
 起点课堂会员权益
起点课堂会员权益大模型微调:从通用到专属领域专家
你是否在用大模型,却总觉得“不够贴合业务”?微调或许是你的突破口。本文将带你从0到1掌握微调实操方法,覆盖数据准备、参数设置与效果验证,让你的AI模型真正“懂业务、会协作”。

在人工智能飞速发展的当下,大语言模型(LLM)已成为众多领域的关键技术支撑。无论是在智能客服、内容创作,还是数据分析决策等场景中,LLM 都展现出了强大的能力。但在实际应用中,经常需要经过微调优化大模型,才能更好地满足特定的需求。
什么是微调
微调(fine-tuning)是在大模型在预训练完成后进一步训练,以优化其在特定任务上的表现。简单来说,在预训练阶段,大模型会通过大量的语料学习基本知识和推理能力,从而形成一个基础模型。为了使这个基础模型能够更好地适应不同的任务,就需要在其基础上进行微调。
如何优化大模型
如何微调大模型?要解决这个问题,首先要知道怎么优化大模型, 大概分为三大步 :
第一 找出问题
大模型常见问题有:
- 答案不相关/相关度低,用户提问的问题答案和大模型生成答案差十万八千里。
- 答案相关但不够专业,当提问某些专业领域的问题时,大模型可能会生成一些看似合理但实际上是错误的信息。比如当用户提问:“我最近总是头痛和头晕,可能是什么原因?”大模型回答:“头痛和头晕的原因有很多,常见的有睡眠不足、精神压力大、颈椎问题、高血压或者贫血。建议你多休息,放松心情,如果持续不缓解,请及时就医。”大模型看似回答了,但过于宽泛、笼统模糊。
- 答案相关但缺少针对性。模型的回答虽然与主题相关,但没有精准地匹配用户的具体场景、隐含需求或知识水平,像一个放之四海而皆准的“标准答案”,而不是为你量身定制的方案。如当用户输入“请为我推荐一个周末旅行计划。”,大模型输出“第一天:上午游览故宫,下午参观天坛,晚上去王府井逛街吃饭。第二天:上午攀登八达岭长城,下午返回市区参观鸟巢和水立方。”这是一个充实而经典的行程,但它可能完全不适合用户,没有考虑用户目的地、预算、兴趣爱好等。
- 答案相关但逻辑错误。答案看起来头头是道,且围绕主题展开,但内在的推理链条却不相符。如下雨天要带伞,大模型可能理解为因果关系:“因为下雨所以带伞”,实际是关联关系。
- 答案语气表达/输出格式不合适。大模型在回答的语气和格式上有时会不符合特定场景和角色。如用户需要论文格式,大模型输出的格式是其它的。
- 答案输出不够稳定。同一个问题,第一次和第二次问,大模型可能输出不同的答案,降低用户的信任度。
