
 起点课堂会员权益
起点课堂会员权益全网AI看不到的爱心,被这款开源全模态模型攻克了。。
美团刚开源首款全模态实时交互大模型 LongCat-Flash-Omni,竟让多国 AI 检测器失效,还能同步处理音视频图文,低延迟交互超 8 分钟。解对高考数学、认准狗子品种,更凭开源,原生全模态打破 AI 交互局限

昨天一大早,就发现美团开源了他们首款全模态实时交互大模型:LongCat-Flash-Omni。
立马上手体验了一下,最让我惊艳的是这个:
不儿?这个让一众国内外AI全部翻车的 AI检测器失效了
在视频对话前,我没有给它任何暗示或者明示的上下文,而且测了很多次。

不清楚的朋友可以看一下卡子哥(@数字生命卡兹克)前两天这篇10万+文章
我本来以为是实时的视频流是拯救了AI,结果不是,因为ChatGPT怎么都看不懂。。
因为ChatGPT App不支持录屏的时候录语音,所以只能再拿一个手机来拍了。。
大家也可以试试别的有视频流理解能力的大模型
以后,应该也可以用来导盲,它还是认路的。
不得不说,美团今年下半年实在是太活跃了,陆续开源了多款大模型。
比如国庆前开源的LongCat-Flash-Thinking,我也写过一篇文章,确实有点东西。
今天发布的这个模型,有两个关键词让我非常兴奋:开源、全模态实时交互
然后,我们来聊聊LongCat-Flash-Omni的全模态实时交互。
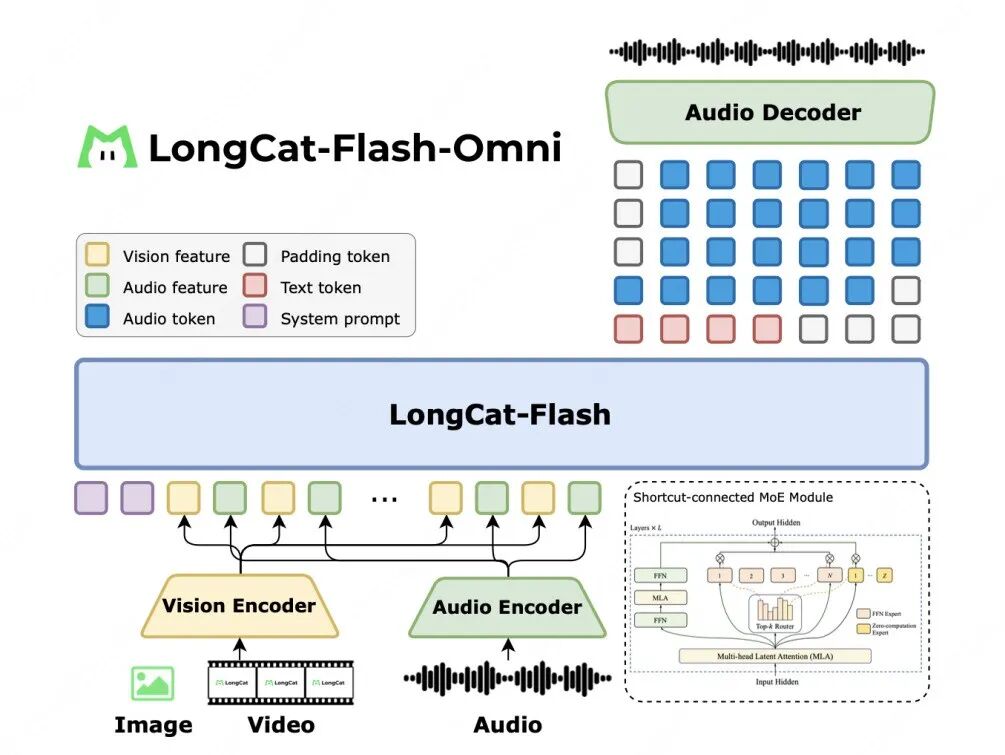
LongCat-Flash-Omni是一个all-in-one的一体化模型。不仅能处理我们常见的文本,图像,还能同时处理音频和视频。
