
 起点课堂会员权益
起点课堂会员权益今天你低代码了吗?
编辑导语:当下,各行各业都在寻找可以降本增效的效率途径,AI人工智能、机器学习等概念也被广泛应用至业务中;而亚马逊云科技推出的0代码机器学习智能工具——Amazon SageMaker Canvas,就是一款可以应用于数据分析业务中的工具。本文作者就对这款工具做了体验测评,一起来看。

随着人工智能技术的发展和普及,人们对机器学习和数据分析的需求一直居高不下。几乎没有哪个行业在交易中不涉及机器学习。
在这一背景下,与许多大型科技公司一样,亚马逊云科技也推出了一款无低代码机器学习平台——Amazon SageMaker Canvas,今天就让我们来试用一下吧。
一、测评说明
- 测评人:刚毕业一年的B端产品经理,硕士毕业,计算机专业,机器学习方向;
- 测评对象:Amazon SageMaker Canvas(一款低代码机器学习平台);
- 测评目的:对产品的可操作性(用起来方不方便)、预测准确性(好不好用)进行测评。
二、使用体验测评
1. 对没有机器学习知识的人友好
作为一个有机器学习专业知识背景的新用户,我从最初的账号注册,到最终使用SageMaker Canvas构建模型,花费了不过半天时间,非但不用在本地电脑装各种软件、各种库、各种包,还省去了几百行的机器学习代码,整个过程无需编码即可构建机器学习模型,完成对本地数据的预测分析。
