
 起点课堂会员权益
起点课堂会员权益动态上下文管理:工业AI应用的上下文工程革命
工业AI的真正突破,不在模型精度,而在任务协作的上下文设计。本文系统解析“动态上下文管理”在工业场景中的应用逻辑,揭示上下文工程如何重构人机协作边界,推动AI从工具走向流程伙伴。

01、工业知识库的上下文危机
我想从最近跟客户沟通发现的问题开始,带大家聊聊上下文工程的作用。
我们的客户是业内做的比较好的一些制造工厂,他们想做AI设备维修助手或者是工艺SOP助手,帮助新来的员工快速排查故障。
其实最开始他们的第一选择是使用像Dify/RagFlow之类的产品来直接落地。
毕竟对他们来说部署dify还是简单的,把工厂里几万页的设备手册、历史维修记录、SOP文档全都喂到知识库里,让AI在回答问题的时候自己去调用就行了。
但是大部分工厂在落地这类产品后一般都用不起来,反而变成了高科技鸡肋,这也是他们来向我们寻求解决方案的原因之一:
- 答案驴唇不对马嘴:用户问的是胎面问题,但是大模型分不清胎面、胎侧的区别,回复的往往是错误信息。(胎面=轮胎正面,胎侧=轮胎侧面,不同的位置会出现问题,而问题的原因通常不一样)
- 维护成本高得吓人:知识库内容太多太大,更新和维护非常消耗人力物力,依赖人的主动管理,每次产生了新的案例都要手动再添加进来。
- 不懂用户的偏好:单轮问答可能做的很好,但是知识飞轮没有转起来,聊过的信息里有很多有用的信息,没有做二次沉淀,下一次当然也记不住用户的偏好数据。
在了解之后我发现,一个RAG知识库+提示词很难解决根本原因,哪怕调优了以后其中一个问题好了,另一个又会出现,就像跷跷板一样,而且提示词内容越来越多越来越难维护。
这时候我们的解决方案应该升级为:
面对眼前这个具体的故障,我应该把哪些最关键的信息(上下文)递给AI专家,让它能立刻做出精准判断?
02、揭秘:上下文工程到底是什么?
刚刚我们说的就是上下文工程,没有那么高大上,工程一词只是强调这是一项需要系统化、优化性工作的任务。如果说提示工程是教AI怎么说,那上下文工程就是教AI找什么、看什么、听什么、用什么。
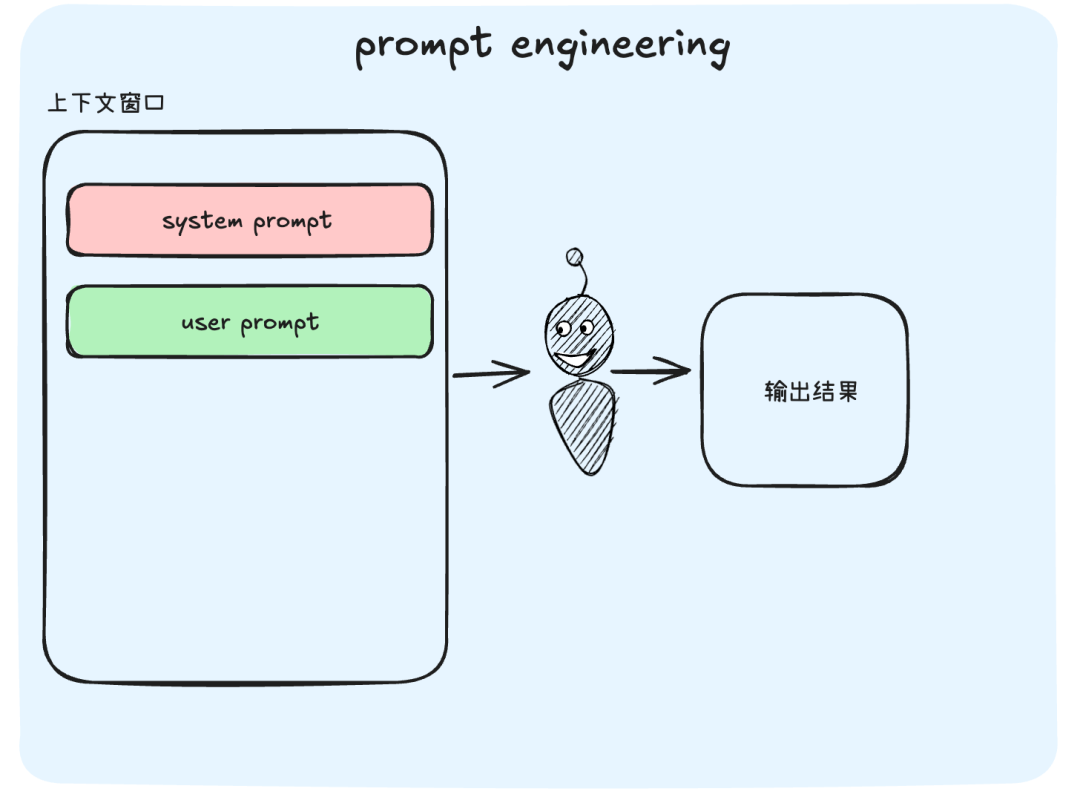
提示词工程
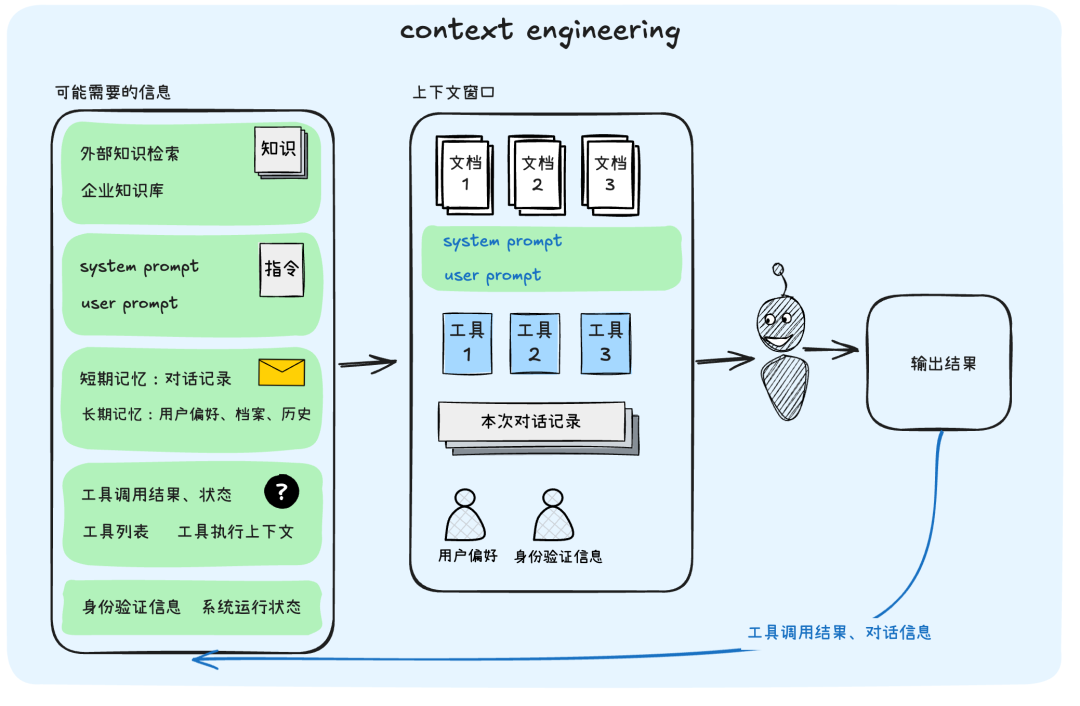
上下文工程
它是一套为AI智能体设计的信息供给工程,决定了在解决特定问题时,哪些信息应该被优先加载到AI有限的上下文窗口上。
上下文中包含了以下内容:
- 系统提示(SystemPrompt),用户提示也包含在里面
- 工具/函数(Tools/Functions)
- 检索到的外部数据(RetrievedData)
- 实时动态数据(Real-timeDynamicData)
- 消息历史(MessageHistory)
- 以及所有可能在提示词之外进入到上下文中的其他信息
不同的模型上下文窗口大小是不一样的,通常是128k,也就是200w字。
可能你看到这个数字会觉得,这不是挺多的吗,但是一些复杂的任务,很容易就可以消耗完,尤其是在调用传感器数据时,处理非常慢。
而且当你给AI看的无关资料太多时,它反而会忘记你最初问的那个具体故障是什么,也就是上下文腐烂(这个叫法很有意思)。AI的注意力就像我们每个人的时间一样,非常宝贵。

anthropic最新的上下文工程中提到上下文窗口中的信息越多,大模型反而效果会开始变差
03、灵活使用上下文:让AI助手学会自己动手
到底如何解决这种问题呢?
