
 起点课堂会员权益
起点课堂会员权益如何做Agent评测
在大语言模型主导的AI时代,如何确保Agent应用层的稳定输出成为关键命题。本文系统拆解Agent评测体系的构建逻辑,从过程指标与结果指标的双重视角,揭示如何通过标准化测试收敛概率模型的不确定性。更包含评测集构建、自动化评测实施等实战方法论,为AI产品落地提供可复用的质量保障方案。

LLM(大语言模型)本质上是概率,Agent作为应用层,必须通过标准化测试来收敛这种不确定性,确保产出符合业务SOP。
Agent 评测是一个迭代的过程,旨在为 Agent 的持续优化提供明确方向。好的指标能准确的判断当前Agent是否符合业务预期,并且能快速定位到需要优化的点去进行优化。
接下来将详细说明评测如何进展。
一、确定指标
指标分为2种,结果指标和过程指标。
1. 过程指标
过程指标是即Agent运行过程中,是否按照预期路径来执行,是否调用某工具,是否搜索了知识库,过程指标就是为了防止Agent使用“邪门歪道”来完成任务而导致结果的不可信,不然很可能结果全对,但是过程全错。
举个现实的例子:某销售经理为了完成月100W的销售额,花了公司200W的营销预算,最终达成了目标。
- 意图识别准确:识别能精准的识别客户的想法并进行分流。例如客户说:我要换货,则分流到售后-退换货,而不会分流到售前;
- 工具选用正确:是否调用工具或者调用工具是否准确。例如:北京今天的天气,需要调用日历+天气两个工具;
- 是否调用知识库:结论是否查询了知识库说得出的答案:例如:李白是谁。不调用知识库,可能回答的是唐朝诗人或者某游戏的打野人物,调用了知识库后,可能结果是:李白是某部门的主管,现在分管…
- 思维链路是否准确:在获取一个问题的时候,拆解任务的逻辑是否连贯。例如帮我找一件200元以内的红色裙子,指令是否能拆解为:搜索商品-筛选红色-价格区间0-200。
还有很多过程指标,可以按照业务的需求来定义。
2. 结果指标
结果指标顾名思义,得出的结果是否符合预期。以下是一些通用型的指标:
- 准确性:内容是否准确;
- 伦理标准的遵循:是否有脏话或者不道德的语言;
- Token消耗成本: 完成一个标准任务所需的Token花费;
- 平均响应速度: Agent思考和执行的时间。过长的等待会直接摧毁用户体验。
当然,除了针对Agent回复内容做出分析以外,也可以针对用户提问做出分析,以此来评判是否需要在用户问题上做出优化和引导。
例如用户的问题是否清晰、意图是否明确、上下文是否完整等。
三、指标评分维度
指标确认后,需要确认评分的维度,不同的指标对于结果的评估方式是不同的。
常用的评分维度包括:
1. 二元判断
完全肯定或否定,即非是即否,例如是否调用工具、是否遵守安全规范等。
2. 分数评估
有的不能完全用是否判断的,可以用打分评估,例如:准确性、相关性、流畅度
按照1-5分进行打分,其中5分表示非常流畅自然,1分表示生硬不通顺
3. 区间指标
还可以做一些区间指标,例如响应时长:
- 优秀:≤3秒
- 良好:3秒<时长≤5秒
- 及格:5秒<时长≤10秒
- 不合格:>10秒
指标和评分维度的设定并不是一成不变的,甚至同一个数据集,需要分析的方向不一样,设定的指标和评分维度也会不一样。
举个例子:一份客服智能体回复的评测集,要评测回复质量,直接沿用上述的指标即可,但是要评测某一个具体的方向,例如要找到Agent回答错误的原因:可能就需要开放性的问题+几个筛选项了。
query意图是否完整-单选
-语义完整
-语义不完整
query语义不明类型-单选
-上下文缺失
-单词有歧义
-query无实际意义
-query带错别字
当前query还有哪些问题-开放性问题
四、评测集
在指标和指标评分维度确认后,去收集评测数据。
评测集就像考试的考题一样,需要覆盖重点考察的知识点。一份好的评测集,需要有足够的真实度和场景覆盖度。数据来源通常有以下场景:
1. 历史真实数据
这是最有价值的数据来源,可以直接获取历史真实业务的数据作为基础,例如:
- 过去3个月内客户咨询客服的问题
- 客户搜索的关键词提取
- 用户反馈的问题工单
- 实际发生的异常case
2. 人工构造数据
针对一些低频但高风险的场景,需要人工构造测试用例:
- 边界条件测试(极大值、极小值、空值等)
- 异常场景测试(系统报错、API超时等)
- 对抗性测试(恶意指令、模糊表达等)
3. 合成数据
利用大模型生成测试数据,但需要人工审核确保质量。
举个例子:

由于评测的方向和目标的不一致,评测集的使用方式也不一样,例如,原始数据为:获取了线上3个月内客户咨询的1000组对话。
要评估走向人工答复的原因,则可以筛选出对话最终走向人工的对话;
要评估Agent拒答的原因,则可以筛选出Agent回复类似,很抱歉,对不起…
五、评测执行
有了指标和评测集,接下来就是执行评测。评测执行分为人工评测和自动化评测两种方式。
1. 人工评测
人工评测适用于初期验证和复杂场景判断。通过人工对比Agent生成的内容与标准答案,对结果进行各项指标的打分。
即评测集包含:用户提问/Agent答复/标准答复。
然后将评测集分发给多位参与评测的成员,人工判断Agent答复的内容与标准答案进行打标,最后按照打标结果进行分析。
2. 自动化评测
自动化评测适用于大规模、高频次的评测场景。
在设定好了指标和评分维度后,利用另一个大模型作为”裁判”,评估Agent的输出质量:
评测提示词示例:

对比人工评测和自动化评测,各有优劣。
人工评测依靠的是主观的判断,很容易因为人为因素而影响判断和最后的结果,因此会采取交叉评测的方式来降低这种影响;
而自动化评测,本身命题是否成立还有待商榷,用AI评价AI生成的内容,可靠性能到多少?
六、结果分析与优化
评测执行完成后,即需要对打标的内容进行汇总分析,找到本次想要验证和优化的点。
通过计算各项指标的:平均值、加权平均值、中位数、标准差、分布区间等,看出Agent输出是否稳定,最终结果是否在预期范围内等;

根据某个问题的打标占比,找到解决问题的方向;

将问题进行分门别类的归纳并对应寻求解决方案,在之前的文章中,也提到过部分优化的方案:
例如:
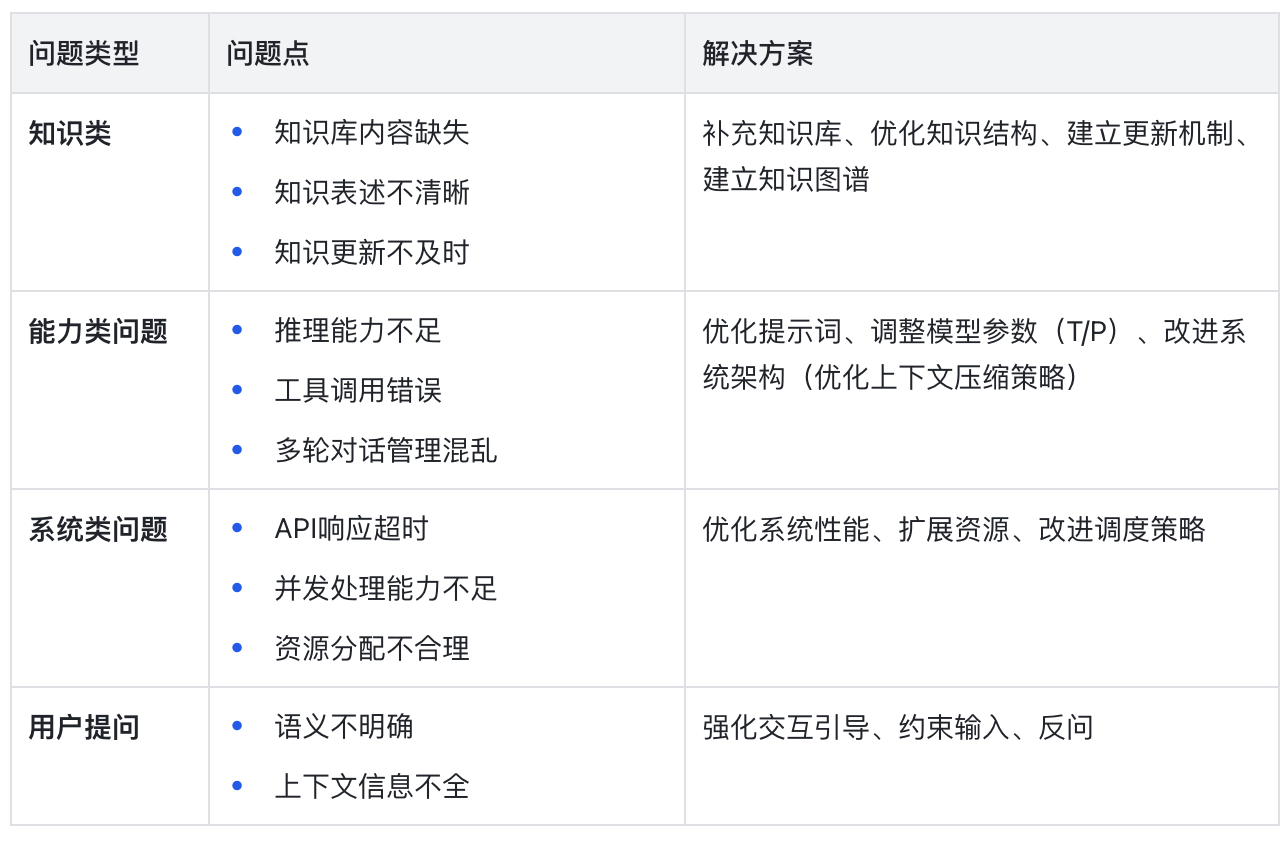
最后即是针对性的做调整、优化后,新一轮的迭代、上线、观测、评测、再次迭代的流程了。
写在最后
Agent评测是一个系统工程,不是简单的打分游戏。一个完善的评测体系,需要合理的指标设计、高质量的评测集、科学的执行方法、深入的结果分析,以及持续的迭代优化。
在实践中,通常会遇到各种各样的困难和挑战:评测标准的主观性、评测成本的高昂、真实场景的难以模拟、模型黑盒的难以诊断等。但这些都是正常的,关键是要有系统性的思维和解决问题的方法论。
借用一句话:“没有度量,就没有改进。” 只有建立系统化的评测体系,才能真正驾驭Agent,让AI为业务创造价值。
本文由 @诸葛铁铁 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


