
 起点课堂会员权益
起点课堂会员权益数据思维驱动AI产品迭代:以推荐系统为例的实战指南
在AI产品迭代的浪潮中,数据不再只是支撑,而是驱动。推荐系统作为最典型的应用场景,正展现出数据思维如何塑造产品优化的路径。本文将以实战案例为核心,带你理解数据驱动迭代的逻辑与价值。
引言:为什么AI产品经理必须是数据掌舵人?
各位有没有想过,为什么同样是做推荐系统,有些产品能让用户一看就停不下来,而有些产品推荐的内容却总是让人觉得”这不是我想要的”?
AI产品和传统产品最大的不同,在于它的核心价值来源于数据和算法的持续迭代。如果把AI产品比作一艘在大海中航行的船,那么数据就是罗盘,而产品经理则必须是那个最会看罗盘的掌舵人。没有数据思维的AI产品经理,就像在浓雾中航行却没有罗盘的船长,永远不知道自己要驶向何方,更别提带领团队到达成功的彼岸了。
在传统产品中,我们可以通过用户访谈、可用性测试等方式获取反馈,然后基于这些定性的 insights 来优化产品。但在AI产品,尤其是像推荐系统这样的产品中,这种方式就显得远远不够了。因为AI系统的决策过程往往是”黑箱”式的,用户看到的只是最终结果,很难准确描述中间过程的问题所在。
更重要的是,AI模型的优化往往是一个边际效益递减的过程。我们可能花了很大力气将某个模型指标提升了1%,但用户几乎感受不到任何变化。这时候,如果产品经理不能用数据来准确衡量和证明AI的商业价值,就很容易在资源竞争中处于劣势。
说实话,太多初入行AI产品经理会因为缺乏数据思维而陷入困境。他们要么被算法团队的技术指标牵着鼻子走,要么凭感觉做决策,最终导致产品迭代方向与业务目标背道而驰。这也是我写这篇文章的初衷——希望能用一个真实的案例,带你走完数据驱动AI产品迭代的完整流程,让你真正理解为什么数据思维对AI产品经理如此重要。
案例背景-搭建一个”更懂你”的电商推荐系统
让我们从一个具体的案例开始。我之前负责优化一个服装电商APP的推荐模块,也就是大家常说的”猜你喜欢”。这个模块位于APP首页的核心位置,按理说应该是流量和转化的重要来源,但实际表现却一直平平。
我记得第一次看到这个推荐模块的数据时,心里就惊了一下。整个模块的CTR只有行业平均水平的三分之二,GMV贡献更是不到预期的一半。更让人头疼的是,用户对推荐内容的吐槽声不断,后台经常收到类似”为什么总是给我推荐我已经买过的东西”、”这些推荐的商品根本不是我喜欢的风格”这样的反馈。
当时团队内部对这个问题的看法也不一致。算法团队认为是数据量不够,尤其是新用户的数据太少,导致模型很难准确捕捉用户兴趣。运营团队则觉得是商品池的问题,认为推荐的商品本身就缺乏吸引力。而业务团队最关心的是,这个模块到底能不能带来实际的GMV增长,什么时候能看到效果。
我简单梳理了一下我在实际工作场景中的思路:
第一步也是最重要的一步,就是明确我们的业务目标。真实工作场景中需要经过和各方反复沟通,例如最终可以将这个推荐系统的核心业务目标确定为:在未来6个月内,将推荐模块带来的GMV占比从目前的15%提升到25%。
