
 起点课堂会员权益
起点课堂会员权益我搭了一个智能体,用第一性原理帮你挖掘行为背后的真相!
深度思考不再是少数人的专利!这款名为"第一性:真相挖掘Agent"的创新智能体,通过AI驱动的自我追问循环,将马斯克推崇的第一性原理思维变得触手可及。它能自动完成四层递进式挖掘——从现象拆解到关联断裂,从公理化到重构验证,帮你穿透表象直达问题本质。本文将揭秘这款融合工作流架构与LLM能力的智能体,如何通过可视化过程呈现系统性思维,并为每个问题生成可执行的行动方案。
想了解马斯克如果遇到你的问题,会如何思考?
不是简单的类比和表面分析,而是从最根本的原理出发,层层追问,直到找到问题的本质。这就是第一性原理思考——很多顶尖思考者的核心能力,但门槛很高。
这就是我最近搭建的智能体:”第一性:真相挖掘Agent”。
这篇文章分享一下这个智能体的搭建过程,既有技术实现细节,也有产品设计思考,帮助大家了解如何用工作流架构和LLM能力,打造一个能够自动层层追问、挖掘第一性原理的智能体。
智能体的体验链接在文章最后。

为什么做这个?
1. 痛点:治标不治本的困境
我们生活中经常遇到这样的困惑:明明知道问题在哪,却总是找不到根本原因。孩子沉迷游戏,表面是”不听话”,背后可能是成就感缺失、社交需求未被满足。我们习惯性地只问一层”为什么”,却很少继续追问”为什么会有这个原因”。
所以我做了这个智能体:通过AI自动层层追问,用第一性原理的思维方式,帮你从现象到本质,找到行为背后的底层逻辑。
2. 产品出发点:让深度思考变得简单
第一性原理思考是很多顶尖思考者的核心能力,但门槛很高:需要持续追问、需要系统性思维、需要方法论指导。我想做的是:用AI能力降低第一性原理思考的门槛,让每个人都能轻松体验深度思考的乐趣,同时保持思考的深度和系统性。
核心价值:
- 自动层层追问:AI自己主动层层下钻,自己追问自己,直到找到第一性原理
- 可视化过程:实时展示每一层的挖掘结果,让用户看到思考的过程
- 系统性思维:从现象拆解、关联断裂、公理化到重构验证,完整的四层下探方法论
- 可执行方案:基于第一性原理,给出具体可执行的行动建议
3. 核心差异:AI自我追问循环
这个智能体的核心差异在于:不是“用户问,AI答”的单次交互,而是“AI自己主动层层下钻,自己追问自己,自己挖掘真相”。
传统AI问答:
用户:为什么孩子沉迷游戏?
AI:可能是因为游戏有趣、缺乏监督等原因。
真相挖掘Agent:
用户:为什么孩子沉迷游戏?
AI(第1层):现象拆解
– 孩子沉迷游戏的表现是什么?
AI(第2层):关联断裂
– 为什么游戏能提供这些体验?
AI(第3层):公理化
– 人的核心需求是什么?
AI(第4层):重构验证
– 从核心需求出发,如何解决这个问题?
