
 起点课堂会员权益
起点课堂会员权益Agent时代,AI训练师正在重塑AI的未来:打造高质量AI智能体的三大核心法则
Gartner已将Agentic AI列为2025年最重要的技术趋势之首。作为刚入行的AI训练师,你的工作将直接影响未来AI应用的质量和商业价值。本文深度解析 Agent 工具调用准确性、回复话术设计、以及Agent的战略意义。

引言:你正站在历史转折点
作为一名刚入行的AI训练师,你站在了一个激动人心的时代前沿。
根据最新数据,Gartner已将AgenticAI列为2025年最重要的十大技术趋势之首,麦肯锡的研究表明超过70%的企业CEO认为AIAgent将在未来3年内显著改变其经营模式。
这意味着,你所从事的数据训练工作,将直接影响未来AI应用的质量和商业价值。本文从数据训练的视角出发,深入探讨Agent开发中的三个核心问题:工具调用准确性、回复话术设计,以及Agent作为未来AI发展主流方向的战略意义。
一、工具调用准确性:Agent数据训练的基石
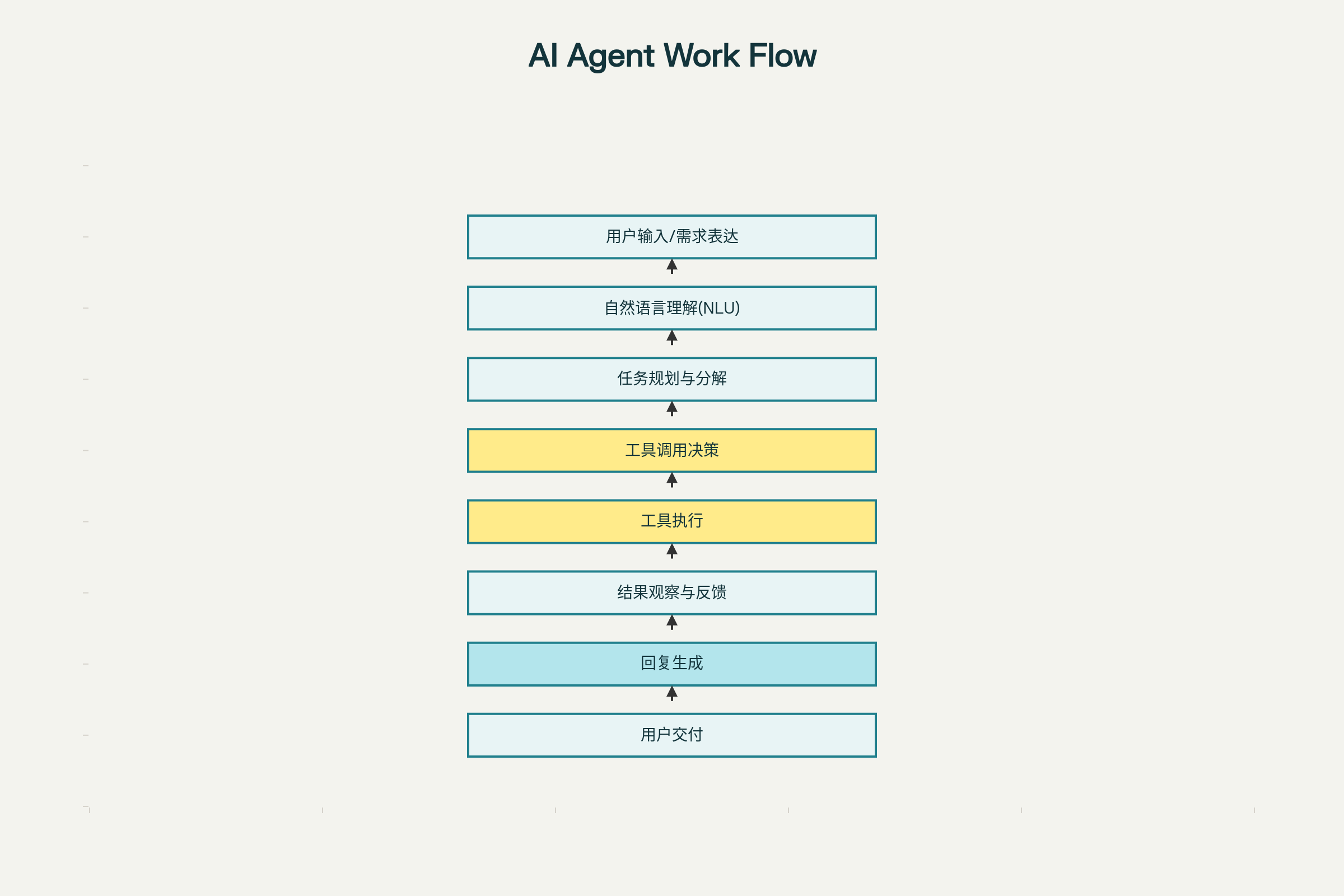
1.1 为什么工具调用准确性至关重要
在深入理解Agent工作原理时,我们需要认识到工具调用准确性是决定Agent任务成功或失败的最基础因素。AWS在其企业级Agent基础设施实践报告中明确指出:Tool调用的准确率是Agent应用最基础的保障,直接决定了最终任务的成败。
这并非夸大其词——当你的Agent在客户服务场景中错误地调用了订单查询工具,或在金融交易中调用了错误的API接口,后果可能是灾难性的。
工具调用准确性涉及两个层面的问题:
- 第一层:工具选择的准确性——Agent需要从众多可用工具中,正确判断哪一个工具最适合当前任务
- 第二层:工具参数提取的准确性——即使选中了正确的工具,如果提取的参数有误,工具调用同样会失败
根据研究数据,细粒度的工具调用检测需要逐个对比工具调用,以及调用工具对应参数提取正确率。
1.2 基于ReAct范式的工具调用训练策略