对比过去和现在,如果你想使用机器学习算法对手头上的数据进行分类、预测:

表1 过去 VS. 现在
2. 界面风格简洁
以产品经理的视角看,Amazon SageMaker Canvas每个页面的排版样式、控件设计及交互效果都非常的通俗易懂。
例如,登录Amazon SageMaker Canvas的工作台后,能在其中查看该账户下所有已创建模型和已导入的数据集。其中,模型列表支持两种展现形式:卡片列表和表格列表。
我个人比较喜欢卡片列表,因为卡片列表相比于表格列表,样式要活泼很多,能让页面显得不那么死板和单调。接着进入一个模型之后,会看到选择数据>>模型构建>>模型分析>>模型预测这四个步骤,这能指引用户更便捷地完成模型构建工作。
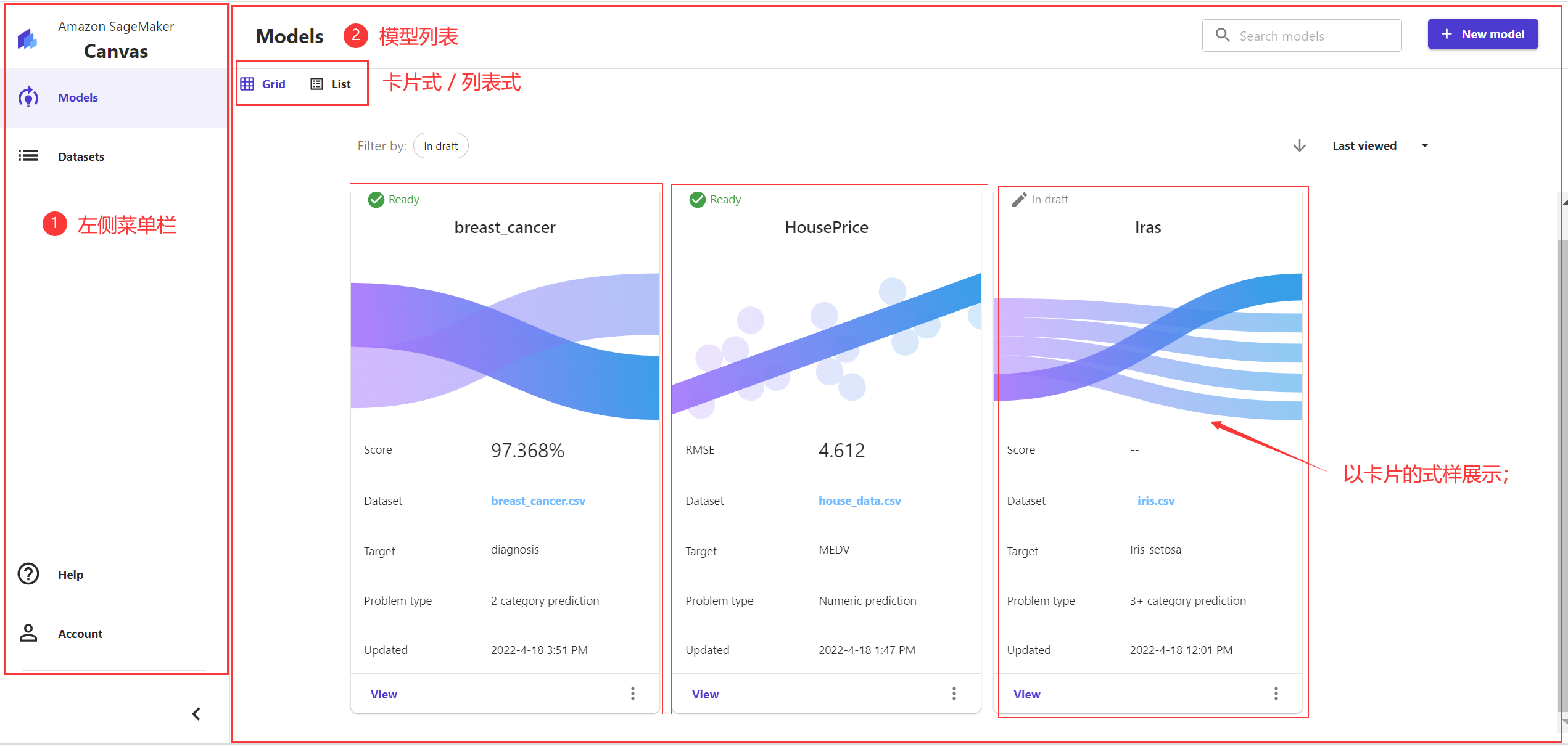
图1 模型列表—卡片式
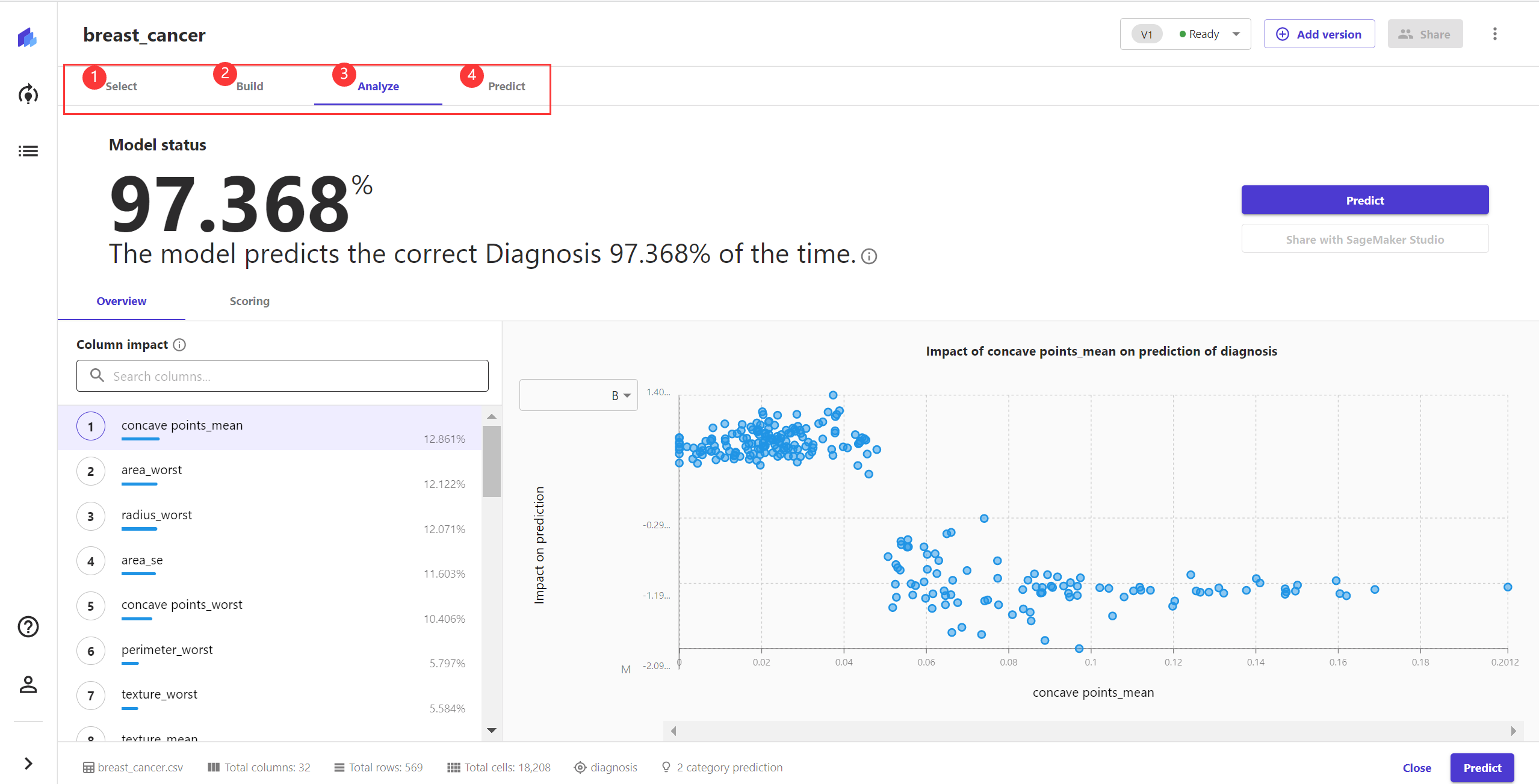
图2 训练模型的步骤
三、功能测评
低代码作为一种技术手段,自然有它独特的优势,可低代码机器学习平台的预测准确性相较于常规的python编程语言会有所下降吗?
下文将从分类、预测两大类场景使用Amazon SageMaker Canvas构建模型,并将Amazon SageMaker Canvas构建的模型准确度与python编程语言得出的结果进行对比分析。
