
 起点课堂会员权益
起点课堂会员权益DeepSeek:当大模型学会“慢思考”,人类的护城河还剩多少?
DeepSeekMath-V2在北美最难的Putnam数学竞赛中拿到118分,其独特的Generator + Verifier + Meta-Verifier架构及多项创新算法令人瞩目。本文从产品和商业逻辑维度深入剖析其底层逻辑及给产品经理的启示。

在刚刚过去的这个周末,AI 圈被一份技术报告引起了我的注意。
不是 OpenAI 的 GPT-5.1不是 Google 的 Gemini 3.0,而是来自国内团队 DeepSeek(深度求索)的 DeepSeekMath-V2。
为什么这份报告值得每一个关注 AI 应用层的人细读?
因为在很长一段时间里,我们对大模型的产品定义都停留在“生成器”上——你问它答,语速极快,但经常幻觉。
我们习惯了用 RAG(检索增强)去给模型打补丁,却忽略了模型本身推理能力的缺陷。
DeepSeekMath-V2 的出现,实际上是捅破了一层窗户纸:如果让 AI 在回答之前,先像人类一样在草稿纸上反复推演、自我纠错,结果会怎样?
结果是:它在北美最难的 Putnam 数学竞赛中拿到了 118 分(满分 120),在这一垂类场景下,它不仅接近,也让此前所有的通用大模型黯然失色。
今天,我们就跳出纯技术视角,从产品和商业逻辑的维度,来拆解DeepSeekMath-V2。的底层逻辑。
做过 AI 产品的同学都知道一个痛点:Reward Hacking(奖励黑客)。
