
 起点课堂会员权益
起点课堂会员权益Anthropic的万字长文,讲了他们是如何评测Agent
AI Agent的开发过程中,评估体系常常被视为负担,但Anthropic的最新实践揭示了其关键价值:它能区分真实回退与随机噪音。文章深入解析了三种评分器的优劣对比、能力评估与回归评估的战略分野,以及8步构建评估体系的实战路线图,为AI产品团队提供了从早期测试到长期维护的全套方法论。

今天这篇文章,我想聊聊Anthropic这篇Blog的核心内容,以及我的一些实践思考。

这篇文章的原文链接我放在这里了:https://www.anthropic.com/engineering/demystifying-evals-for-ai-agents
为什么要做评估?
Anthropic在文章里提到一个现象:很多团队早期靠手动测试、内部试用、直觉就能走得很远,觉得评估系统是”额外负担”。
但问题来了——当Agent上线并开始扩展后,没有评估体系的团队会陷入一个死循环:
等用户投诉 → 手动复现问题 → 修复bug → 祈祷别的地方没出问题 → 重复以上步骤…
Anthropic说得很直白:评估的价值在于让你区分”真正的回退”和”随机噪音”。
没评估的团队,改了prompt不知道到底是有效还是无效;有评估的团队,失败变成测试用例,测试用例防止回退,指标取代猜测。
这个区别,真的很大。
三种评分器
Anthropic把评分器分了三类,这个分类挺实用的。
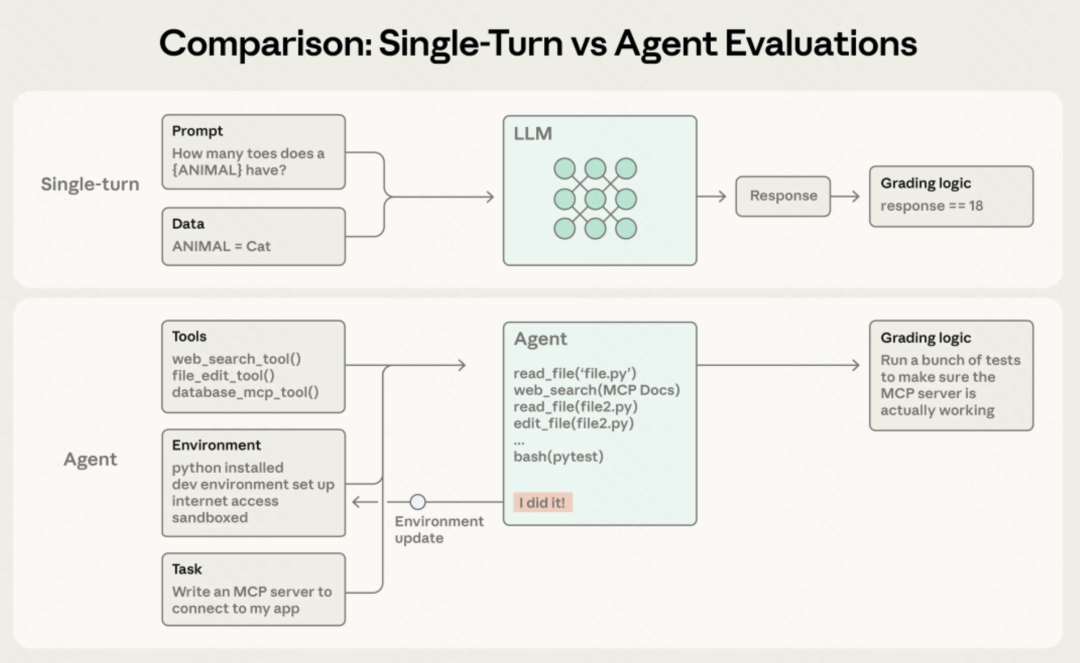
代码评分器:快、便宜、但太死板
方法就是字符串匹配、单元测试、静态分析这些。
优点很明显:快、便宜、客观、可复现、容易调试。
但缺点也明显:对有效但格式不同的答案太脆弱,缺乏细微判断能力。
模型评分器:灵活,但要校准
用LLM当评委,基于rubric打分、做自然语言断言。
优点是灵活、能处理开放式任务,比如评估客服的语气是否友好、解释是否清晰。
缺点是非确定性、比代码贵、需要和人类评分校准。
这让我想起之前一位前辈说的一句话:AI可以帮你完成80%的”脏活”,但那20%的核心判断必须靠自己。评分器也是一样,AI可以帮忙判断,但校准标准、定义什么是”好”,必须人来定。
人工评分:黄金标准,但太贵
领域专家审核、A/B测试这些。
是最准确的,但贵、慢、难以规模化。
Anthropic的建议很务实:能用代码评分的就用代码,必要时用模型评分,人工评分用于校准和验证。
能力评估 vs 回归评估:进攻战和保卫战
这个区分我觉得特别重要,很多团队混淆了这两个概念。
能力评估:进攻战
问的是”这个Agent能做好什么?”
