
 起点课堂会员权益
起点课堂会员权益构建认知桥梁:面向企业级对话式BI的NL2MQL2SQL架构与系统提示词工程深度技术报告
随着生成式AI与商业智能的融合,数据分析正经历从图形化交互到自然语言交互的转变。NL2MQL2SQL架构通过引入语义层,解决了传统Text-to-SQL方案在企业级复杂数据仓库中的痛点。本文将提供基于NL2MQL2SQL架构的Chat BI助手的系统提示词设计指南。

随着生成式人工智能(Generative AI)与商业智能(BI)的深度融合,数据分析领域正经历着从“图形化交互”向“自然语言交互”的范式转移。传统的 Text-to-SQL(文本转 SQL)方案在面对企业级复杂数据仓库时,由于缺乏业务上下文理解、逻辑推理能力薄弱以及对“幻觉”的控制力不足,难以满足企业对数据准确性和一致性的严苛要求。
为了解决这一核心痛点,行业逐渐收敛于 NL2MQL2SQL(自然语言转指标查询语言转 SQL)架构。该架构引入了**语义层(Semantic Layer)**作为中间件,将大语言模型(LLM)的生成目标从不可控的 SQL 语句转移为结构化、受控的指标查询语言(MQL)。这一转变不仅极大地提升了查询的准确率,还通过标准化的中间表示层实现了业务逻辑的复用与治理。
本报告旨在为构建基于 NL2MQL2SQL 架构的 Chat BI 助手提供一份详尽的系统提示词(System Prompt)设计指南。报告深入剖析了该架构的理论基础,探讨了语义映射、歧义消解、复杂推理及时间逻辑处理等关键技术挑战,并结合 dbt MetricFlow、Cube、WrenAI 等前沿技术实践,提出了一套模块化、可扩展的 System Prompt 设计框架。通过引入思维链(Chain of Thought)、TypeScript 接口定义及交互式澄清协议,本报告展示了如何将通用 LLM 转化为具备专业素养的“数据分析师”,从而在企业环境中实现可信、可解释的对话式数据分析。
第一章:数据交互范式的演进与语义层的复兴
1.1 从 GUI 到 LUI:分析界面的认知重构
商业智能(BI)的发展史,本质上是降低数据获取门槛的历史。从早期的 SQL 命令行,到以 Tableau、Power BI 为代表的图形用户界面(GUI),每一次交互范式的升级都旨在缩短用户意图与数据洞察之间的距离。然而,GUI 固有的局限性在于其“预定义”的特征——仪表板只能回答设计者预先设想好的问题。当决策者面临突发性、探索性的业务问题时(例如:“上个季度在除德国以外的欧洲市场,哪类产品的毛利率下降最快?”),传统的 GUI 往往无能为力,迫使业务人员依赖数据分析师编写 SQL,造成决策延迟 1。
语言用户界面(LUI)的出现,承诺通过自然语言处理(NLP)打破这一瓶颈。早期的 NL2SQL 尝试主要依赖基于规则的解析或简单的深度学习模型,但在处理复杂语义时表现脆弱。随着大语言模型(LLM)的爆发,GPT-4、Claude 3 等模型展现出了惊人的代码生成能力,使得“与数据对话”似乎触手可及。然而,直接让 LLM 编写 SQL(NL2SQL)在企业落地中遭遇了严重的信任危机 1。
1.2 直接 NL2SQL 的“阿喀琉斯之踵”
尽管 LLM 能够生成语法完美的 SQL 语句,但在面对企业真实数据环境时,其逻辑准确性往往大打折扣。这种失败并非模型能力的缺陷,而是架构设计的错位。
1.2.1 业务逻辑的缺失与“幻觉”
SQL 是一种命令式语言,它描述了“如何”从数据库中提取数据,但并不包含数据“代表什么”的业务语义。例如,当用户询问“计算去年的流失率”时,LLM 必须面对一系列未定义的业务逻辑:
- 流失的定义是什么?是 30 天未登录,还是 90 天无交易?
- 分母是期初用户数还是期末用户数?
- 是否包含试用期用户?