同时,它能处理这些模态的任意组合输入。比如你可以一边给它看视频,一边用语音跟它说话。可以直接生成语音输出(这在之前是需要一个专门的TTS模型来搞定的)。
这意味着,它从输入到输出,整个链条是原生的全模态。它不再仅仅是一个你需要打字的聊天机器人,这个大模型有大脑,而且原生就长出了耳朵、嘴巴、眼睛,终于算是有一个完整的头啦。而且,它还是实时的。
LongCat-Flash-Omni是一个总参数量560B(平均激活参数27B)的混合专家模型(MoE架构),支持128K tokens上下文窗口和超8分钟音视频交互。
虽然参数量不小,但凭借完全端到端的设计,也实现了低延迟的实时交互。
PS:核心在于,它可以直接处理来自视觉和音频编码器的输入信号,并且能同时生成文本token和语音token。最后再由一个轻量级的音频解码器,把语音token快速转换成自然的人声。整个流程高度整合,以此实现了低延迟的实时交互。
再来看看它的考试成绩。
在OmniBench和WorldSense这两个最能体现全模态综合能力的榜单上,它在所有开源模型里,都是SOTA(最先进水平)。
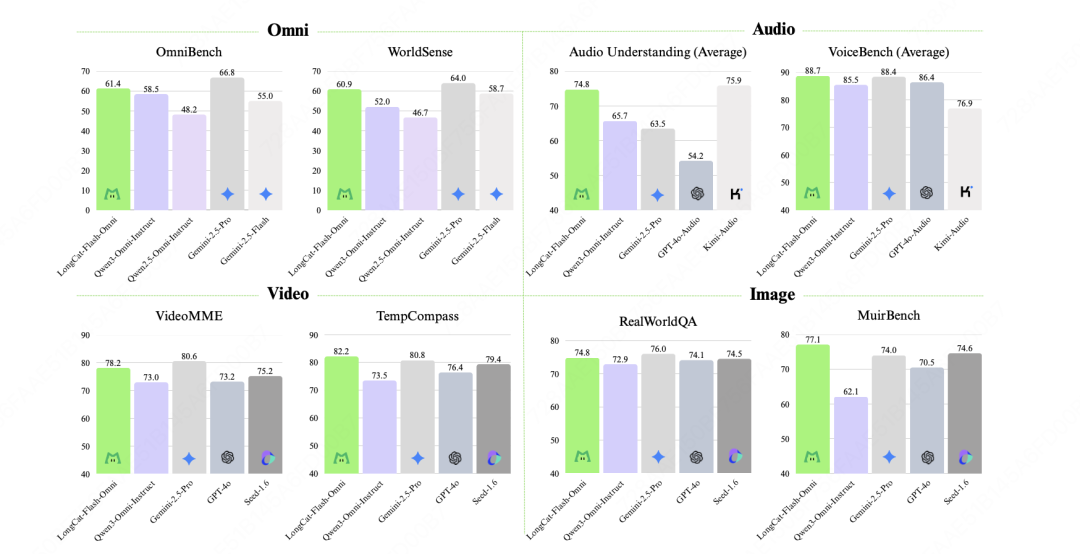
在Audio音频,Video视频,Image图像,这些单点能力上,也超越了市面上其他的开源模型。
看起来美团的这个模型,不是那种为了全模态而牺牲了单模态能力的偏科生。是在保证了文本,语音,图像,视频每一项都是顶级水平的前提下,再把它们很好的集成到了一起。