为什么选择GMV占比作为核心目标?因为对于电商平台来说,最终的商业价值才是王道。我们可以追求点击率、停留时长等指标的提升,但这些都应该是服务于最终的商业目标,而不是为了优化而优化。

确定了这个大目标后,我们还需要思考:什么样的推荐系统才能真正帮助我们实现这个目标?在我看来,一个”更懂你”的推荐系统应该具备以下几个特点:
- 能够准确捕捉用户的真实兴趣,推荐用户真正想要的商品
- 在满足用户现有兴趣的同时,也能适当拓展用户的新兴趣点
- 能够根据用户的行为实时调整推荐策略,做到“千人千面”
- 既能推荐热门商品,也能发现长尾商品的价值
带着这些思考,我们开始整个推荐系统的迭代优化之路。接下来的内容,我会详细分享产品经理如何一步步通过数据驱动的方式,发现问题、分析问题、解决问题,并最终实现业务目标的。我相信,整个过程中的经验和教训,对于任何从事AI产品工作的人来说,都会有所启发。
第一步:定义衡量AI好坏的”尺子”——数据指标体系构建
在开始任何优化工作之前,我们首先需要一把能够准确衡量AI系统好坏的”尺子”。这把尺子,就是我们的数据指标体系。没有清晰的指标,就像射箭没有靶子,你永远不知道自己有没有命中目标,更不知道自己离目标有多远。
我见过很多团队在做AI产品时,要么指标定义得模糊不清,要么就是盲目追求技术指标,结果往往是费力不讨好。比如有些推荐系统团队,整天把”准确率”挂在嘴边,觉得准确率越高,系统就越好。但实际上,如果一味追求准确率,很容易导致推荐结果过于单一,用户很快就会感到厌倦,最终反而会影响整体的用户体验和商业转化。
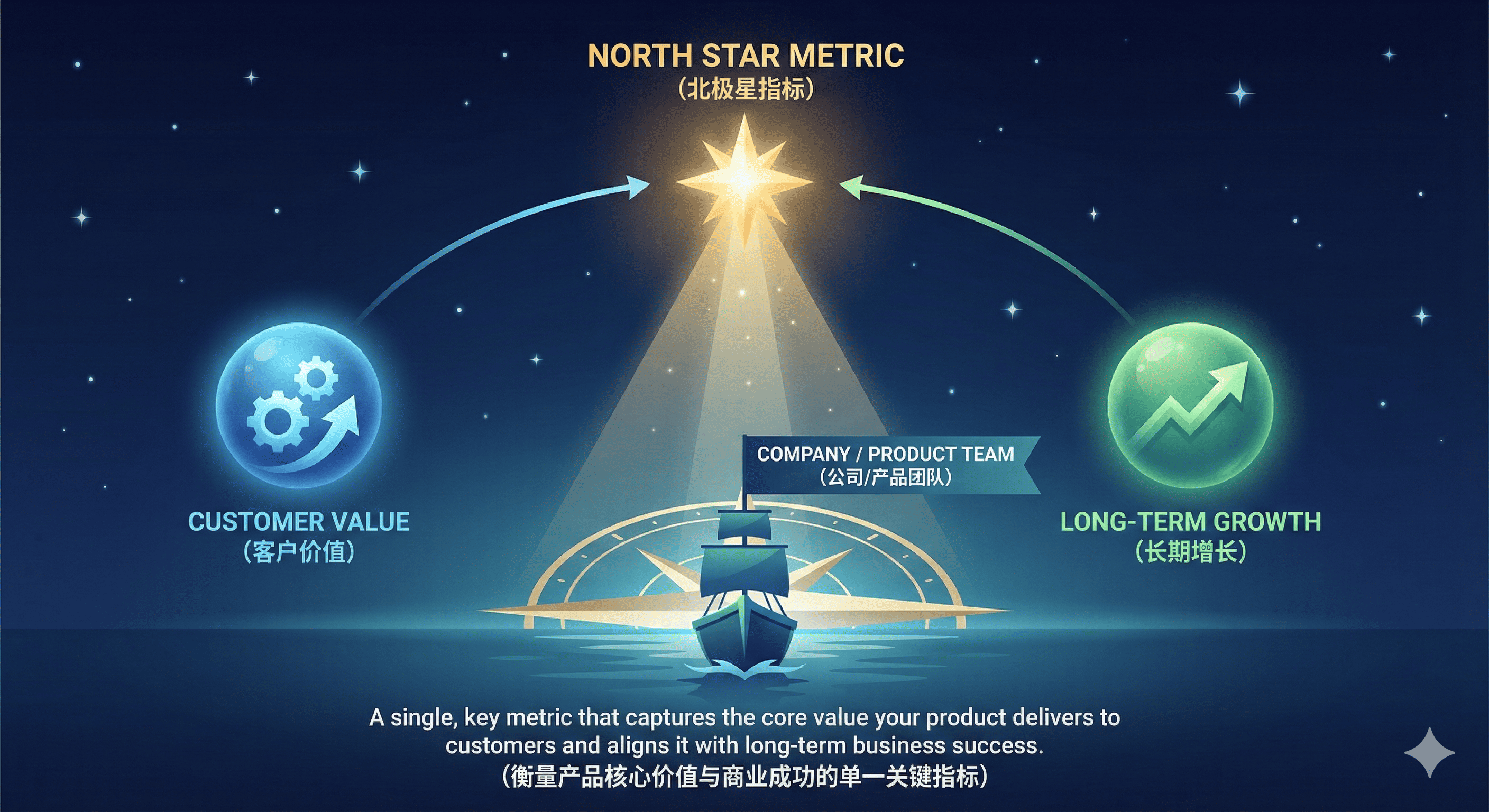
北极星指标:推荐模块带来的GMV占比
我们前期已经确定,我们的核心业务目标是将推荐模块带来的GMV占比从15%提升到25%。这个目标,自然而然地就成为了我们整个优化过程中的”北极星指标”。
选择北极星指标的关键,在于它必须能够直接反映产品的核心价值,并且是可衡量、可实现、与业务目标强相关的。对于推荐系统来说,GMV占比正是这样一个指标——它直接反映了推荐模块对整体业务的贡献,数值可精确衡量,25%的目标经过分析也是可以实现的。
核心过程指标:从点击到转化的全链路追踪
北极星指标虽然重要,但它是一个结果指标,变化相对缓慢,而且无法直接指导我们的日常优化工作。因此,我们还需要一套能够反映中间过程的核心指标,来帮助我们更精细地衡量和优化系统表现。
对于推荐系统来说,用户的行为路径通常是:看到推荐内容(曝光)→点击感兴趣的内容(点击)→查看详情页(浏览)→采取行动(加购或下单)。基于这个路径,我们设计了以下几个核心过程指标:
为了衡量推荐内容在不同阶段的表现,可以从曝光、点击、详情页进入以及最终的购买过程建立指标体系。
首先,通过 曝光点击率(CTR),即点击次数除以曝光次数,用于衡量推荐内容对用户的基础吸引力。
其次,点击到详情页转化率,计算公式为详情页浏览次数除以点击次数,用来判断用户点击后是否认为内容与自身兴趣相关。