如果没有语义层的约束,LLM 只能基于训练数据中的通用知识进行“猜想”(即幻觉),导致生成的 SQL 逻辑与企业的实际业务定义不符 3。这不仅导致数据不准确,更严重的是造成了“指标漂移”(Metric Drift)——不同的用户询问同一个问题,可能会得到完全不同的计算逻辑 5。
1.2.2 物理图谱的复杂性与上下文过载
企业数据仓库通常包含数千张表,字段命名往往晦涩难懂(如 tbl_f_001_v2)。将完整的数据库模式(Schema)直接注入 LLM 的上下文窗口(Context Window),不仅成本高昂,而且会引入巨大的噪声,导致模型在检索时出现“迷失在中间”(Lost-in-the-Middle)现象 6。此外,物理表结构往往为了性能进行了高度规范化(范式化)或过度反规范化,LLM 难以推断正确的连接(Join)路径,容易陷入“扇形陷阱”(Fan Trap)或“断层陷阱”(Chasm Trap),导致聚合计算错误 7。
1.3 语义层:AI 时代的“Rosetta Stone”
为了解决上述问题,架构重心从“模型能力”转向了“语义治理”。语义层(Semantic Layer)作为位于数据仓库与消费端之间的中间层,负责将复杂的物理数据抽象为业务友好的概念:指标(Metrics)、维度(Dimensions)和实体(Entities) 。
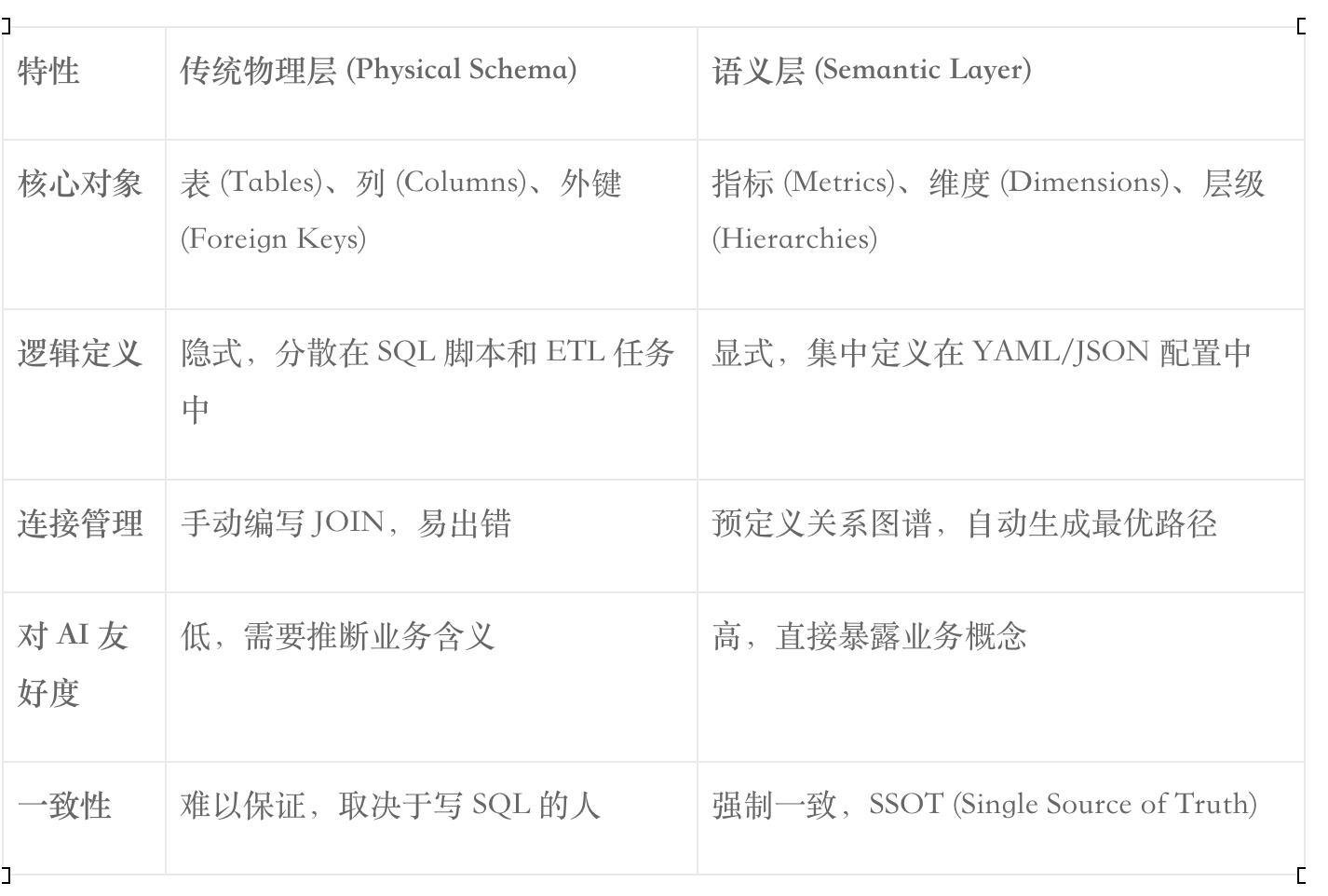
在 NL2MQL2SQL 架构中,LLM 不再直接生成 SQL,而是生成指标查询语言(MQL)。MQL 是一种面向业务意图的声明式语言(通常为 JSON 格式),它只描述“需要什么指标”和“按什么维度分析”,而将“如何生成 SQL”的脏活累活交给语义层引擎(如 Cube, dbt MetricFlow)去完成 8。
这种架构变革将 LLM 的角色从“全能工程师”转变为“业务翻译官”,极大地降低了任务复杂度,提升了系统的可信度与可维护性 11。
第二章:NL2MQL2SQL 架构原理与核心组件
2.1 架构全景图
NL2MQL2SQL 架构的核心在于分层解耦。整个处理流程可以划分为三个主要阶段:意图理解与映射、逻辑规划与生成、执行与反馈。
1)自然语言处理层 (NLP Layer):
- 输入:用户的自然语言问题。
- 处理:LLM 作为核心推理引擎,结合系统提示词(System Prompt)和检索增强生成(RAG)提供的上下文,进行意图识别和实体链接。
- 输出:中间表示层——MQL(JSON/YAML)。
2)语义层引擎 (Semantic Engine):
- 输入:MQL 查询对象。
- 处理:验证 MQL 的合法性(指标是否存在、维度是否匹配),解析预定义的连接路径和计算逻辑,将其编译为针对特定数据库方言的 SQL 语句。
- 输出:可执行的 SQL。
3)数据执行层 (Data Layer):
- 输入:SQL。
- 处理:在云数据仓库(Snowflake, BigQuery, Databricks 等)中执行查询。
- 输出:结果集。
2.2 为什么选择 MQL 而非 SQL?
