
 起点课堂会员权益
起点课堂会员权益浅谈评分模型
编辑导语:我们在生活中处处都有需要评分的地方,比如我们点外卖或者去一家餐饮店,就习惯性会去看看评论如何;本文是作者分享的关于评分模型在业务、系统、公司的意义,以及搭建的方法论,我们一起来学习一下。

一、什么是评分模型
在写这篇文章前,我一直在思考评分模型之于业务、系统、公司的意义,如果用一句话描述评分模型,我的定义是——对某一群体事物(评价主体)由定性分析到定量分析的过程。
二、搭建评分模型的意义
评分模型在平台上应用较为广泛,常见的交易,内容、社交、社区平台都会广泛运用评分模型或分层模型(分层模型更多是在评分模型的基础上进一步归类得到)。
为什么是平台?
平台作为供给方与需求方的连接,在平台生态的搭建中,往往通过规则的制定,激励、惩罚、约束供给方与需求方,打造正向体验,促使平台朝着良性、正向的方向发展。
在规则的制定与履行中,往往基于平台的价值观去制定规则,再借由评分模型(体系)进行度量,所以我们也说评分模型是平台价值观的体现。
举个例子
基于场景:某个区域有100位用户打车(需求),而司机(供给运力)仅有80个单位,针对此场景大D、小D两平台调度系统逻辑分别为:
大D平台:认为打车业务是需求驱动型业务,即平台的核心在于最短时间内满足所有乘客的出行需求,因此调度系统会从全局最优角度为司机——路线匹配程度进行量化评分,进而依据分值进行调度
小D平台:认为打车业务是供给驱动型业务,即平台核心是保障司机端体验以聚拢更多司机(运力),因此调度系统从司机体验最优角度为司机——路线匹配程度量化评分,进而依据分值进行调度