传统的强化学习训练就像教小孩做数学题,我们只看最后答案对不对。
如果答案对了,就给奖励。
这就导致了一个滑稽的现象:模型可能中间步骤全错,甚至编造了不存在的定理,但恰好符号抵消碰对了答案。
在产品落地时,这表现为“逻辑不严密,看似有理,实则胡扯”。
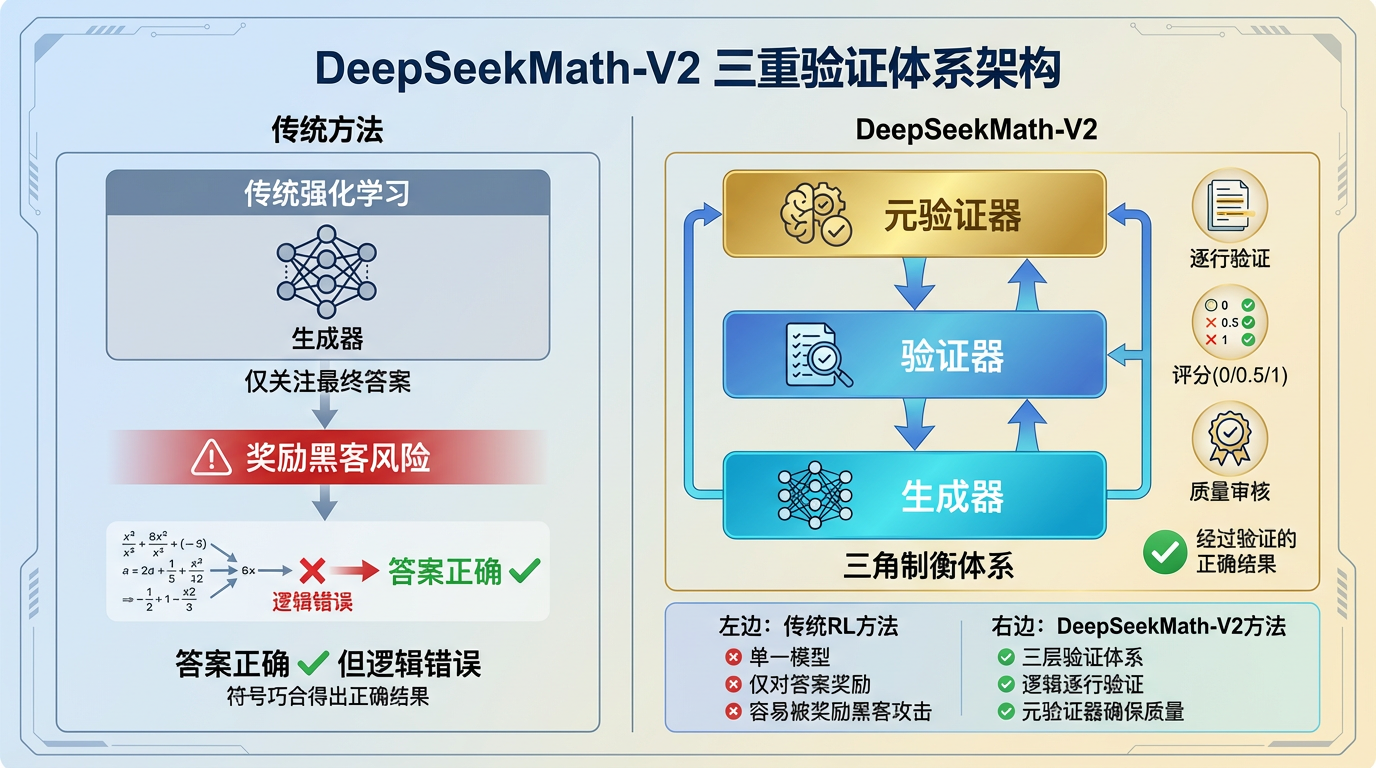
DeepSeekMath-V2 做了一个极具胆识的范式转移:验证器优先(Verifier-First)。
它的核心假设非常符合人类认知规律——鉴赏力往往先于创造力。一个学生可能暂时解不出压轴题,但他一定能看懂老师的解题步骤哪里错了。
三角制衡体系
DeepSeekMath-V2 不再是一个单一的“生成模型”,它构建了一个类似公司内部的“制衡体系”:
- Generator(生成器): 负责输出解题思路,也就是那个干活的员工。
- Verifier(验证器): 负责挑刺,逐行扫描逻辑漏洞,打分(0/0.5/1),这是严苛的质检员。
- Meta-Verifier(元验证器): 这是 DeepSeek 的神来之笔。它负责监管验证器,防止验证器“外行指导内行”或出现幻觉。
这种Generator + Verifier + Meta-Verifier 的架构,本质上是在模拟人类数学家“大胆假设,小心求证”的思维闭环。
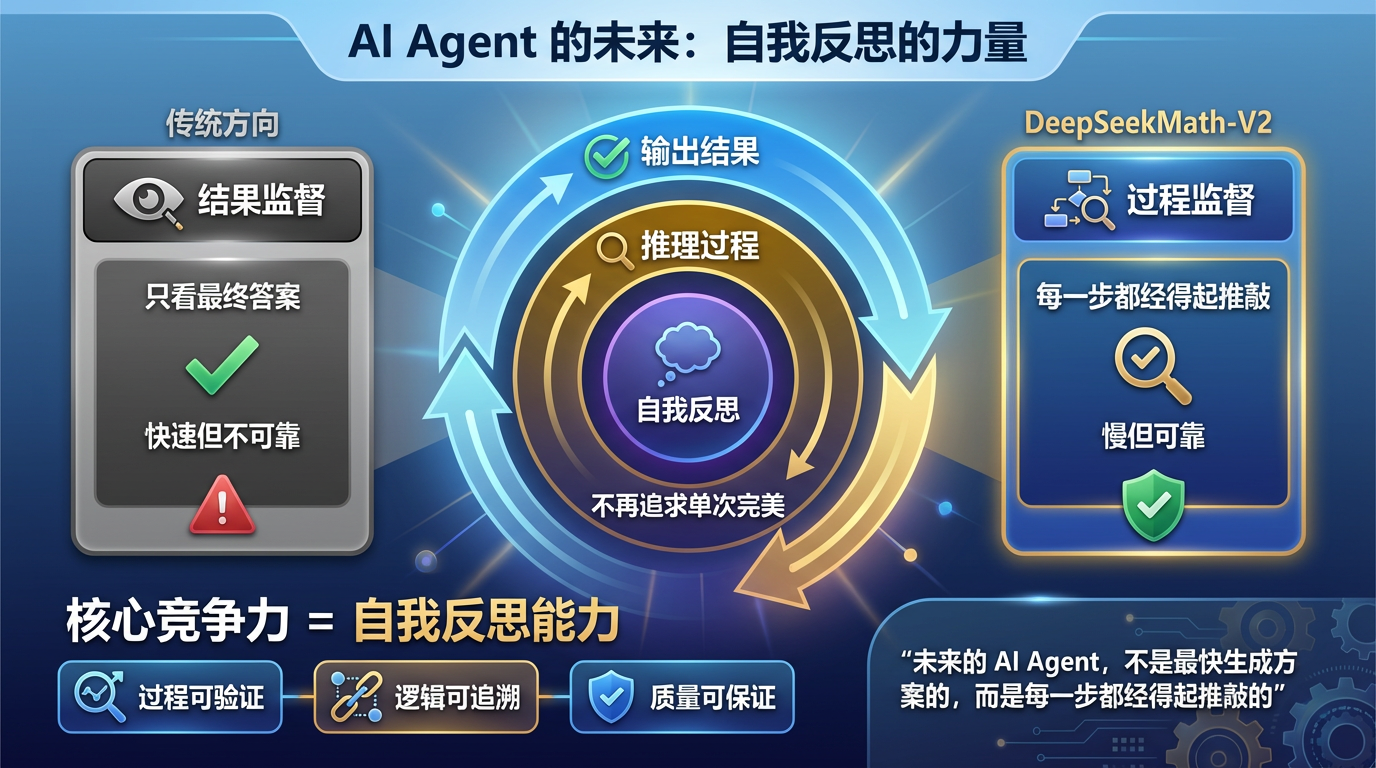