在系统提示词设计中,明确 LLM 的输出目标至关重要。选择 MQL 作为输出目标具有显著的工程优势:
2.2.1 确定性与可验证性
SQL 极其灵活,同一个查询可以有无数种写法,这使得验证 LLM 生成的 SQL 是否正确变得异常困难。相比之下,MQL 是受限的、结构化的。我们可以轻松编写代码验证生成的 JSON 是否包含必需字段,或者指标名称是否在白名单中。这种“语法即正确性”的特性大大降低了测试和调试的难度 7。
2.2.2 Token 效率与模型亲和性
JSON 和 TypeScript 接口是现代 LLM(特别是经过代码训练的模型)最熟悉的语言格式之一。相比于冗长的 SQL 语句(包含大量的 SELECT, GROUP BY, JOIN ON 等样板代码),MQL 的 JSON 结构更加紧凑,能够显著节省 Token 消耗,提升响应速度 13。
2.2.3 屏蔽底层变更
当底层数据库表结构发生变化(例如字段重命名或表拆分)时,只需要更新语义层的映射配置,而不需要重新微调 LLM 或修改提示词。LLM 始终面向稳定的语义接口编程,实现了应用层与数据层的解耦 7。
第三章:认知架构设计:从 System 1 到 System 2
要设计一个优秀的 System Prompt,不能仅仅将其视为一堆指令的集合,而应该将其视为对 AI 智能体(Agent)**认知架构(Cognitive Architecture)**的编程。认知心理学中的双重加工理论(Dual Process Theory)为我们提供了理论指导:System 1 是直觉的、快速的、联想的;System 2 是逻辑的、慢速的、推理的。
3.1 拒绝“直觉式”生成
传统的 Chatbot 往往依赖 LLM 的 System 1 能力,即看到问题直接生成答案。在数据分析场景下,这种模式极易导致错误。例如,用户问“上周销售额”,模型可能会直觉地查找名为 sales 的列,而忽略了可能存在的 revenue_recognized 和 revenue_booked 的区别。
3.2 强制“思维链” (Chain of Thought)
为了激活 LLM 的 System 2 能力,System Prompt 必须强制模型在生成最终 MQL 之前,先进行显式的推理。这被称为**思维链(Chain of Thought, CoT)**技术 15。
在 Prompt 设计中,我们需要构建一个“推理缓冲区”,要求模型按步骤输出:
- 意图识别:用户是想看总量、趋势、对比还是明细?
- 实体映射(Schema Linking):将自然语言中的词汇(如“赚钱”)映射到语义层中的标准指标(如 gross_profit)。此时需要评估映射的置信度。
- 时间解析:将相对时间(如“上个月”)转化为绝对时间范围(ISO 8601 格式),依据是 Prompt 中注入的当前时间。
- 歧义检测:判断用户的问题是否包含模糊不清的概念,是否需要反问 17。
通过这种分步推理,模型有机会“自我校正”。例如,在推理阶段发现没有直接对应的指标,模型可能会决定请求计算衍生指标或寻求澄清,而不是胡乱生成 19。
3.3 显性化的思考过程
在用户界面(UI)设计上,我们通常不希望用户看到冗长的推理过程,但又需要保留其可解释性以建立信任。一种最佳实践是利用 Markdown 的折叠语法(<details> 标签)将思维链封装起来 20。这样,用户默认看到的是简洁的回答或图表,但点击“查看思考过程”后,可以审查 AI 的逻辑路径,确认其是否正确理解了“上周”的定义。
第四章:语义上下文的结构化表达策略
System Prompt 的核心职能之一是向 LLM 提供“世界知识”,即当前可用的数据指标和维度。如何高效、清晰地将语义层元数据(Metadata)注入到 Prompt 中,直接决定了模型的理解能力和 Token 成本。
4.1 格式之争:JSON vs YAML vs TypeScript
在描述数据模式(Schema)时,存在多种格式选择:
- JSON: 最通用,但语法冗余(大量的引号和括号),Token 消耗较高。
- YAML: 结构清晰,利用缩进表示层级,Token 效率优于 JSON,且更接近人类阅读习惯,适合描述配置和列表 13。
- TypeScript Interface: 对代码生成模型(如 GPT-4, Claude 3.5 Sonnet)极其友好。它利用类型系统(Type System)精确传达了字段的数据类型、枚举值(Enums)和可选性,且 Token 消耗最低 14。
推荐策略:
- 对于语义模型的目录(Catalog)(即有哪些指标和维度),推荐使用 YAML 格式,因为其包含大量描述性文本(Description),YAML 的可读性最强。
- 对于目标输出格式(MQL Schema)(即模型应该生成什么),推荐使用 TypeScript Interface,利用强类型约束模型的输出结构。
4.2 上下文注入策略:RAG 与 动态 Prompt
企业语义层可能包含成百上千个指标。将所有定义一次性塞入 System Prompt 是不可行的,不仅昂贵,而且会因上下文窗口过长导致模型注意力分散(Recall Degradation)。
必须采用 RAG(检索增强生成) 策略:
- 预处理:将所有指标和维度的名称、描述、同义词生成向量索引(Vector Index)。
- 检索:在用户提问时,先对问题进行 Embedding,在向量库中检索出 Top-K 个最相关的指标和维度。