三、评分模型的基础结构
评分模型,更准确的说应该是评价模型与我们的生活息息相关,当我们对某一事物进行评价时,实际上已完成了评价模型的建立。
例如我们评价一件商品的好坏,一个人工作能力的强弱,一道菜品的优劣。
评价模型是我们对某一事物的价值评估,更侧重定性分析;而评分模型,文章开头我们讲过定义:是对某一群体事物由定性分析到定量分析对过程,本质上是定量分析。
如何理解两者的差异,下面一张图方便大家理解:
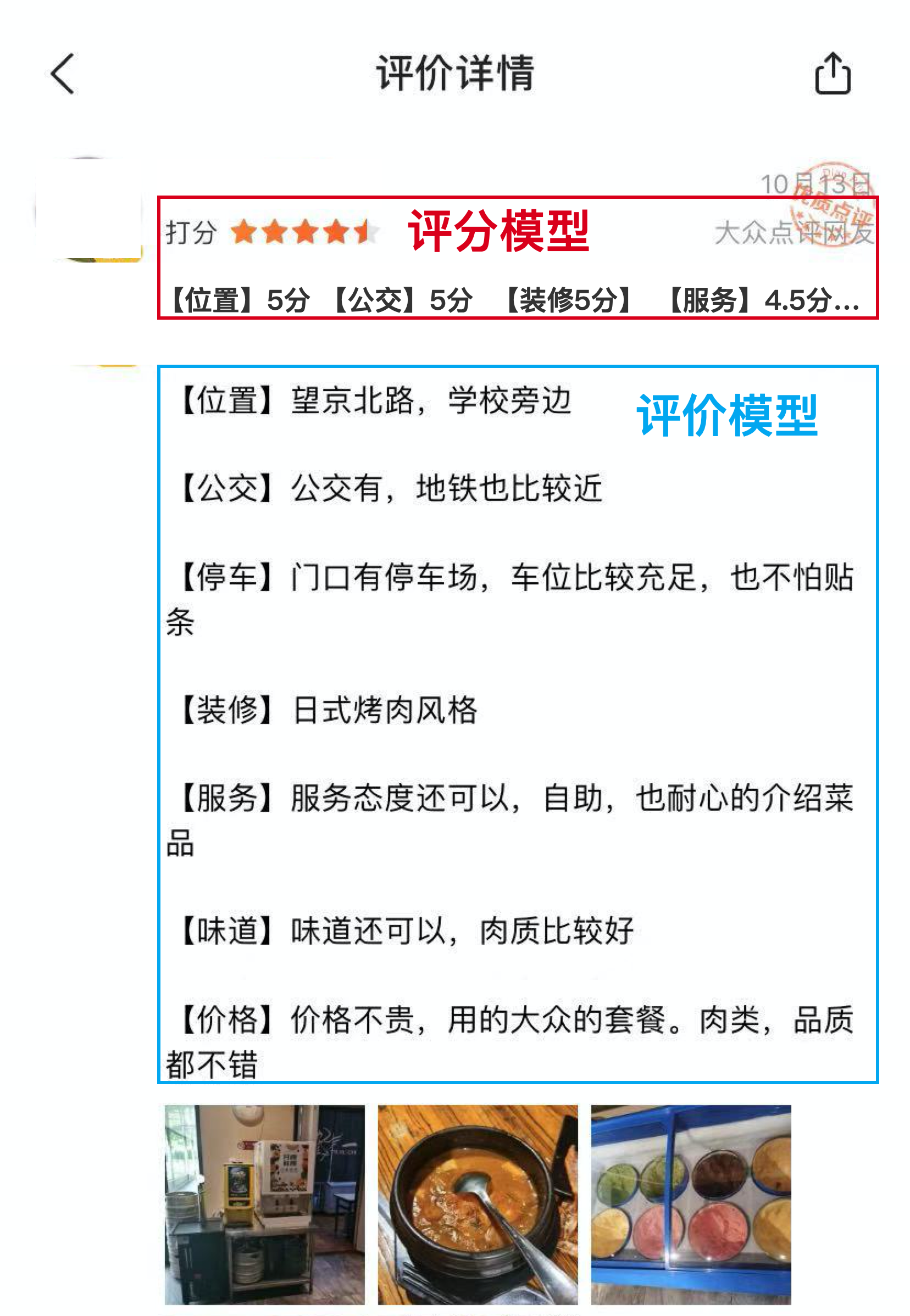
刚才我们讲评价模型与评分模型的差异,及生活中被各类评价模型裹挟。那么生活中有没有评分模型?
有一类评分模型我们从小就开始与其打交道,伴随了我们的成长 —— 考试,考试的本质是对学生的学习情况定量分析的过程。
现在我们就由考试讲起,聊一聊评分模型的组成。
考试作为评分模型,它的结构是怎样的呢?让我们先回想一下考试的几个组成要素:
- 学生
- 试卷
- 老师
对上述三个对象在评分模型中的定位进行抽象:
- 学生——被评价者:即评价模型所研究对象
- 试卷——综合评价模型
- 老师——评价标准制定者
我们可以看到,考试的本质是评价标准制定者通过模型的建立对被评价者某种能力/特征进行量化评分的过程。
这个结构简单理解就是:被评价者特征信息的输入通过评价模型进行量化,完成结果分值的输出。
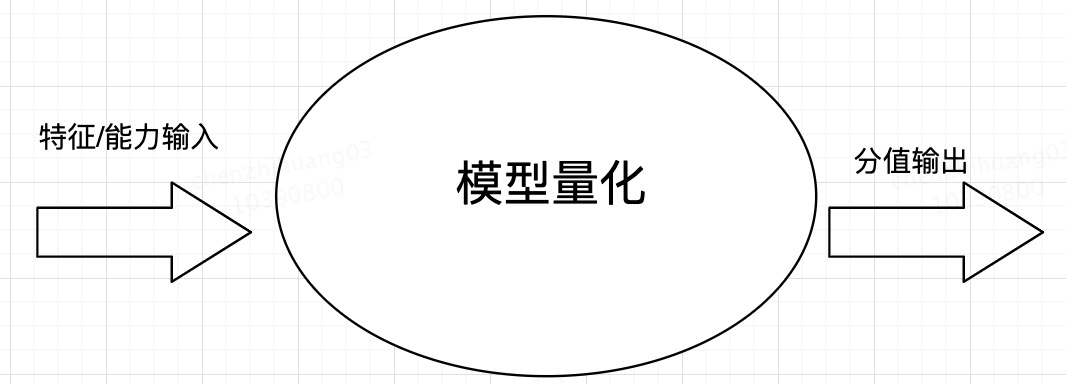
那么模型本身的内在构造又是怎样的呢。回到考试场景,试卷就是评分模型,试卷中包含了哪些要素?
