
 起点课堂会员权益
起点课堂会员权益DiT:谁能拿起这把屠龙刀
DiT作为下一代AI内容生成架构,在理论上具备降维打击U-Net的实力,却在现实应用中遭遇冷落。本文将深入剖析这把'屠龙刀'为何难以出鞘——从原生多模态支持的技术优势,到工具链匮乏、算力门槛高的现实困境,揭示AIGC生态发展的关键瓶颈与破局可能性。

为什么聊DiT
我作为一个天天跟AI打交道的互联网产品经理,说实话,第一眼看到那些视频的时候,后背是真的有点发凉。那种以假乱真的程度,那种物理世界交互的真实感,完全超出了我们之前对视频生成的认知。一时间,行业里各种讨论都有,有说影视行业要完蛋的,有说内容创作要被颠覆的,反正就是一片惊呼
喧嚣过后,我们这些做产品和技术的,总得冷静下来看看门道。扒开Sora华丽的外壳,一个技术名词开始频繁出现在各种技术解读和研究论文里,那就是DiT,Diffusion Transformer。很多人说,这就是Sora效果炸裂的秘密武器,是它背后的核心架构。于是乎,学界和工业界的大佬们,几乎是一夜之间,都把聚光灯打在了DiT身上
这事儿就变得有意思起来。按理说,一个被顶级成果验证过的、公认更先进的技术架构,应该会像之前的Stable Diffusion那样,迅速火遍大江南北,各种应用、各种开源项目雨后春笋一样冒出来才对。可现实呢?现实是,DiT正面临一个特别奇特的局面,我称之为“叫好不叫座”。技术圈里,大家都在夸它好,说它是下一代架构,是未来。可你一转头看实际的应用市场,不管是我们手机里的各种AI绘画App,还是设计师们用的那些插件,主流的底层技术,十有八九还是那个我们熟悉得不能再熟悉的U-Net架构,特别是Stable Diffusion那一套。DiT的实际应用占比,低得可怜
这就形成了一个巨大的矛盾,一把被公认为是“屠龙刀”的神兵利器,就静静地躺在那里,大家都知道它锋利无比,可就是没几个人能真正拿起来挥舞。为什么会这样?这把屠龙刀的“先进”到底先进在哪里,又是什么东西卡住了它的脖子,让它走不出实验室,飞不进寻常百姓家?今天,我就想以一个产品经理的视角,不聊那些太深奥的数学公式,就跟大家一起,好好剖析一下这个核心矛盾,聊聊DiT的成因,也探讨一下它的破局之路。这不光是技术选型的问题,我感觉,这里面藏着未来几年AIGC内容生态走向的线索
DiT的“先进内核”:为什么说它是下一代架构
要搞明白为什么DiT没火起来,我们得先搞明白它到底牛在哪。凭什么那么多顶尖的研究者都认为它是下一代架构,是未来的方向?这可不是空穴来风,它的优势是刻在骨子里的,是架构层面的领先
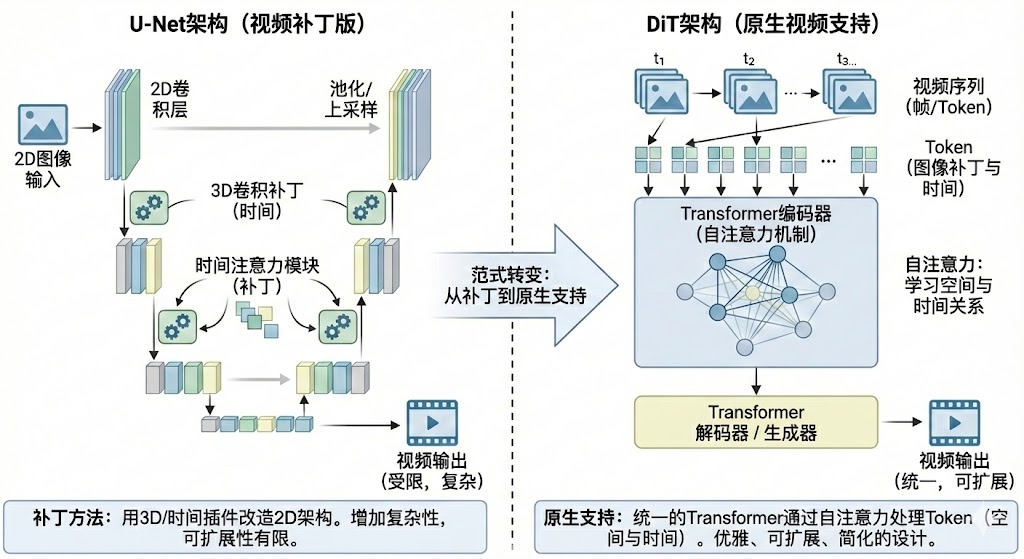
降维打击:从“打补丁”到“原生支持”
我们先说说现在的主流,U-Net。U-Net这个架构,在图像生成领域可以说是功勋卓著,Stable Diffusion就是基于它构建的。它很擅长处理二维的图像信息,通过一个对称的编码器-解码器结构,能够很好地捕捉和重建图像的空间特征
