
 起点课堂会员权益
起点课堂会员权益DeepSeek V4要来了,但我更想聊它最近在“憋”什么?
DeepSeek的沉默背后,隐藏着比V4大模型更值得期待的战略布局。从Agent全链路人才储备到自建算力底座,这家公司正在构建一个完整的智能产品生态。当行业还在追逐参数竞赛时,DeepSeek可能正在酝酿一场真正的AI产品革命——从能对话的AI升级为能执行任务的智能体。

最近,上海财经大学特聘教授胡延平发了封“给DeepSeek的最后一封催更信”。
这封信说出了很多人现在的状态:既期待,又没耐心。
今年年初市场都在喊V4要来了。结果2月,没来。3月,又没来。现在说4月会发,但朋友圈的反应已经不是“期待”,而是“哦”。
别的厂商:大模型刷屏、功能发布刷屏、PPT刷屏。 DeepSeek:沉默。
所有人都在问:DeepSeek到底在干嘛?
我也好奇。所以我最近翻了一下招聘网站,想通过看它最近在招什么人、在做什么事,看能不能找到答案。
V4真正有意思的在水面之下
先说V4。
它会来,这是确定的。多模态已有灰度测试信号,Agent能力是确定的方向,百万token价格继续往下走基本也是确定的。
但这不是我想聊的重点。
你有没有注意到一件事——过去这一年,各家大模型你追我赶,参数刷新、榜单刷新、发布会刷新,但真实用下来,大多数人的感受是:好用了,但没什么特别大颠覆感。(反而不如海外来的”那只虾”带来的震感强烈)
你打开任何一个AI助手,让它写个方案、查个资料、搞段话术,它都能给你一个像模像样的答案——但你真的会把它的输出直接用吗?大多数时候,你还是要改,要复核,要重新组织,AI只是帮你省了一部分力气。
为什么会这样?是大模型能力不行?是,也不是。AI发展到今天,模型能力本身,已经不是什么瓶颈了。
真正的瓶颈在出口:你有再强的模型,如果没有一个好产品承接,用户感知不到,就什么都白搭。(”小龙虾”就是一个例子,OpenClaw的爆火,本质上就是模型能力在产品端应用的外化)
V4只是模型,模型的出口在哪,才是大问题。
我个人觉得DeepSeek比谁都清楚这件事。
它沉寂的这段时间,或许不是在“等”,而是在持续升级模型能力、做国产芯片的适配之外,还想搞清楚一件事:发完V4之后,拿什么去产品化。
从招聘看DeepSeek的真正方向
有人可能会杠,你凭什么这么认为?你又是怎么看出来的?
很简单,看看它正在招什么人,一家公司开始大量招聘什么方向的人,基本也就能确定它要干什么事儿。
我把DeepSeek官网近几个月的招聘记录扒了一遍(截至4月中旬),有几个信号,单看都说明不了什么,合在一起就很有意思了。
第一个信号:Agent,一次押上全链条。
3月24日,DeepSeek官网一口气发布了17个Agent相关岗位——算法研究员、数据评测专家、基础设施工程师、策略产品经理,一次全到位。这不是“探索方向”的姿态,是在搭完整的流水线。
而且有个细节值得注意:多个岗位的加分项里写着“重度使用Claude Code、Cursor、Copilot等AI编程工具优先”,Agent全栈工程师的岗位职责里甚至出现了“作为Vibe Coding重度用户”这种表述。