进一步地,详情页到加购转化率(加购次数除以详情页浏览次数)能够反映推荐内容激发用户购买欲望的能力。
最后,详情页到下单转化率(下单次数除以详情页浏览次数)用于衡量推荐内容的最终商业转化效果。
这四个指标形成了一个漏斗,从用户看到推荐内容开始,到最终完成购买,每一个环节的转化效率都反映了推荐系统在某个方面的表现。通过监控这个漏斗,我们可以很直观地看到用户在哪个环节流失最多,从而有针对性地进行优化。
模型健康度指标:避免”只见树木不见森林”
除了业务指标,我们还需要关注一些反映模型健康状况的指标。这些指标可能不会直接影响短期的商业表现,但从长期来看,它们对于维持系统的持续健康发展至关重要。
例如:团队为了追求短期的点击率和转化率,把所有流量都集中到了少数几个热门商品上。短期内数据确实会很漂亮,但没过多久,用户就开始抱怨推荐内容太单一,看来看去都是那些东西,最终导致整体的用户活跃度和留存率都出现了明显的下滑。
所以说,评估一个AI系统的好坏,不能只看短期的商业指标,还要关注系统的长期健康度。为此,我们可以设计以下几个模型健康度指标:
- 覆盖率:被推荐的商品数量 / 总商品数量。这个指标反映了我们的推荐系统是否能够覆盖足够多的商品,避免“马太效应”导致的商品资源分配不均。
- 新颖性:用户首次接触的商品占比。这个指标反映了推荐系统是否能够帮助用户发现新的商品,避免用户陷入“信息茧房”。
- 多样性:推荐结果中不同品类/风格/价格段商品的占比分布。这个指标反映了推荐结果的丰富程度,避免推荐内容过于单一。
这些健康度指标,就像是推荐系统的”体检报告”。它们可能不会直接告诉你哪里出了问题,但却能提醒你系统是否存在潜在的健康风险,帮助你在问题变得严重之前就采取措施。
有了这套完整的指标体系,我们就像是有了一把精确的尺子和一套全面的体检报告。接下来,我们就可以用这把尺子来衡量系统的表现,用体检报告来关注系统的健康状况,从而有针对性地进行优化和改进。
第二步:定位问题——”哪里不行?”与”为什么不行?”
有了指标体系,我们就可以开始系统地分析推荐系统的表现了。记得刚开始看数据的时候,我总是被各种图表和数字搞得眼花缭乱,不知道从哪里下手。后来我慢慢总结出一个经验:分析数据就像医生看病,首先要通过”望闻问切”发现异常,然后再深入诊断病因。
我们先来看一下整体数据表现。从表面上看,我们的推荐系统似乎还不错:整体CTR稳定在2.3%左右,和行业平均水平差不多;推荐模块带来的GMV也在稳步增长,每个月大概有5%左右的提升。但是,如果把这些数据和我们定的北极星指标——GMV占比对比一下,问题就立刻显现出来了:虽然GMV在增长,但它的增长速度远远落后于整体平台的GMV增长速度,导致GMV占比不升反降,从15%跌到了14.2%。
这就好比一个学生,虽然每次考试分数都在提高,但在班级里的排名却一直在下降。这时候,我们不能只看到分数的提高就沾沾自喜,而是要分析为什么排名会下降——是自己进步太慢,还是别人进步太快?