第二 搞清原因
模型常见问题原因分为两大类:输入质量差和模型能力低
针对输入质量差,应该从以下几个方面找原因:
1.回答的必需信息,在输入中是否明确。2. 解答问题,需要哪些步骤?3. 用户更关注哪些生成效果,在输入中是不是有体现?总之,大模型也是需要充分的context。
模型能力低主要是因为:
1.答案稳定性不够。 通常来说,跟模型本身的关系比较大,例如模型输出的参数、模型拟合情况,甚至训练数据分布,都有一定关系,这个需要逐步分析确定。
2. 逻辑推理错误 。逻辑推理问题、 加强逻辑一致性、 因果关系判断优化、长文本处理与多任务能力、 抽象概念理解、抗干扰能力差等;
3. 答案语气表达 / 输出格式不合适。第一是模型对指令理解有问题,第二是模型泛化能力不足。
第三 选择手段
针对输入质量差:
1、缺少专业知识:RAG+Prompt工程
2、缺少针对性:反问+Prompt工程
3、相关性差:query转换+Prompt工程
针对模型能力低:
1、稳定性差
解决方法:修改模型参数,进行模型优化。
2、逻辑推理差
解决方向:
- 逻辑推理:可加入专门的逻辑推理引导等。
- 逻辑一致性:可加入外部记忆组件、加强对连贯等。
- 因果关系判断:创建/使用专有因果关系数据集训练,辅助模型学习因果推理。
- 长文本与多任务:用层次化模型结构处理文本层级,或设计多任务学习框架。
- 抽象概念理解:尝试知识图谱嵌入等创新方法。
- 抗干扰能力:因注意力机制“天生毛病”,需优化以降低信息噪音。
3、答案语气表达 / 输出格式不合适:适合微调, 微调(尤其是 LoRA)性价比高,适合语气、格式类局部调整;若需深入学习专业知识,全参数微调或 RAG 更合适(RAG 成本更低、效果直接可控)。
微调的典型应用场景
1. 文本提取:在法律合同、财物合同中,有一项重要业务是合同要素化,需要把很多文件、合同的内容做提取,且提取对格式要求严格,方便下游录入或作业,这时通过全量微调。
•2. 文本的生成:例如评语、游记、小红书笔记等,对风格化要求很强,更多需要微调才能达到。
• 3. 报告生成:例如法律报告、产品说明书等,对输出格式、文体有强烈要求,这时也需要微调。
• 4. 角色扮演:如让大模型做教育辅导、情绪安抚、虚拟人助手、游戏人物等,对语气有很高要求,不微调往往难以达到。
模型选择与数据需求