1. 分类问题
1)数据集
我们一般接触到的分类问题大多属于二分类问题,非此即彼。乳腺癌分类问题就是机器学习中一个经典的二分类问题,建立乳腺癌风险评估模型,预测乳腺癌发生概率,对乳腺癌的防治具有重要意义。
本文使用的数据据集来自美国威斯康星州公开的乳腺癌诊断数据集,医疗人员采集了患者乳腺肿块经过细针穿刺后的数字化图像,并从这些数字图像中提取了32个特征,用这些特征描述图像中的细胞核呈现。
数据集共569行,每行数据具有32个特征,第一行是id,第行为diagnosis诊断类型(良性/恶性),第3-32个特征其实只包含了十个属性,只是每个属性都从3个维度:平均、标准差、最大值去分析,所以总共有30个特征。

表2 乳腺癌数据集说明
2)对比分析
使用Amazon SageMaker Canvas实现乳腺癌分类的步骤如下:
① 登录Amazon SageMaker Canvas。
② 数据准备:导入本地数据到Amazon SageMaker Canvas。
③ 构建模型,选择数据集中的某一列作为让模型去预测的目标列,此时SageMaker Canvas会根据该列的值,自动识别该问题是分类问题还是预测问题。在我导入乳腺癌数据集,选择了“diagnosis”列作为目标列后,Amazon SageMaker Canvas判断其为二分类问题。的确,该列只有两种值:B表示乳腺癌良性,M表示乳腺癌恶性。