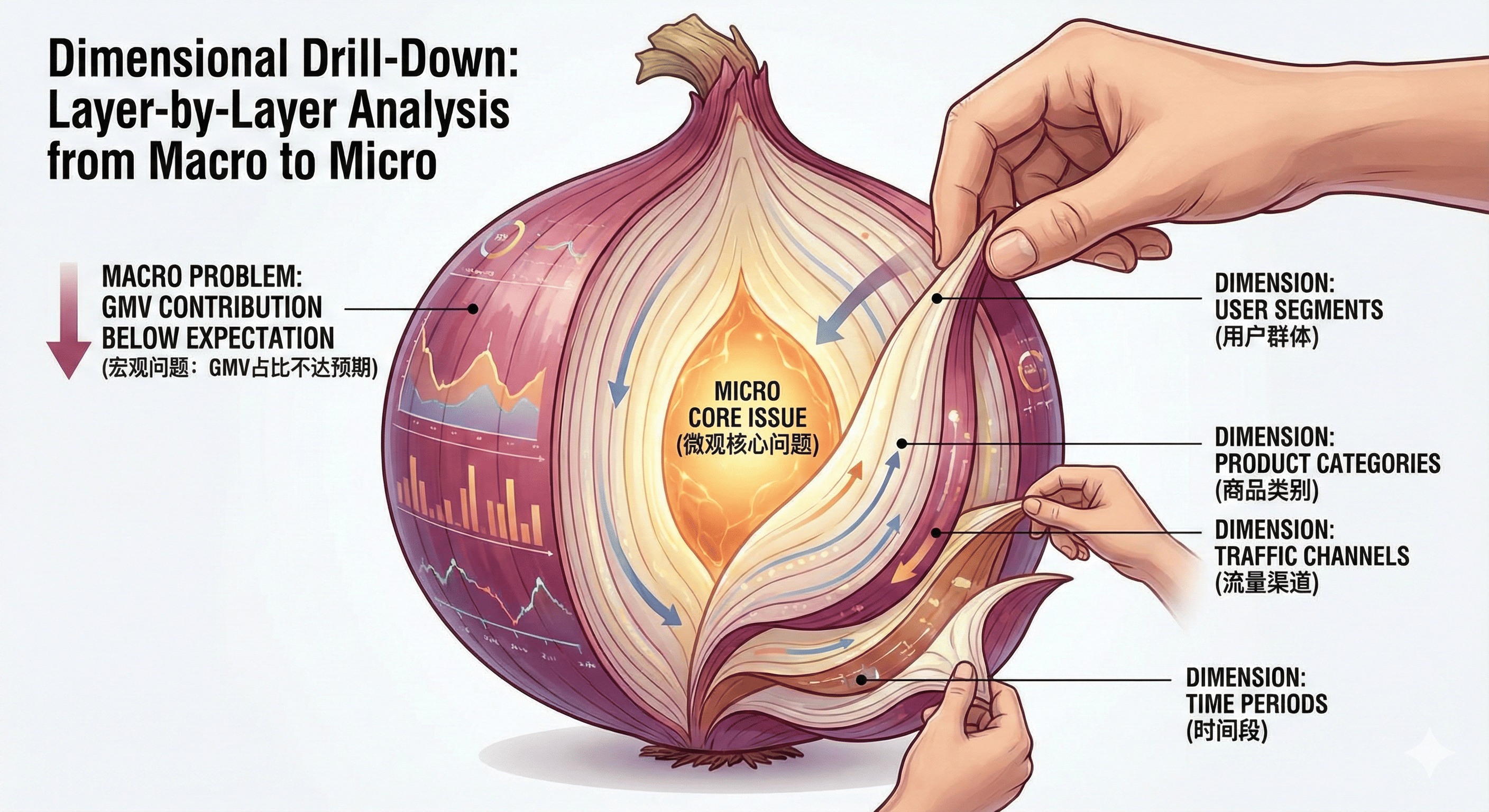
维度下钻:从宏观到微观的层层剖析
发现了GMV占比不达预期这个宏观问题后,我们需要做的就是”下钻”——从不同维度对数据进行细分分析,找出问题到底出在哪里。这个过程就像是剥洋葱,一层一层地剥,直到找到最核心的问题所在。
用户分群:新用户 vs 老用户
我们首先按照用户的使用时长,将用户分为新用户(使用时长<1个月)、中期用户(1个月≤使用时长<6个月)和老用户(使用时长≥6个月)三个群体,然后分别分析他们在推荐模块的表现。
分析结果让我们大吃一惊:老用户的CTR高达3.5%,详情页转化率也有28%,而新用户的CTR只有1.2%,详情页转化率更是低到只有8%。更重要的是,新用户在推荐模块的GMV贡献占比一直在下降,从原来的20%降到了15%左右。
这个发现很重要,因为平台的新用户增长一直很稳定,占总用户的比例在30%左右。如果这部分用户在推荐模块的体验和转化一直上不去,那么整体的GMV占比目标就很难实现。
场景分析:首页推荐 vs 详情页关联推荐
接下来,我又分析了不同场景下的推荐表现。推荐系统主要分布在两个场景:首页的”猜你喜欢”模块,和商品详情页底部的”看了又看”关联推荐模块。
数据显示,首页推荐的CTR虽然不算高(2.1%),但转化率还不错(详情页到下单的转化率有3.2%);而详情页关联推荐的表现则差强人意——CTR只有1.5%,转化率更是低到只有1.8%。考虑到详情页场景本身就带有比较强的购买意向,这样的表现显然是不达标的。
内容分析:哪些商品表现好,哪些表现差?
除了用户和场景,我还对推荐的商品内容进行了分析。我们发现,有两类商品的推荐效果特别差:一类是价格低于20元的低价商品,虽然点击率还不错,但转化率极低,只有0.5%左右;另一类是新品,尤其是那些没有任何历史销售数据的全新商品,点击率和转化率都远低于平均值。
这两类商品的占比还不低,加起来差不多占了整个推荐流量的30%。这就好比一个球队,有三分之一的球员表现不佳,整体成绩自然很难上去。
归因分析:拨开迷雾见真相
通过以上几个维度的分析,我们已经发现了不少问题点:新用户表现差、详情页关联推荐效果不佳、低价商品和新品推荐效率低。但这些还只是表面现象,我们需要进一步分析,为什么会出现这些问题?背后的根本原因是什么?