这是一个”自我追问”的过程,而不是”用户被追问”。AI会自动完成整个挖掘过程,用户只需要看到结果。
定位&整体交互
产品定位
目标用户:想要深度理解问题本质的人、对第一性原理思考感兴趣的人、想要提升系统性思维能力的人、遇到复杂问题需要系统性分析的人
核心价值:通过AI自动层层追问,用第一性原理的思维方式,帮你从现象到本质,找到行为背后的底层逻辑,并给出可执行的行动方案
整体交互设计
交互流程非常简单直观:

工作流架构设计
整个智能体基于工作流架构搭建,分为两个核心模块:
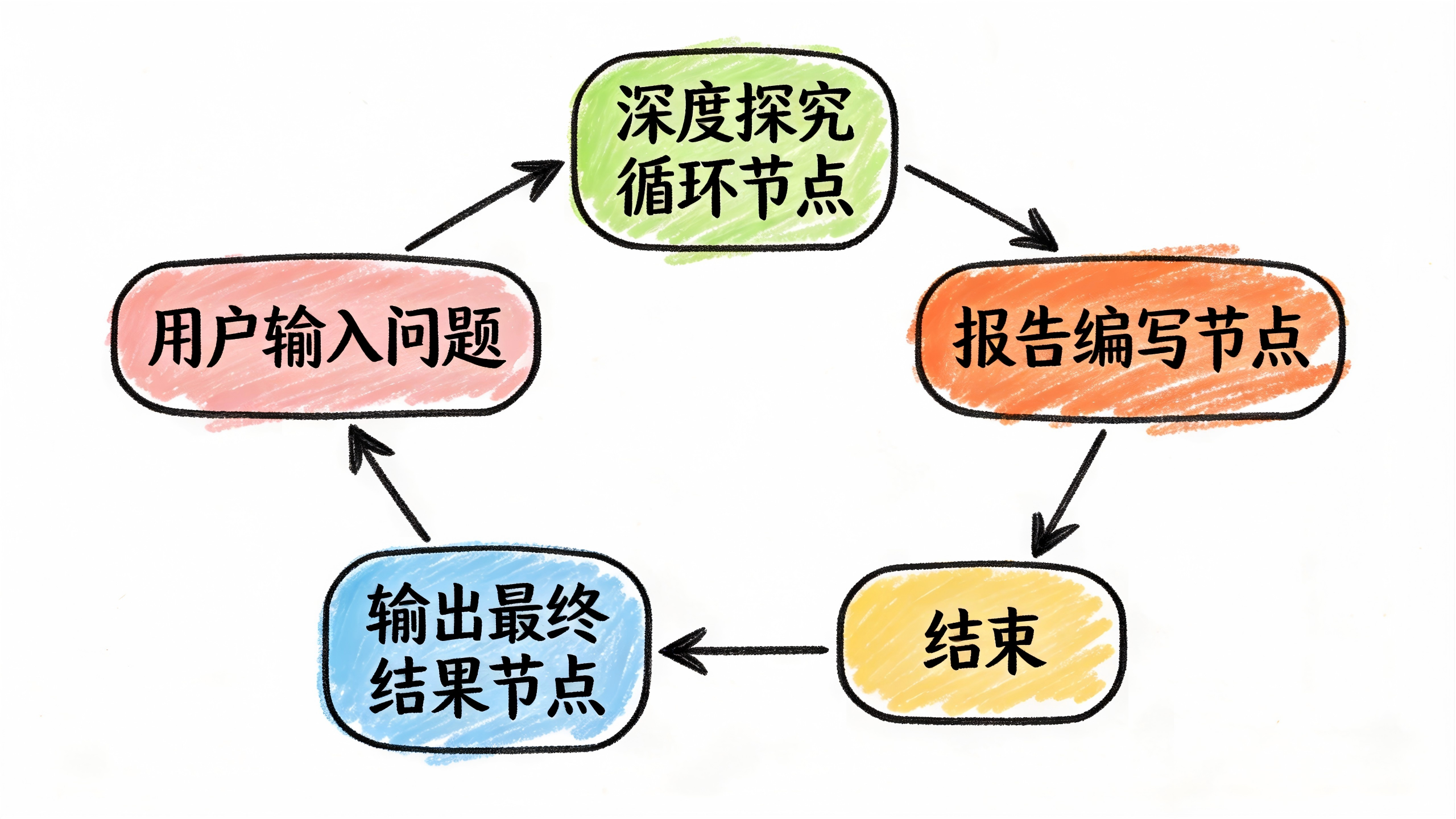
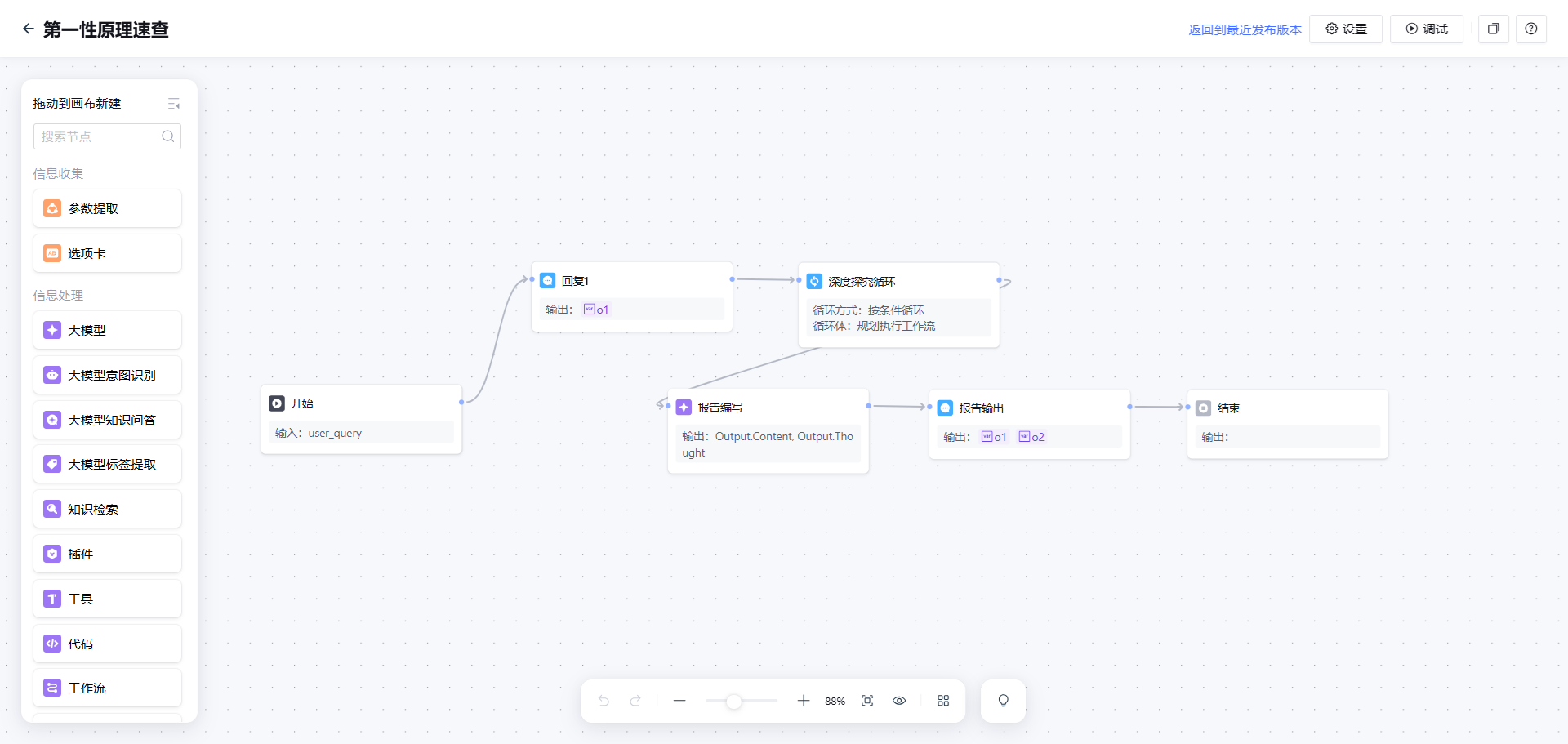
工作流1:主工作流(入口与报告生成)
输入:用户问题(如”为什么孩子一回家就打游戏?”)