除此之外,SageMaker Canvas会自动对上传的数据集进行预处理,例如,使用数据集中毗邻的值来推断缺失值,且能提供数据集中每列的数据是如何分布的,这极大省去了在使用python进行分类时的特征预处理以及特征选择的工作。
图3 使用python进行特征预处理
接着点击构建或预览模型,SageMaker Canvas会从自身封装的众多模型中为你推荐最合适的一个,并将特征按照重要程度排名,你可据此看出哪些特征对机器学习模型影响最大,去掉不重要的特征,点击更新模型,待到模型准确率无明显变化后便可不再调整。
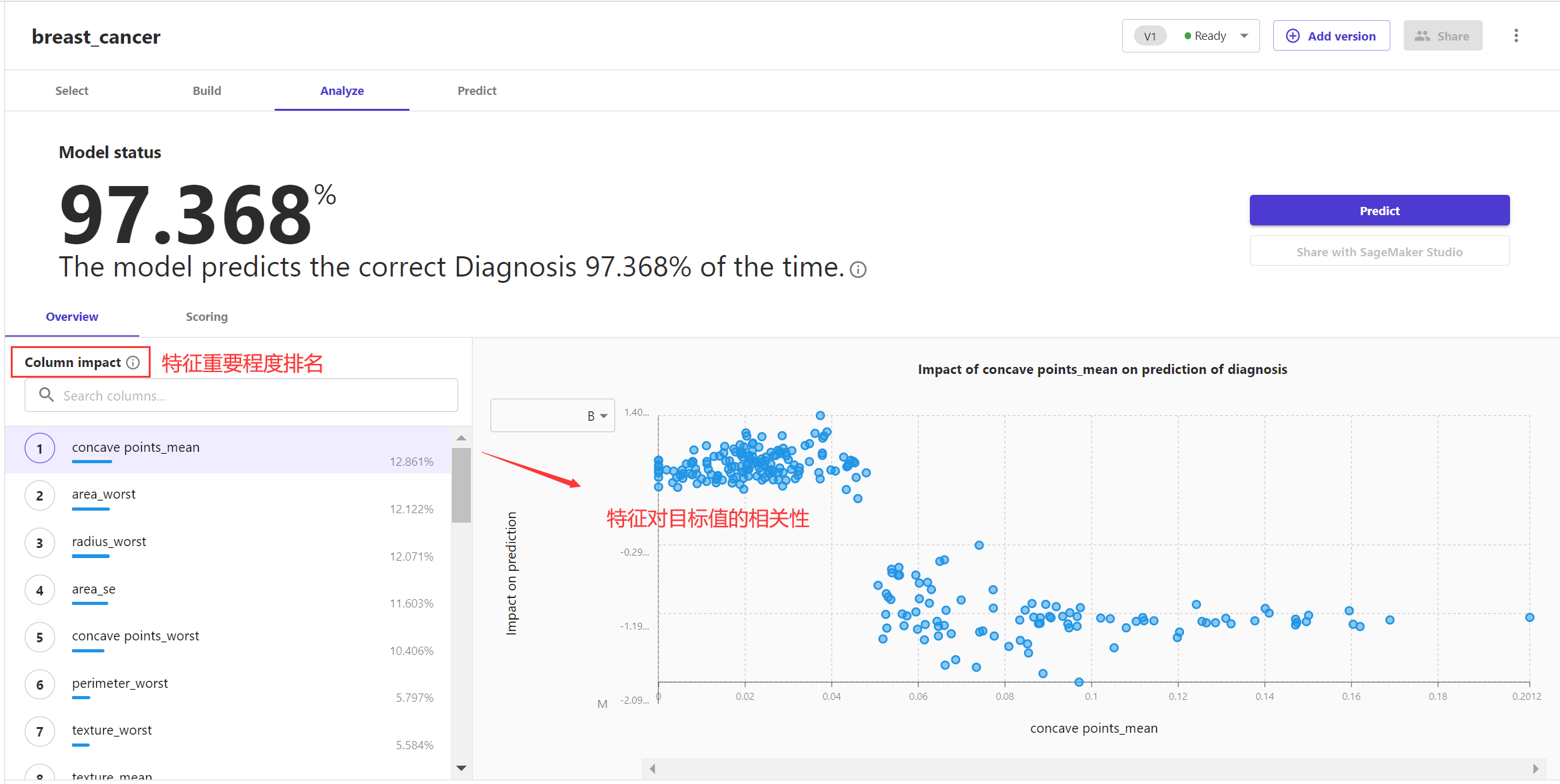
图4 特征重要程度排名
讲到这里,大家肯定想印证一下,用python编程语言筛选出的特征和Amazon SageMaker Canvas给出的特征排名,二者之间有没有偏差,或者说有多少是吻合的?下面就为大家揭秘。
如下图所示,左侧是Amazon SageMaker Canvas得出的排名,右侧是python得出的特征相关性热力图,据此热力图选取相关性特征值维度值较大的特征。
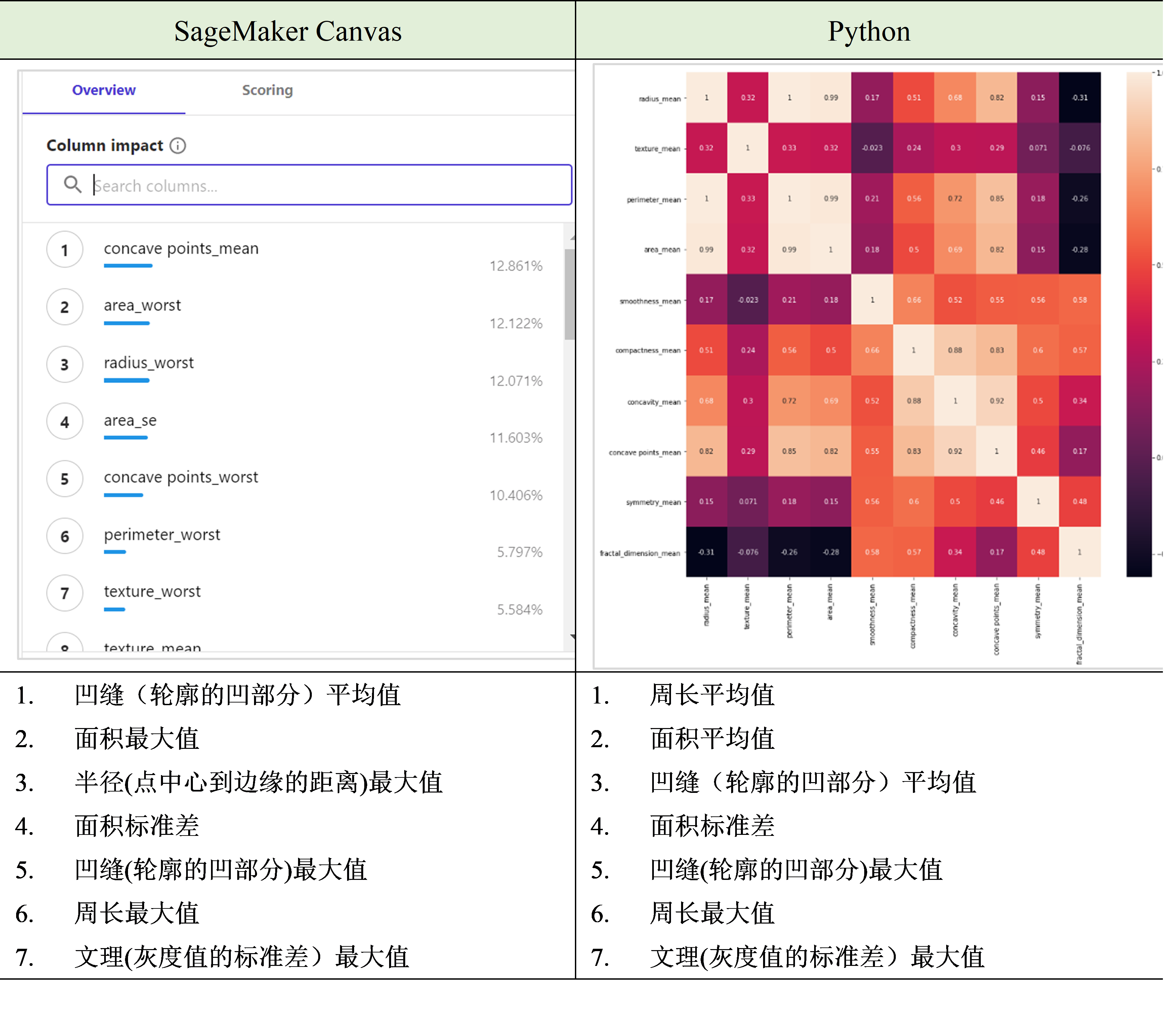
表3 SageMaker Canvas Vs. Python