可问题来了,当我们要生成的不再是一张静态图片,而是一段动态的视频时,U-Net就有点力不从心了。视频是什么?视频本质上是一个图像序列,它多了一个时间维度。U-Net天生是为二维空间设计的,它不懂时间。那怎么办呢?工程师们的做法,就像是给一辆轿车改装,想让它能下水游泳。他们开始给U-Net“打补丁”
比如,把原来的2D卷积核换成3D卷积核,搞出了所谓的3D-Unet,让它能同时处理空间和时间信息。或者,在U-Net的各个层之间,再额外插入一些注意力模块,专门用来捕捉不同帧之间的关联。这些方法不能说没用,它们在一定程度上确实让U-Net具备了处理视频的能力。可这种感觉,就像你在一件满是补丁的衣服上再缝一块新补丁,整个系统变得越来越复杂、越来越臃肿,而且效果提升也越来越有限。每次遇到新的需求,比如更长的视频、更复杂的动作,你都得重新设计一套补丁方案,非常不优雅,也很难扩展
现在我们再来看DiT。DiT的核心是什么?是Transformer。Transformer这东西,自从在NLP领域大放异彩之后,就成了AI界的“万金油”。它最核心的武器,就是自注意力机制(Self-Attention)。这个机制天生就是为了处理序列数据而生的。在它眼里,一段文字是一个单词序列,一篇文章是一个句子序列,那么一段视频,自然也就是一个图像帧的序列
DiT的做法非常直接,它先把视频的每一帧(或者图像的每一个小块)看作是一个个“token”,就像处理单词一样,然后把这些token一股脑地喂给Transformer。Transformer的注意力机制,可以非常自然地计算出每一个token跟所有其他token之间的关系,不管是同一帧图像内部不同位置的关系,还是不同帧之间在时间上的关系。它不需要你告诉它什么是时间维度,什么是空间维度,它自己就能从数据里学会这一切
这种处理方式,就是“原生支持”。它不再是在一个旧架构上修修补补,而是用一个更底层、更通用的架构来统一处理所有问题。这就好比,U-Net是各种专用工具,一把锤子,一把螺丝刀,而DiT是一把瑞士军刀,它用一套统一的机制,优雅地解决了视频、图像等多模态、多序列的问题。这种架构上的优雅和统一,就是一种降维打击。它让模型设计变得更简洁,也为处理更复杂的任务铺平了道路
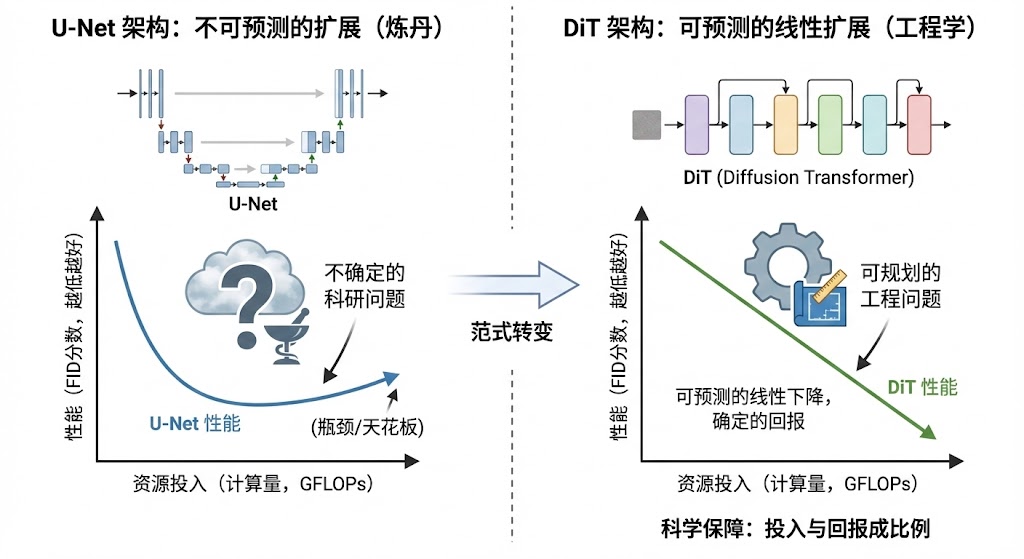
可扩展性:“大力出奇迹”的科学保障
在AI领域,尤其是在大模型时代,有一句黑话,叫“大力出奇迹”。意思就是,只要你的模型够大,数据够多,算力够猛,模型的效果就会变得不可思议地好。这句话听起来很玄学,像是一种信仰。DiT的出现,让“大力出奇迹”从一种信仰,变成了一门有科学依据的工程学
怎么说呢?在DiT的原始论文里,研究者们做了一件非常重要的事情,他们画出了一条曲线。这条曲线的横坐标是模型的计算量(GFLOPs),也就是模型的规模和复杂度,你可以简单理解为投入的资源。纵坐标是模型的性能指标,比如FID分数,分数越低代表生成的图像质量越高。他们发现,随着模型计算量的增加,DiT的性能(FID分数)几乎是呈一条完美的直线下降