这给产品经理的启示是什么?未来的 AI Agent,核心竞争力可能不在于它能多快生成方案,而在于它是否具备**自我反思(Self-Reflection)**的能力。
DeepSeekMath-V2 证明了,通过自然语言进行的“过程监督”,比单纯的“结果监督”更有效。它不再追求单次生成的完美,而是追求在推理链条上的每一步都经得起推敲。
作为商业产品,抛开成本谈性能都是耍流氓。DeepSeekMath-V2 是基于 685B(6850 亿)参数的底座训练的,听到这个数字,很多人的第一反应是:这推理成本得是个天价吧?
DeepSeek 在这里祭出了两把“手术刀”,精准切掉了大模型的高昂成本。
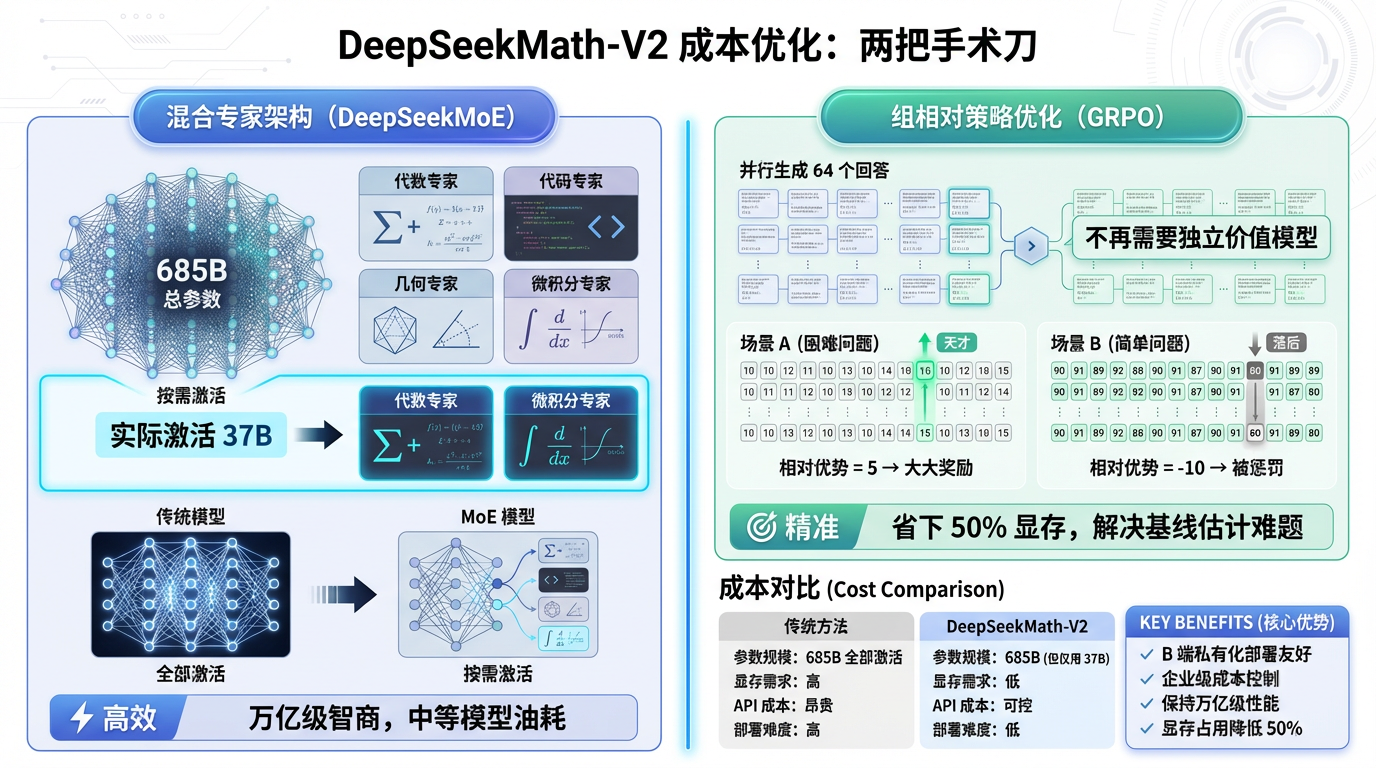
虽然参数总量高达 685B,但它采用的是 DeepSeekMoE(混合专家) 架构。
简单来说,就是把大模型拆成了无数个细分的“专家”。遇到代数题,喊代数专家;遇到编程题,喊代码专家。每次推理,实际被激活干活的参数只有 370 亿(37B) 左右。
这意味着什么?意味着它拥有万亿级模型的“智商”储备,但在运行时,只消耗了中等模型的“算力”油耗。这对于 B 端私有化部署或 API 成本控制来说,是决定性的优势。
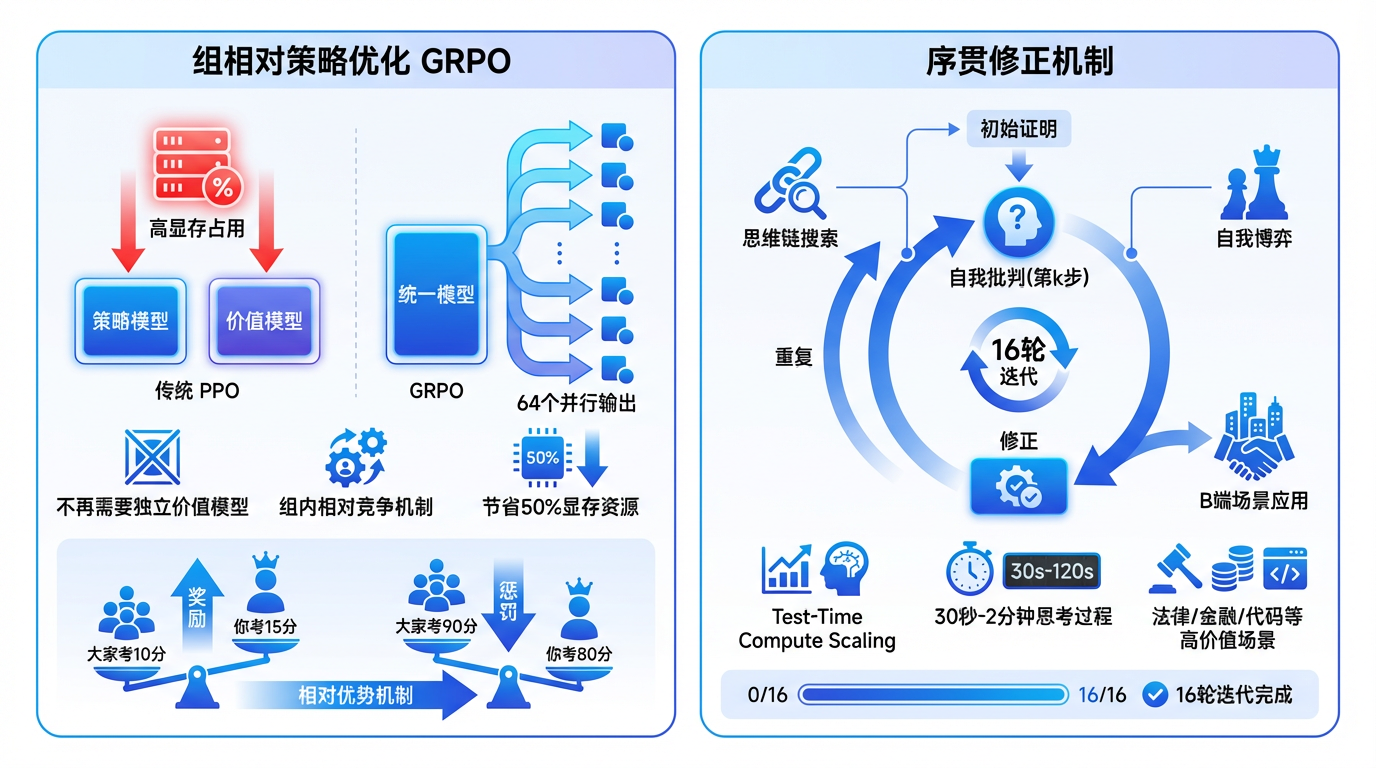
这是本次报告中最硬核的算法创新——组相对策略优化(GRPO)。