能够识别患者是否罹患乳腺癌的分类器训练完了,那么如何评判这个分类器的优劣呢?
传统的评估分类器性能的方法是使用混淆矩阵来描述数据集的真实标签和模型预测标签之间的差异。此外,基于混淆矩阵,还可以计算出各种指标来比较分类器的性能,如F1-Score、准确率(Accuracy)、精确率(Precision)、召回率(Recall)、AUC值。
如下表所示,针对以上指标,对比二者的结果。通过比较,使用Amazon SageMaker Canvas得出的模型评估值,和用Python中linear_SVM算法得到的结果几乎吻合,近似一致。
只是AUC值一列,似乎存在一些问题,Amazon SageMaker Canvas得出的为0.991%,python得出的是0.974,数值上是吻合的,但在度量上差了两位小数点儿,这一点还有待进一步探讨。
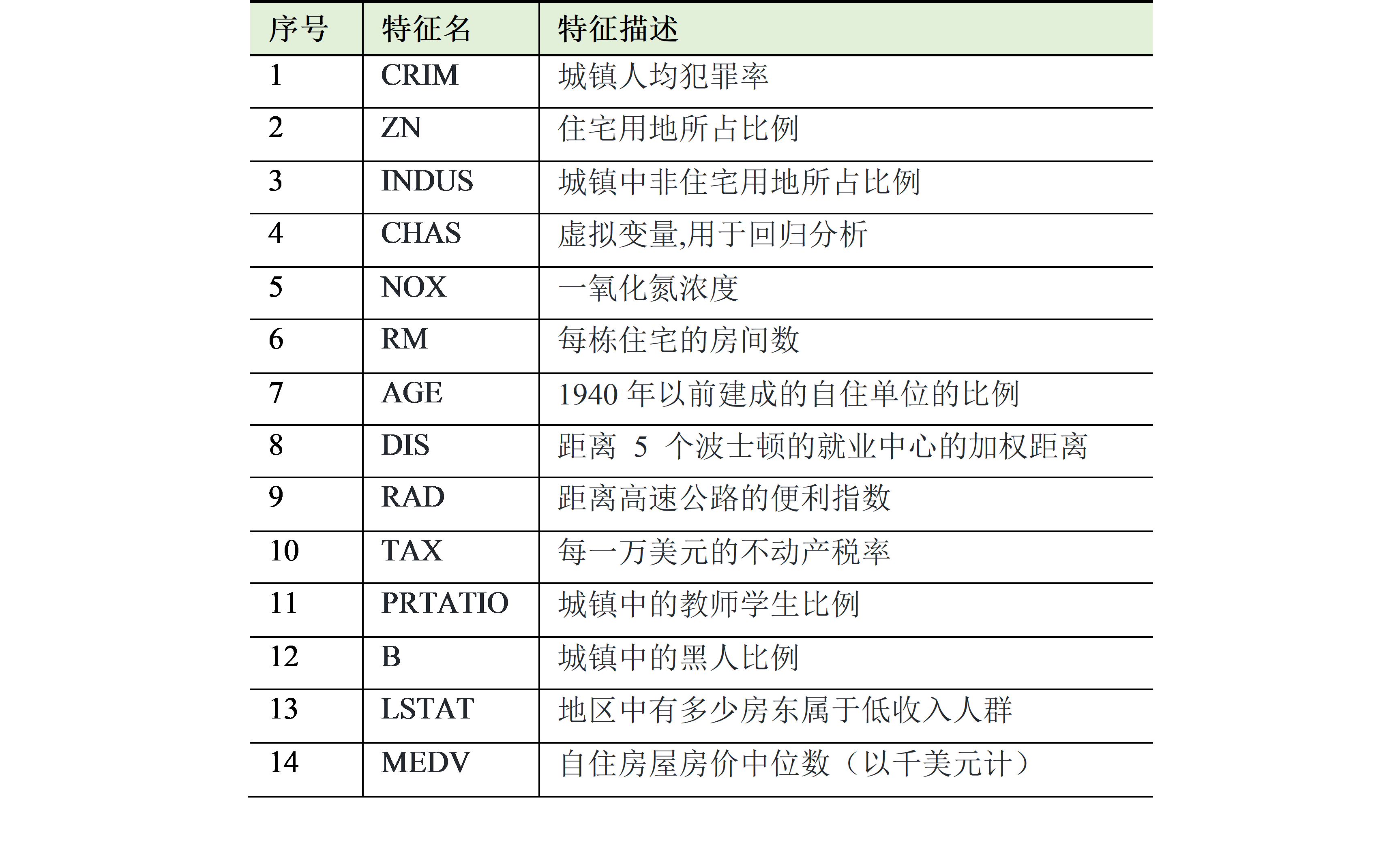
表4 Amazon SageMaker Canvas VS. Python
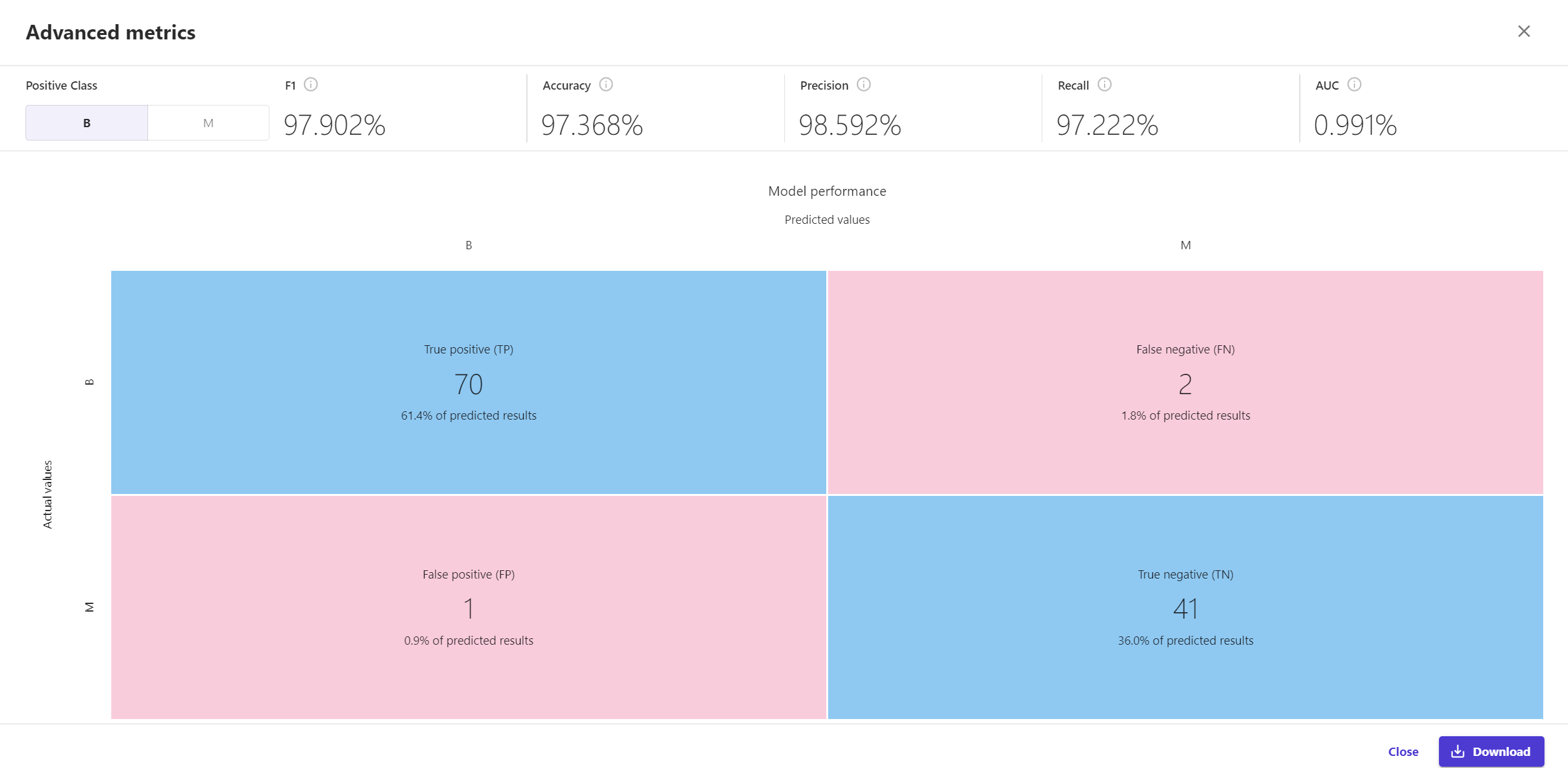
图5 SageMaker Canvas的混淆矩阵和几大指标
3)小结
分类算法的应用范围和涉及的场景非常多,涉及各行各业,我们要解决的问题大都可以抽象为分类问题.