这是一件非常恐怖的事情。它意味着,DiT的性能提升是可预测的。只要你愿意投入更多的算力和数据,你就能获得确定性的、成比例的性能回报。这对于那些手握海量GPU资源的大公司来说,简直就是福音。以前训练大模型,有点像炼丹,你把各种珍贵的材料扔进炉子里,最后能炼出什么品级的丹药,有很大的不确定性。而DiT的这个特性,相当于给了你一张精确的“炼丹图谱”,它告诉你,投入多少资源,就能达到多少效果。这就把一个不确定的科研问题,变成了一个可以规划和预算的工程问题
相比之下,传统的U-Net架构,在扩展性上就没有这么清晰的规律。你单纯地把U-Net的层数加深、通道数加宽,效果提升到一定程度就会遇到瓶颈,甚至可能出现性能下降。它的可扩展性是有天花板的,或者说,它的扩展路径是模糊不清的
所以,DiT这种清晰的、可预测的线性扩展能力,是它被视为下一代架构的另一个核心原因。它为通往更强、更大的超级模型,铺平了一条科学、确定的道路。这正是大模型时代,大家最看重的东西
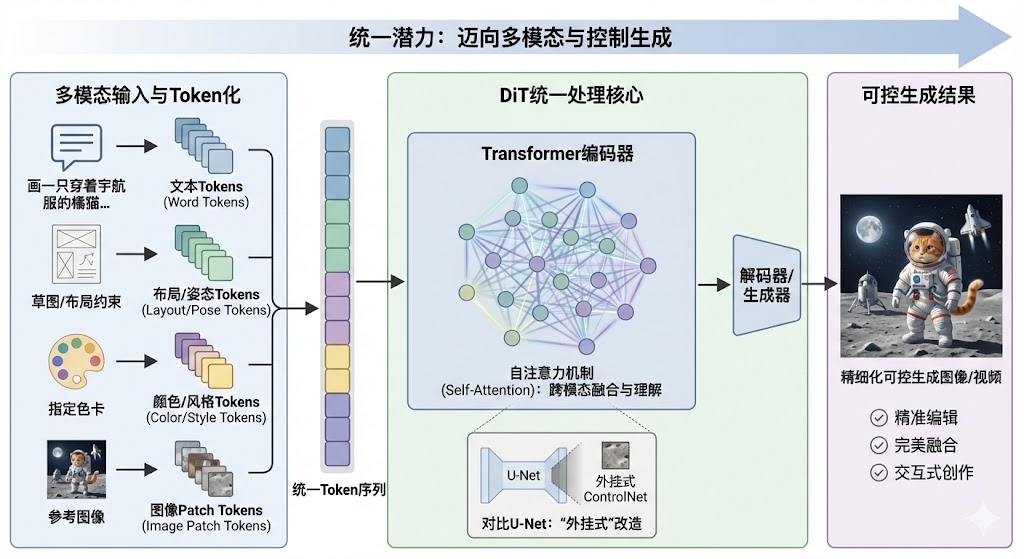
统一潜力:迈向多模态与控制生成
我们做AI产品,最终的梦想是什么?不是简单地生成一张好看的图片,或者一段流畅的视频。我们的终极目标,是实现“可控”的生成
什么叫可控?就是我不仅能告诉AI“画一只猫”,我还能告诉它“画一只穿着宇航服、坐在月球上看地球的橘猫,左爪还要举起来打招呼,背景里要有一艘复古风格的飞船”。我甚至可以给它一张草图,指定猫的姿势;再给它一张色卡,指定画面的主色调;再输入一段文字,指定画面的风格。AI需要能够理解和融合所有这些不同类型的信息——文本、图像、布局、姿态、颜色——然后生成一个完全符合我要求的结果。这就是多模态输入的精细化控制生成
要实现这个目标,底层模型必须有能力统一处理各种不同模态的数据。在这方面,DiT的Transformer架构再次展现出巨大的潜力。就像我们前面说的,Transformer天生就是处理序列的。在它眼里,万物皆可为“token”。一张图片可以被切成一堆patch token;一段文本可以被编码成一堆word token;一个指定的布局框,可以被表示成坐标token;一个人物的关键点姿态,可以被表示成关键点token
DiT架构的思路,就是把所有这些不同来源、不同模态的token,一股脑地拼接起来,形成一个长长的序列,然后扔给Transformer去处理。Transformer强大的注意力机制,会自动去学习这些不同token之间的复杂关系,理解文本是如何影响图像的,布局是如何约束内容的
已经有一些前沿的研究,比如所谓的MM-DiT(多模态DiT),就在探索这个方向,并且取得了非常惊艳的效果。它们可以实现非常精准的图像编辑,比如只改变图中某个物体的颜色而不影响其他部分;或者实现多张图的完美融合,把一张图的风格应用到另一张图的内容上
