
 起点课堂会员权益
起点课堂会员权益大模型微调后,可上线的标准是什么?
随着大模型微调技术(尤其是LoRA轻量参数微调)的广泛应用,如何判断一个微调后的模型是否可以进入上线测试阶段,成为了一个亟待解决的问题。本文结合心理场景项目中的实践经验,详细探讨了大模型微调后上线前的评估标准。

在大模型微调(尤其是LoRA这种轻量参数微调)成为主流后,我们会遇到了一个标准问题:
“模型我们已经调好了,但它现在能上线实测了吗?”
“有没有标准来判断这个模型已经‘调完’了”
今天笔者就结合在心理场景项目中的经验来讲讲:LoRA微调之后,模型上线测试前到底应该怎么评估?
01.我们训练的不是一个“答案模型”,而是一个“行为角色”
微调训练的目标不是一个通识模型,而是一个具备特定场景下、特定行为风格的定制模型。因此,评估的目标有三个:
- 行为是否对齐:模型是否按照你设定的风格、语气、角色在回应?
- 任务是否完成:模型能否在预期场景下完成目标(如引导、共情、建议)?
- 稳定性是否合格:是否在多个相似输入下都能保持一致逻辑、不掉入幻觉或乱答?
这三个维度必须同时评估,才可以判断微调是否“收官”,进入上线实测阶段。
[fancyadid=“45”]
特别是在心理、教育、客服、对话式产品中,你微调后的模型不只是知识更丰富了,而是应该更像你想要的那种人,比如:它要更温柔/更能共情/更会引导。
接下来我们分机器评估和人工评估两个部分来讲清楚。
02.机器评估:能跑通的基础验证,但不能替代人工判断
目前主流大模型平台都提供了评估机制,大致包括以下几个方面:
1.Loss(损失值)
衡量模型在训练或评估过程中的预测误差,是最基础的优化目标。Loss越低,说明模型越贴近训练数据的标签。
适用于:
- 不同阶段或数据集下的对比;
- 监督任务和指令微调阶段的趋势监控
但要注意:Loss下降≠泛化能力提升,还需结合其他指标判断。
2.Perplexity(困惑度)
衡量模型在生成下一个token时的置信度。这个值越低,说明语言建模效果越自然、自信。
适用于:
- 通识语言模型评估;
- 对话策略类微调的参考价值有限
3.BLEU/ROUGE/METEOR分数
用于衡量生成文本与参考文本的相似度,适合QA、摘要、翻译等任务。
不适用于:
- 自由表达类任务(如开放对话)
- 风格自由但语义合格的生成
4.ChatScore/ModelQualityScore(部分平台定制)
ChatScore或模型评分机制,是“非统一标准”,多数是平台自研或社区共识工具,它泛指一类用模型自身或另一个模型,来判断回答质量的评估方法。常见的做法包括:
- 对比式评估(PairwiseRanking): 给两个回答A/B,请模型或人判断哪个更好,算累积“胜率”
- 打分式评估(ScalarScore):模型看完问答后,给一个1~10的质量分数
- Embedding比对(Similarity):多用于QA、搜索场景,输出与目标答案向量比对,看相似度是否足够高
03.人工评估:LoRA能不能上线的决定性指标
机器分数只是辅助,真正决定“是否上线”的,是目标用户能不能接受它的表现。建议从以下四个维度进行人工评估:
1.任务完成度评估(最关键)
部分场景下,对话类模型评估的核心,不只是“答不答得对”,而是:有没有完成对这个人的陪伴或支持任务?
📌以“拖延”为例:
不是看模型有没有提供“拖延解决方案”,而是看它是否:
- 能理解并接住用户的情绪
- 能温和引导对方看见情绪背后的动机
- 能给出适当、小步、不压迫的建议(或允许暂时不做)
示例判断:
用户说:“我又拖到最后才开始,真的烦死了。”
- A模型回答:拖延是因为你对结果缺乏预期,可以尝试时间分块。
- B模型回答:听起来你内心有些疲惫,又不想放弃。这种拉扯是很常见的,我们可以从呼吸开始。
→显然,B更符合心理陪伴场景的“任务完成度”
2.行为风格一致性
你训练它成为“温柔型”、“正念型”、“洞察型”?那它现在还保持这种风格吗?
❌常见问题:
- 风格跳变,一会儿温柔,一会儿训人
- 一轮很会听,一轮突然打鸡血
推荐评估方式:
- 用统一的输入测试多轮风格是否稳定
- 多人评分时,可以提供评分模板
3.表现稳定性&多样性应对能力
一定要测试不同情绪强度、表达方式下模型的稳定表现。
📌以“拖延”为例:

4.安全性&不当言论排查(心理场景尤其重要)
避免:
- “你现在必须开始!”(强建议、压迫感)
- “你这是懒惰”(标签化、诊断式)
- “别想太多,坚持一下就行了”(压抑情绪)
📌 LoRA有时会“过拟合人类话术”,变成“口头禅生成器”,也要注意。
04.评估流程建议(LoRA微调后的推荐路径)
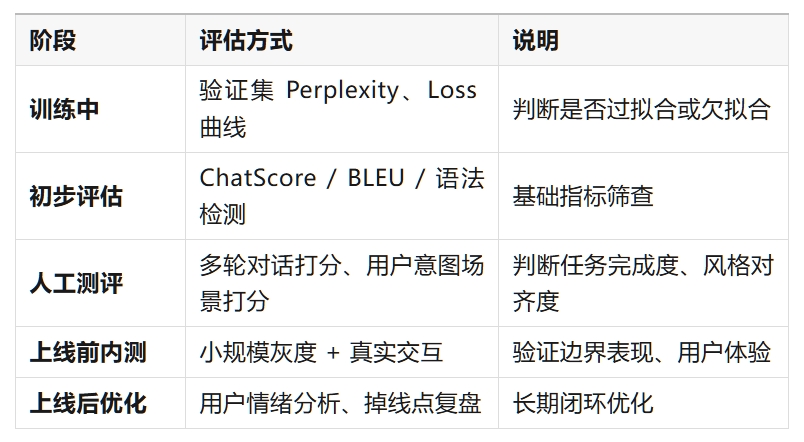
05.结语
LoRA微调的“轻”与“快”虽然让我们能迅速产出模型,但这也意味着:你必须更谨慎地评估它的行为边界与质量标准。
一个可以上线测试的微调模型,应该满足以下三点:
✅ 完成了预期场景任务(如拖延→共情+引导+支持)
✅ 语言风格一致、可信,无AI腔
✅ 能稳定应对不同输入,没有伤害性输出或误导性建议
如果你也正在打造一个面向心理、教育、咨询、服务的AI产品,希望这篇文章能成为你在“是否上线”这道门槛前的一盏灯。
本文由 @养心进行时 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