- 注入:将检索到的子集动态插入到 System Prompt 的 {{SEMANTIC_CONTEXT}} 占位符中 6。
这种“即时编译”(Just-in-Time)的 Prompt 构建方式,确保了模型始终专注于与当前问题最相关的业务概念。
第五章:通用指标查询语言 (MQL) 的模式设计
虽然市面上存在多种具体的语义层实现(如 Cube 的 JSON Query, dbt 的 MetricFlow),但在设计通用的 Chat BI Agent 时,我们需要定义一个抽象的、标准化的中间表示。这个 MQL 应该足够通用,能够映射到任何后端的语义引擎。
基于 Cube 和 MetricFlow 的最佳实践 25,我们设计如下的通用 MQL JSON 结构:
// 通用 MQL 接口定义 interface MQLQuery {
// 查询类型:数据检索、需要澄清、无法回答 type: “data_retrieval” | “clarification_needed” | “out_of_scope”;
// 数据检索负载 query?: { metrics: string;
// 指标列表,例如 [“total_revenue”, “active_users”] dimensions?: string;
// 分组维度,例如 [“product_category”, “region”]
// 时间维度处理 timeDimension?: { dimension: string;
// 通常是主要的时间轴,如 “order_date” granularity: “day” | “week” | “month” | “quarter” | “year”; dateRange: string | { start: string; end: string };
// 绝对时间范围 };
// 过滤器 filters?: Array<{ dimension: string; operator: “equals” | “notEquals” | “contains” | “gt” | “lt” | “in”; values: string | number; }>;
// 排序与限制 orderBy?: { metric?: string;
// 按哪个指标排序 dimension?: string;
// 或按哪个维度排序 direction: “desc” | “asc”; }; limit?: number; };
// 澄清负载 clarification?: { message: string;
// 给用户的反问句 options: string;
// 供用户选择的选项 };}
这个结构清晰地涵盖了 BI 查询的核心要素:选什么(Select)、怎么分(Group By)、看哪里(Filter/Where)、看多久(Time Range)。它摒弃了 SQL 的具体语法细节,让 LLM 专注于业务逻辑的组合。
第六章:系统提示词 (System Prompt) 的核心构建模块
基于上述理论,我们将 System Prompt 解构为以下几个核心模块。在实际部署中,这些模块通过模板引擎动态组装。
6.1 角色定义 (Role Definition)
确立 AI 的身份、职责和行为边界。
Prompt 片段示例:
“你是一名专业的语义数据分析师(Semantic Data Analyst)。
你的职责是将用户的自然语言业务问题转化为精确的结构化指标查询(MQL)。
你不直接编写 SQL,也不直接回答文本,而是充当人类意图与数据引擎之间的翻译官。
你的核心原则是:准确(Accuracy)、确定性(Determinism)和诚实(Honesty)。
如果你不确定用户的意图,必须请求澄清,绝不猜测。”
6.2 语义上下文 (Semantic Context)
这是动态注入的知识库,使用 YAML 格式。
Prompt 片段示例:
“你拥有以下可用的语义数据模型。请仅使用此处列出的指标和维度:
YAML
current_date: 2023-11-14 # 用于相对时间计算metrics: – name: total_revenue description: 扣除退款后的净销售额 synonyms: [销售额, 收入, 营收, 卖了多少钱] – name: conversion_rate description: 支付转化率 (订单数 / 访问数) format: percentdimensions: – name: product_category description: 产品的一级分类 values: [Electronics, Home, Fashion] – name: order_status description: 订单当前的生命周期状态“`”
6.3 输出协议 (Output Protocol)
利用 TypeScript 接口强制约束输出格式。
Prompt 片段示例:
“你的输出必须严格遵守以下 TypeScript 接口定义。请在一个 Markdown 代码块中返回 JSON 对象。
[插入 MQLQuery Interface 定义]”
6.4 推理指引 (Reasoning Guidelines)
这是激活 System 2 思维的关键。
Prompt 片段示例:
“在生成 JSON 之前,你必须在一个 <details> 标签内进行逐步推理(Chain of Thought):
1)意图分析:用户想要聚合、对比还是趋势?