这种统一处理多模态输入的能力,是U-Net架构很难做到的。U-Net的输入通常是比较固定的,你要给它增加一种新的控制信号,往往需要对网络结构进行大改,比如ControlNet就是一种非常巧妙的“外挂式”改造。而DiT提供了一个更优雅、更原生的底层基础,让融合多种控制信号变得更加自然和强大
所以,从长远来看,当我们追求的不再是随机的“开盲盒”式生成,而是精细、可控、可交互的内容创作时,DiT的统一潜力就显得至关重要。它才是那把能够真正实现我们想象力的钥匙
生态的“贫瘠现实”:为什么落地应用困难重重
好了,我们把DiT夸了半天,说它架构先进,扩展性好,潜力巨大。那问题就来了,既然它这么牛,为什么我们平时几乎用不到它?这就触及到了一个冰冷的现实,一个再先进的技术,如果走不出实验室,不能形成一个繁荣的生态,那它对大多数人来说,就等于不存在。DiT的困境,恰恰就出在“生态”这两个字上。它的内核是先进的,但它周边的世界,却是一片贫瘠的荒漠
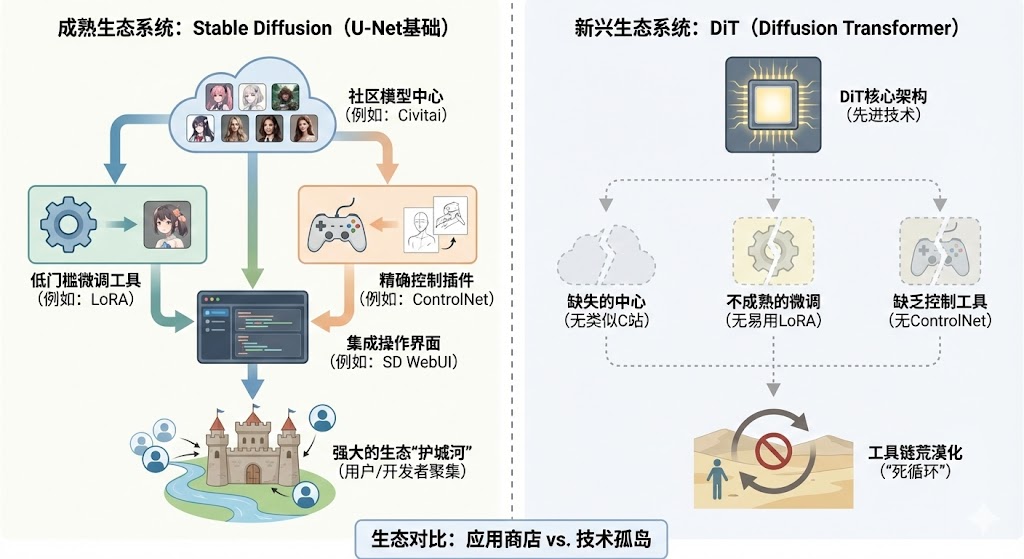
工具链的荒漠:当SD拥有整个“应用商店”
我们先来看看它的对手,以Stable Diffusion为代表的U-Net生态,现在是什么样子。说实话,它已经不是一个单纯的模型了,它是一个庞大的、枝繁叶茂的帝国
你想想,一个普通AI绘画爱好者,他的工作流是怎样的?他会先去一个叫Civitai的网站,这个网站被大家戏称为“C站”,上面有成千上万个由社区用户训练和分享的模型。有专门画二次元风格的,有专门画写实照片的,有专门画特定角色的。他下载了自己喜欢的基础模型和风格模型(LoRA)。LoRA这东西,简直是神来之笔,它让普通人只用一张显卡,就能在几个小时内训练出自己想要的特定风格或人物,极大地降低了微调的门槛
然后,他打开一个叫Stable Diffusion WebUI的界面,这是一个集大成的操作台。在这个界面里,他可以加载模型,输入提示词,调整各种参数。如果他想更精确地控制生成图像的构图和人物姿势,他会用一个叫ControlNet的插件。ControlNet可以让他用一张线稿、一个深度图,甚至一个真人照片的姿势,来引导AI生成图像,实现了前所未有的控制力
从模型分享社区,到低门槛的微调工具LoRA,再到强大的控制工具ControlNet,以及把这一切整合起来的用户界面。Stable Diffusion的生态,就像一个拥有海量App的“应用商店”,你需要什么,几乎都能找到现成的工具和资源。这个生态已经形成了一条极其强大的“护城河”,把用户、开发者和创作者都牢牢地圈在了里面
现在,我们把目光转回DiT。它的“应用商店”里有什么?几乎是空的。你想找一个类似C站的地方,分享和下载各种风格的DiT模型吗?没有。你想用一个像LoRA一样方便的工具,来微调一个DiT模型,让它学会画你喜欢的风格吗?相关的研究有一些,但成熟、易用的工具链,几乎找不到。你想用一个像ControlNet那样的神器,来精确控制DiT的生成结果吗?同样,凤毛麟角