在传统的 PPO(近端策略优化)算法中,我们需要在显存里同时养一个“策略模型”和一个“价值模型”(Critic)。对于 600B+ 的巨兽来说,显存根本塞不下。
GRPO 做了一个极其聪明的改动:它不再需要那个独立的价值模型了。
它的逻辑是:全靠同行衬托。 针对一个问题,模型并行生成一组回答(比如 64 个)。GRPO 不去评估每个回答的绝对分数,而是计算它们相对于这组回答平均水平的“优势”。
- 如果题目很难,大家都考 10 分,你考 15 分,那你就是天才,大大奖励。
- 如果题目很简单,大家都考 90 分,你考 80 分,那你就要被惩罚。
这种组内相对竞争的机制,不仅省下了一半的显存资源,还天然解决了题目难度不一导致的基线估计难题。
DeepSeekMath-V2 的报告中反复提到了一个词:序贯修正(Sequential Refinement)。
这其实揭示了下一代 AI 产品的核心交互形态。
在过去,用户习惯的是 ChatGPT 式的“秒回”。但 DeepSeekMath-V2 告诉我们,对于复杂的逻辑任务,慢就是快。
在推理阶段,模型会生成初始证明,然后自己扮演验证器进行“自我批判”,指出第 k 步的逻辑跳跃,然后重新修正,如此循环往复,甚至可以迭代 16 轮。
这被称为 Test-Time Compute Scaling(测试时计算扩展)。
产品启示: 我们未来的界面设计,可能不再是一个简单的“正在输入”光标。对于高价值的 B 端场景(如法律文书撰写、金融研报分析、复杂代码重构),用户愿意等待 30 秒甚至 2 分钟。