处理流程:
- 开始节点:接收用户问题
- 深度探究循环节点:循环调用子工作流,完成四层下探
- 报告编写节点(LLM):基于完整的探究历史,生成Markdown格式的探究报告
- 输出最终结果节点:展示报告给用户
流程非常简单,一路走到底型:
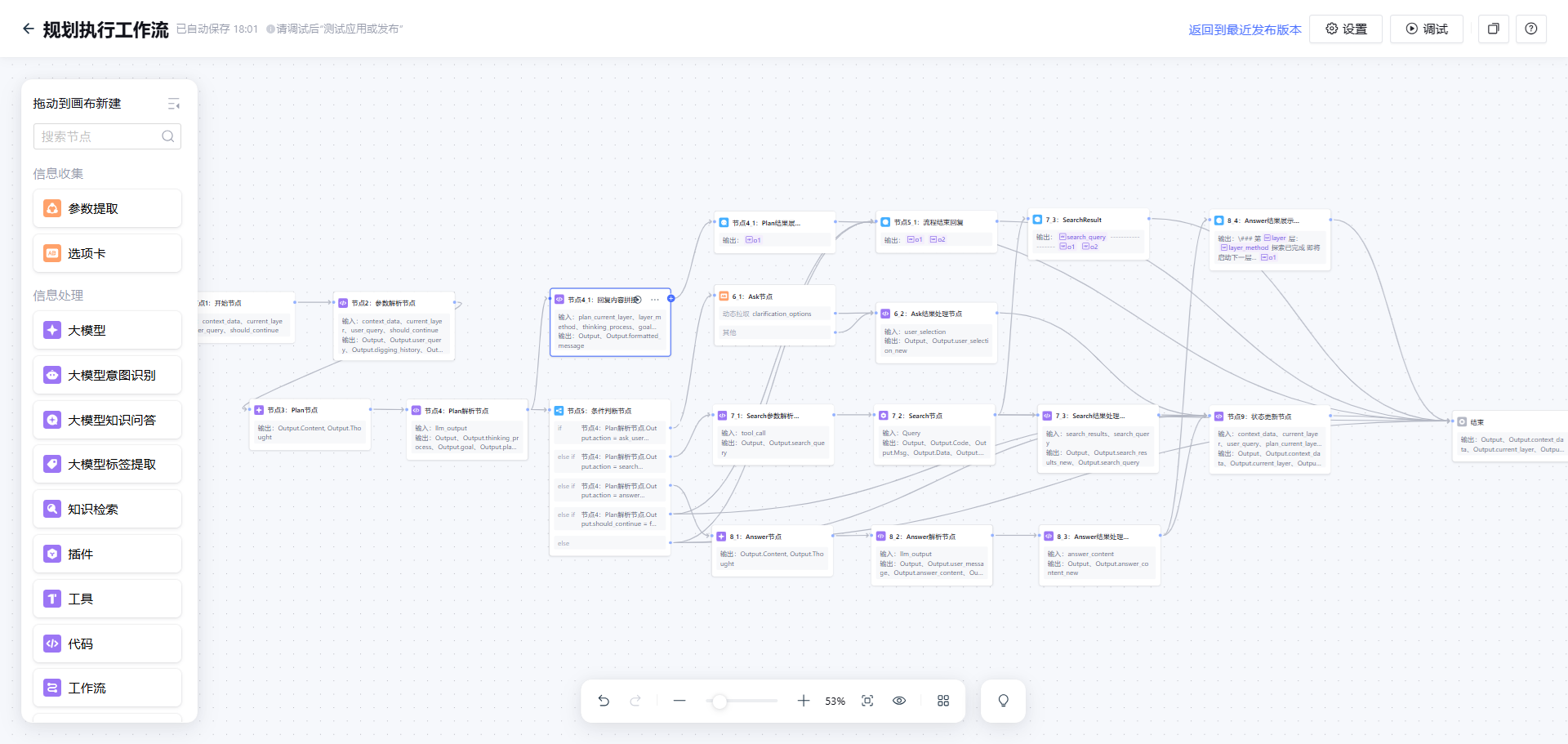
工作流2:深度探究循环体(子工作流,核心挖掘模块)
输入:循环变量(context_data、current_layer、user_query、should_continue)
这是整个体验的核心,通过循环节点调用这个子工作流,最多循环4次(对应4层下探)。
子工作流的处理逻辑:
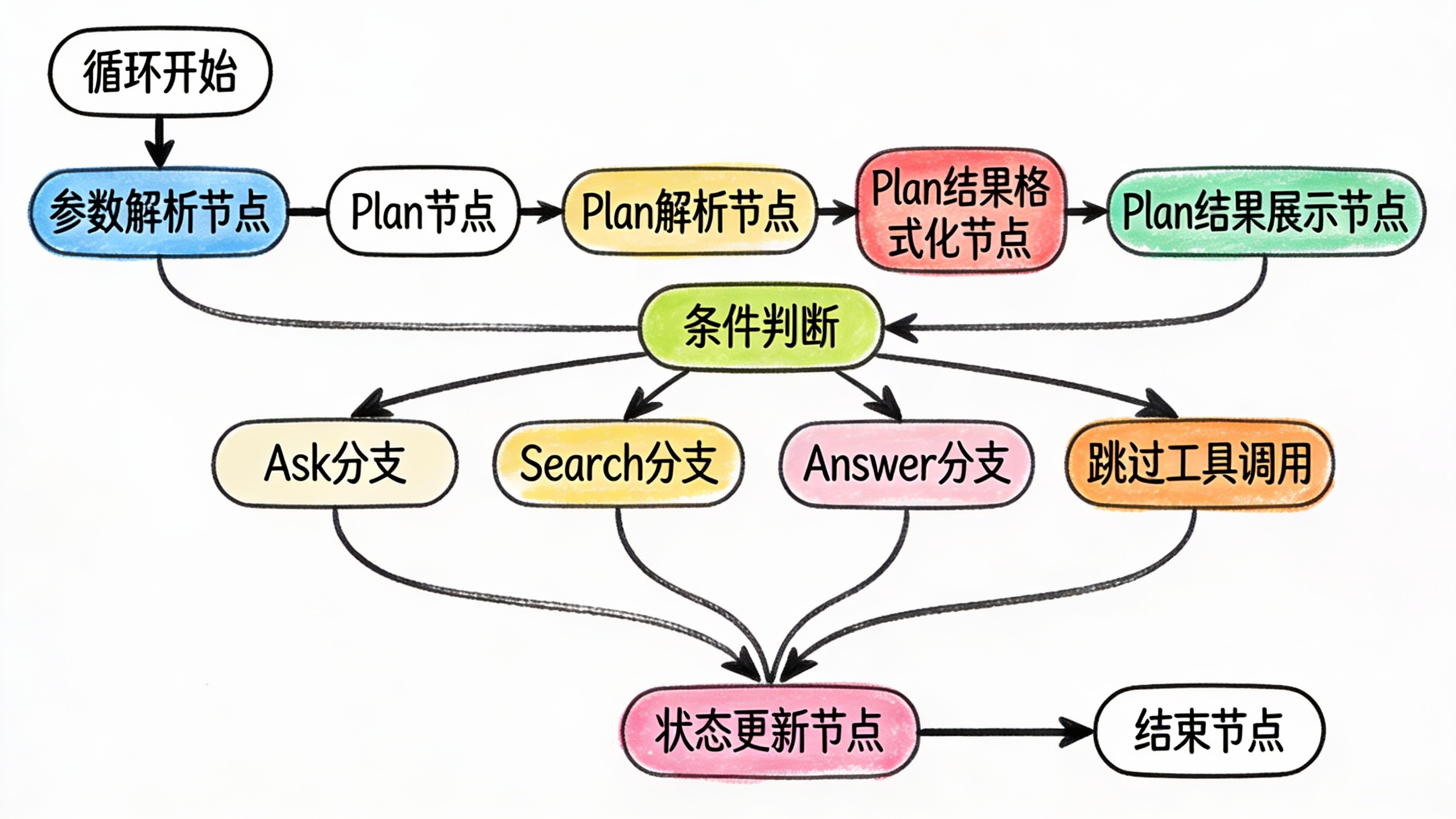
关键技术点:
1. 状态管理:状态完全在循环体内管理
- 第一次循环时,初始化状态(current_layer=1,context_data={“digging_history”: []})
- 每次循环结束后,状态在状态更新节点中更新
- 更新后的状态通过输出变量传递给下一个循环
- 循环结束后,最终状态传递给报告编写节点
2. 四层下探方法论:
- 第1层:现象拆解 将复杂问题/现象拆解为基本要素
- 第2层:关联断裂 切断传统认知的类比链条,追溯起源
- 第3层:公理化 识别第一性原理(不可删除、不可违背、不可推导)
- 第4层:重构验证 从第一性原理向上推演,验证结论
3. Plan节点的智能规划:
- Plan节点负责规划下一步行动(ask_user、search、answer、null)
- 第一次循环时,必须询问用户澄清(action: “ask_user”)
- 根据当前层级和上下文,决定是否需要搜索资料
- 当具备足够上下文时,调用Answer节点回答问题
4. 工具调用的灵活性:
- 每次循环最多调用一个工具(ask_user、search、answer)
- 工具调用由Plan节点决定,不是固定的流程
- 支持在任意层级进行搜索,获取相关资料
技术实现细节
接下来逐个功能点拆分。
1. 循环节点的状态传递
循环节点的设计,本质上是让你用工作流构造一个”工具插件”,循环调用、处理每一层下探。
关键设计:状态完全在循环体内管理,不依赖循环体外的全局变量。
状态管理方式:
- 第一次循环时,在循环开始节点初始化状态(current_layer=1,context_data={“digging_history”: []},should_continue=“true”)
- 每次循环结束后,状态在状态更新节点中更新
- 更新后的状态通过输出变量(context_data、current_layer、should_continue)传递给下一个循环
- 循环结束后,最终状态会传递给报告编写节点
循环变量的设计:
由于平台限制,循环过程变量必须作为工作流输出参数传递。因此,我们设计了4个循环变量:
1.context_data:所有上下文信息(对象,序列化为JSON字符串)
- 包含digging_history数组,记录每一层的挖掘结果
