
 起点课堂会员权益
起点课堂会员权益2026 年中大模型权力榜:别再问谁最强,先看谁适合你
2026年的AI模型竞争已从对话能力转向任务完成度,各大厂商密集迭代版本却让选择变得更为复杂。本文深度拆解Claude、GPT、Gemini等12款主流模型的真实战力,从价格策略、工程能力到场景适配,提供一份拒绝「跑分陷阱」的实战选型指南。

2026 年中的模型竞争,已经从“谁更会聊天”转向“谁更能把事情做完”。
打开任意一个大模型平台,二十多个名字挤在一起:旗舰版、快速版、推理版、代码版,个个都说自己更强。麻烦在于,这些说法通常都没错,只是各自省略了条件。
模型之间的价格可以差到上百倍,适合的任务也完全不同。拿最贵的模型改一句通知,和让低价模型硬扛一套复杂工程,本质上是同一种浪费:没有先想清楚任务,再去选工具。
这篇文章不做“谁永远第一”的结论。那种榜单保质期太短。这里更关心五件事:当前可用版本、擅长什么、价格大致落在哪一档、适合谁,以及什么情况下不该选它。资料核对至2026 年 6 月 23 日,价格与型号仍可能随时调整。
半年时间,牌桌又换了一轮
2026 年上半年的更新速度,已经很难用传统软件版本的节奏来理解。1 月,文心 5.0 正式上线;2 月,Claude、豆包 Seed、通义千问和智谱先后更新;4 月,DeepSeek V4 Preview 与 GPT-5.5 登场;5 月又轮到 Gemini 3.5 和文心 5.1。进入 6 月,Kimi、智谱、MiniMax 继续往代码和智能体方向加码。
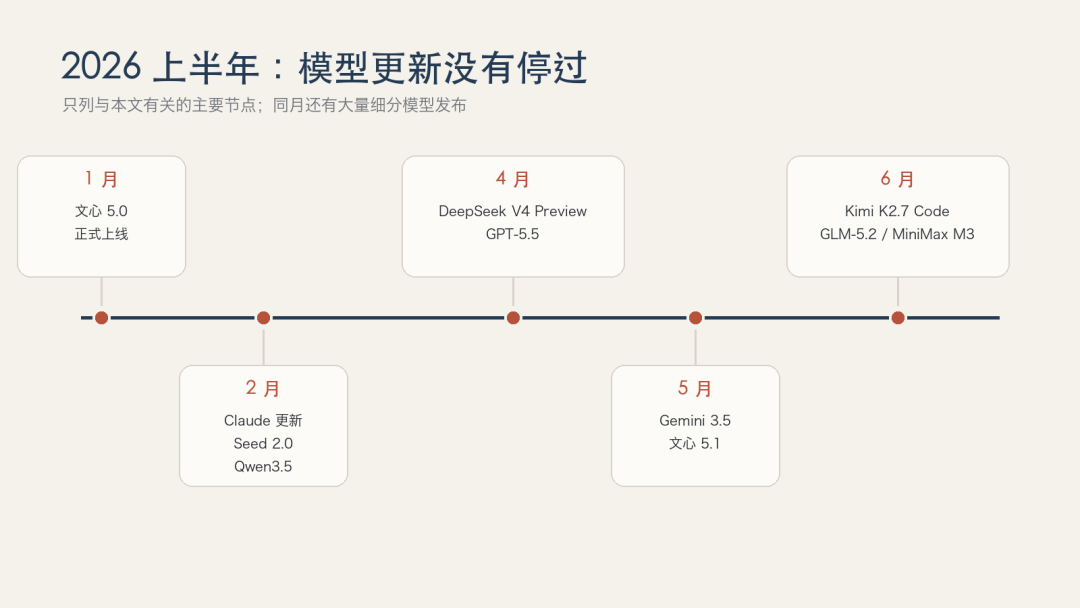
2026 年上半年主要模型更新节点。
版本号变得越来越不值钱,竞争的重点却越来越清楚:模型不只要回答问题,还要会拆任务、调工具、读文件、写代码、检查结果,必要时自己回头重做。过去大家比“聊得像不像人”,现在更关心“能不能独立把一件事做完”。