在这段时间里,后台的模型正在进行海量的“思维链”搜索和自我博弈。产品经理需要思考的是,如何可视化这个“思考过程”,让用户感知到这种深思熟虑的价值。
为什么 DeepSeek 能在数学这个垂类上打败 Google 和 OpenAI?
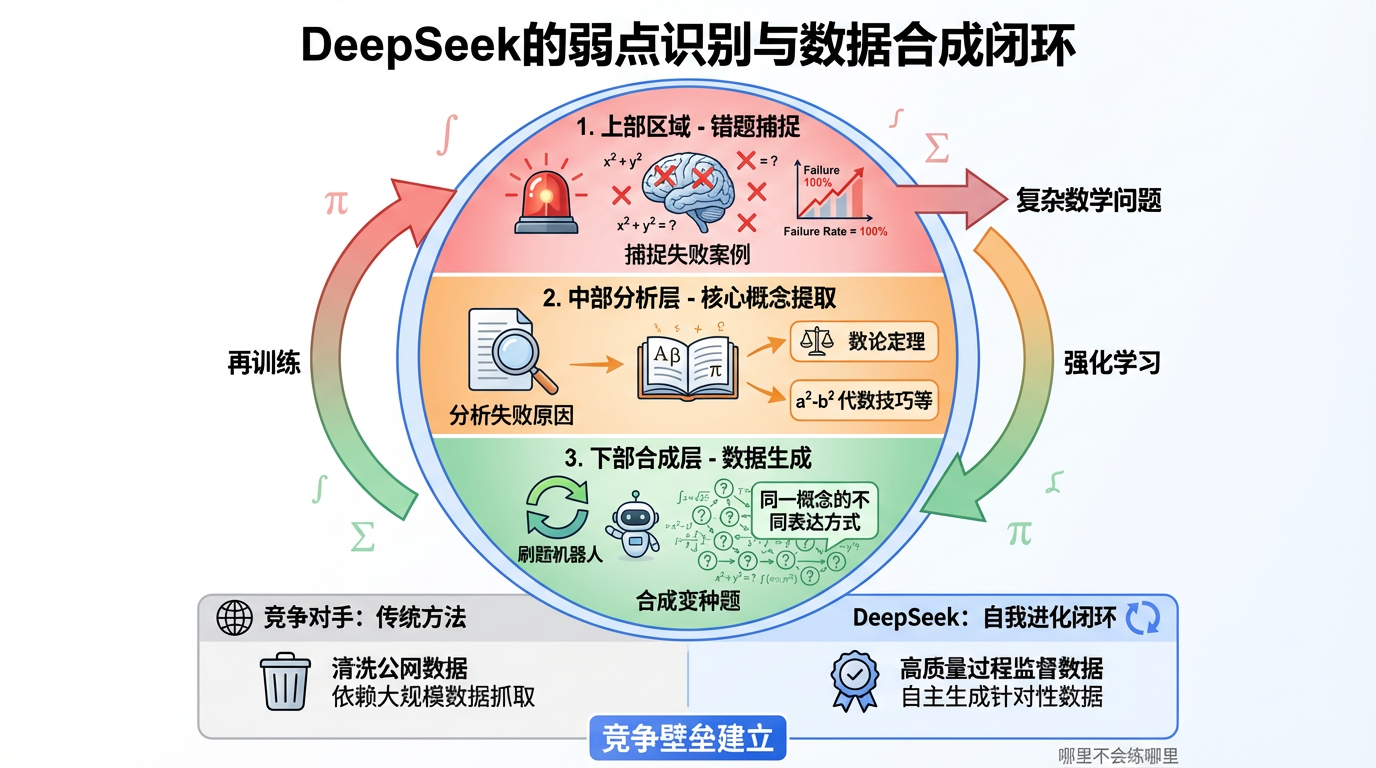
除了算法,更可怕的是它的弱点识别与数据合成闭环。
DeepSeekMath-V2 在训练过程中,建立了一个自动化的“错题本”机制。系统会捕捉那些模型反复尝试都无法解决的问题(Failure Rate = 100%)。
然后,它不是简单地丢弃,而是分析这些失败案例,提取其中的核心数学概念(比如某个特定的数论定理),然后利用合成数据技术,针对性地造出成千上万道类似的变种题,再喂给模型吃。
这就像是一个不知疲倦的刷题机器人,哪里不会练哪里。
这构成了极高的竞争壁垒: 当竞争对手还在清洗公网数据(Common Crawl)的时候,DeepSeek 已经通过“自研算法 + 合成数据”建立了一个自我进化的闭环。这种基于高质量过程监督数据的壁垒,远比单纯堆砌 GPU 数量要稳固得多。
当然,作为第三方观察者,我们也要清醒地看到 DeepSeekMath-V2 的局限性。
推理成本的隐忧: 虽然 MoE 降低了激活参数,但“序贯修正”为了求准,生成了数千个候选证明。在商业化落地时,这种“大力出奇迹”的模式能否覆盖 Token 成本?这需要打一个问号。