- 每次循环都会append新记录,而不是覆盖
2.current_layer:当前挖掘层级(数字,int类型)
- 1 → 现象拆解
- 2 → 关联断裂
- 3 → 公理化
- 4 → 重构验证
3. user_query:用户原始问题(字符串)
4. should_continue:是否继续循环(字符串,”true”或”false”)
- 由Plan节点决定
- 当第4层完成Answer后,Plan节点会设置should_continue: false
2. Plan节点的智能规划
Plan节点是整个循环的核心,负责规划下一步行动。
Plan节点的职责:
- 分析当前层级和上下文
- 规划下一步行动(ask_user、search、answer、null)
- 输出current_question,指导Answer节点回答问题
- 判断是否继续循环(should_continue)
关键设计点:
1. 第一次循环必须询问用户澄清:
- 当current_layer === 1且digging_history为空时,必须设置action: “ask_user”
- 提供2-4个澄清选项,每个选项是用户第一人称的陈述(如“我更关注产品曝光不足”)
2. 层级限制:
- 系统最多只有4层
- 当current_layer === 4且已有answer_content时,立即设置should_continue: false,action: null
3. 智能判断是否需要搜索:
- 根据当前问题和上下文,判断是否需要搜索相关资料
- 如果需要,设置action: “search”,并输出search_query
4. 判断是否可以回答:
- 当具备足够上下文时(用户已澄清、或已搜索、或已有历史记录),设置action: “answer”
- 输出current_question,指导Answer节点回答问题
Plan节点的输出格式(JSON):
{
“thinking_process”:”思考过程(50-100字,用户友好)”,
“goal”:”当前目标(20-30字)”,
“plan”:”执行计划(1、2、3、4编号列表)”,
“current_layer”:1,
“current_question”:”当前层的问题(用户友好,避免技术术语)”,
“should_continue”:true,
“action”:”ask_user” | “search” | “answer” | null,
“need_user_clarification”:true | false,
“clarification_options”:[“选项1″,”选项2″,”选项3”],
“tool_call”:{
“tool_name”:”ask_user” | “search” | “answer” | null,
“input_params”:{
“clarification_options”:[…],
“query”:”…”
}
}
}
3. 状态更新节点的设计
状态更新节点负责将当前轮次的结果保存到digging_history中。