另一条线是成本。百万级上下文、工具调用和多模态能力,正在从少数旗舰的卖点变成常规配置。厂商一边冲榜,一边把缓存、批处理、轻量版和分层计费做得越来越细。原因很现实:企业真正落地时,不会只问效果好不好,还会问每完成一单到底花多少钱。
国际四家:各有一块硬地盘
四家国际厂商的差异,更多体现在任务风格,而不是简单的高低排名。
Claude(Anthropic)的优势仍然集中在代码、复杂推理和长链条任务。当前可正常采购的高端型号是 Opus 4.8,日常更实用的是 Sonnet 4.6。Fable 5 曾短暂开放,但截至本文核对时已标注为不可用,所以不该把它当成生产环境的默认选择。Claude 的特点不是“永远答得最漂亮”,而是做复杂工作时比较愿意暴露不确定性:需求不清楚会追问,方案走不通也更可能停下来重排。缺点同样明显,贵。
GPT(OpenAI)的长处是均衡。GPT-5.5 面向代码和专业工作,标准 API 价格为每百万 token 输入 5 美元、输出 30 美元;GPT-5.4 则便宜一半。它不一定在每个单项上都最突出,但工具生态、文档、第三方集成和现成经验最丰富。对于不想长期折腾模型切换的人,它仍然是省心的默认项。
Gemini(Google)最适合长文档、多模态和高吞吐任务。Gemini 3.5 Flash 的标准价格是输入 1.5 美元、输出 9 美元,速度和成本都比顶级旗舰轻得多。它的价值不只是“上下文长”,而是能把文本、图片、音频、视频放进同一套工作流里处理。合同审阅、研究资料整理、长报告分析,这些任务更能体现它的优势。
Grok(xAI)的位置最特别。Grok 4.3 的标准 API 价格为输入 1.25 美元、输出 2.5 美元,支持百万级上下文。它和 X 平台的实时信息结合得最紧,做舆情、追突发话题、看当天讨论有天然优势。反过来,如果任务是严谨写代码或长周期工程,Claude 和 GPT 的稳定性、生态积累通常更让人放心。
这四家并不是“全面碾压”其他模型。它们更像高价工具箱:碰到最难的任务,确实更有底气;大量日常工作却不需要一直开最高档。
国产模型:价格优势之外,开始拼工程能力