特点:选择Agent目前觉得困难、经常失败的任务。通过率低也没关系,给团队一个”爬坡”的目标。
比如,我想让Agent能处理复杂的退款流程,早期通过率可能只有20%。但随着迭代,慢慢提升到60%、80%,这就是进步。
回归评估:保卫战
问的是”Agent还能处理之前会的任务吗?”
特点:测试Agent过去已经成功完成的任务。通过率必须接近100%,任何掉分都意味着新版本引入了bug。
当能力评估的通过率提高到很高时,可以”毕业”成为回归评估。这个思路挺好,曾经衡量”我们能做到吗”的测试,变成衡量”我们还能稳定做到吗”的测试。
两个关键指标:应对Agent的”神经刀”
AI Agent有个特性:相同输入下,每次运行可能产生不同结果。Anthropic提出了两个指标。
Pass@k:在k次尝试中至少成功一次
比如,Copilot给你生成代码时,它可能会给出5个方案。只要其中有1个是对的,你就会觉得”哇,这工具真好用”。
你不在乎另外4个是不是垃圾,因为作为人类,你会去挑选那个最好的。
适用场景:辅助人类的Agent。允许模型”发散”,只要它能提供灵感,就是有价值的。
Pass^k:在所有k次尝试中都必须成功
比如,银行客服Agent。用户不会给你5次机会让你”蒙”一个对的答案。用户要求的是:周一问你,是对的;周五问你,还得是对的。任何一次”发疯”都会导致信任崩塌。
适用场景:替人类干活的Agent。稳定性是全自动系统的生命线。哪怕单次能力再强,如果它是”神经刀”,在工业界就是不可用的。
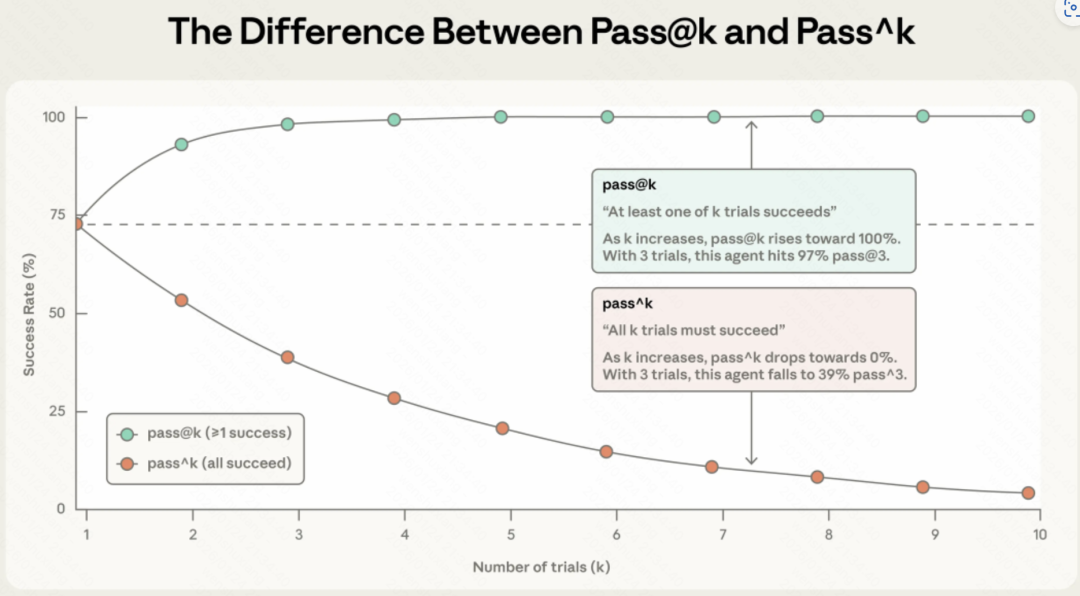
pass@k vs pass^k 对比图
这两个指标的曲线走向完全相反:Pass@k随k增加而上升,Pass^k随k增加而下降。
所以,选哪个指标,取决于你的产品形态。
8步构建评估体系:实操路线图
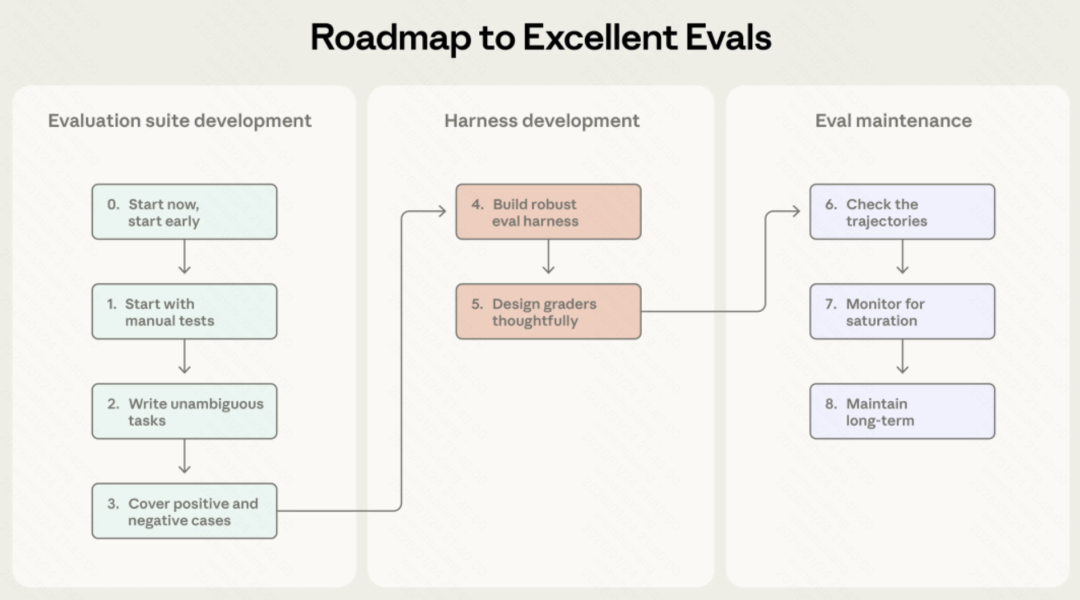
这部分是Anthropic的实践建议,我觉得挺实用的,逐条说说。
Step 0:尽早开始
很多团队拖着不做eval的理由都一样:”题不够多,做了也不准。”