关键设计:每次循环都创建一条新记录,append到数组,而不是更新已有记录。
状态更新节点的代码:
import copy
defmain(params: dict) -> dict:
#
1. 获取长期保存变量(从循环参数)
context_data = params.get(‘context_data’, {})
loop_current_layer = params.get(‘current_layer’, 1)
user_query = params.get(‘user_query’, ”)
# 确保context_data是字典类型
ifnotisinstance(context_data, dict):
context_data = {‘digging_history’: []}
# 确保loop_current_layer是int类型
ifnotisinstance(loop_current_layer, int):
try:
loop_current_layer = int(loop_current_layer)
except (ValueError, TypeError):
loop_current_layer = 1
# 从context_data中提取digging_history
digging_history_raw = context_data.get(‘digging_history’, [])
ifnotisinstance(digging_history_raw, list):
digging_history = []
else:
# 创建列表的深拷贝,确保不会意外修改原始数据
digging_history = copy.deepcopy(digging_history_raw)
#
2. 获取当前轮次的结果
plan_current_layer = params.get(‘plan_current_layer’)
if plan_current_layer isnotNone:
ifnotisinstance(plan_current_layer, int):
try:
plan_current_layer = int(plan_current_layer)
except (ValueError, TypeError):
plan_current_layer = loop_current_layer
current_layer = plan_current_layer
else:
current_layer = loop_current_layer
current_question = params.get(‘current_question’, ”)
# 获取should_continue:直接透传字符串值,不做任何处理
should_continue = params.get(‘should_continue’, ‘true’)
plan = params.get(‘plan’, ”)
thinking_process = params.get(‘thinking_process’, ”)