国产模型的竞争重点,已经从低价扩展到代码、长文档、语音和智能体。
国产模型已经从早期的“百模混战”,收敛到几条相对清晰的路线:开源与低价、代码与智能体、中文内容、多模态产品,以及面向企业的工程交付。
DeepSeek。4 月发布的 V4 Preview 分为 Pro 和 Flash 两档,均支持 100 万 token 上下文并开放权重。官方 API 中,Flash 的标准缓存未命中输入价为 0.14 美元、输出 0.28 美元;Pro 为 0.435 美元和 0.87 美元。它最有冲击力的地方,不只是便宜,而是把长上下文、推理、工具调用和开源部署放进了同一套产品里。预算敏感、需要本地部署,或者要批量跑代码和推理任务,它仍是很难绕开的选择。
通义千问(阿里)。目前商业主力是 Qwen3.5 系列,而不是传闻中的“Qwen3.7”。它的优势是产品线完整:Max、Plus、Flash 分工清楚,文本、图像、视频和开源模型都能接上。不同地区和输入长度采用分档价格,Flash 在低输入档尤其便宜。千问未必每次都给人最惊艳的单点表现,但工具、教程、部署方案和社区资料足够多,真正做项目时少踩坑,这一点很值钱。
Kimi(月之暗面)。K2.6 继续主打长程任务和多模态,6 月又推出 K2.7 Code,明确向代码与智能体工具靠拢。它适合资料多、项目周期长、需要反复读写文件的工作,例如分析一批图文 PDF,或者接手一个持续迭代的代码库。需要提醒的是,代码模型的宣传分数只能当起点,最好拿自己的仓库跑一轮,再决定是否迁移。
智谱 GLM。主力已经更新到 GLM-5.2,官方全球 API 标价为输入 1.4 美元、输出 4.4 美元。它在代码、工具调用和多步任务上的进步很快,也较早把“编程套餐”做成了明确的商业产品。想要国产模型承担更重的工程任务,GLM 值得放进实测名单。
豆包(字节)。Seed 2.0 把重点放在多模态理解、复杂任务执行和 Agent 场景,Pro、Lite、Mini 三档面向不同成本。豆包真正的护城河仍然在产品体验:语音交互、生活化问答、短视频与即梦生态,对普通用户更友好。它未必是开发者眼里的“最强代码模型”,却可能是大众最容易长期留下来的那个。