2)实体链接:提取关键词并映射到具体的 metrics 和 dimensions。如果置信度低,标记为歧义。
3)时间解析:将“上个月”、“Q3”等相对时间转换为基于 current_date 的 ISO 日期范围。严禁依赖数据库的相对时间函数(如 NOW()),必须在推理步骤中计算出具体日期。
4)过滤器构建:识别隐含的过滤条件(如“美国市场” -> country = ‘US’)。”
6.5 少样本演示 (Few-Shot Learning)
提供 3-5 个高质量的问答对,覆盖常见场景(简单查询、时间过滤、多维分组、歧义处理)。
Prompt 片段示例:
“User: ‘看下上个月电子产品的销售趋势’
Reasoning:
… 用户意图是趋势分析。’销售’映射为 total_revenue。’电子产品’映射为 product_category = ‘Electronics’。’上个月’基于当前日期 2023-11-14 推算为 2023-10-01 至 2023-10-31。’趋势’意味着需要按时间粒度分组,默认为 day 或 week…
Output:
JSON
{ “type”: “data_retrieval”, “query”: {… } }“`”
第七章:歧义处理与交互式澄清机制
在真实对话中,用户的提问往往是模糊的。一个优秀的 Agent 必须具备“反问”的能力,而不是盲目生成结果。这被称为“交互式澄清协议”(Clarification Protocol)** 27。
7.1 歧义的分类与处理策略
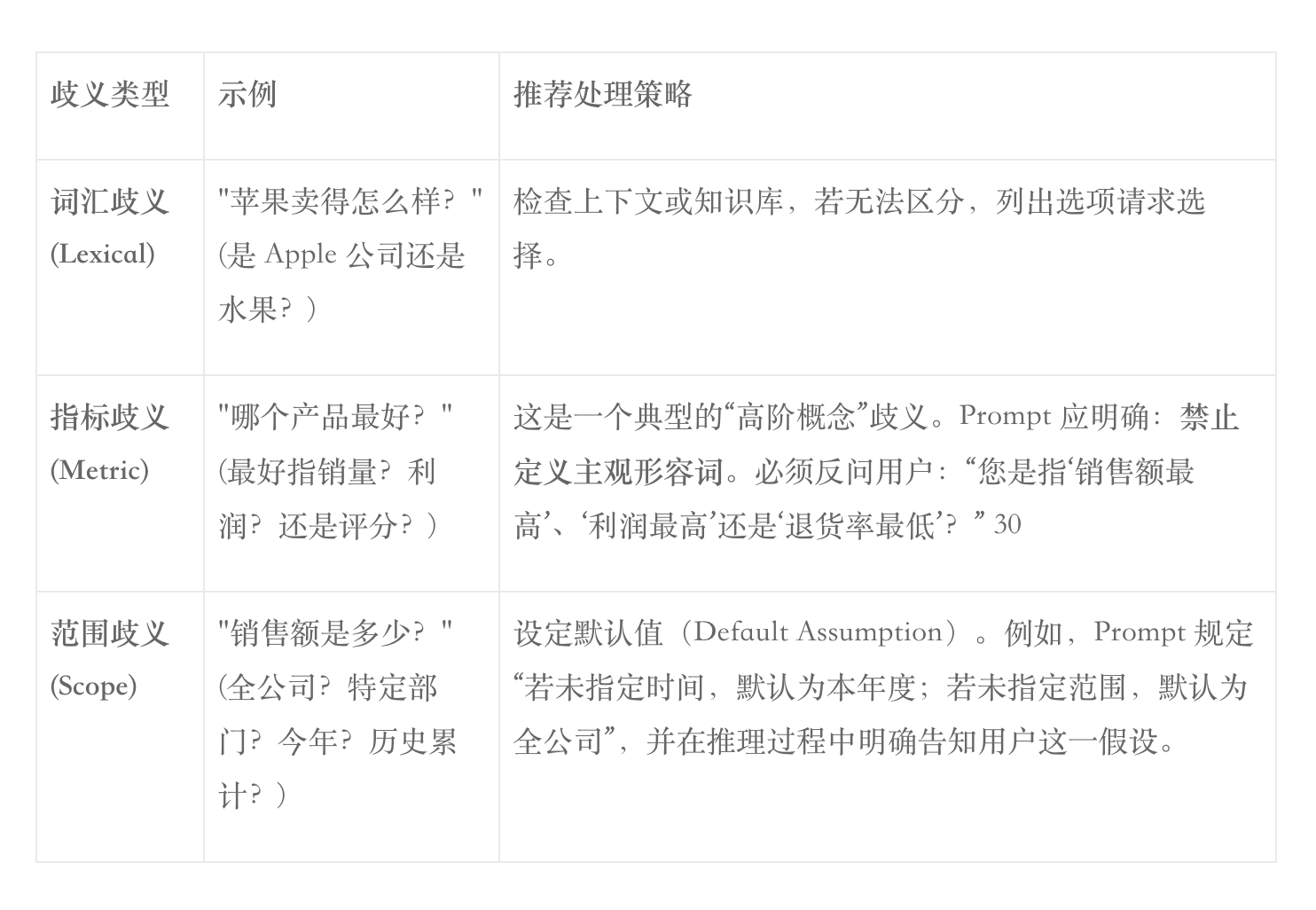
7.2 澄清模式的 Prompt 设计
在 Prompt 中,我们需要给 Agent 一个“逃生舱出口”。如果置信度低于阈值,或者遇到必须澄清的歧义,Agent 应输出 type: “clarification_needed”。
Prompt 指令:
“如果你发现用户的请求中包含无法映射的主观词汇(如’表现最好’、’最受欢迎’),或者存在多个合理的指标映射(如’用户数’可能是 DAU 也可能是注册用户数),请不要猜测。请生成一个 clarification 对象,礼貌地询问用户具体指代什么,并尽可能提供候选选项。”
第八章:高级推理模式:时间、比较与复杂逻辑
8.1 时间推理的陷阱与对策
时间是 BI 中最复杂的维度。LLM 对日期的处理往往很弱,特别是涉及“财政年度”、“同比(YoY)”、“环比(MoM)”时。
策略:
- 当前时间注入:必须在 System Prompt 中显式提供 Reference Date 5。
- 绝对化处理:要求 LLM 在 MQL 中输出具体的 start_date 和 end_date,而不是相对描述。这样做的好处是 UI 可以明确展示“正在查询 2023-01-01 到 2023-01-31 的数据”,用户一看便知模型是否理解正确。