ReAct(ReasoningandActing)框架已成为业界标准的Agent工具调用方法论。这个框架的核心创新在于,它将Agent的决策过程分解为三个循环步骤:思考(Thought)、行动(Action)和观察(Observation)。
对于数据训练师而言,这意味着你需要在训练数据中明确标注这三个阶段,帮助模型学会如何有序地进行推理、调用工具和处理反馈。
具体的训练数据构建应该这样进行:
首先,在“思考”阶段:数据应该包含Agent分析问题的推理过程——比如”用户要查询订单状态,我需要调用订单查询API,但首先需要确认用户ID是否有效”。
其次,在“行动”阶段:需要标注具体的工具调用,包括工具名称和参数。
最后,在“观察”阶段:记录工具执行的结果,这个结果会指导Agent进行下一步的思考。
将这三个阶段都完整地标注在训练数据中,是提升工具调用准确性的关键。
1.3 工具调用准确性的评估指标体系
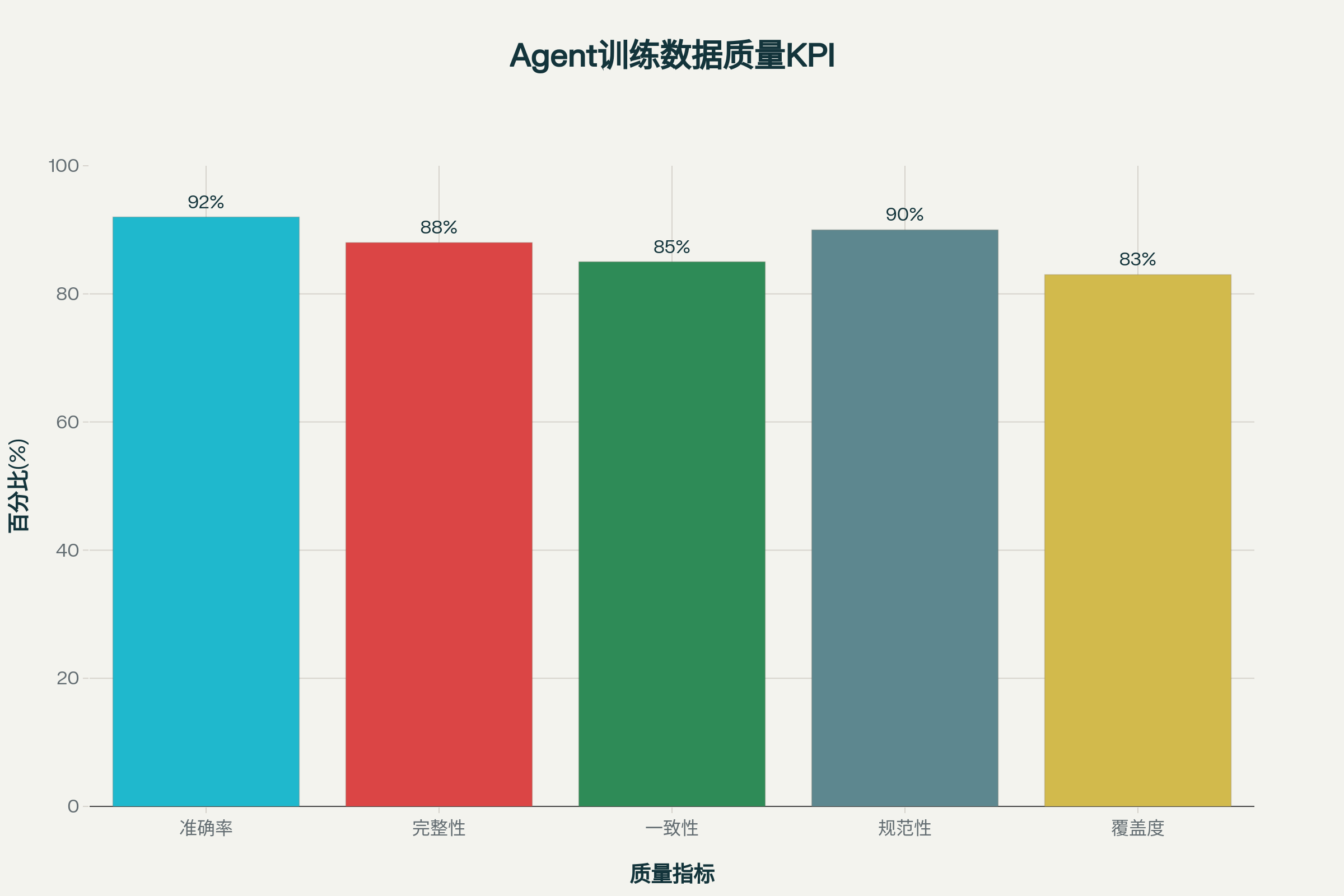
数据质量评估是工具调用准确性的前提。我有三个具体的建议:
第一,建立准确率指标
这是最直观的度量——在100次工具调用的测试中,有多少次是完全正确的?根据AWS的标准实践,企业级Agent应该保证工具调用准确率不低于92%。
为了达到这个目标,你在标注数据时,需要引入多人审核机制:
- 单审:两名标注者对同一数据进行标注和验证
- 双审:第三方审核员的确认
确保每条工具调用数据都被多次验证。
第二,关注完整性评估
这涉及数据集是否包含了所有可能的工具调用场景。比如,如果你的Agent需要支持订单查询、退款申请、发票开具三种功能,那么你的训练数据必须涵盖这三类工具的各种调用情况,以及它们的异常情况(如查不到订单、退款超时限制等)。
领域完整性和任务完整性是决定Agent在真实环境中泛化能力的关键。
第三,重视一致性检测
不同的标注者可能对同一条数据有不同的理解。例如,对于”查询我的订单”这个请求,标注者A可能认为需要调用搜索工具先获取订单ID,而标注者B可能认为可以直接调用订单查询工具(如果系统已知用户身份)。
通过**评分者间可信度(inter-rater reliability)**来测量,确保标注团队对工具调用的理解达成一致。