MiniMax。主力已从原文中的 M2.5 更新到 M3。官方把它定位为面向代码、工具使用、智能体推理和长上下文的最新 M 系列模型,目前标准档活动价约为输入 0.3 美元、输出 1.2 美元。它的思路很直接:用低价和高吞吐去承接需要大量调用的 Agent 工作流。
文心、混元与其他厂商。文心 5.1 已于 5 月正式发布,中文写作、搜索和智能体是它继续强调的方向;腾讯混元则更适合放在腾讯云、微信生态和多模态产品里看。商汤、阶跃、零一、百川、讯飞仍各有垂直优势,但如果只挑一个通用主力,它们目前通常不是多数人的第一顺位。
价格差距,比跑分差距更大
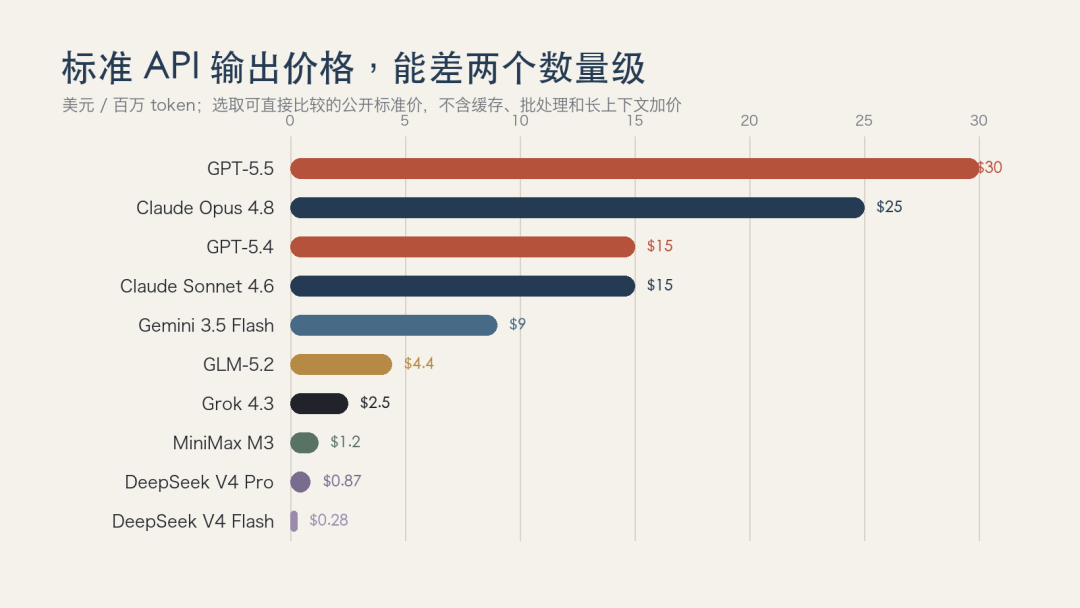
部分主力模型标准 API 输出价格对比。不同地区、缓存、批处理和长上下文会改变实际费用。
把标准 API 价格放在一起,最直观的感受不是“谁更强”,而是“同一百万 token,能贵出两个数量级”。不过,便宜并不自动等于划算。低价模型如果需要反复重试、人工返工,最终成本未必低;高价模型如果一次把复杂任务做完,也可能更省。
主流模型对比速览
Claude
当前主力:Opus 4.8 / Sonnet 4.6
参考价:$5 / $25;$3 / $15
更适合:复杂代码、长链条任务
GPT
当前主力:GPT-5.5 / GPT-5.4
参考价:$5 / $30;$2.5 / $15
更适合:通用生产、工具生态
Gemini
当前主力:Gemini 3.5 Flash
参考价:$1.5 / $9
更适合:长文档、多模态、高吞吐
Grok
当前主力:Grok 4.3
参考价:$1.25 / $2.5
更适合:实时信息、舆情
DeepSeek
当前主力:V4 Pro / Flash
参考价:$0.435 / $0.87;$0.14 / $0.28
更适合:开源部署、低成本推理