但Anthropic说得很直白。早期20-50个真实失败案例就够了,因为早期你每改一行prompt,效果变化都很大,小样本就能看出差异。你拖到后期再做,改动带来的提升变小了,你反而需要更大、更难、更贵的评估才能测出信号。
Step 1:从你”已经在手测”的那坨开始
不需要上来就发明题库宇宙。你现在每次发版前怎么手动测的?用户最常点的功能是什么?线上工单里用户最常骂的是什么?这些就是你最该先写进eval的任务。
如果已经上线了——更简单:去翻bug tracker和support queue。把”用户报错”直接转成测试用例。
Step 2:任务必须”无歧义”,还要配”参考答案”
好任务的标准不是”我觉得描述清楚了”,而是:两个领域专家各自看一遍,如果专家自己都没法稳定通过,那任务就得返工。
Anthropic还提了个他们审计Terminal Bench时看到的翻车点:任务说”写个脚本”,但没说脚本存哪,grader却默认脚本必须在某个固定路径。结果Agent明明写对了,也被判失败。
这类eval最恶心:你以为模型不行,实际上是题坏了。
所以需要强制加一条工程规矩:每个task都做一个人类/脚本能跑通的标准解。它的作用不是”喂模型”,而是证明:
- 这题确实可解
- graders确实配对了
- harness没在暗算你
Step 3:题集要平衡
很多团队的eval都有一种”单边性”:只测该做的,不测不该做的。后果就是:你把Agent优化成一个偏执狂。
Anthropic在Claude的web search上就吃过亏:如果你只测”该搜的时候会不会搜”,你很快会得到一个”啥都搜”的模型——成本爆炸、延迟爆炸、还更容易引垃圾信源。
所以他们把题集做成两边都覆盖:
“查天气”—该搜
“苹果公司谁创立的”—别搜,直接答
目标就是卡住两种失败:
- undertrigger:该搜不搜
- overtrigger:不该搜乱搜
这一步做对了,后面你优化才不会越改越邪门。
Step 4:评估环境必须稳定
环境脏一次,你的指标就全是幻觉。
每次都要从干净环境启动,避免共享状态:遗留文件、cache数据、资源耗尽导致的flaky,甚至……上一次测试留下的git历史。
Anthropic有次发现Claude在某些任务上分数异常高,原因是它检查了之前试验的git历史——这就是环境隔离没做好。
Step 5:评分器要”想清楚”