goal = params.get(‘goal’, ”)
# 获取各分支的新结果
user_selection_new = params.get(‘user_selection_new’, ”)
search_query = params.get(‘search_query’, ”)
search_results_new = params.get(‘search_results_new’, ”)
answer_content_new = params.get(‘answer_content_new’, ”)
#
3. 创建当前轮的新记录并追加到digging_history
# 创建当前轮的新记录
new_layer_item = {
‘layer’: current_layer,
‘layer_type’: [‘现象拆解’, ‘关联断裂’, ‘公理化’, ‘重构验证’][current_layer
– 1] if1 <= current_layer <= 4else’未知’,
‘user_selection’: user_selection_new if (current_layer == 1and user_selection_new) elseNone,
‘question’: current_question if current_question else”,
‘plan’: plan if plan else”,
‘thinking_process’: thinking_process if thinking_process else”,
‘goal’: goal if goal else”,
‘search_query’: search_query if search_query elseNone,
‘search_results’: search_results_new if search_results_new elseNone,
‘answer_content’: answer_content_new if answer_content_new elseNone
}
# 追加到digging_history数组
digging_history.append(new_layer_item)
#
4. 确定输出的current_layer
if plan_current_layer isnotNone:
output_current_layer = plan_current_layer
else:
output_current_layer = loop_current_layer
#
5. 重新构建context_data对象
context_data = {
‘digging_history’: digging_history
}
result = {
‘context_data’: context_data, # 直接输出对象
‘current_layer’: output_current_layer, # 使用Plan节点决定的层级,或保持原值