通义千问
当前主力:Qwen3.5 系列
参考价:分地区、分长度计价
更适合:均衡工程、开源生态
Kimi
当前主力:K2.6 / K2.7 Code
参考价:平台分档计价
更适合:长文档、代码智能体
智谱 GLM
当前主力:GLM-5.2
参考价:$1.4 / $4.4
更适合:国产工程与代码任务
豆包
当前主力:Seed 2.0 系列
参考价:国内分档计价
更适合:语音、多模态、大众产品
MiniMax
当前主力:M3
参考价:$0.3 / $1.2(活动价)
更适合:高并发 Agent
文心
当前主力:ERNIE 5.1
参考价:约 ¥4 / ¥18(32K 内)
更适合:中文内容、搜索、企业应用
混元
当前主力:HY 2.0 系列
参考价:资源包 / 点数计费
更适合:腾讯生态、多模态
真正落地时还要看缓存命中、批处理折扣、搜索和工具调用费、上下文长度,以及模型为了完成任务实际会吐出多少 token。
按需求对位,比排总榜有用
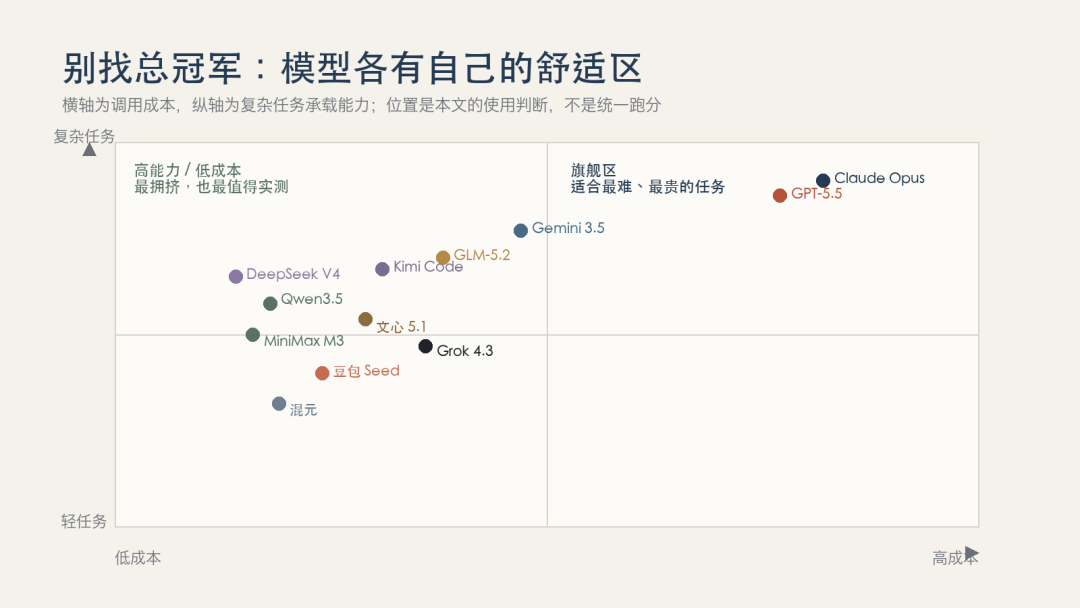
模型位置示意:横轴是调用成本,纵轴是复杂任务承载能力。位置为本文的使用判断,不是统一基准测试排名。
写代码。预算充足、任务复杂,先试 Claude Opus 或 GPT-5.5;预算紧,DeepSeek V4、Kimi K2.7 Code、GLM-5.2 都值得用自己的仓库实测。不要只跑一道算法题,最好测试真实的改错、跨文件重构、运行测试和回滚。
长文档与研究资料。Gemini 仍是优先项,Kimi、DeepSeek 和 Qwen3.5 也适合中文资料。关键不只是能不能塞进去,还要看引用能否对上原文、长文中后段是否丢信息。
内容、文案与日常办公。豆包、千问、文心的免费产品已经够用。对英文质量、结构化交付或复杂工具链要求更高,再考虑 GPT 或 Claude 订阅。
智能体与自动化。国际模型先看 Claude、GPT;国产可测 GLM、千问、MiniMax 和 DeepSeek。这里最重要的指标不是单轮回答,而是工具调用成功率、长任务中断率和成本上限。