验证器的天花板: 目前模型表现好,是因为数学题(尤其是竞赛题)相对容易验证。但在开放性的商业决策、创意写作领域,如何定义“验证器”?这是一个巨大的挑战。
未来的产品猜想:
1. Co-Pilot 进阶为 Co-Scientist, DeepSeekMath-V2 展示了 AI 辅助科研的可能性。它不仅是写代码,而是能辅助推导公式、验证猜想。
2. 教育硬件的降维打击。 想象一下,把这个模型蒸馏后塞进学习机里。它不是给你搜题,而是像老师一样,一步步看你的解题过程,告诉你“第三行公式用错了”,而不是直接丢给你答案。这才是真正的 AI 教育。
最后,谈谈我的一些小想法
DeepSeekMath-V2 的发布,给喧嚣的 AI 行业泼了一盆冷水,也点了一盏灯。
它告诉我们,通用大模型的红利期可能正在消退,垂类深度推理(Deep Reasoning)或许是下一个高地。
对于我们而言,与其焦虑于 AI 会不会取代自己,不如思考如何利用这种具备“慢思考”能力的工具,去重构我们现有的业务流程。
毕竟,一个能考 118 分的数学天才已经诞生了,未来还会出现更多颠覆我们想象的填错出现。
你准备好了hc,给他们安排什么“工作”了么?
以上,感谢各位大哥赏脸看到这里!
如果觉得不错,随手点赞支持一下吧,我们,下次再见。
本文由 @虾灰鱼 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