模型选择:微调一般都会选择开源模型,除非有必须使用闭源模型的特殊原因,还需要考虑模型提供公司的运营可持续性、模型尺寸上应选择最小可行尺寸,而确定这个尺寸通常需要进行多次实验
训练数据:数据质量是影响微调效果最关键的因素,应尽量使用真实场景的数据、 需要对数据质量设置标准统一的评分体系、梳理足够的子场景标签、确保不同子场景的比例分布与实际情况一致、对实际影响更大的场景,可适当提高其数据比例。
评估微调后的模型能力
大模型微调效果可从技术指标、业务目标、实际场景等多个角度进行衡量。
1. 明确评估目标
首先需要明确微调的目标是什么:是提升模型在特定任务的性能?优化推理速度?还是解决领域适应性问题?不同的目标对应不同的评估方法。
2. 技术指标评估
基础指标:
- 训练损失:观察模型在训练集上的损失是否收敛,若持续下降且稳定,说明模型学习了训练数据。
- 验证损失:在独立验证集上检查损失,若验证损失与训练损失差距过大(如验证损失上升),可能出现过拟合。
- 分类任务:准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1-Score、AUC-ROC曲线等。
- 生成任务:BLEU、ROUGE、METEOR(文本生成);生成结果的流畅性、逻辑性等(人工评估)。
- 回归任务:MSE、MAE、R²。
- 困惑度(Perplexity):评估模型对测试数据的预测能力,值越低说明模型越适应任务。
3.对比实验
- 与未微调的基线模型(如原版LLM)在相同测试集上对比性能提升。
- 与其他微调方法(如LoRA、全参数微调)或不同超参数组合的结果对比。
4.过拟合/欠拟合分析
- 检查训练集和验证集的指标差异(如训练Loss下降但验证Loss上升可能过拟合)。
- 通过交叉验证(Cross-Validation)或学习曲线(LearningCurve)判断模型泛化性。
5. 业务场景适配性领域相关指标:
- 领域内测试:构建领域相关的测试集,验证模型是否掌握专业术语、逻辑和行业规范。例如:医疗领域模型需准确回答疾病诊断建议,金融领域模型需符合合规性。
- 跨领域泛化:用未见过的数据(或跨领域数据)测试模型,观察性能是否显著下降,判断是否过拟合。
6.业务KPI
如果微调目标是提升用户转化率,需通过A/B测试对比微调前后的业务指标(如点击率、留存率)。
人工评估:
- 邀请领域专家或用户对模型输出进行主观评分(如相关性、专业性、流畅性)。
- 对生成内容进行人工打分,评估维度包括:
- 相关性:内容是否符合任务需求(如客服问答是否切题)。
- 流畅性:语言是否自然、符合语法。
- 事实准确性:生成内容是否包含错误或虚构信息。
- 多样性:避免重复性回答(例如在创意生成任务中)。
- 下游任务表现**:将微调后的模型嵌入实际业务流,测试端到端效果:例如,客服场景中统计问题解决率、用户满意度。
7. 效率与稳定性
- 推理速度:微调后模型的响应时间是否满足业务需求(如实时性要求)。
- 资源占用:显存占用、模型体积是否适配部署环境(如移动端、边缘设备)。
- 输出稳定性:多次输入相同/相似问题时,输出是否一致(避免“模型幻觉”)。
8. 长期监控与迭代
- 在线指标监控:上线后持续跟踪用户反馈、错误率、异常输入处理能力。
- 数据漂移检测:监控输入数据分布变化,判断模型是否需要重新微调。
实操
结合工作项目经验和相关资料,打造一个医学检验检测专业具有医学检验背景、丰富的实践经验、精通标准与规范的咨询专家。
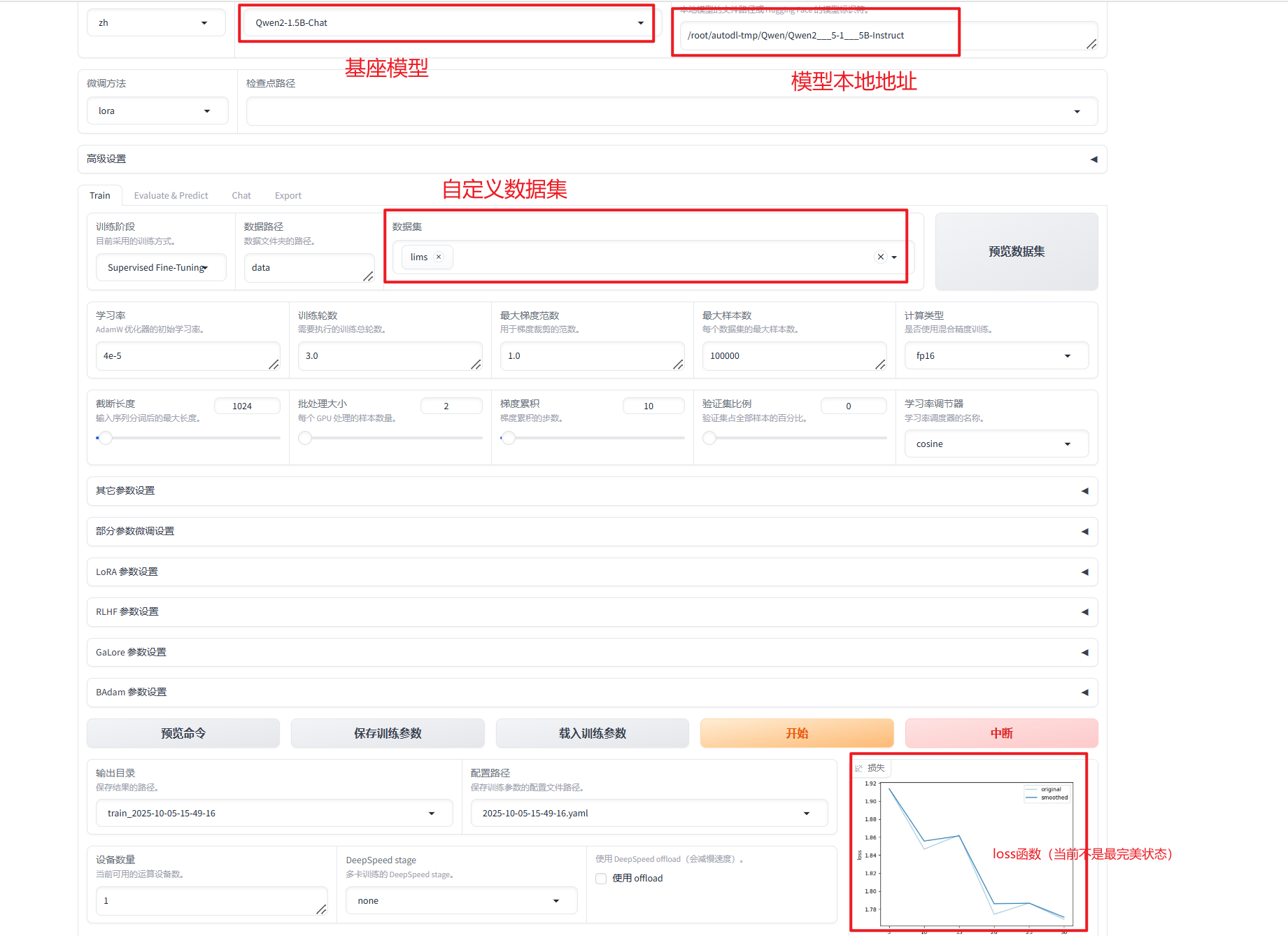
框架: LLama-Factory
算法: LoRA (常用的部分参数微调算法)
基座模型:Qwen2-1.5B-Chat
硬件资源、搭建环境:AutoDL(算力云)
步骤1:AutoDL购买云服务器,连接到本地,详情可参考:https://blog.csdn.net/qq_53690996/article/details/143179521
步骤2: 准备数据集,可从行业、市场、内部等相关资料整理,也可以从公共的资源库如hugging face、modelscope等寻找合适数据集,或是使用大模型生成合成数据集,如下图:

步骤3: 配置数据集、配置基座大模型、微调大模型、测试微调结果,详情可参考:https://blog.csdn.net/qq_53690996/article/details/143179521
llamafactory webui设置示例如图:
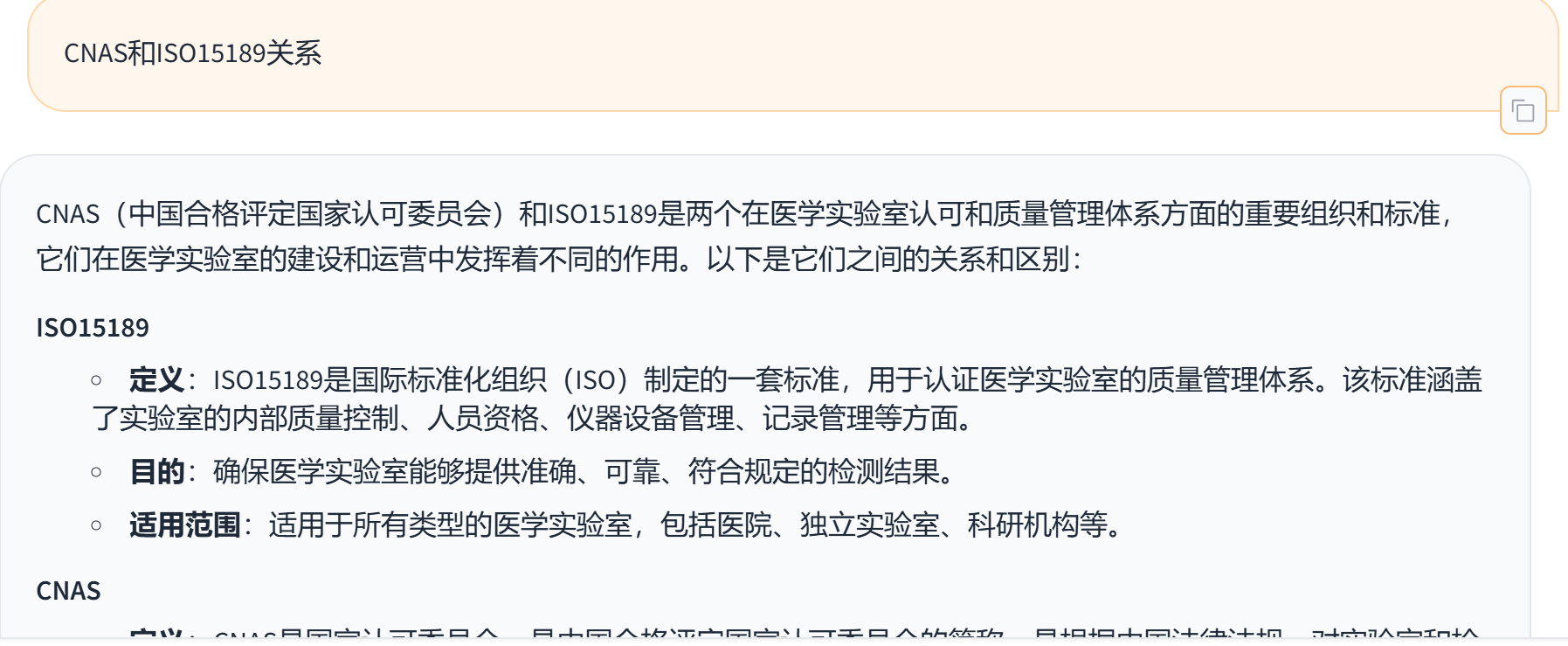
微调结果测试如下(因数据集数量有限,微调效果并非最好) :
步骤4: 导出大模型,部署后即可使用微调好的模型
本文由 @叶子 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务









这是一个很全面的文章,如果案例更详细些可能会给到初学者更多帮助
好的!谢谢您的建议