要让AI成为随身专家,关键是让它学会自己动手获取信息,而不是我们预先塞给它所有东西。这依赖几个核心机制:工具、即时策略。
工具在工业场景里,就是赋予AI助手的感官和手臂,让它能感知物理世界,获取实时信息。
企业AI落地最常见的问题之一可能就是工具集的臃肿,一个不同工具之间能力有所重叠,或者我们自己也无法判断遇到问题时调用哪一个工具更好,大模型当然也没办法知道。所以工具的边界非常重要,也是我们作为产品经理需要重点关注的内容。
设计好的工具,就像设计一个好的函数,意图清晰,返回高效。比如,我们可以为AI维修助手设计两个关键工具:
- 感知工具:一线制造业都会有非常多的传感器、数据采集器,当AI需要时,它可以调用这个工具,实时获取指定设备的温度、压力、振动频率等数据。获取数据不难,但是关键在于,每秒记录的海量数据中,如何选择出真正有用的数据?比如只返回异常的指标和数值,而不是返回过去24小时的所有正常数据流,那就需要更优质的算法模型做好数据对齐进行配合。
- 知识工具:也就是知识库,AI可以调用它,根据关键词和设备型号,精准地从文档库中只检索出最相关的那一页操作规程,而不需要把整本厚厚的手册都加载进来,但是前提是知识的分类归纳和元数据构建一定要完善。
有了工具,我们就可以改变AI的工作模式了,通过即时上下文策略来增强检索系统,让AI知道它更应该知道的信息。
怎么做呢?我们只让AI助手维护一个轻量级的设备资产索引。这就像一张张索引卡片,上面只写着:设备ID -> 对应的数字手册路径 -> 历史维修记录数据库的查询地址。
现在,当一个维修工单描述A产线B设备出现异响时,AI助手的工作流是这样的:
- 第一步(感知现状):它会立刻调用工具get_device_realtime_data(‘B’),发现振动频率这个指标异常。
- 第二步(查阅手册):它根据设备索引,找到B设备的手册路径,并调用工具find_SOP(‘振动异常’,’B型号’),只把最相关的那一页SOP加载到自己的工作台上。
- 第三步(借鉴历史):它再次根据索引,找到历史维修记录的数据库地址,并调用查询工具,只检索出过去处理B型号设备振动异常的成功案例。
这个过程就像一个经验丰富的老工程师,他不会背下所有手册,但他脑子里有一张清晰的地图,知道遇到什么问题,该去档案室的哪个柜子、拿出哪本手册来看。
在Anthropic 的Claude Code中他们也在使用这种方法对大型数据库执行复杂的数据分析。模型可以编写有针对性的查询、存储结果,并利用 Bash 命令(如 head 和 tail)来分析大量数据,而不是把完整的数据对象加载到上下文中。
让代理自主探索逐步发现相关上下文反而可以带来意想不到的优点,每次交互都会产生为下一个决策提供信息的上下文:文件大小表明复杂性、命名约定暗示了目的、时间戳可以分析相关性。
不过如果没有适当的指导,Agent可能会滥用工具、追逐死胡同或未能识别关键信息而浪费上下文。
04、让上下文活起来:从人工投喂到系统自学
我们已经讨论了如何为AI设计一个高效的上下文系统。但还有一个更深层次的问题:这个工作台上的工具和档案,能不能随着时间推移,自己变得越来越好用?