我们团队为此专门开了一次头脑风暴会议。算法工程师认为是数据稀疏性问题,尤其是新用户和新品,缺乏足够的行为数据来训练模型。运营同事则认为是商品标签体系不够完善,导致模型很难准确捕捉商品特征。而我则注意到一个细节:我们的推荐算法用的是统一的模型,无论是对新用户还是老用户,无论是在首页还是详情页,用的都是同一套逻辑。
经过深入讨论和进一步的数据验证,我们最终将问题的核心定位在了”冷启动”场景上——也就是当系统缺乏足够用户行为数据时的推荐效果问题。具体来说,这个问题又可以分为两个方面:新用户冷启动和长尾商品冷启动。
对于新用户,由于系统缺乏他们的历史行为数据,很难准确捕捉他们的兴趣偏好,导致推荐内容相关性不高。而对于长尾商品,尤其是新品,由于缺乏足够的交互数据,系统很难判断它们的质量和受欢迎程度,导致推荐效果不佳。
更重要的是,这两个问题是相互叠加的。新用户本来就对平台不熟悉,更需要高质量的推荐来建立对平台的信任和兴趣。但恰恰是在这个关键阶段,我们的推荐系统表现最差,这直接影响了新用户的留存和转化。
第三步:提出假设与数据验证——”我们该怎么改?”
找到了冷启动这个核心问题后,接下来就是思考如何解决它。这时候,我们不能拍脑袋就决定要做什么,而是要基于前面的分析提出合理的假设,然后通过数据来验证这些假设是否成立。这就像是做科学实验,先提出假设,再设计实验验证,最后根据结果得出结论。
提出产品假设:混合推荐策略能否解决冷启动问题?
基于对冷启动问题的理解,我们团队提出了一个核心假设:在冷启动阶段,引入基于热门商品或相似用户群的混合推荐策略,能够有效提升新用户的点击和转化。
为什么会提出这个假设?因为我们发现,纯粹的个性化推荐在冷启动场景下效果往往不佳,这时候需要一些”保底”的策略。热门商品推荐就是一种很好的保底策略——虽然不够个性化,但至少能保证推荐内容的普遍吸引力。而相似用户群推荐则是一种折中的策略——基于和新用户相似的老用户的行为数据来做推荐,既能保证一定的个性化,又能避免数据稀疏性的问题。
具体来说,我们设计了三种不同的混合推荐策略:
- 策略A(对照组):现有的纯个性化推荐策略
- 策略B:个性化推荐(60%)+ 热门商品推荐(40%)
- 策略C:个性化推荐(50%)+ 相似用户群推荐(30%)+ 热门商品推荐(20%)
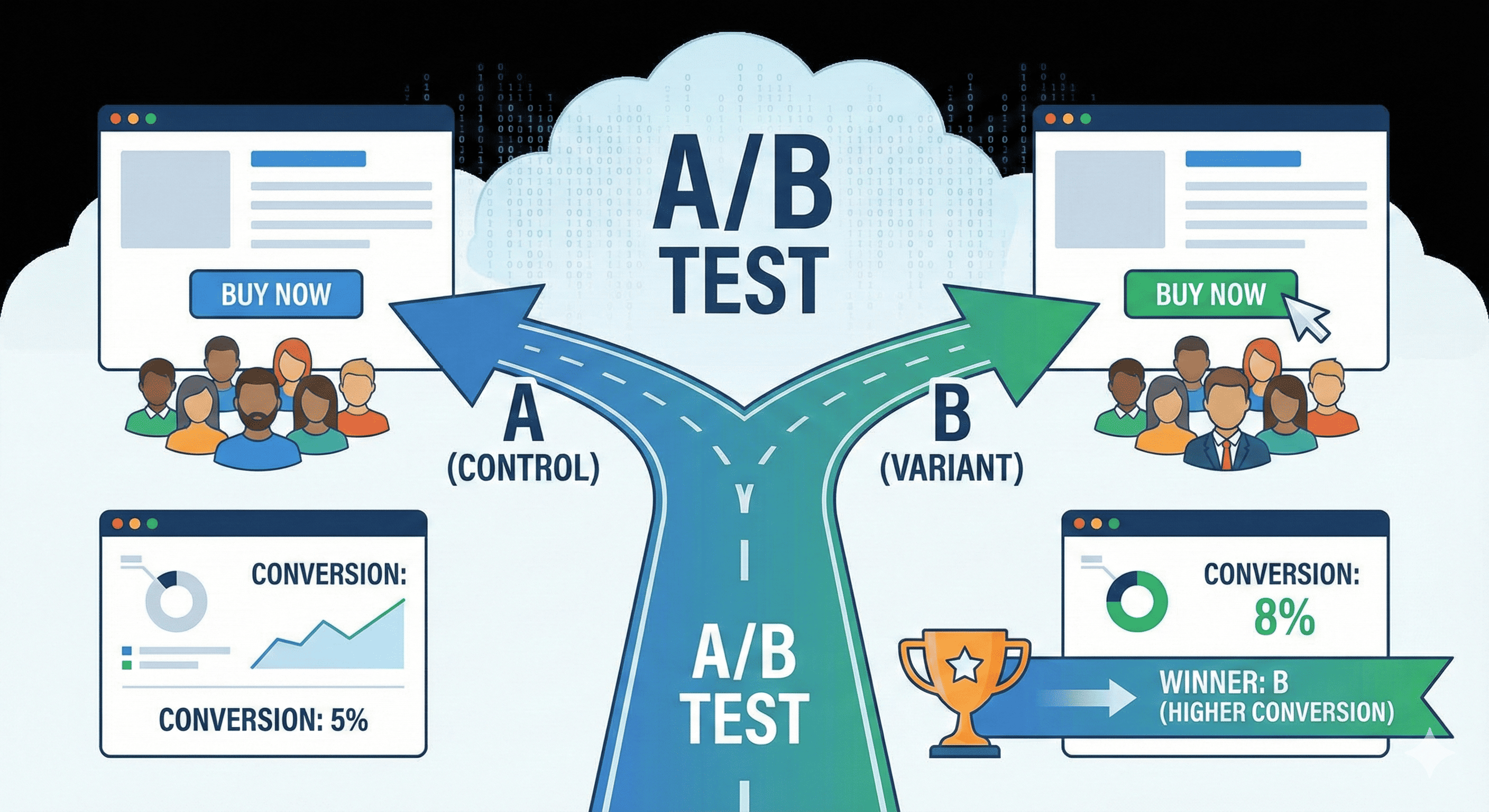
设计验证方案:A/B测试
提出假设后,我们需要设计一个严谨的实验来验证它。