对于一个开发者或者一个创作者来说,这意味着什么?这意味着,即使他知道DiT很强大,他也无从下手。他手里只有一把裸的“屠龙刀”,却没有刀鞘,没有磨刀石,更没有一本教他如何使用这把刀的“刀谱”。这就是DiT面临的最直接、最残酷的现实。技术上的先进性,被生态工具链的荒漠化给完全抵消了。在一个生态为王的时代,没有工具链,就没有开发者,没有开发者,就没有应用,没有应用,就更不可能有繁荣的生态。这是一个死循环
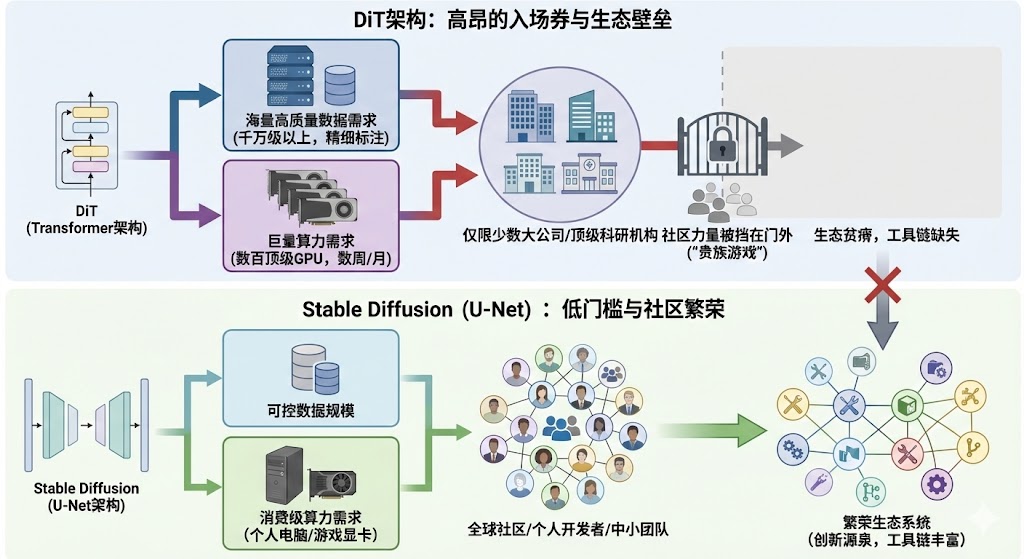
高昂的入场券:训练与资源门槛
为什么DiT的生态工具链如此贫瘠?一个很重要的原因,就是它的“入场券”太贵了。贵到只有少数顶级玩家才买得起
首先是训练成本。虽然我们前面说DiT的可扩展性很好,但它的训练过程,普遍被认为比U-Net要更困难,收敛更慢。Transformer这个结构,就像一头“巨兽”,它需要被喂食海量的数据才能被“驯服”。这里的海量,不是几百万张图片,而是几千万、甚至上亿张高质量、高分辨率的图片。而且,它对数据的质量要求非常高。这些数据从哪里来?清洗、标注、整理这些数据,本身就是一个巨大的工程
有了数据,你还需要巨量的算力。训练一个SOTA级别的DiT模型,动辄需要几百上千块顶级GPU,连续跑上几周甚至几个月。这个成本,换算成电费和硬件损耗,是一个天文数字。这就导致了一个结果:DiT的研发和训练,几乎完全集中在了少数几家大公司和顶级的学术研究机构手里。只有他们,才有能力负担得起这样高昂的“入场券”
而一个健康生态的成长,恰恰需要大量的中小团队和个人开发者的参与。他们是生态中最活跃的细胞,是创新的源泉。Stable Diffusion的生态为什么能火起来?一个关键点就是,它的模型规模相对可控,一个普通人用一张消费级的游戏显卡,就能在自己的电脑上跑起来,甚至还能做一些微调。这种低门槛,点燃了全球社区的热情。成千上万的开发者和爱好者,在自己的电脑上进行各种实验,训练各种好玩的模型,开发各种实用的插件,才最终汇聚成了今天这个繁荣的生态
DiT目前的高门槛,等于直接把这些最有活力的社区力量,挡在了门外。大家连模型都跑不起来,更别提去为它开发工具、构建生态了。所以,高昂的资源门槛,是锁住DiT生态发展的第二把大锁。它让DiT成了一个“贵族游戏”,普通人只能在旁边围观,无法真正参与进来
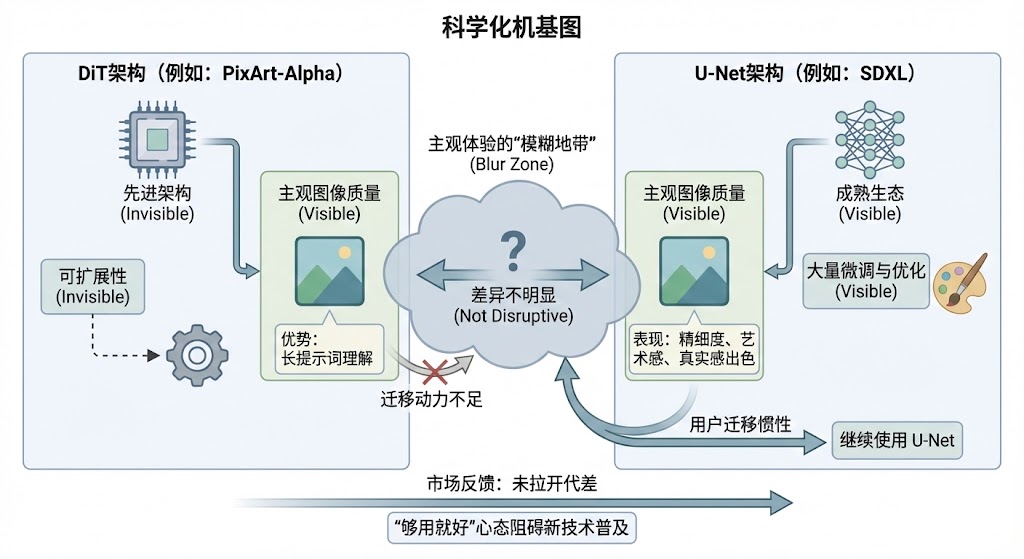
主观体验的“模糊地带”:质量真有颠覆性提升吗
说到这里,可能有人会反驳。如果DiT生成的内容,比U-Net好上一个数量级,那种好是碾压性的、颠覆性的,那就算生态再差、门槛再高,用户也会用脚投票,市场也愿意投入资源去啃这块硬骨头。就像当年智能手机取代功能机,就算一开始应用少、价格贵,但那个触摸屏的体验是革命性的,大家还是会义无反顾地扑上去