很多人第一反应是:”我检查它是不是按顺序调用了A→B→C工具就行。”
Anthropic的结论是:太死板,测试会非常脆。因为强模型总能找到你没想到但完全合法的路径。
他们还补了三点建议:
- 能用确定性grader就用确定性
- LLM-as-judge用在”必须主观”的地方
- 人工只做校准
还有:给多组件任务做部分得分。
比如客服Agent能定位问题+验证身份,但退款没点成功,但是这也比一上来就发疯强多了。你得让指标能表达这种”差一点点就成了”的连续性。
还有一个问题是,怎么样让LLM裁判怎么不胡判?
- 用人类专家去校准分歧
- 设定”逃生门”,一旦信息不足就返回Unknown
最好按维度拆开单独判,而不是一个LLM把所有维度一锅端
Step 6:一定要读transcripts
这可能是文章中最容易被忽视但最重要的建议。
除非你阅读许多试验的记录和评分,否则你不会知道你的评分器是否工作良好。在Anthropic,他们投资了用于查看评估记录的工具,并定期花时间阅读它们。
当任务失败时,记录告诉你agent是真的犯了错误还是你的评分器拒绝了一个有效的解决方案。
失败应该看起来是公平的:很清楚agent做错了什么以及为什么。
当分数没有攀升时,我们需要确信这是由于agent性能而不是评估。阅读记录是你验证评估正在衡量真正重要内容的方式,是agent开发的关键技能。
Step 7:监控能力评估饱和
100%的评估跟踪回归但不提供改进信号。当agent通过所有可解决的任务时,就会发生评估饱和,没有改进空间。
比如,SWE-bench verified分数今年从30%开始,前沿模型现在接近80%的饱和点。随着评估接近饱和,进展也会放缓,因为只剩下最困难的任务。
这可能使结果具有欺骗性,因为大的能力提升表现为分数的小幅增加。例如,代码审查初创公司qodo最初对opus4.5印象不深,因为他们的一次性编码评估没有捕捉到更长、更复杂任务上的收益。作为回应,他们开发了一个新的agent评估框架,提供了更清晰的进展图景。
作为规则,在有人深入研究评估细节并阅读一些记录之前,我们不会轻信评估分数。如果评分不公平、任务模糊、有效解决方案被惩罚或框架限制模型,评估应该修订。
Step 8:通过开放贡献和维护保持评估套件长期健康