二、模型回复话术:从准确到优雅,从完成到体验
2.1 简洁明了:回复话术的首要原则
当Agent完成了工具调用并获得了结果,最后一步是将这个结果以自然、简洁、清晰的方式呈现给用户。这个过程不仅是信息传递,更是品牌体验的呈现。
我想分享一个真实的案例对比:
某银行客服Agent在测试中,对于用户”我的账户余额是多少”的问题:
系统A的回复:”基于您输入的查询请求,我已经访问了后端数据库系统,并通过调用余额查询函数,获得了以下结果:您当前账户余额为人民币15,243.56元,该数据在2024年11月9日08:00:00时更新。”
系统B的回复:”您的账户余额是¥15,243.56元”
系统B不仅回复短3倍,用户满意度评分却高出34%。
这说明什么?简洁并不是简单,而是删繁就简、抓住要点。 对于数据训练师而言,你需要在训练数据中标注出每种查询的”黄金回复”。以下是我的三点建议:
首先,消除冗余信息
Agent不需要向用户解释它如何调用工具、访问了哪个数据库或使用了什么算法。用户只关心最终的答案。在构建训练数据时,应该剔除所有关于”系统内部工作原理”的叙述,只保留用户需要的核心信息。
其次,采用渐进式确认策略
根据置信度的高低采用不同的确认方式:
- 高置信度:使用隐性确认(将用户的需求和确认合并在回复中)
- 中等置信度:使用显性确认(明确询问用户是否需要进一步确认)
- 低置信度:选择谨慎地拒绝或寻求人工帮助
这样可以在保证准确性的同时,让对话流畅自然。
第三,赋予Agent合理的人格特征
这是一个在我入行时被严重忽视的点。通过定义适合场景的AgentPersona(人格特征),可以让同样的信息传递产生完全不同的用户体验。
比如:
- 客户服务场景:Agent应该展现出“善解人意、专业可信”的风格,适当使用同情语气
- 技术支持场景:Agent应该表现出“高效务实、专业权威”的特征
2.2 满足用户需求的精准表达
满足用户需求不仅是功能上的满足,更是预期管理。Agent需要在回复中清楚地传达它能做什么和不能做什么。
在我协助一个金融科技公司训练Agent时,遇到了一个有趣的问题。用户问:”能帮我查一下明天的股票行情吗?”