语音、视频与大众创作。豆包及字节的 Seed / 即梦体系更完整;腾讯混元、MiniMax 也应按具体的语音或视频模型单独比较。不要用语言模型的排名替代视频模型的选择。
实时信息。Grok 的 X 信息流有独特价值,但涉及事实核查时,仍应回到原始来源。任何带搜索功能的模型,都可能把“搜到了”误当成“证实了”。
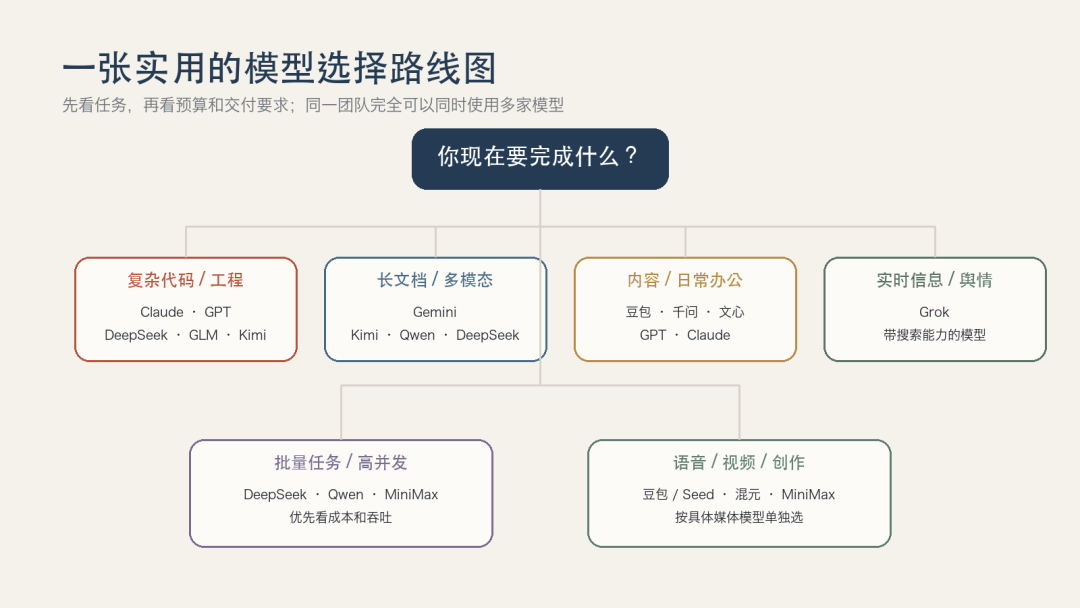
一张实用的模型选择路线图:先看任务,再看预算与交付要求。
API 和订阅,别混在一起算
很多人第一次付费,最容易在这里绕晕。聊天产品的月费订阅,买的是网页或 App 里的使用额度;API 则是给程序、自动化和批量任务调用,按 token 或其他资源计费。两套账通常互不相通。
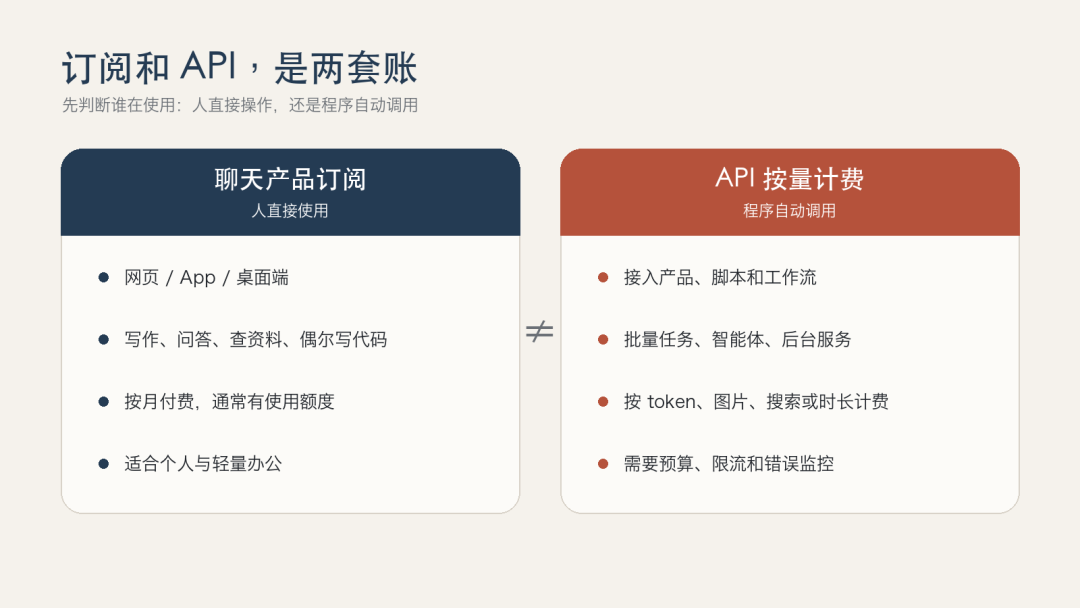
订阅适合人直接使用聊天产品;API 适合程序调用、批处理和自动化。
一个人写文章、查资料、偶尔写代码,先买月费订阅或用免费档就够了。要做产品、跑工作流、让几十个任务自动执行,再开 API。反过来,用 API 当聊天软件,往往麻烦;拿个人订阅去支撑生产系统,也不现实。
最后:别把自己绑在一个模型上
真正好用的方案通常不是“选出唯一冠军”,而是分工:复杂任务交给贵模型,批量杂活交给便宜模型,长文档交给擅长上下文的模型,实时信息交给能联网检索的模型。模型路由做得好,省下的钱往往比换一次供应商更多。
也不必看到新版本就立刻迁移。先拿三到五个真实任务做一个小测试集,记录一次完成率、返工时间、速度和总成本。只看榜单分数,很容易买到一台性能很高、却不适合自己路况的车。
三个月后,本文里的若干版本号大概率又会过期。但有一条不会:先把任务说清楚,再去选模型。知道自己要什么的人,没那么容易被发布会和排行榜牵着走。
本文由 @岚天 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