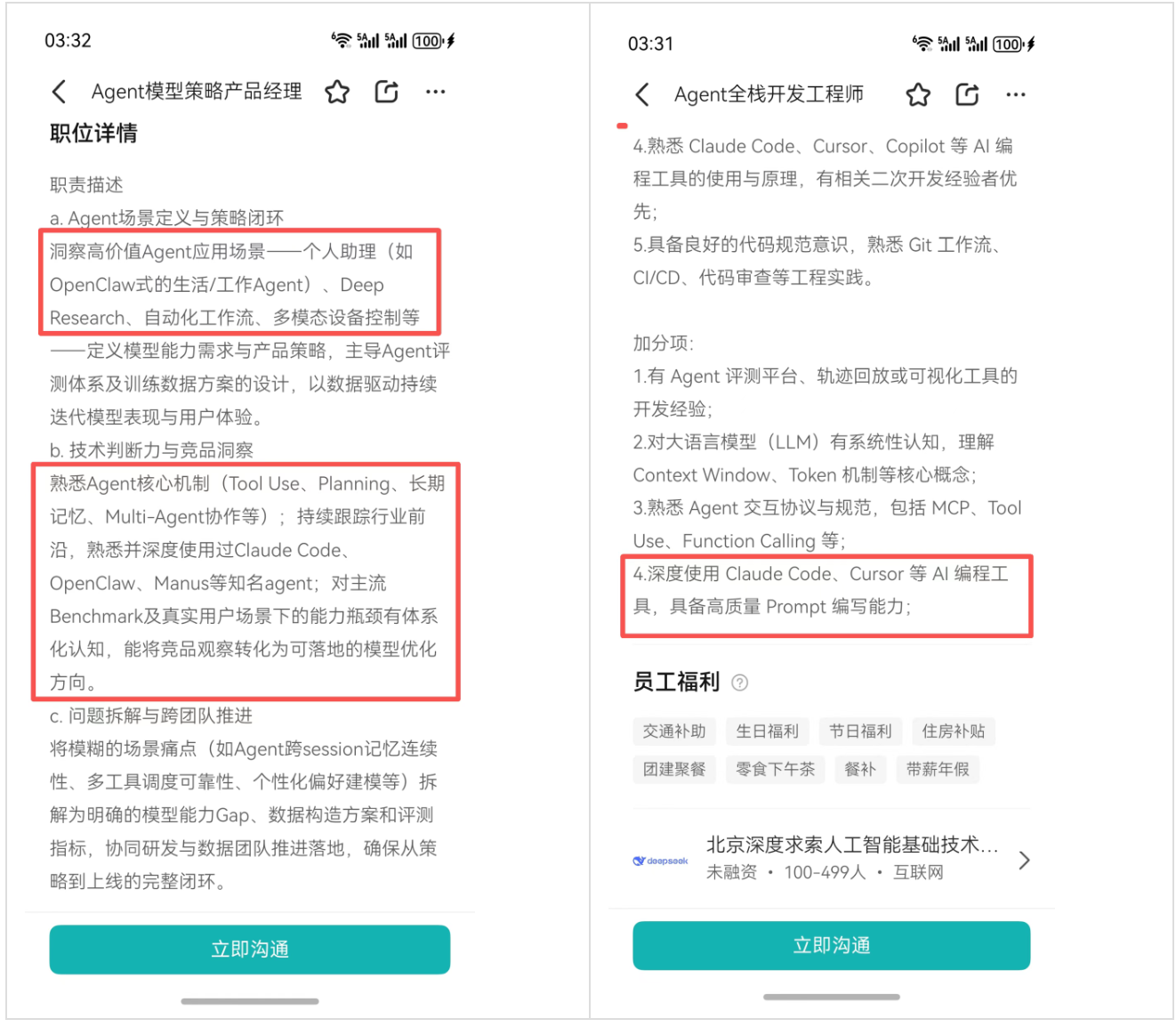
DeepSeek要招的不是“懂AI的人”,是“用AI的方式工作的人”。这个用人标准本身,其实就在隐约透露着它接下来想干什么。
第二个信号:搜索,一条更早布局的隐线。
这条线很多人没注意到。早在今年1月,彭博社就报道过DeepSeek在招多语言AI搜索引擎的开发人才,目标是做能同时处理文本、图像、音频的多模态搜索产品,对标的是Google和OpenAI。
搜索是AI产品里最难做、但用户黏性最强的入口。DeepSeek把这条线悄悄布了这么久,现在才被人注意到。
第三个信号:内蒙古,第一次招线下数据中心岗位。
这个信号最新,也最容易被忽视。4月,DeepSeek在内蒙古乌兰察布发布了数据中心运维工程师和交付经理的招聘。
如果没记错的话,这应该是DeepSeek第一次公开招线下基础设施岗位。
一家大模型公司开始招数据中心运维,意味着什么?意味着它在认真准备自建算力——不再完全依赖幻方量化原有的“萤火系列的自建算力集群”,而是正式为即将发布的万亿参数V4大模型(以及未来更高版本的模型)自建专属“算力工厂”。这也预示着DeepSeek正在通过算法优化与基础设施保障两条腿走路,来应对未来更高量级的竞争。
把这三个信号叠在一起看:Agent全链路、多模态搜索入口、自建算力底座——这不是零散的招聘动作,是一家公司在悄悄搭一个完整的产品底盘。
DeepSeek现在的APP,说实话,能力还很薄。基本就是接了大模型,做了个搜索框,多模态也还没正式上线、没有Agent能力、没什么让人离不开的东西。用起来像个“高配搜索引擎”,而不是一个真正的AI智能体。
所以,说到这,可以大胆预测一下,到时候和V4一起端出来的,很可能不只是一个“更聪明的对话框”。
如果真是这样,那就跟国内其他厂商的思路不太一样了。别家在做的事:大模型刷屏,API降价,应用层套壳。
DeepSeek在想的事:能不能做出一个真正帮用户把事干成且干漂亮的智能产品。(中国版原创的”小龙虾Plus”、Claude Code会不会来自DeepSeek?真的值得期待一下)
这个差别,决定了它下一步能走多远。
我为什么一直用DeepSeek
说远了。说说我自己这两年用下来的感受。
我日常用DeepSeek,并不是冲着“最强模型”这个标签去的。
我用它,是因为它在我日常的部分真实业务场景里相对更靠谱。
举个例子。我最近几个月在给一群学员做IP孵化陪跑,为了帮助大家更高效地产出内容,我给学员定制了一套系统级Prompt——学员先把这个Prompt丢给AI,然后把自己的口述录音稿发过去,AI就能整理并输出一份相对合规且基本可以直接拿去录制的视频脚本。
在这个过程中,学员不需要自己码字写脚本,毕竟不是所有人都有那么好的文笔,但是对着手机发语音把想表达的说出来就简单得多。
注意,这个Prompt,我是要求学员一定要用DeepSeek去执行,而不是豆包。
为什么?