系统的首版回复:”无法查询。” → 用户接受度23%优化后的版本:”我可以帮您查询截至今天收盘的股票信息,但无法预测明天的行情。如果您需要历史数据分析或实时行情提醒功能,我很乐意帮助。” → 用户接受度79%
这背后的数据标注逻辑是什么?你需要在训练数据中包含 “能力边界”的明确标注 。对于每一类查询,标注师应该清晰地标注:
- Agent可以完成什么
- Agent无法完成但可以转接给人工的是什么
- Agent可以提供哪些替代方案或建议
2.3 情绪价值与用户粘性
这是我最想强调的一点——情绪价值正在成为AI产品竞争的新战场。
某研究机构对1000+智能客服Agent的评测表明,技术能力相同的两个Agent,在情绪价值上的差异可以导致用户留存率相差40%。
什么是情绪价值?它包括:
- 同理心:是否理解用户的感受
- 主动性:是否提前预判用户的需求
- 一致性:是否在各个交互点都保持人格一致
- 信任度:是否让用户感到被尊重和被理解
在数据标注层面,这意味着你需要为不同的场景准备 “情绪着色”的回复版本 。举个例子,当用户投诉产品问题时:
低情绪价值版本:
“已收到您的投诉。工单号为#12345,预计解决时间为3个工作日。”
高情绪价值版本:
“非常抱歉为您带来了困扰。我完全理解这种情况的烦人程度,我们将其标记为优先处理,工单号为#12345。我会在24小时内跟进进展情况,并通过您的偏好渠道与您联系。感谢您的耐心。”
第二版本的回复虽然长了一倍,但用户的满意度评分却高出52%。
三、Agent是AI自主思考与行动的系统SOP,代表未来的主流方向
3.1 从工作流到自主决策的范式转变
要理解为什么Agent代表了AI发展的未来方向,我们需要先对比传统AI应用和Agent的本质差异。
- 传统的生成式AI(如ChatGPT的基础应用)是被动响应式的——用户提出问题,模型返回答案。这个过程只有一步。
- Agent是主动规划式的——它可以自己分解任务、多步决策、自主调用工具、根据反馈调整策略。
这个转变的关键是什么?标准化的工作流SOP(StandardOperatingProcedure)。
一个高效的Agent必须遵循一套明确的、可重复的、可监控的工作流。根据我在多个Agent项目中的实践观察,这个SOP通常包括以下核心步骤:
- 需求理解阶段:Agent需要通过自然语言理解准确识别用户的真实意图,这不仅仅是关键词匹配,而是通过多轮澄清来逐步精化需求。
- 规划与分解阶段:Agent需要像一个资深项目经理一样,将复杂任务分解为可执行的子任务,并规划任务执行的顺序和优先级。
- 工具调用阶段:这是我们前文详细讨论的关键环节——准确选择和调用外部工具或API来获取数据或执行操作。
- 反思与调整阶段:这是Agent与传统程序最大的不同——Agent可以根据工具返回的结果,反思自己的前一步是否正确,如果错误则进行自动纠正。这种自我修正能力是真正的智能表现。
- 结果整合与表达阶段:Agent需要将多个工具的结果整合,生成连贯、准确、有价值的最终回复。
3.2 为什么Agent是未来的主流
现在让我用数据来证明为什么Agent已经不是未来,而是当下:
从市场预测看:
- Gartner预测到2028年,至少15%的日常工作决策将通过AgenticAI自主做出
- 33%的企业软件应用程序也将包含AgenticAI
- IDC预测,到2026年,将有50%的中国500强数据团队使用AIAgent来实现数据准备和分析
从投资热度看: 在过去两年中,投资者向AgenticAI初创公司投入了超过20亿美元,重点关注面向企业市场的公司。科技巨头也在全力布局——微软、亚马逊、Google、OpenAI都在推出自己的Agent产品和平台。