我们通过得分拆解:分值=题*每题得分。
- 题的本质:对被评价者在某方面能力、特征的度量——考核指标。
- 分的本质:某项能力、特征对整体评价的重要性——权重。
花了很大篇幅讲评分模型的相关概念,是为了让大家理解评分模型的基础原理。
四、指标:评分模型的基石
1. 指标的特性
评价指标是反应被评价对象在评价体系中影响评价结果的影响因子。
选择的指标需要满足几个基本特性:关联性、普遍性、可度量性
关联性:在选取模型指标时常出现以下几个问题,导致选取指标组成的评分模型无法准确表达评分模型目标及意义。
- 选取指标不全,片面表达
- 选取指标不合理
- 选取指标重复
如场景:在制定商家服务评分体系的时候,主要考核衡量商家对用户服务的质量,以下哪些指标可以运用于商家服务评分体系,体现商家服务质量:
- 销量
- 评价数
- 30s应答率
- 退货率
各位可以思考下(一分钟思考时间)~
答案是仅30s应答率可纳入商家服务质量指标体系。
我在线下跟朋友交流此问题时,鲜有人能准确选出答案,甚至到商家管理业务同学这里也栽了跟头;这个问题在未明确目标时,我们容易将销量,评价数、退货率这些指标引入评价模型。
从主观感知上来看,我们天然认为销量高的商家比销量低的商家服务质量好;评价越多的商品,店铺服务质量会越好;退货率越高的店铺,服务质量不好,从平台大盘数据看整个商家体系往往也是此趋势。
但具体到个例上看确是如此么?
- 销量高、评价数多的商家普遍比销量低评价数少的商家服务好,但新商家服务质量不一定比老商家差,小众品类商家服务质量不一定比大品类商家差;
- 退货率低的商家普遍比退货率高的商家服务质量好,但有些品类天然退货率高,如服饰鞋帽品类天然比食品零食品类退货率高。
- 退货也不一定是商家服务质量造成的退货,可能存在用户个人原因,故若要反应商家服务质量,也品质退货率会更准确,类似此类例子还有很多。
商家对用户提供的服务质量确实会影响销量、评价数、退货率等指标,但这是一个逆命题。
上述几个指标均是结果型指标,代表的场景是:商户对用户提供了良好的服务质量,会影响上述指标的结果。
我们的模型要探究的是哪些指标对商家服务质量结果产生了影响,而不是商家服务质量会对哪些指标产生影响;在此语境下,我们更应关注过程型指标。
但这并不代表结果型指标不可用于评分模型,结果型指标运用于评分模型中有两个天然的劣势:
- 滞后性,从评价主体的行为到结果的输出存在时间差;
- 多因素干扰,实际业务场景下,某个结果型指标往往被多因素共同影响,存在部分因素不是评分模型研究范围。
若实际业务过程中能接受滞后性,或者能排除多因素干扰,那么结果型指标同样可作用于评分模型