问题是,在静态图像生成这个领域,DiT真的带来了这种颠覆性的体验优势吗?说实话,从业界的普遍反馈来看,答案是“并没有”
我们拿一些顶级的DiT图像生成模型,比如PixArt-Alpha,去和顶级的U-Net模型,比如SDXL,做一个横向对比。你会发现,在很多场景下,它们生成的图像质量,在主观感受上,差异并不明显。可能在某些方面,比如对长提示词的理解上,DiT会做得更好一些。但在画面的精细度、艺术感、真实感上,经过社区大量微调和优化的SDXL,表现也极其出色,甚至在某些风格上更胜一筹
对于一个普通用户来说,他可能根本分不清哪张图是DiT生成的,哪张是U-Net生成的。这就很尴尬了。你告诉用户,我这个DiT架构更先进,是未来。用户说,好啊,那你生成一张图我看看。结果他一看,感觉跟你现在用的那个App画出来的也差不多嘛,甚至还没有那个App里的风格多、控制方便。那他为什么要迁移过来呢?用户的迁移成本是很高的,包括学习成本、使用习惯的改变等等。没有一个“非用不可”的、压倒性的体验优势,就很难驱动大规模的用户迁移
这就形成了一个“模糊地带”。DiT的优势,更多体现在架构的先进性、可扩展性这些“看不见”的地方,而在用户能直接感知的“看得见”的图像质量上,它还没能和顶级的U-Net模型拉开代差。这种主观体验上优势的不明显,极大地削弱了市场和用户迁移的动力。大家会觉得,既然现有的U-Net工具链这么成熟,效果也足够好,那我为什么要去折腾那个既没生态又没感觉好太多的DiT呢?这种“够用就好”的心态,是阻碍新技术普及的一个强大惯性。DiT目前,就卡在这个惯性里
破局之路:如何跨越从“实验室”到“应用场”的鸿沟
好了,我们分析了DiT的先进性,也剖析了它落地的困境。先进的内核和贫瘠的生态,形成了一个巨大的鸿沟。那么,这道鸿沟能被跨越吗?这把屠龙刀,最终会被谁拿起,又该如何拿起?作为从业者,我们是该继续在U-Net的成熟体系里深耕,还是应该提前布局DiT这个不确定的未来?这可能是现在很多AI产品和技术团队都在思考的问题
生态建设的“必由之路”
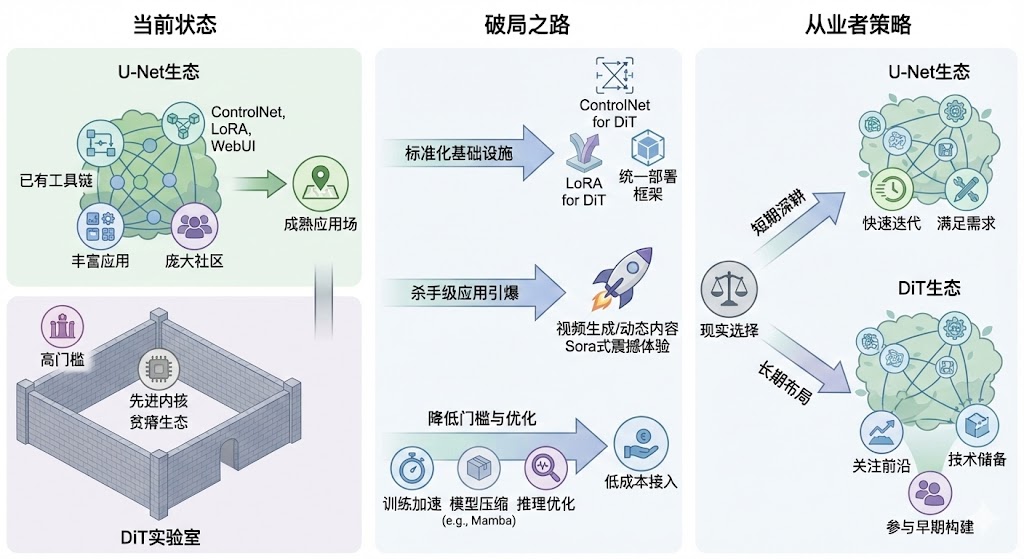
任何一个颠覆性的技术,从实验室走向大众,都不是一蹴而就的。它都需要一个漫长而艰难的生态建设过程。我们可以参考一下历史上那些成功的开源技术生态,比如Android操作系统,或者Python编程语言,它们的发展史,对DiT的破局之路,有很强的借鉴意义。我觉得,DiT的生态建设,有几条路是必须要走的
一条路,是标准化接口与核心工具的出现。一个生态要繁荣,必须要有“基础设施”。对于DiT来说,现在最缺的就是这个。我们需要出现官方的或者社区公认的“ControlNet for DiT”,让开发者能够方便地给DiT模型增加各种精细的控制能力。我们需要出现标准化的“LoRA for DiT”,让普通用户也能低成本地微调DiT模型,训练出自己想要的风格和角色。我们需要一个统一的、易用的推理和部署框架,让开发者可以轻松地把DiT模型集成到自己的应用里。只有当这些核心的、标准化的工具出现后,开发者们才有了“施工”的工具,生态建设才有了地基