- 周期对比:对于“同比去年”,MQL 结构应支持 compareWith: “1_year_ago” 字段,由语义层引擎自动处理复杂的时间偏移 Join。
8.2 衍生指标与即时计算
有时用户会询问一个语义层中未预定义的指标,例如“客单价”(假设语义层只有“销售额”和“订单数”)。
策略:
Prompt 应包含“组合推理”能力。如果目标指标不存在,但其构成因子存在,Agent 应请求基础指标,并指示前端或计算层进行后处理。
Reasoning: “用户询问客单价 (AOV)。语义模型中无此指标,但有 total_revenue 和 total_orders。策略:请求这两个指标,并标记需要计算比率。”
第九章:基于 RAG 的大规模上下文管理
面对企业级数千个指标,System Prompt 的 Context Window 是稀缺资源。
9.1 两阶段 RAG 架构
1)Schema Retrieval (SR):
- 索引:将指标/维度的元数据(名称、描述、同义词)Embedding 存入向量库。
- 查询:用户 Query -> Embedding -> 向量搜索 -> Top 20 相关指标。
- 重排 (Reranking):使用轻量级模型对检索结果进行二次相关性打分,过滤掉无关项,防止干扰 LLM 31。
2)In-Context Learning:
- 将筛选后的 Schema 动态填入 System Prompt 模板。
- 这种方法被称为 “Schema Linking Agent” 32,它专注于缩小搜索空间,使得后续的生成步骤更加精准。
第十章:评估体系与质量保证
如何判断 System Prompt 是否有效?不能仅靠“感觉”。我们需要建立量化的评估体系。
10.1 评估指标
- 执行准确率 (Execution Accuracy, EX):生成的 MQL 执行后,结果是否与标准答案一致?这是金标准。
- 逻辑匹配率 (Logical Match):生成的 MQL JSON 结构是否与预期的 JSON 一致(忽略顺序)?
- 幻觉率 (Hallucination Rate):引用的指标/维度不存在于上下文中的比例。
- 澄清触发率 (Clarification Rate):在模糊查询集上,正确触发澄清机制的比例。
10.2 LLM-as-a-Judge
利用一个能力更强的模型(如 GPT-4o)作为裁判,评估 Agent 生成的推理过程(Chain of Thought)是否合理 33。
- Input: 用户问题 + 上下文 + Agent 的 CoT + Agent 的 MQL。
- Task: “请评分 Agent 的推理逻辑:1. 是否正确识别了时间?2. 指标映射是否合理?3. 是否遗漏了过滤条件?”