可度量性:这个就相对易理解了,文章开头我们定义了评分模型的概念:本质上是定性分析到定量分析的过程——这就要求选取的指标可量化。
普遍性:评分模型在完成评价主体的确定,对模型指标选择中,应尽量选择评价主体都具备的能力/特征作为考核指标,以减少统计的不公平性,避免模型计算过程中的复杂性。
2. 指标的选择——GSM模型
合理的指标需要满足什么基础特征,我们现在知道了。
但就像明白了很多做人道理却依旧过不好此生,很多人会感觉指标该满足关联性、普遍性、可度量性,我知道了,但合理的指标如何选取呢,还是不知道。
这里面其实有一个逻辑定式在里面,我们说的指标满足各种特性,其实是对结果的一种验证,缺少的是对实现路径的认知。

这里我提供一个路径,供大家参考:拆分目标-归纳表现型-选取指标——GSM模型。
GSM模型:目标(Goal)→信号(Signal)→指标(Metric)是谷歌用户体验团队提出的一种指标体系搭建方法,其核心思想:通过明确目标,归纳测量主体表现型,找出关键指标。
目标确立(Goal):
- 明确业务目标、系统目标等;
- 根据核心(主)目标做目标拆解;
推导信号和现象(Signal):
- 目标达成或未达成的表现型是怎样;
- 什么行为指示了目标达成/未达成;
- 很多时候负向信号/表现型比正向信号/表现型更容易识别;
选取指标(Metric):
- 目标达成/未达成的表现通过哪些数据指标量化;
- 考虑每个数据指标对推导信号/现象的描述程度;

3. 指标的正向化
选择的指标从评判标准来将会存在以下几种类型:
- 正向指标——越大越好;
- 逆向指标——越小越好;
- 中间型指标——越趋于某个值越好;
- 区间型指标——越靠近某一区间;
为了便于后续计算与分析,我们通常将各类型指标转化为正向指标。
逆向指标正向化:
yi=max-xi 或 yi=1/xi
中间型指标正向化:

其中Xbest为中间最优值。
区间型指标正向化:
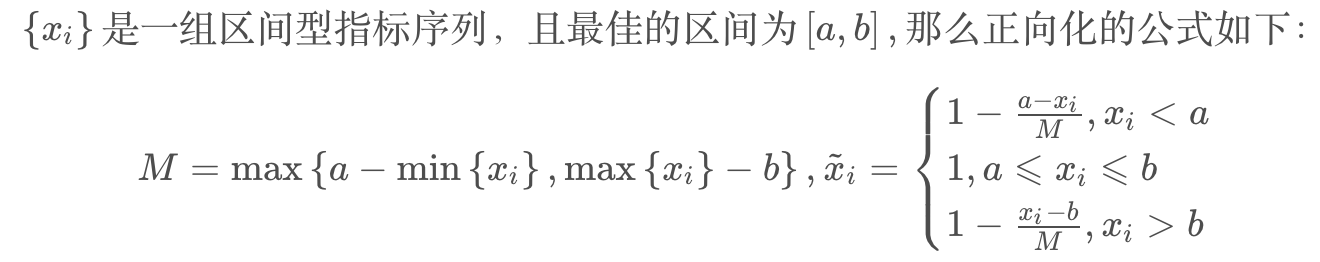
4. 指标的无量纲化
无量纲——听起来有点晦涩。
无量纲是物理学延伸出的概念,指在便于对物理常量进行比较、分析,不同常量(重量、长度、时间、体积、温度等)之间单位是不一样,为了消除单位的影响需要进行的去量纲化。
同理,不同指标之间由于存在量纲不同致其不具可比性,亦需将指标进行无量纲化,消除量纲影响将指标实际值转化为评价值,大家可以简单理解为去单位化。
目前最普遍使用的无量纲化方法是标准化法,标准化法即令:
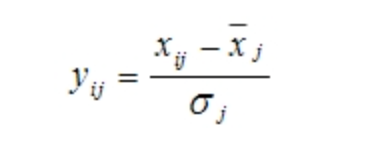