我第一时间研究了一下技术报告(论文)
https://arxiv.org/abs/2510.15227
并且下载了LongCat的官方App,做了一些简单测试。
对了,美团刚刚推出了他们第一款AI App:LongCat
在IOS上,可以直接在App Store搜索下载
技术报告里提到了一个词,叫「渐进式早期多模融合训练」。
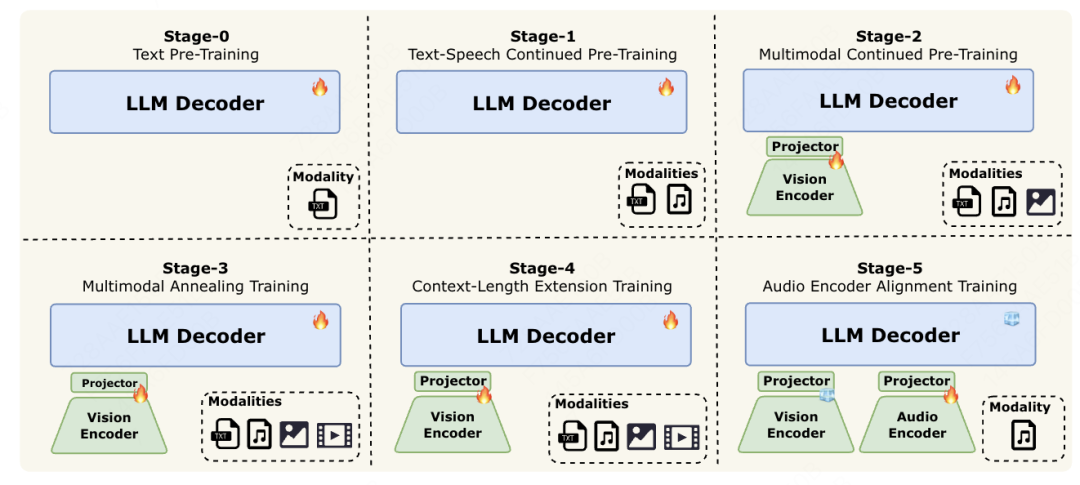
要训练一个全能的AI,最大的挑战,就是不同模态的数据分布存在显著异质性。
比如,你教它看图,它可能就忘了怎么听声;你教它看视频,它又忘了怎么合成语音。
美团的搞法,就非常像我们人类的学习过程,循序渐进。
你也可以把它想象成盖房子:
第一阶段,先打一个极其扎实的地基。这就是Stage-0,只用海量的文本数据,把模型最基础的读写能力和逻辑能力训练到极致。
第二阶段(Stage-1),开始盖房子的主体框架,在保留文本能力的同时,加入语音数据,让它学会听说。
第三阶段(Stage-2),开始装修和上窗户,加入海量的图像数据,让它学会看图。
第四阶段(Stage-3),开始通电和接水管。加入最复杂的视频数据,让它看片,理解动态的世界。
最后,再进行精装修,比如Stage-4的长上下文扩展(从8K扩展至128Ktokens),和Stage-5的音频编码器校准。
这种从简到繁的渐进式训练,保证了AI在学习新技能时,不会丢掉老本行。让它在每一个模态上,都打下了最扎实的基础。
接下来测试了一下,我比较看重的图片识别能力
丢了一张模糊不清的《孤独美食家》韩国釜山菜单给它

