能风控决策领域,做过知识图谱产品经理,做过智能决策、知识图谱、模型管理&模型监控等相关的项目实施,因此除产品和技术外,得益于项目上的历练,也有了一些些业务思维。
结合笔者在实际的业务应用场景和期间对知识图谱、机器学习、用户画像、智能决策的理解、思考,总结出四类目前知识图谱与机器学习的常见结合场景和结合方式。
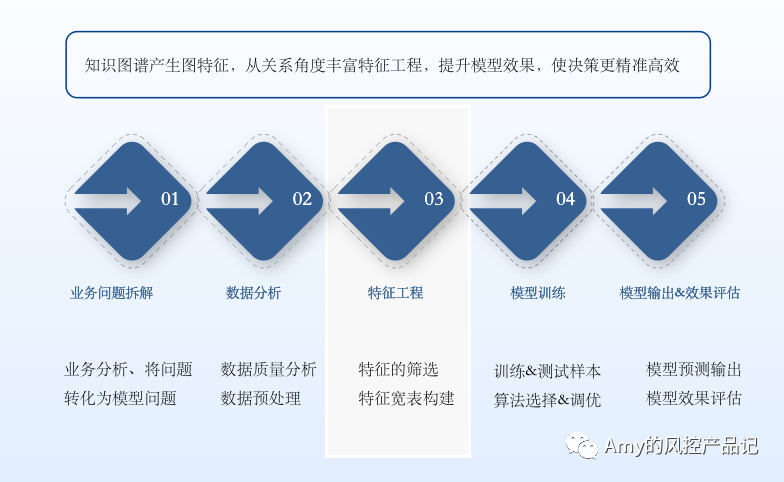
一、知识图谱产生图特征,从关系角度丰富特征工程,提升模型效果,使决策更精准高效
数据决定了模型的上限,特征宽表则从各个纬度去刻画数据特征,在机器学习过程中,特征工程的构建是建模最重要的环节之一。
常规的行为类、交易类、时序类、高频类等特征很容易从数据中挖掘,而关联类特征则需要数据分析师在脑海中推演可能的关联情况和关系网络构成,且需要通过多次join来验证,涉及三度及其以上的多度关联时,无论是脑海推演过程抑或join逻辑都比较复杂。
如果事先构建好图Schema(实体类型&关系类型及其属性),通过知识图谱直接抽取关联特征就方便很多,在实践中证明,其余条件保持不变的情况下,丰富图特征后,可以一定程度上提高模型的K-S、AUC值,某些用户画像、智能营销推荐、信贷、反欺诈等场景下效果显著。
通过图特征丰富特征宽表,全面刻画样本表现情况,提高模型效果是目前知识图谱和机器学习结合方式中最常见也是实践最多的一种方式。
二、机器学习提供学习结果,丰富和增强图谱知识,使图谱更智能化
机器学习的本质是通过学习历史数据和经验得到未来的预测结果,通过学习而得到的预测结果本质也是一种“知识”,只是这类知识的准确性是个概率值。
当我们将机器通过学习而得来的知识输入到图谱中,在一定程度上丰富和增强图谱知识,可以使图谱更智能化。
例如,在原生图数据库中,我们知道用户的基本信息,却不知道这个人的信用分、行为分、欺诈分是多少,而机器学习提供的学习结果使我们对“人”这个实体的认知更丰富了,知识图谱增强了知识储备,这个时候再通过图表征(graph embading)得到更智能化的结果。
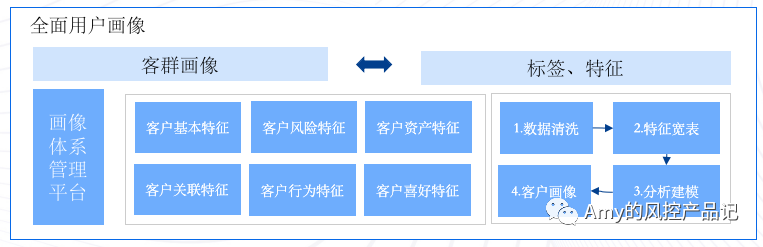
三、知识图谱结合机器学习,基于已有数据输出全用户画像
在刻画全面用户画像场景下,知识图谱和机器学习往往需要结合使用。
我们知道万事万物都由形形色色的关系构成,知识图谱所产生的关于“人”实体的标签和人与人之间的关系是“用户画像”的基本元素,机器学习、数据服务等产生的标签也是用户画像的重要组成部分。
当然在全面用户画像场景下,遵循元素越多越好的原则:关联关系越多越好,模型产生的标签越多越好,数据纬度也是越多越好。
基于知识图谱、机器学习、数据服务等综合纬度的结合,让我们更了解我们的用户,更清楚他的喜好和习惯,然后更好地为他服务(让他买买买)。

四、机器学习辅助社团划分,交叉验证定位欺诈团伙
第四种方式较适用于团伙欺诈场景,从业务视角看,一般社团划分所得社团中涉黑占比较高且社团成员数量适中的会被初步划分为可疑社团,业务人员再从可疑社团中进行逐一排查得到欺诈团伙。
然而当知识图谱进行社团划分(常见的社团划分图算法有:louvian、lpa标签传播等)的样本中没有黑样本或黑样本极少时,一方面图谱只能通过原生关系进行聚类得到社团,另一方面业务人员初步的“可疑社团”范围也无法圈定。
这个问题一般有三种解法,一是人为手工打标,通过人为经验给样本打标,该方式费时费力,一般不会采取除非资源足够;二是通过制定规则(策略)识别出黑样本或可疑样本后进行打标;三是通过机器学习模型得到可疑样本,并将阈值大于x(如0.6)的样本默认打标再输入到知识图谱中进行社团划分。
第三种解法即为本文中机器学习与知识图谱结合的第四种方式—“机器学习产生样本标签,辅助图谱社团划分,寻找欺诈团伙”。
在欺诈团伙场景,还有种结合方式是:知识图谱产生的可疑社团成员,通过模型来进行验证。
例如图谱产生某可疑社团中有200个成员,而模型对这200个成员的预测结果大多数为黑,则可大程度上认为该社团为欺诈社团。当然也可以反着来,通过模型预测得到的黑成员里,对应在图谱上的划分情况如何,有哪些成员是在图谱的可疑社团里面。通过这类交叉验证的结合方式,可以帮助我们定位可疑社团、得到欺诈团伙。
五、知识图谱产生黑名单,丰富机器学习黑样本
前文提到的“大数据分析、机器学习建模相关的朋友”说起,目前机器学习的痛点之一是缺乏黑样本、很多场景下建模无法获取黑名单,这时就可以通过知识图谱的关联关系,通过一度、二度或多度关联得到网络中的可疑名单,再加上业务专家经验得到更多黑名单,扩展后的黑名单作为机器学习(这里主要是有监督类)的标签样本输入,一定程度上可以较大提高模型效果。
相关阅读:
作者:Amy,公众号:Amy的风控产品记(Amy_fkcpj)。
本文由 @Amy 原创发布于人人都是产品经理。未经许可,禁止转载









写的真好
公众号貌似搜不到了
搜这个:xishi_mulan
不是graph embading,应该是graph embedding
哈哈 谢谢纠正笔误(笔芯)