其中x拔和σj分别是指标xj的均值和标准差。
五、权重
1. 权重的内涵
前面我讲过评分模型是平台价值观的体现,这个价值观很大一部分由指标的选择与权重的定义承载。
不同平台在定义指标权重时会存在较大差异,可以简单理解为不同平台因产品形态/产品定位/目标用户/使用场景存在差异,导致平台在评价一项事物时会有不同的标准,这个标准我们可以抽象为权重。
权重的大小反映了对于目标结果来说,评价指标的重要程度。
这个重要程度一般从两方面衡量:
- 指标包含评价主体信息量的多少,包含信息量越大,权重越大;
- 指标对评价主体的区分度,评价指标区别被评价对象的能力越大,则权重越大
2. 权重的计算
我们知道,价值观具有极强主观性,同样,平台在指标权重的定义上也存在极强的主观性。
我目前了解到各大平台在定义各类评分模型的指标权重时,往往用主观赋权法较多:
主观赋权法:常用的主观赋权有专家定权法、层次分析法,该类方法主观性都较强;
- 专家定权法:专家定权的本质是由业内/领域权威人士直接定义各指标权重;
- 层次分析法:层次分析法虽属于主观定权,但也存在一定的科学性,旨在通过指标量量对比,量化权重,主观定权下带有一定的客观计算规则。
其计算思路如下:
1)构造判断矩阵
判断矩阵含义:建立指标之间两两比较的影响程度的矩阵。例如对指标B1;B2;B3;B4;B5定权,构造判断矩阵为:
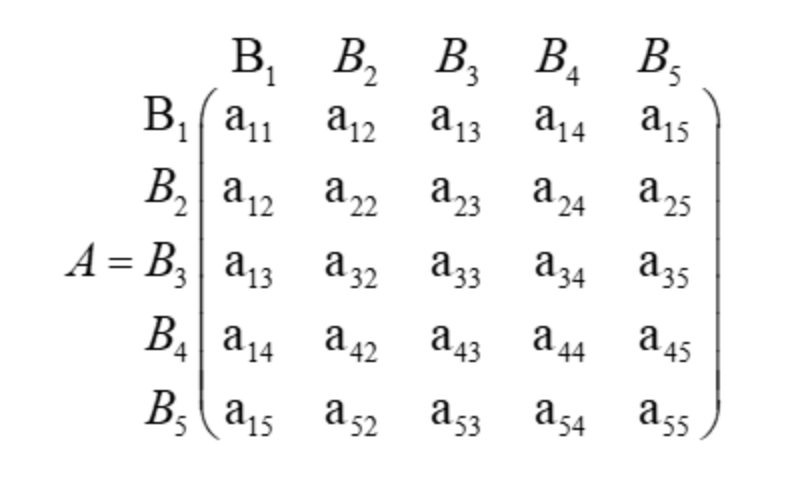
2)建立指标度量标度
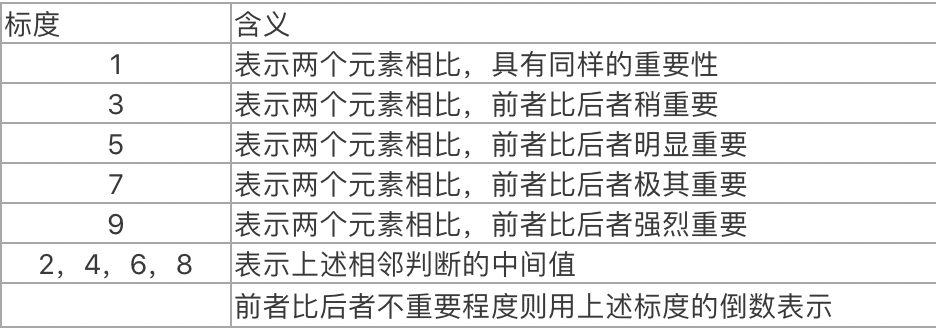
其中aij表示第i个指标与第j个指标的比较度量,用如下标度表示:
3)检验判断矩阵的合理性
判断矩阵构建后,需要进行矩阵一致性校验,何为一致性校验,即在比较时是否表达一致,例如:A>B,B>C,那么A必然大于C,这样检验方式称为一致性检验。
一致性检验是通过计算一致性比例CR得来:
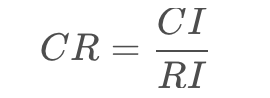
中CI表示一致性指标,其公式为:
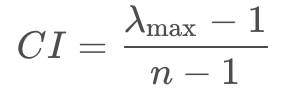
n表示判断矩阵中指标的个数,λmax表示判断矩阵的最大特征值。
RI表示随机一致性指标,可查表获得,如下表所示:

当CR<0.1时,则表示一致性检验通过,判断矩阵构造合理,CI 越大,判断矩阵的不一致性程度越严重。
4)定权
客观赋权法
这里仅介绍下常用的客观赋权——熵值法。
什么是熵?
物理学对熵的定义是描述体系混乱程度(离散程度)的度量,宇宙是一个熵增的过程,熵增也是世间万物的运行规律。
什么是熵值法?