就拿信用卡的生命周期来讲,在营销期,利用分类算法对积累的客户的数据进行预测,找到潜在的推广客户,满足个性化营销。
到审核阶段,需要对客户进行资质评估,无通过分类算法预测违约的概率,从而达到信用评级的目的。
到了稳定期,随着客户的账龄不断增长,客户的资质不断发生变化,需要定时定点对客户进行风险的研究,及时发现风险客户并进行管理。
最后,到了衰退期,会涉及到客户流失的问题,需要用分类算法预测客户流失的可能性有多高。
2. 预测问题
1)数据集
波士顿房价预测是经典的数据分析/机器学习入门项目,我们都知道,房价一般会与房间面积的大小、房子所在的城市、房子的空间布局等因素有关。而房价预测的任务就是给定与房价相关因素的数据,通过这些数据预测出房子的价格。
波士顿房价数据集:波士顿房价数据集来自卡内基梅隆大学StatLib库,涵盖了麻省波士顿的506个不同郊区的房屋数据,404条训练数据集,102条测试数据集 每条数据14个字段,包含13个属性和1个房价的平均值。下表是对波士顿房价数据集的特征描述:
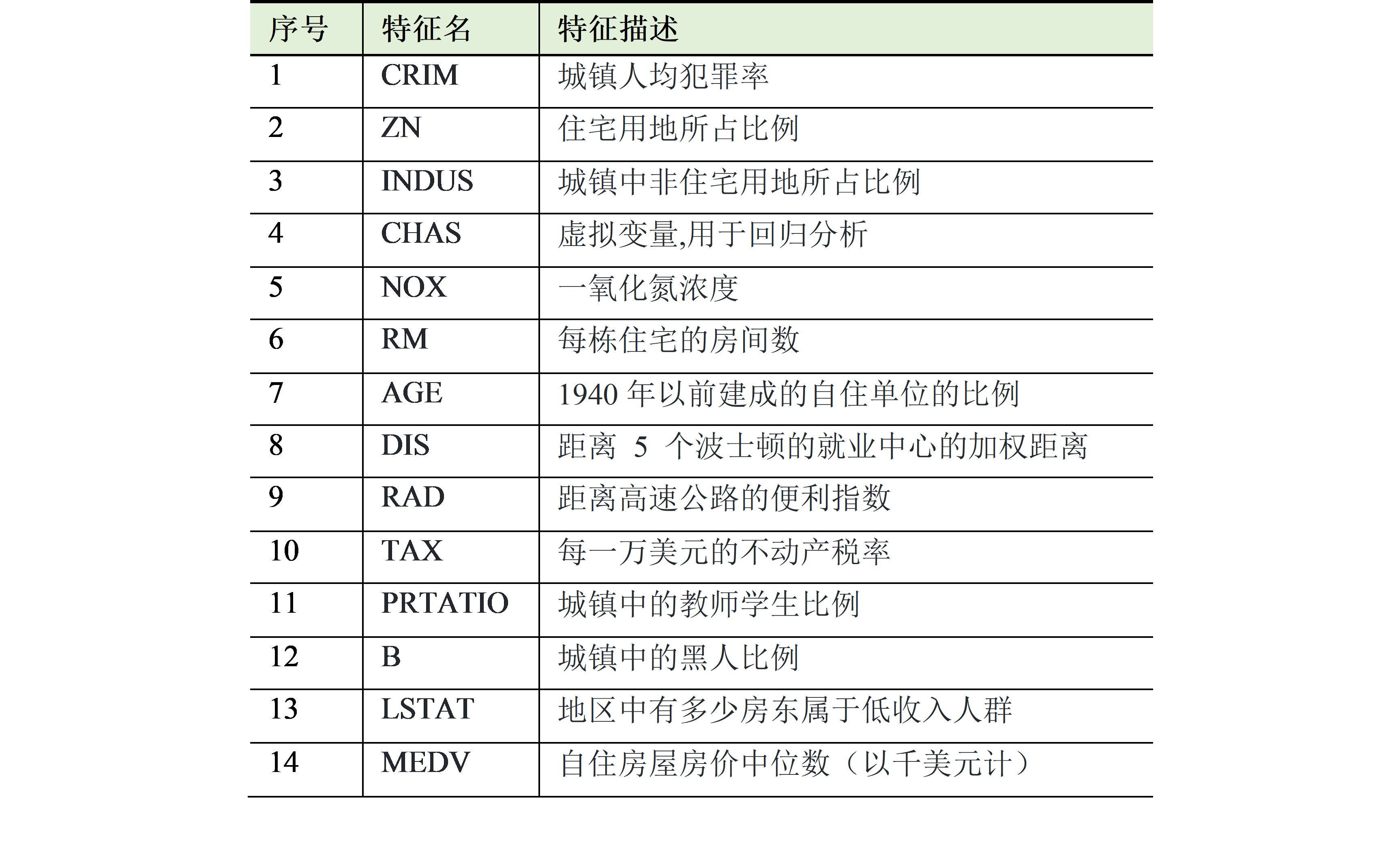
表5 波士顿房价预测数据集
2)对比分析
波士顿房价数据集中共计13个特征,每个特征都会或多或少的提升或者抑制房价。现将SageMaker Canvas预测出的特征重要程度排名与Python机器学习算法得出的进行对比,发现前7个特征中,有5个特征是重叠的,这证明SageMaker Canvas的模型预测性是值得信赖的。