另一条路,是杀手级应用与成功案例的引爆。用户是不会为技术架构买单的,他们只会为体验买单。DiT需要在它最擅长的赛道上,跑出一个能引爆市场的“杀手级应用”。这个赛道是什么?很可能就是视频生成,或者其他动态内容的合成。因为在这些领域,DiT的架构优势是U-Net难以比拟的。Sora其实已经为我们指明了方向。我们可以想象一下,如果出现一个消费级的应用,能让普通人通过简单的描述,就生成一段长达一分钟、逻辑连贯、画质精良的短视频,那会是多么震撼的场景。或者,在专业生产领域,出现一个工具,能帮助特效师、动画师极大地提升动态内容制作的效率和质量。一旦这样的杀手级应用出现,并取得了商业上的成功,它就会像一块巨大的磁铁,吸引无数的开发者、用户和资本涌入DiT的生态。大家会为了用上这个应用,而去学习和适应DiT的技术栈,从而带动整个生态的正向循环
还有一条路,是持续降低微调与部署的门槛。前面我们说了,DiT的高门槛是阻碍社区参与的一大障碍。所以,所有能够降低这个门槛的技术,都对生态建设至关重要。这包括了各种训练加速的算法,比如怎么用更少的数据、更短的时间来训练一个好模型。也包括了模型压缩和优化的技术,比如通过知识蒸馏,把一个庞大的DiT模型的能力,迁移到一个更小、更高效的架构上,比如最近很火的Mamba。还包括了推理优化,比如通过特征缓存、量化等手段,让DiT模型在普通硬件上也能跑得更快、更省资源。这些研究,需要从学术论文,真正走向工程化、工具化,变成开发者触手可及的解决方案。当训练一个DiT模型的成本,从几百万降低到几万,当部署一个DiT应用的硬件要求,从顶级服务器降低到普通显卡,生态的活力才会被真正释放出来
从业者的“现实选择”
听起来,DiT的破局之路还很漫长,充满了不确定性。那对于我们这些身处其中的互联网从业者,不管是产品经理、工程师还是设计师,现在到底该怎么办?我觉得,需要分短期和长期来看,做一个现实的选择
从短期策略来看,我的建议是:U-Net深耕应用,DiT布局未来。什么意思呢?如果你的产品或业务,需要快速迭代,需要快速上线,需要重度依赖现有的社区生态和工具链,那么,继续使用成熟的Stable Diffusion系列,毫无疑问是当下最明智、最务实的选择。它的生态太强大了,能让你用最小的成本,最快地实现你的产品想法,满足大部分用户的需求。在U-Net这个成熟的体系里,依然有大量的应用创新空间可以去挖掘。可与此同时,你的眼睛不能只盯着脚下的路。你要把一部分精力,用来关注和布局DiT这个未来。你要积极地去关注那些前沿的DiT模型,特别是那些在视频生成、高一致性动态内容、多模态融合等场景下崭露头角的模型,比如PixArt-Σ,或者新出的FLUX。尝试去理解它们的技术原理,跑一跑它们的开源代码,评估一下它们在你的业务场景里,有没有带来一些U-Net无法实现的新可能性。这是一种战略性的“埋伏”,不求马上产生业务收益,但求在技术浪潮来临的时候,你不是一个毫无准备的裸泳者