物理规律下的离散程度我们定义为熵,信息领域的信息不确定度被定义为信息熵,熵值法是对信息熵的计算,用来判断某个指标的离散程度。
在权重的内涵中我们讲到衡量权重的标准之一:指标对评价主体的区分度,评价指标区别被评价对象的能力越大,则权重越大。
熵值法正是基于此思想而建立,是泯灭指标特性的数据分析,不对指标实际含义进行解析和解释,通过对数据的离散程度(不确定度)进行对比而推算权重。
例如在商家服务质量评分模型建立过程中,各商家在指标A上的数据离散程度非常小,如果我们赋予该指标较大的权重就会出现各商家得分相近,难以区分优劣。
计算方法如下,较为晦涩,感兴趣的同学可以百科自行学习,再此不多赘述,以下参考资料来源百度百科:


上述指标权重的定义更多是在讲“术”的方面,即如何科学定义权重;但我们要明白的是权重不是一成不变的,评分模型运行后我们往往会动态定义权重,观察在不同权重组合影响下(如各类AB实验),对用户体验/平台效益/系统效能等方面的收益进行量化,以期寻找一个最优组合;甚至在平台发展的不同阶段,各指标权重也会跟着平台战略演进而调整。
六、分值的选择
- 5分制:具备分层属性:极差、较差、一般、较好、极好,强化等级/层级,弱化同级差异,重定性描述,直观,易于交互,阅读性较强,常用于C端展示;
- 百分制:强化排序/排名 重比较,重定量描述,常用于内部排序、排名使用;
- 10分制:归属定性描述还是定量描述,我的理解介于两者之间。
介绍至此,你会想评分模型就是这样?如果是狭义上的评分模型,我认为是的,但是至此该评分模型都不具备商业价值。
狭义的评分模型仅是作为衡量尺度的工具,文章开头我们讲了,评分模型是平台价值观的体现;这个价值观不止体现在指标的选择、权重的定义,还体现在蛋糕(权益)的分配。
任何平台的资源都是有限的,如何携带有限资源在企业发展这个无限游戏中长久玩下去,是每一个平台都要思考的问题;而评分模型的建立正是期望通过一系列量化,提升资源的利用效率。
所以我们也定义权益分配是评分模型中的一部分,如下图:
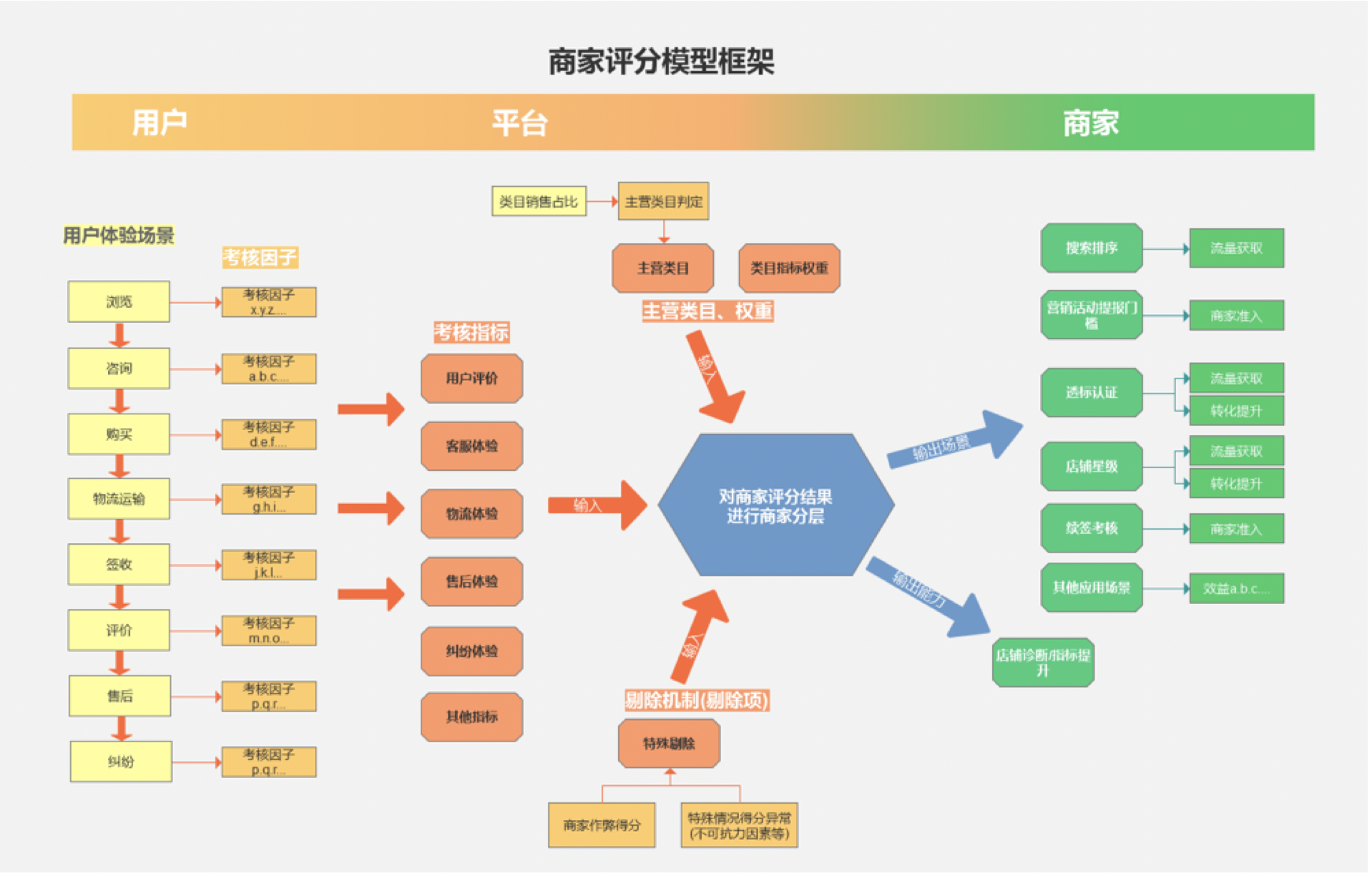
至此,我本次的分享告一段落了。
本文用“浅谈”旨在表达评分模型搭建的方法论远不止于此,往后还可延展出很多内容,如评分模型的ABtest、通用评分模型系统的搭建等等,有机会再分享。