因为DeepSeek出来的内容更可用,逻辑更顺,幻觉相对更少。这不是我自己测了几次得出的结论,是学员反复跑、反复用,对比出来的判断和反馈。
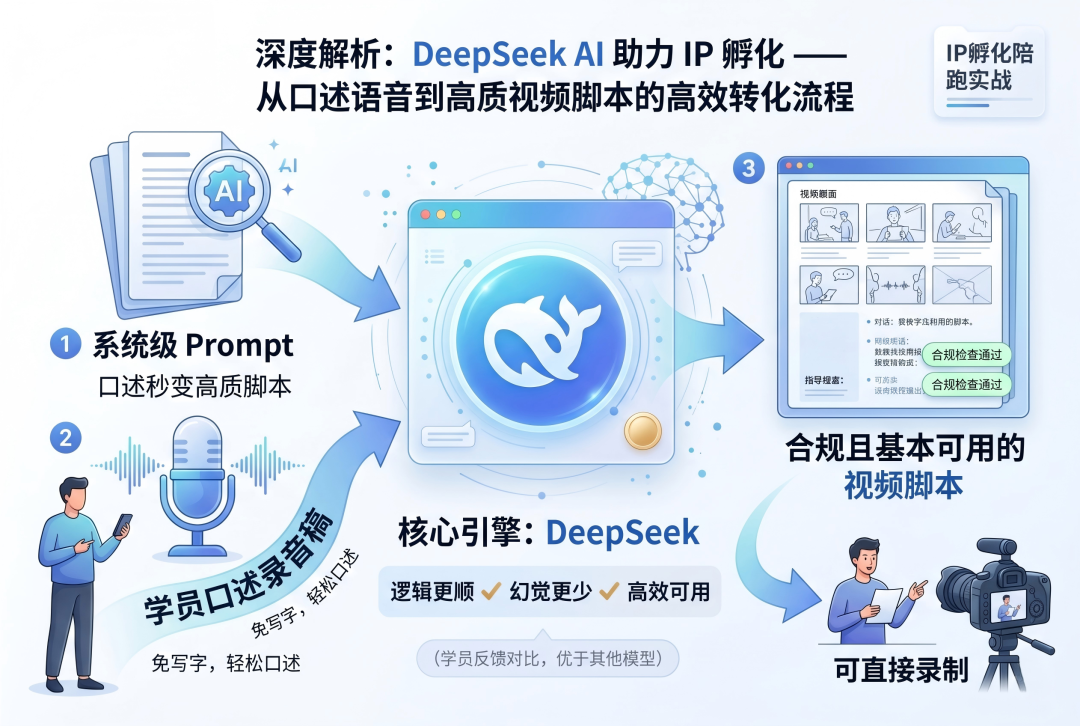
当然豆包不是不能用(它的搜索场景、人性化的语音也很给力),而是在一些业务场景下,它的输出稳定性不如DeepSeek。
这个差距看起来很小,但放在实际业务交付里,就很大。
国产模型中,我用得比较多的就是DeepSeek,不是因为它最火,是因为它相对更适合我现在在干的活。
说白了,它的模型底子已经足够扎实了,V4推出后基本上更没有什么悬念。缺的是能有一个真正好用的产品去承接。这也是为什么我觉得DeepSeek做C端产品这件事值得认真期待。
AI正在从“对话”走向“执行”
最后说说我的个人判断。
胡延平教授的催更信里有一句话,大概意思是DeepSeek沉寂的这一年,错过了几波浪潮。
但我觉得,错过不是失败,是选择。
DeepSeek在等一个窗口——不是等发V4的窗口,而是等做产品的窗口。
接下来AI的竞争,不只是“谁的大模型最强”,更是谁的产品真的能帮用户把事干漂亮了。
能对话的AI,大家都有了。
能高效自主执行的AI工具,才是国内AI行业的下一个赛点。
V4会来的,Agent也会来的。
真正值得看的,不是它什么时候发,而是它发完之后,能怎样帮我们把事儿干漂亮。
好了,我去接着用DeepSeek了。
本文由 @麦克先生 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供






- 目前还没评论,等你发挥!