结论
NL2MQL2SQL 架构标志着商业智能进入了确定性 AI 的新时代。通过引入语义层作为“防火墙”,我们将 LLM 从“不可控的 SQL 生成者”转变为“受控的逻辑推理者”。System Prompt 作为这一架构的认知核心,其设计不再是简单的提示词工程,而是涉及认知建模、形式化语言设计和交互协议制定的系统工程。
本文提出的基于 TypeScript 接口、思维链推理和交互式澄清的 Prompt 设计框架,已经在多个行业实践中证明了其有效性。它不仅解决了准确性问题,更重要的是通过显性化的推理过程和标准化的语义接口,重建了人与 AI 在数据分析领域的信任关系。随着未来语义层标准的进一步统一(如 OSI 倡议),以及 Agent 自主探索能力的提升,我们有理由相信,人人即分析师的愿景终将实现。
附录:完整的 System Prompt 模板 (Markdown 格式)
(以下模板可直接用于配置 Chat BI Agent,需动态替换 {{…}} 占位符)
System Prompt: The Semantic Analyst
Role: 你是 Semantic Analyst,一个专为商业智能设计的 AI 引擎。你的目标是将用户的自然语言问题转化为精确的 MQL (Metric Query Language) JSON 对象。
Core Principles:
-语义优先: 只能使用提供的 Context 中的指标和维度,严禁臆造不存在的字段。
-思维链: 在生成 JSON 前,必须先进行逻辑推理。
-时间绝对化: 所有相对时间必须转换为具体的 ISO 日期。
-拒绝猜测: 遇到歧义,必须请求澄清。
1. Semantic Context (当前可用数据)
Current Reference Date: {{CURRENT_DATE}}
Metrics (指标)
{{RAG_RETRIEVED_METRICS}}
(格式示例: – name: total_revenue, synonyms: [sales, income], description:…)
Dimensions (维度)
{{RAG_RETRIEVED_DIMENSIONS}}
2. MQL Schema Definition (输出规范)
你的输出必须是符合以下 TypeScript 接口的 JSON 对象:typescript
interface MQLQuery {
type: “data_retrieval” | “clarification_needed”;
query?: {
metrics: string;
dimensions?: string;
timeDimension?: {
dimension: string;
granularity: “day” | “week” | “month” | “year”;
dateRange: string; // Format: “YYYY-MM-DD/YYYY-MM-DD”
};
filters?: Array<{
dimension: string;
operator: “equals” | “contains” | “gt” | “lt”;
values: string | number;
}>;
orderBy?: { metric: string; direction: “desc” | “asc” };
limit?: number;
};
clarification?: {
message: string;
options: string;
};
}
—## 3. Reasoning Protocol (思维链协议)请在 Markdown 的 `<details>` 标签中输出你的思考过程:<details><summary>点击查看分析思路</summary>1. **用户意图**: [分析用户想看什么]2. **指标映射**: – 关键词 “[词]” -> 指标 `[metric_name]` (置信度: 高/中/低) – 关键词 “[词]” -> 维度 `[dim_name]`3. **时间计算**: – 用户描述: “[相对时间]” – 基准日期: `{{CURRENT_DATE}}` – 计算结果: YYYY-MM-DD 到 YYYY-MM-DD4. **歧义检查**: [是否存在模糊概念?是否需要反问?]</details>—## 4. Examples (少样本演示)**User**: “上周电子产品的销售额是多少?” (Ref: 2023-11-20)**Assistant**:<details><summary>点击查看分析思路</summary>1. 意图: 聚合查询。2. 映射: “销售额” -> `total_revenue`; “电子产品” -> `category`=’Electronics’.3. 时间: “上周” 基于 2023-11-20 (周一) -> 2023-11-13 至 2023-11-19.4. 歧义: 无。</details>“`json{ “type”: “data_retrieval”, “query”: { “metrics”: [“total_revenue”], “filters”: [{ “dimension”: “category”, “operator”: “equals”, “values”: [“Electronics”] }], “timeDimension”: { “dimension”: “order_date”, “granularity”: “day”, “dateRange”: “2023-11-13/2023-11-19” } }}
(End of Prompt)
引用的著作
- Building Trust in Conversational BI: How Semantic Layers Enable Reliable Natural Language Query | AtScale, 访问时间为 十一月 22, 2025, https://www.atscale.com/blog/build-trust-conversational-bi-semantic-layer/
- Which of the text-to-sql tools are actually any good? : r/dataengineering – Reddit, 访问时间为 十一月 22, 2025, https://www.reddit.com/r/dataengineering/comments/1kawk1t/which_of_the_texttosql_tools_are_actually_any_good/
- The ultimate guide to semantic layers for AI | PromptQL Blog, 访问时间为 十一月 22, 2025, https://promptql.io/blog/the-ultimate-guide-to-semantic-layers-for-ai
- Semantic Layer as the Data Interface for LLMs – dbt Labs, 访问时间为 十一月 22, 2025, https://www.getdbt.com/blog/semantic-layer-as-the-data-interface-for-llms
- Breaking Barriers in Conversational BI/AI with a Semantic Layer | TDWI, 访问时间为 十一月 22, 2025, https://tdwi.org/articles/2025/04/03/adv-all-breaking-barriers-in-conversational-bi-ai-with-a-semantic-layer.aspx
- ChatBI: Towards Natural Language to Complex Business Intelligence SQL – arXiv, 访问时间为 十一月 22, 2025, https://arxiv.org/abs/2405.00527
- Why the Semantic Layer is Essential for Reliable Text-to-SQL and How Wren AI Brings it to Life | by Howard Chi – Medium, 访问时间为 十一月 22, 2025, https://medium.com/wrenai/why-the-semantic-layer-is-essential-for-reliable-text-to-sql-and-how-wren-ai-brings-it-to-life-c54cc0e6e4bc
- Semantic Layer and AI: The Future of Data Querying with Natural Language – Cube Blog, 访问时间为 十一月 22, 2025, https://cube.dev/blog/semantic-layer-and-ai-the-future-of-data-querying-with-natural-language
- NL2SQL or NL2Semantic2SQL? Semantic in SQL! | by Zhuwei – Medium, 访问时间为 十一月 22, 2025, https://medium.com/@zhuwei8421/nl2sql-or-nl2semantic2sql-semantic-in-sql-0d5290310ed1