本文由 @阿铁 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自 Unsplash,基于CC0协议









厉害了,学到了~
大佬,你好厉害哦
求后续内容更新
帅锅,你也在研究评分模型么?我们也在筹划类似产品,我拉一个群,可以一起探讨一下么?欢迎入群:QQ290061204
哇哦,学习了,还可以在哪里看到大佬的分享资料哦,或者会考虑继续更新嘛~~
帅锅,你也在研究评分模型么?我们也在筹划类似产品,我拉一个群,可以一起探讨一下么?欢迎入群:QQ290061204
想要请教一下,指标选取好了,如果将指标转化为分值呢?可以展开讲讲么?
帅锅,你也在研究评分模型么?我们也在筹划类似产品,我拉一个群,可以一起探讨一下么?欢迎入群:QQ290061204
您目前是怎么处理“将指标转化为分值”这个问题的呢
学习了!想问有没有公众号,想关注一波
帅锅,你也在研究评分模型么?我们也在筹划类似产品,我拉一个群,可以一起探讨一下么?欢迎入群:QQ290061204
学生 考试 那里讲的很好 ,刚好要做个评分系统
帅锅,你也在研究评分模型么?我们也在筹划类似产品,我拉一个群,可以一起探讨一下么?欢迎入群:QQ290061204
不明觉厉
帅锅,你也在研究评分模型么?我们也在筹划类似产品,我拉一个群,可以一起探讨一下么?欢迎入群:QQ290061204
铁哥这逻辑点赞
帅锅,你也在研究评分模型么?我们也在筹划类似产品,我拉一个群,可以一起探讨一下么?欢迎入群:QQ290061204
看了作者其他文章,都干货满满,有思想的产品经理
帅锅,你也在研究评分模型么?我们也在筹划类似产品,我拉一个群,可以一起探讨一下么?欢迎入群:QQ290061204
已关注,期待大神的更多分享
帅锅,你也在研究评分模型么?我们也在筹划类似产品,我拉一个群,可以一起探讨一下么?欢迎入群:QQ290061204
老铁666
帅锅,你也在研究评分模型么?我们也在筹划类似产品,我拉一个群,可以一起探讨一下么?欢迎入群:QQ290061204
老铁,讲的太好了,受教了
帅锅,你也在研究评分模型么?我们也在筹划类似产品,我拉一个群,可以一起探讨一下么?欢迎入群:QQ290061204