首先是样本量的确定。我们通过统计功效分析,计算出每组至少需要1000名新用户才能保证结果的统计显著性。考虑到可能会有用户流失,我们最终决定每组分配1500名新用户,总共4500名新用户参与这次实验。
其次是流量分配。为了保证实验的公平性,我们采用了随机分配的方式,将符合条件的新用户随机分配到A、B、C三个组中。同时,我们还控制了其他可能影响结果的因素,比如用户的注册渠道、设备类型等,确保三个组在这些方面的分布基本一致。
然后是实验周期。考虑到用户行为可能会受到周末、节假日等因素的影响,我们将实验周期定为2周,确保覆盖了完整的用户行为周期。
最后是数据采集。我们需要采集的数据不仅包括核心的业务指标(CTR、转化率、GMV等),还包括一些模型健康度指标(如推荐多样性、新颖性等),以全面评估不同策略的表现。
做A/B测试有一个很重要的原则,就是”单一变量原则”——即每次实验只改变一个因素,其他条件保持不变。这样,当实验结果出现差异时,我们才能确定是这个因素导致的差异,而不是其他因素。在这次实验中,我们唯一改变的就是推荐策略,其他所有条件(如推荐位置、展示形式等)都保持一致。
实验过程中的小插曲
实验开始后的第三天,我们就迫不及待地看了一下初步数据。结果让我们有些意外:策略B的CTR竟然比对照组A低了10%左右,而策略C的CTR则低了5%。当时团队里有些人开始动摇了,觉得我们的假设可能是错的。
但我的想法是:”现在数据还太少,可能存在偶然性。而且我们不能只看CTR,还要看最终的转化效果。”—做数据实验最忌讳的就是”过早下结论”,尤其是在数据量不足的情况下。
随着实验的进行,数据慢慢开始显现出稳定的趋势。到第一周末的时候,策略B和策略C的CTR虽然还是低于对照组,但差距已经缩小到了3%和1%。更重要的是,在转化率方面,策略B和策略C开始反超对照组——策略B的详情页-下单转化率比对照组高了15%,策略C更是高了22%!
这个结果让我们备受鼓舞,也更加坚定了我们的假设。接下来的一周,这种趋势继续保持,而且差距进一步扩大。到实验结束时,策略C不仅在转化率上领先对照组30%,在GMV贡献上更是领先了35%。而策略B虽然也比对照组好,但效果明显不如策略C。
实验结果证明,我们的假设是成立的:混合推荐策略确实能够有效提升新用户的点击和转化。尤其是策略C——个性化推荐+相似用户群推荐+热门商品推荐的组合,表现最为出色。
第四步:效果评估与持续监控——”改得怎么样?下一步去哪?”