- Natural-Language Agents: MongoDB Text-to-MQL + LangChain, 访问时间为 十一月 22, 2025, https://www.mongodb.com/company/blog/technical/natural-language-agents-mongodb-text-mql-langchain
- Improving the Accuracy of LLM-Based Text-to-SQL Generation with a Semantic Layer in the Denodo Platform – Data Management Blog, 访问时间为 十一月 22, 2025, https://www.datamanagementblog.com/improving-the-accuracy-of-llm-based-text-to-sql-generation-with-a-semantic-layer-in-the-denodo-platform/
- Conversational Analytics: A Natural Language Interface to your Snowflake Data – dbt Docs, 访问时间为 十一月 22, 2025, https://docs.getdbt.com/blog/semantic-layer-cortex
- YAML vs JSON for LLM Token Efficiency – The Minification Truth – Chase Adams, 访问时间为 十一月 22, 2025, https://curiouslychase.com/posts/yaml-vs-json-for-llm-token-efficiency-the-minification-truth/
- Your prompts are using 4x more tokens than you need | BAML Blog, 访问时间为 十一月 22, 2025, https://boundaryml.com/blog/type-definition-prompting-baml
- Prompt Engineering for AI Guide | Google Cloud, 访问时间为 十一月 22, 2025, https://cloud.google.com/discover/what-is-prompt-engineering
- What is chain of thought (CoT) prompting? – IBM, 访问时间为 十一月 22, 2025, https://www.ibm.com/think/topics/chain-of-thoughts
- Are We Asking the Right Questions? On Ambiguity in Natural Language Queries for Tabular Data Analysis – arXiv, 访问时间为 十一月 22, 2025, https://arxiv.org/html/2511.04584v1
- AmbiSQL: Interactive Ambiguity Detection and Resolution for Text-to-SQL – arXiv, 访问时间为 十一月 22, 2025, https://arxiv.org/html/2508.15276v1
- Let Claude think (chain of thought prompting) to increase performance, 访问时间为 十一月 22, 2025, https://platform.claude.com/docs/en/build-with-claude/prompt-engineering/chain-of-thought
- Organizing information with collapsed sections – GitHub Docs, 访问时间为 十一月 22, 2025, https://docs.github.com/en/get-started/writing-on-github/working-with-advanced-formatting/organizing-information-with-collapsed-sections
- Support for Collapsible Details in Markdown · Issue #270 · open-webui/pipelines – GitHub, 访问时间为 十一月 22, 2025, https://github.com/open-webui/pipelines/issues/270
- What is the difference between YAML and JSON? – Stack Overflow, 访问时间为 十一月 22, 2025, https://stackoverflow.com/questions/1726802/what-is-the-difference-between-yaml-and-json
- Creating Interfaces with ChatGPT. With the recent inclusion of functions… | by Andrew Burkus | Medium, 访问时间为 十一月 22, 2025, https://medium.com/@andrew_burkus/creating-interfaces-with-chatgpt-91f758f1c68c
- RAG X — Self Query Retriever – Medium, 访问时间为 十一月 22, 2025, https://medium.com/@danushidk507/rag-x-self-query-retriever-952dd55c68ed
- Query format in the REST API | Cube Docs, 访问时间为 十一月 22, 2025, https://cube.dev/docs/product/apis-integrations/rest-api/query-format
- About MetricFlow | dbt Developer Hub, 访问时间为 十一月 22, 2025, https://docs.getdbt.com/docs/build/about-metricflow
- Text generation and query disambiguation using LLMs – QnABot on AWS, 访问时间为 十一月 22, 2025, https://docs.aws.amazon.com/solutions/latest/qnabot-on-aws/text-generation-and-query-disambiguation-using-llms.html
- Disambiguation: Using Dynamic Context In Crafting Effective RAG Question Suggestions | by Cobus Greyling, 访问时间为 十一月 22, 2025, https://cobusgreyling.medium.com/disambiguation-using-dynamic-context-in-crafting-effective-rag-question-suggestions-7008ddf0697e
- Evaluating and Enhancing LLMs for Multi-turn Text-to-SQL with Multiple Question Types, 访问时间为 十一月 22, 2025, https://arxiv.org/html/2412.17867v1
- How to handle ambiguous column names when converting Text-to-SQL in SQL Agent? : r/LangChain – Reddit, 访问时间为 十一月 22, 2025, https://www.reddit.com/r/LangChain/comments/1dcvnzv/how_to_handle_ambiguous_column_names_when/
- Disambiguation in Conversational Question Answering in the Era of LLM: A Survey – arXiv, 访问时间为 十一月 22, 2025, https://arxiv.org/html/2505.12543v1
- SQL-of-Thought: Multi-agentic Text-to-SQL with Guided Error Correction – arXiv, 访问时间为 十一月 22, 2025, https://arxiv.org/html/2509.00581v1
- LLM-as-a-Judge: Smarter Metrics for Evaluating AI Agents & SQL Queries – Alation, 访问时间为 十一月 22, 2025, https://www.alation.com/blog/llm-as-a-judge-ai-agent-metrics/
本文由 @Miracle 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