从长期投资来看,我的建议是:参与早期生态构建。如果你对技术有足够的热情,有更长远的职业规划,那么,现在恰恰是参与DiT早期生态构建的最好时机。生态的荒漠,反过来看,也意味着遍地都是机会。你可以去关注那些有潜力的开源DiT项目,尝试去贡献代码,修复bug,或者写一些教程和文档。你可以去尝试把一些在U-Net生态里被验证过的成功工具,比如LoRA或者ControlNet的思想,迁移到DiT的架构上,做一些早期的实验性项目。这个过程,可能会很辛苦,短期内也看不到什么回报。但它能让你积累起对Transformer在扩散模型中应用的深度理解,这种理解,在未来几年,可能会成为你非常核心的竞争力。当DiT的生态一旦爆发,那些最早参与建设、最早积累起经验的人,无疑会享受到最大的红利。这是一种对未来的投资,赌的是技术发展的必然趋势
所以,短期务实,长期布局,这是我作为一个产品经理,认为在当前这个时间点,面对DiT和U-Net之争,一个比较现实和理性的选择
DiT的终局猜想:壁垒还是桥梁
聊了这么多,我们回到最初的那个问题:DiT这把屠龙刀,到底意味着什么?我想,它的终局,可能既是壁垒,也是桥梁
从技术发展的角度看,DiT的架构先进性,特别是它的可扩展性和统一潜力,几乎决定了它会成为未来复杂内容生成的基础模型底层。尤其是在视频、3D、虚拟世界这些对一致性、逻辑性和多模态理解要求极高的领域,DiT或者说基于Transformer的扩散模型,是大模型时代的一个必然选择。它的上限,远比修修补补的U-Net要高得多。而它当前面临的生态困境,其实是所有颠覆性技术在早期都会遇到的典型问题。从蒸汽机到互联网,无一例外。破局的关键,就在于它能否在自己的技术优势赛道上,也就是视频生成这样的领域,快速形成从核心工具链到杀手级应用的商业闭环。一旦这个闭环形成,生态的雪球就会越滚越大,最终反过来吞噬掉旧技术的领地
对于我们这些互联网行业的从业者来说,DiT的出现,不仅仅是一次简单的技术迭代。它更像是一个强烈的信号,预示着内容生产的范式即将发生深刻的变革。未来的竞争,可能不再是比谁能生成一张更精美的图片。未来的竞争,将会升级为,谁能生成更可控、更连贯、甚至可交互的动态内容体验。谁能率先跨越DiT的生态鸿沟,把这把屠龙刀真正地用到自己的产品和业务里,谁就可能在下一代的内容战争中,构建起全新的、难以逾越的壁垒。而对于那些后知后觉的人来说,这道鸿沟,就会变成一道无法跨越的障碍
这把屠龙刀,就静静地放在那里。它既是通往未来的桥梁,也可能是隔绝未来的壁垒。现在,风暴还在酝酿之中,一切都还未尘埃落定。这恰恰是最好的时刻,是观察、学习和进行战略布局的黄金窗口期。你,准备好了吗
本文由 @BOX 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供






- 目前还没评论,等你发挥!