比如,抑制房价最明显的是特征NOX,它表示一氧化氮的浓度,基于常识可知,一氧化氮浓度越高,说明住房所在地的环境污染越严重,房价也就越便宜。对房价提升最明显的特征是 RM,对应数据集可知,RM指的是每处住房的平均房间数量,这也是很容易理解,房间越多,房屋总面积就越大,面积越大,总房价就高。
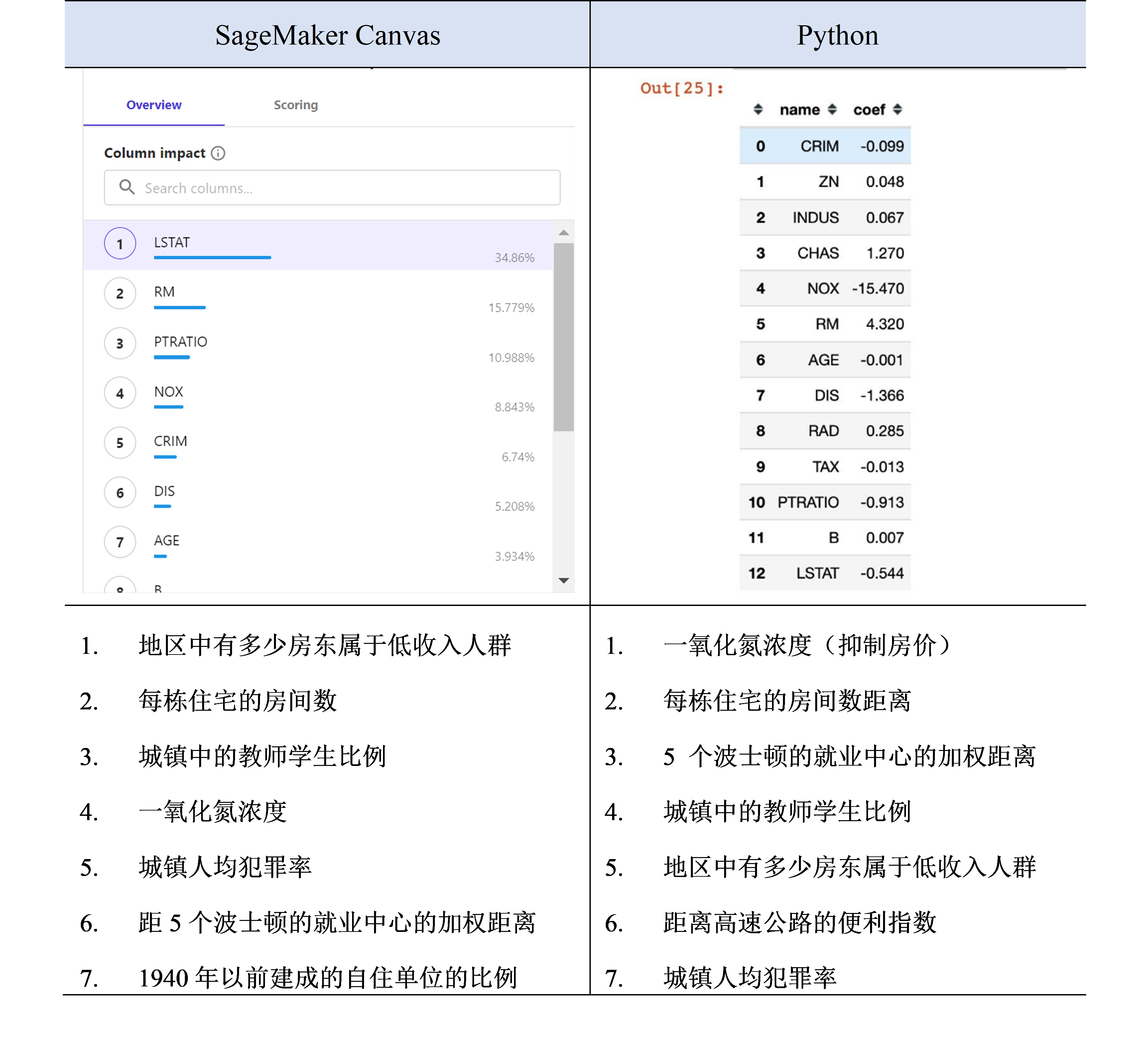
表6 Canvas得出的特征重要性排名 VS. Python得出的
SageMaker Canvas除了能够对数据集中影响预测结果的特征进行重要性排名,还能清晰地展示出每一个特征和预测结果之间的关系(是正相关的还是负相关的),例如,LSTAT这一特征表示“该地区中有多少房东属于低收入人群”,如下图所示,该地区低收入人群越多,房价越低。
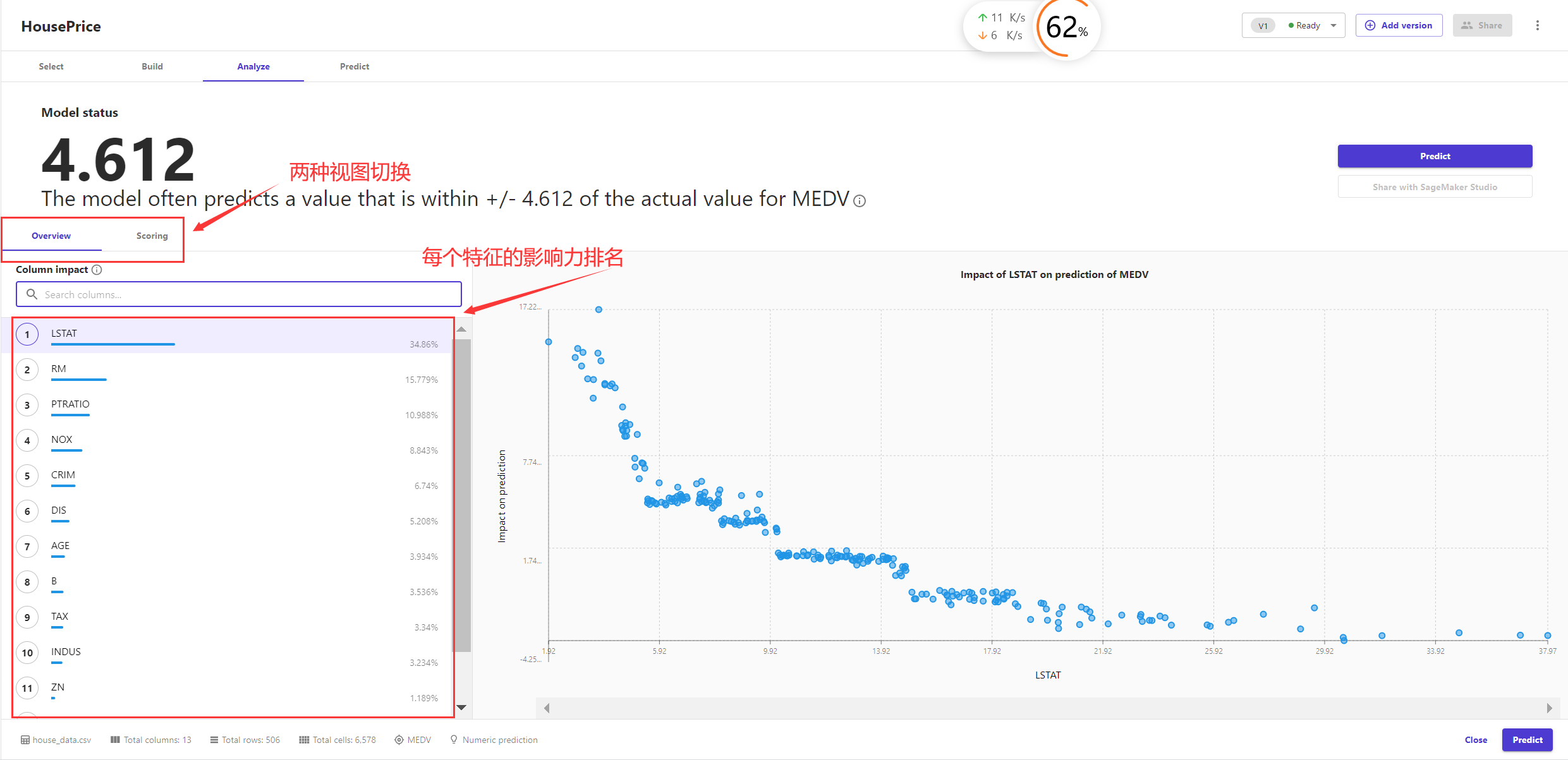
图7 各个属性对模型预测的影响力排名
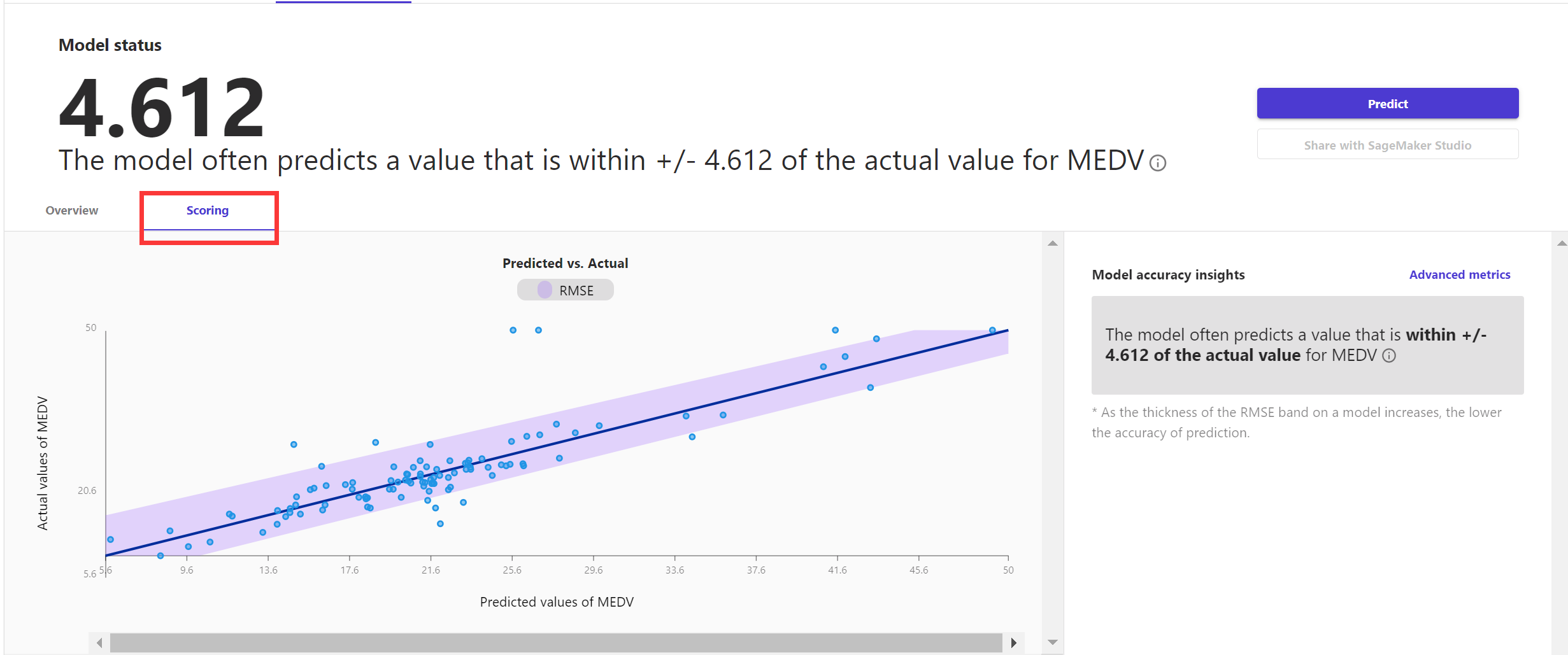
鉴于可视化能给人们带来最直观的认知,SageMaker Canvas中提供了可视化方法,来展示回归模型预测的效果。