实验成功后,我们迫不及待地想把策略C全量上线。但就在准备上线的前一天,我突然想到一个问题:实验环境和生产环境毕竟还是有差异的,小范围实验成功并不代表全量上线后一定能取得同样的效果。而且,即使效果好,我们也需要知道好到什么程度,能给业务带来多少实际的提升。
全面评估:不只是看指标,还要算收益
我们决定先进行小范围灰度发布——先将策略C应用到20%的新用户上,观察一周的表现,然后再决定是否全量推广。灰度发布的结果让我们非常满意:这20%新用户的推荐模块GMV贡献比之前提升了32%,和实验结果基本一致。
有了灰度发布的数据,我们就可以比较准确地估算全量上线后的效果了。当时我们平台每个月新增用户大约有1万,按照灰度发布的提升比例计算,如果全量上线策略C,每个月大概能多带来300万左右的GMV。这个数字虽然听起来不错,但我们还需要把它放到更大的业务背景下来看——300万GMV对于我们整个平台来说,大概能提升0.5个百分点的GMV占比。
这就好比你在玩游戏,好不容易打了一个小怪,获得了一些经验值。这些经验值虽然能让你升级,但升级的速度可能比你预期的要慢。这时候,你不能只满足于打小怪,还要想办法打更大的怪,获得更多的经验值。
虽然0.5个百分点看起来不多,但考虑到这只是针对新用户的一个优化,而且我们还有其他的优化方向(比如详情页关联推荐、长尾商品推荐等),加起来的效果应该会相当可观。基于这个分析,我们决定——全量上线策略C!
建立数据看板:实时监控系统表现
全量上线后,我们并没有就此止步。相反,我们建立了一个实时数据看板,用来持续监控推荐系统的各项指标。这个看板就像是推荐系统的”心电图”,能够让我们随时了解系统的”健康状况”。
看板上的数据每小时更新一次,包括:
- 核心业务指标:GMV占比、CTR、转化率等的实时值和日环比、周环比变化
- 用户分群指标:新用户、中期用户、老用户在推荐模块的表现
- 场景指标:不同推荐场景(首页、详情页等)的表现
- 模型健康度指标:覆盖率、新颖性、多样性等
通过这个看板,我们可以及时发现系统的异常情况。
下一个迭代周期:高价值用户的个性化推荐
这一次,我们的重点不再是冷启动,而是如何提升高价值用户的推荐精度和满意度。
我们提出的新假设是:通过引入用户分层推荐策略,为高价值用户提供更精准、更个性化的推荐内容,能够有效提升他们在推荐模块的GMV贡献。
具体来说,我们计划:
- 基于用户的消费能力、购买频率、品类偏好等维度,构建更精细的用户分层模型
- 为不同层级的用户设计差异化的推荐策略,尤其是针对高价值用户,增加“惊喜推荐”的比例
- 引入更多维度的数据(如用户的浏览深度、停留时间、社交关系等)来优化推荐模型
我相信,只要我们坚持数据驱动的理念,不断地发现问题、分析问题、解决问题,就一定能够实现我们的业务目标。
数据驱动AI产品迭代,就像是一场马拉松,而不是百米冲刺。它需要我们有耐心、有毅力,不断地积累数据、优化模型、提升体验。在这个过程中,我们可能会遇到各种困难和挫折,但只要我们方向正确,方法得当,就一定能够到达终点。
总结:AI产品经理的数据思维修炼
回顾我们推荐系统的优化历程,从最初的GMV占比下滑,到发现冷启动问题,再到通过混合推荐策略解决问题,最后又发现高价值用户的推荐精度问题,整个过程其实就是一个数据思维的实践过程。通过这个过程,我总结出了一套AI产品迭代的核心流程,希望能对大家有所启发。