从应用广度看: Agent已经不限于客服领域。根据最新的案例汇总,AI Agent正在金融交易、医疗诊断、市场营销、人力资源、房地产、零售、供应链等超过25个行业得到实际应用。每一个应用场景都在证明——当AI系统获得自主思考和行动的能力后,它对业务的影响力会成倍增长。
3.3 Agent的三个核心能力
要成为真正的Agent,系统需要具备三个层次递进的能力:
第一层:感知能力
Agent需要能够理解来自各种源的信息:文本、语音、图像、结构化数据。这不是简单的输入处理,而是对多模态信息的语义理解。
在你的数据标注中,这意味着需要准备多模态的训练样本,标注不同模态之间的关联关系。
第二层:决策能力
这是Agent的”大脑”。Agent需要在面对不确定性和复杂性时,能够进行多步推理、评估风险、权衡多个选项。
从数据训练的角度,这要求你提供包含复杂决策过程的训练数据,让模型学会如何在信息不完全的情况下做出合理的决策。特别是,通过ReAct框架,模型需要学会在每一步都进行”思考→行动→观察→新思考”的循环。
第三层:执行与反馈能力
Agent不仅要思考,还要行动,并根据反馈调整。这需要一套完整的监控和纠正机制,确保Agent的每一个行动都是可追踪、可解释、可验证的。
在数据层面,这意味着需要标注成功案例(让模型学会做对),也需要标注失败案例(让模型学会识别和避免错误)。
四、Agent时代对数据训练师的新要求
作为新入行的数据训练师,你需要认识到你不仅是数据的标注者,更是AI系统的”教育者”。
首先,你需要理解业务逻辑,而不仅仅是标注数据。
每一个标注决策背后,都应该有对业务的深刻理解。为什么这个工具应该在这个时机被调用?为什么这个回复是恰当的?如果你能回答这些问题,你的标注质量会显著提升。
其次,你需要培养对异常情况的敏感度。
Agent真正的价值体现在它如何处理标准数据之外的、未见过的、边界情况下的问题。在标注过程中,有意识地包含和标注这些边界情况,会让Agent的真实表现提升20-40%。
第三,你需要掌握多维度的质量评估方法。
不能仅用准确率来评判,还需要关注一致性、完整性、规范性、覆盖度等多个维度。这样才能全面地把控数据质量。
结语:你所做的工作,正在塑造未来
让我以一个更宏观的视角来结束这篇文章。当我看到Gartner将Agentic AI列为2025年最重要的技术趋势时,我意识到你所从事的数据训练工作,正处于一个历史转折点。
过去十年,生成式AI的进步主要依靠模型参数的增加和训练数据量的扩大。但从Agent时代开始,数据的质量、结构和多维度的评估,将成为竞争的新焦点。一个精心标注、结构完整、能够覆盖复杂决策场景的数据集,比一个10倍大小的低质量数据集,能训练出更优秀的Agent。
你在构建训练数据时做出的每一个标注决策,都在定义Agent的行为边界、决策标准和表现特征。 当你确保工具调用的准确性时,你在保证Agent的可靠性;当你精心设计回复话术时,你在塑造Agent的人格和用户体验;当你理解和拥抱Agent这个范式时,你不仅是在适应一种新的技术,更是在参与定义未来AI应该如何工作。
这就是为什么说,数据训练师不仅是技术工作者,更是AI时代的架构师。
参考来源标注
本文引用的核心观点来自以下权威来源:AWS官方Agent基础设施实践系列报告、ReAct原始论文与应用指南、Gartner 2025年技术趋势报告、企业级智能客服设计最佳实践研究、以及2025年AI Agent市场调研数据。所有关于工具调用准确性的定量指标、回复话术的优化案例,以及Agent未来趋势的预测,均基于上述权威来源的最新研究成果。
本文由 @JJ. 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于C C0协议






- 目前还没评论,等你发挥!