如果每一次AI与维修师傅的对话,都只是一次性的任务完成,那系统的价值增长将非常缓慢。就像一个学徒,虽然每天都在干活,但从不复盘总结,那他永远也成不了专家。
真正强大的工业AI系统,必须具备复盘和自学的能力。
一次性对话的价值困境
让我们回到AI维修助手的例子。默认情况下,一次对话结束后,这段宝贵的消息历史(Message History)可能就消失了,或者只是作为日志被存档。这意味着:
- 重复的错误:如果AI在某次对话中给出了一个不太理想的建议,它在下一次遇到类似问题时,很可能会再犯同样的错误。
- 知识的流失:如果一位经验丰富的老师傅,在与AI对话后,补充了一句关键的、手册上没有的诀窍,这句宝贵的知识就随着对话的结束而流失了。
- 效率的瓶颈:AI永远依赖我们预设的工具和知识库,无法发现新的、更高效的解决路径。
要打破这个困境,我们必须建立一个对话历史自动回收与学习机制。
简单来说,就是系统性地、自动化地分析每一次成功的(甚至失败的)人机对话,从中提取有价值的模式和知识,反过来优化未来的上下文供给策略。
自动优化的实践路径
1.知识库内容的动态补充 (RAG 2.0)
不再仅仅依赖我们人工维护的知识库,而是让AI从对话中发现并补充隐性知识。
在一次对话中,老师傅对AI的建议进行了修正:没错,但对于夏天潮湿天气下的B型号设备,最好先用除湿器吹5分钟再操作,否则传感器容易短路。
在实际的工作中,本身老师傅的经验就非常宝贵,而且也不乐意分享给别人,有替代风险。所以我们一定要抓住所有的机会,从对话中挖掘真实经验并沉淀进来
那我们可以构建一个单独的智能体,自动识别出这种人类修正或补充信息的模式,并将这条诀窍提取出来,放入由领域专家审核的知识库中。一旦专家审核通过,这条新知识就会被正式索引。未来,当AI检索到与B型号设备、潮湿天气相关的SOP时,会自动将这条专家诀窍一并加载到上下文中,让它的建议更贴近真实工况。
2.Prompt模板的自我迭代
我们可以分析哪些对话模式最受用户欢迎、解决问题最快,并用这些模式来优化我们的系统提示或任务提示。
在实际的落地过程中,我们发现当AI在给出解决方案时,如果先用一句话总结可能的原因(看起来像是压力传感器的问题),然后再给出执行方法和具体步骤,用户的采纳率会显著提高。
所以我们可以将这个模式固化到AI的系统提示中,加入一条新的行为准则:在提供解决方案前,请先用一句话概括你对根本原因的判断。
这样,所有的AI回复都会自动采用这种更受欢迎的沟通方式。
05、提升专家自主性:让AI助手学会独立思考
有了自己动手的能力,我们还要教AI如何独立思考,在复杂问题面前,知道该先做什么、后做什么。
在工业领域,信息的出身至关重要。一份文件名本身,就是强大的元数据。
比如,一份名叫 KB-3025_v3.1_official_release_2024-Q3.pdf 的手册,就比一份叫 manual.pdf 的手册,给AI提供了多得多的信号:这是关于KB-3025型号设备的,版本是3.1,是官方发布的,并且是2024年第三季度的最新版。AI会本能地更加信任前者。
作为产品经理,我们可以设计一套严格的工业知识库命名和标签规范。这本身就是在预处理上下文的信号强度,是一项低成本、高回报的设计工作。
当面对一个综合性故障,比如整条产线效率下降时,我们不能让AI一下子就去查某台设备的具体参数。我们要让它像个侦探一样,层层深入。
AI的探索路径应该是这样的:
- 初步探索:先调用工具,查看产线整体的OEE(设备综合效率)报表,发现是计划外停机时间过长。
- 深入一层:接着,再去查询具体的停机日志,定位到是C号机械臂故障最频繁。
- 最终定位:最后,AI才会去调取C号机械臂的详细传感器数据和维修手册,进行根本原因分析。
这个过程,我们称之为渐进式探索。它让AI在工作记忆中,永远只保留当下最必需的内容,像医生问诊一样,从宏观到微观,逐步聚焦,避免被海量无关信息淹没。
当然,在紧急抢修的场景下,让AI一步步去探索可能太慢了。所以,最有效的智能体,可以采用混合策略。
- 预加载高频信息:对于最常见、最致命的故障类型,比如产线紧急停机处理预案,可以预先将对应的SOP和解决方案摘要,固化到SystemPrompt中。
- 探索疑难杂症:对于不常见、复杂的故障,则授权AI使用工具进行自主的、渐进式的探索,前提是一定要准备好全部的示例库,让AI能够自行检索和参考。
完成以上这些工作,整个系统就已经非常牢固和坚实了,当然我们实际上的工作也还没有完全到位,还在不断的进行中。
06、结论:打造AI的认知架构
其实不难发现,上下文工程,本质上是在为AI智能体设计一个高效的认知架构,虽然我们今天讨论的是工业AI的上下文工程,但其实大部分场景下都是可以通用的,而且工业领域可能还会更加复杂。
我们的目标不再是训练一个无所不知的万能模型,而是构建一个懂得如何学习、如何查找、如何聚焦的专家系统。
在真正的工作中需要设计的,不仅仅是AI本身,更是AI赖以生存和思考的整个信息环境。
未来最智能的工厂,不是拥有最强大AI大脑的工厂,而是拥有最高效数据循环系统的工厂。这场变革的号角已经吹响,而我们产品经理,就是这个新系统的总设计师。
本文由 @思敏(AI产品) 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