定义指标-定位问题-提出假设-数据验证-评估迭代
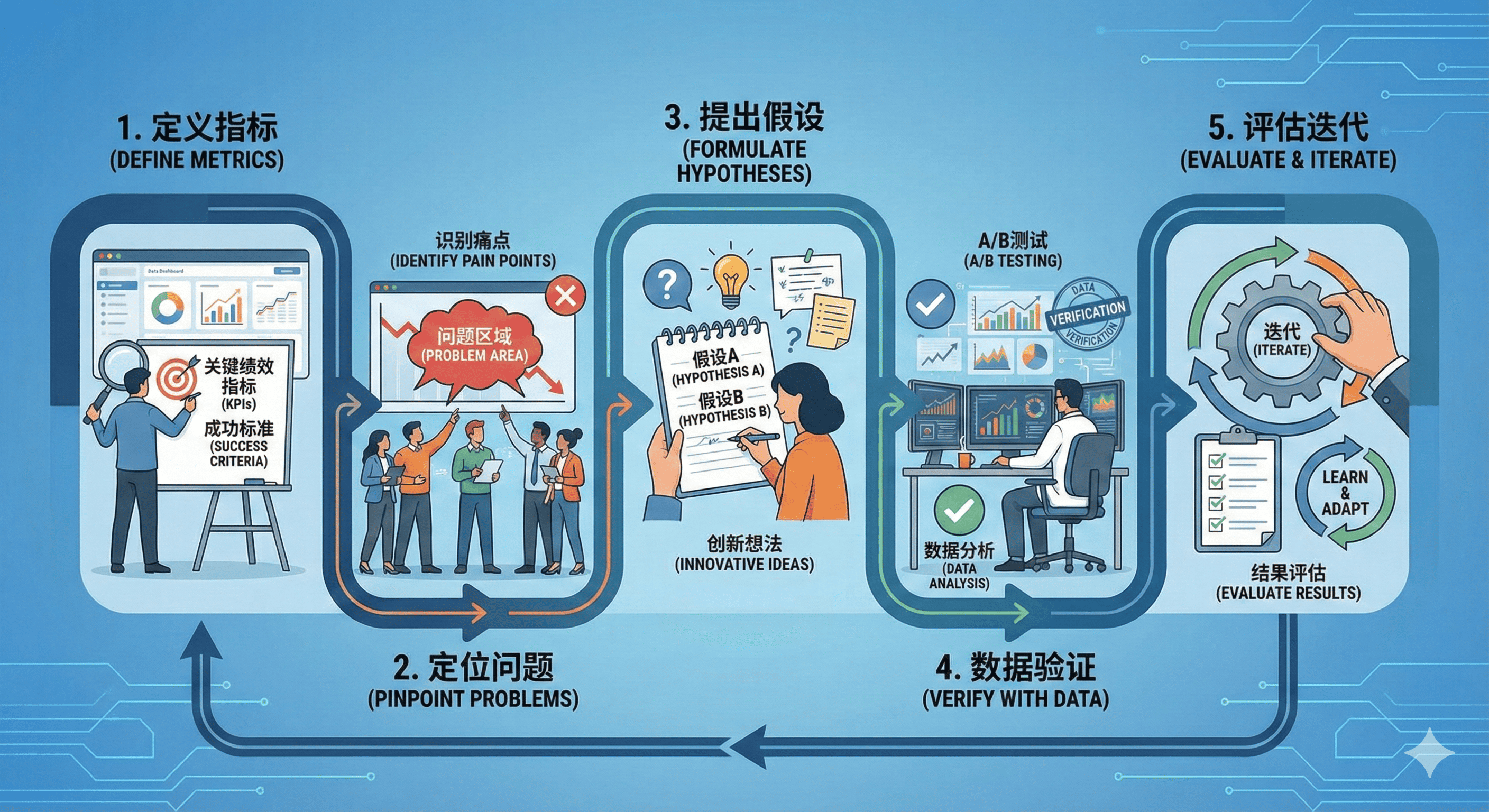
核心流程:从数据到价值的闭环
1)定义指标:找到你的“北极星”
在我们的案例中,GMV占比就是我们的北极星指标,而CTR、转化率等则是支撑这个北极星指标的过程指标。这些指标共同构成了我们衡量推荐系统好坏的”尺子”。
2)定位问题:数据下钻的艺术
有了指标,接下来就是通过数据分析来发现和定位问题。这个过程需要我们具备”数据下钻”的能力——从宏观到微观,从整体到局部,层层剖析,直到找到问题的根源。
在我们的案例中,我们通过用户分群、场景分析、内容分析等多个维度对数据进行下钻,最终将问题定位在了冷启动场景上。这个过程就像是剥洋葱,虽然可能会流泪,但只要坚持下去,就一定能看到最核心的部分。
3)提出假设:基于洞察的大胆猜想
发现问题后,我们需要提出合理的假设——问题可能是什么原因导致的,以及如何解决。这个过程需要我们具备洞察力和创造力,能够基于数据分析的结果,提出大胆而合理的猜想。
在我们的案例中,我们提出的假设是”混合推荐策略能够解决冷启动问题”。这个假设不是凭空想象出来的,而是基于我们对冷启动问题的深入理解和对用户行为的洞察。
4)数据验证:用实验说话
假设提出后,不能想当然地认为它就是对的,而是需要通过数据来验证。A/B测试是验证假设最常用也最有效的方法。通过严谨的实验设计和数据分析,我们可以科学地验证假设的正确性。
在我们的案例中,我们通过A/B测试验证了混合推荐策略的有效性,发现策略C(个性化推荐+相似用户群推荐+热门商品推荐)能够显著提升新用户的转化效果。
5)评估迭代:持续优化,永无止境
实验验证后,我们需要对结果进行全面评估,包括指标提升、业务价值、用户体验等多个方面。然后,基于评估结果进行推广或调整,并持续监控系统表现,发现新的问题,开启下一轮的优化迭代。
在我们的案例中,虽然混合推荐策略取得了不错的效果,但我们并没有止步于此,而是通过持续监控发现了高价值用户推荐精度不足的新问题,开启了下一轮的优化。
AI产品经理的关键能力:连接数据、算法与业务
通过这段经历,我深刻认识到,优秀的AI产品经理需要具备三种核心能力:
- 业务洞察能力:能够深刻理解业务目标,将业务目标转化为可衡量的指标和可执行的产品策略。
- 数据分析能力:能够熟练运用数据分析方法,从数据中发现问题、定位原因、评估效果。
- 跨团队协作能力:能够与算法、工程、运营等不同团队有效沟通协作,推动产品迭代落地。
这三种能力就像是一个三角形的三个顶点,缺一不可。业务洞察能力确保我们做”正确的事”,数据分析能力确保我们”把事做对”,而跨团队协作能力则确保我们能够”把事做成”。
在AI时代,最优秀的产品经理不是最懂算法的人,也不是最懂数据的人,而是能够将数据、算法与业务有机连接起来的人。他们能够用数据洞察业务,用算法赋能产品,最终创造真正的商业价值。
本文由 @511(AI产品) 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