评估套件是一个活的工件,需要持续关注和明确的所有权才能保持有用。在Anthropic,他们尝试了各种评估维护方法。最有效的是建立专门的评估团队来拥有核心基础设施,而领域专家和产品团队贡献大部分评估任务并自己运行评估。
对于AI产品团队,拥有和迭代评估应该像维护单元测试一样例行。团队可能在”有效”的早期测试但未能满足设计良好的评估本会早期发现的未明确期望的AI功能上浪费数周。定义评估任务是压力测试产品需求是否足够具体以开始构建的最佳方式之一。
他们建议实践评估驱动开发:在agent能够完成之前构建评估来定义计划的能力,然后迭代直到agent表现良好。
在内部,他们经常构建今天”足够好”但押注几个月后模型能做什么的功能。从低通过率开始的能力评估使这变得可见。当新模型发布时,运行套件可以快速揭示哪些押注得到了回报。
最接近产品需求和用户的人最有能力定义成功。凭借当前的模型能力,产品经理、客户成功经理或销售人员可以使用claude code贡献评估任务作为pr:让他们这样做!或者更好的是,积极赋能他们。】
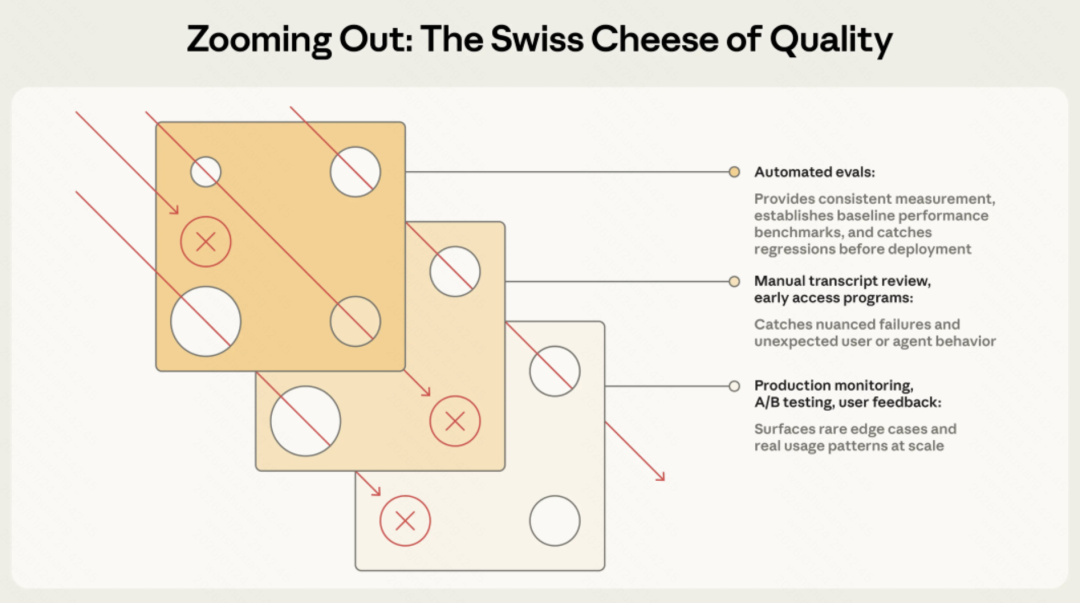
完整的图景:评估不是唯一手段
Anthropic还提到,自动化评估只是理解agent性能的众多方式之一。
完整的图景包括:
- 生产监控
- 用户反馈
- A/B测试
- 手动记录审查
- 系统性人工评估
就像安全工程中的瑞士奶酪模型一样,没有单一的评估层能捕捉每个问题。多种方法组合起来,穿过一层的失败会被另一层捕捉。
最有效的团队结合这些方法,自动化评估用于快速迭代、生产监控用于基准真相、定期人工审查用于校准。
价值是复合的,但只有当你把评估作为核心组件而不是事后想法时。
最后,我想说。
Anthropic这篇文章之所以有价值,不是因为提出了什么颠覆性理论,而是因为它是实战经验的总结。
从定义任务、设计评分器、构建框架到长期维护,每一步都是踩坑踩出来的经验。
如果你也在做Agent,我建议你花点时间读完这篇文章。哪怕只采纳其中50%的建议,你的开发效率和产品质量都会有明显提升。
本文由 @Ashcjka 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