如下图,可以看到针对波士顿房价数据集,预测房价和实际房价之间的对比图。针对预测类问题,SageMaker Canvas提供了均方根误差(RMSE),如下图所示,线条周围紫色区域的宽度代表了RMSE的范围,房价预测的值通常会落在这个范围之内。
3)小结
本次,在使用SageMaker Canvas预测房价的过程中,我们只需要给定输入数据集,SageMaker Canvas就可以从中推演出指定目标变量的可能结果。其他预测问题,也能在SageMaker Canvas上实现。
四、总结
高昂的硬件价格、复杂软件配置一直是阻碍初学者入门 AI 的绊脚石,低代码机器学习开发平台的问世与推广可谓是“码盲人群”的一道曙光。通过低代码功能,使用支持比 Python 编码更快、更容易的模型操作的新的机器学习算法,变得让人期待。可见,在未来,即使是完全不具备机器学习知识的业务人员,也可以运用机器学习模型高效解决业务上的实际问题。
本文由 @麦地与诗人 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自unsplash,基于CCO协议









低代码市场,早在几年前,亚马逊、微软、阿里、腾讯等国内外巨头公司就已纷纷入局。
看标题还以为小白会秃头,但是开头“对没有机器学习知识的人友好”成功让我去了解了哈哈
哈哈,可以try一下~