识别的还不错,很全面。

然后尝试识别并解答高考数学题


题目识别完全正确,但我没想到答案居然也完全正确!
确实如论文所说的,多模态能力上去了,数学能力也没落下呀。
丢了三月份个人AI公众号排行榜过去
看起来它对复杂表格数据提取效果也很不错,就是不知道这个新榜指数分析的对吗?
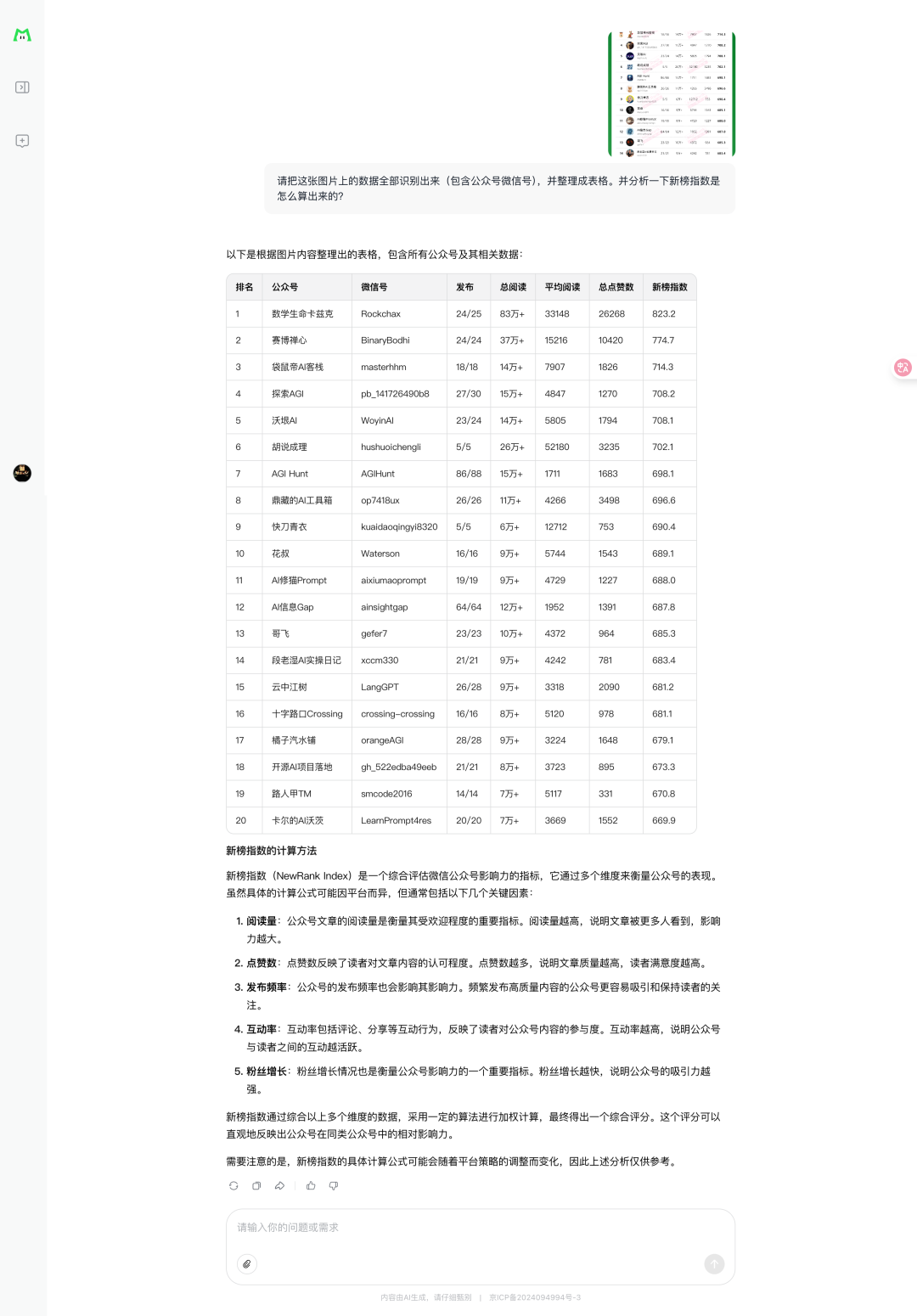
不过在图片识别层面,还是没有逃过这个AI检测器

最后我们再来看看它的视频理解能力
哈哈,让它认识一下我家狗子 哈尼
下面视频中各种要素都识别正确了,而且没想到狗子的品种居然也说对了
最后
体验完LongCat-Flash-Omni,我感觉我们和AI的主流交互方式,正在不可逆转的,从打字,转向语音。
甚至在不远的将来,主流方式会变成视频通话。
我们就像和真人一样,和AI面对面地交流,它能看到我们的世界,理解我们的处境,听懂我们的情绪,然后帮我们搞定一切。
一周前去了我堂姐家,本来想用AI帮她提效的,但是她把她的工作细节一说出来,我就愣住了。
我堂姐是在幼儿园做老师,她经常需要针对性的给小朋友制定学习计划:根据小朋友现阶段的学习情况,还有各方面的实时反馈(比如心情、学习积极性等等)来调整小朋友下一阶段的学习计划。
这完全就是一个实时变化的定制化场景。现有的AI基本很难提供什么实质性的帮助。
我当时给建议就是,得搞一个那种长着”眼睛”,”耳朵”的AI工具,然后挂身上实时感知小朋友的各种情况,才可能凑效。
比如把全模态大模型嵌入AR眼镜。
你戴着它走在街上,它实时看到你所看到的画面,实时听到你所听到的声音,能够通过眼镜架上的扬声器悄悄跟你对话,要是再接上脑机接口,你还能通过意念跟它沟通,那不是妥妥在身上挂了个萧炎的药老?
AI大模型的上半场更多的是在比拼思考、编程、Agent这些单点能力。
下半场,拼的肯定是能听,能说,能实时交互+强Agent能力的综合体验。
毕竟当AI更像人之后,才能更方便的为大家所用。
美团这次,不仅搬出了一个全能选手,而且他们模型一直都是开源的。
这格局,确实够大。
本文由人人都是产品经理作者【袋鼠帝AI客栈】,微信公众号:【袋鼠帝AI客栈】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。





- 目前还没评论,等你发挥!