‘user_query’: user_query,
‘should_continue’: should_continue # 直接透传字符串值
}
return result
关键点:
- 使用copy.deepcopy确保不会意外修改原始数据
- 每次循环都append新记录,而不是查找并更新已有记录should_continue
- 直接透传字符串值,不做任何类型转换current_layer
- 由Plan节点决定,状态更新节点只负责保存
4. 第一性原理的四层下探方法论的实现
四层下探方法论是整个智能体的核心逻辑,通过Plan节点的提示词来实现。
第1层:现象拆解(解构)
- 目标:将复杂问题/现象拆解为基本要素
- 方法:物理拆解、功能拆解、成本拆解
- Plan节点会规划:“需要拆解这个现象的基本要素”
第2层:关联断裂(溯源)
- 目标:切断传统认知的类比链条
- 方法:质问“为什么不能”、识别假设、追溯起源、5Why分析法
- Plan节点会规划:“需要追溯这个现象的起源,切断传统认知链条”
第3层:公理化(第一性原理浮出水面)
- 目标:识别第一性原理
- 标准:不可删除、不可违背、不可推导
- Plan节点会规划:“需要识别第一性原理,判断是否满足三不可检验标准”
第4层:重构验证
- 目标:从第一性原理向上推演,验证结论
- 方法:压力测试、最小可行性验证
- Plan节点会规划:“需要从第一性原理向上推演,验证结论的正确性”
循环终止规则:
- 当current_layer === 4且已有answer_content时,Plan节点会设置should_continue: false,action: null
- 循环节点检测到should_continue === “false”时,终止循环
实际效果展示
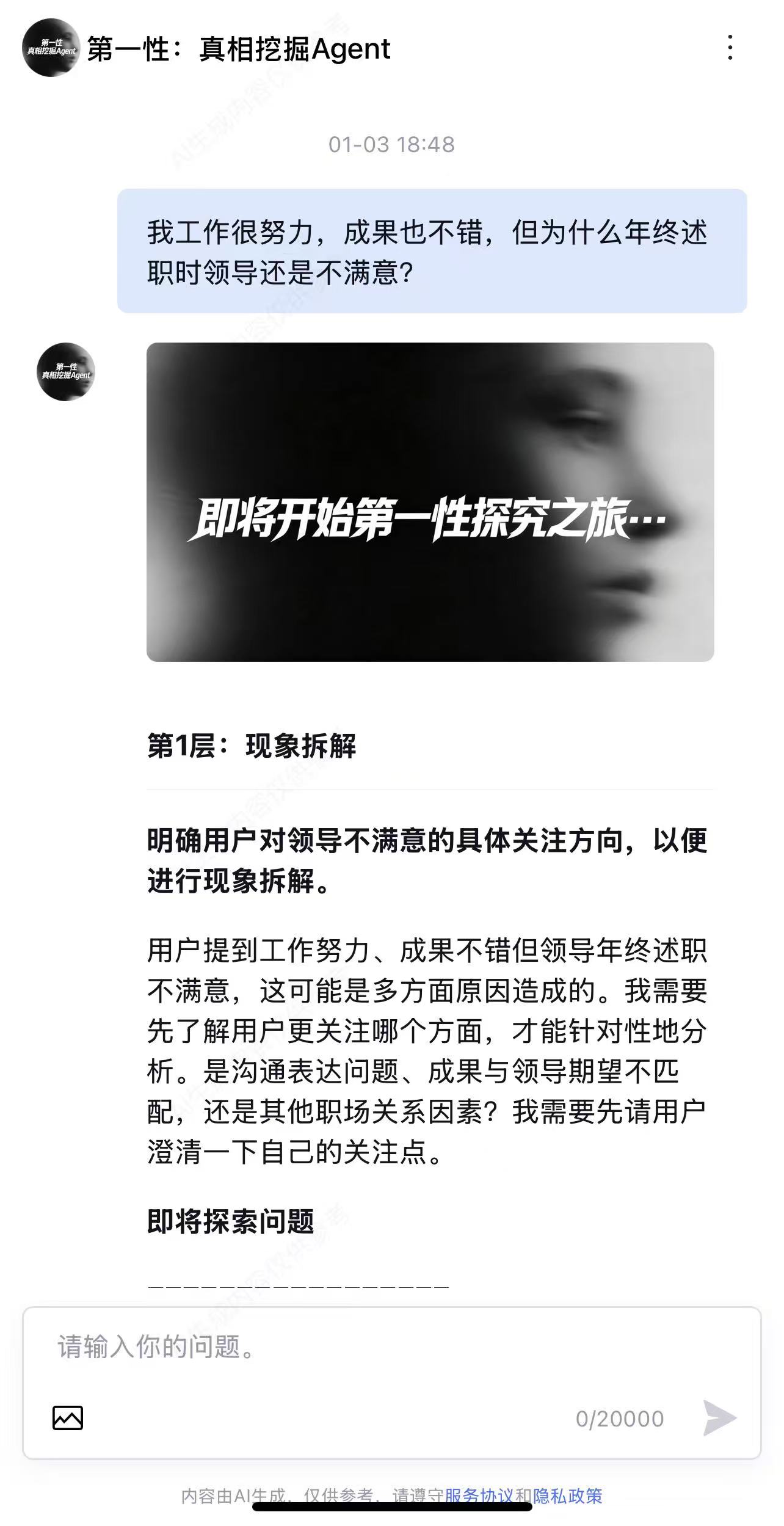



- 用户输入“我工作很努力,成果也不错,但为什么年终述职时领导总是不满意?”
- 第1层:现象拆解(Plan结果展示)
- 第2层:关联断裂(Plan结果展示 + Search结果展示)
- 第3层:公理化(Plan结果展示 + Answer结果展示)
- 第4层:重构验证(Plan结果展示 + Answer结果展示)
- 最终报告(完整的探究报告)
体验一个完整流程后,用户能够:
- 看到每一层的挖掘过程和结果
- 理解为什么这样下探
- 获得第一性原理结论
- 获得可执行的行动方案
- 感受到深度思考的乐趣和系统性思维的魅力
关于智能体平台
搭建这个智能体使用的是工作流平台,它提供了完整的工作流搭建能力:
- 可视化工作流:通过拖拽节点就能搭建复杂的业务流程
- LLM节点:内置多种大模型,支持灵活的提示词工程
- 代码节点:支持Python代码,实现复杂的数据处理逻辑
- 循环节点:支持循环调用子工作流,实现批量处理
- 变量管理:完善的状态管理和变量传递机制
- 工具节点:支持搜索工具、用户输入节点等
最关键的是,你可以把搭建好的智能体直接发布到小程序,不需要自己搞备案、买服务器,用户体验流畅,价值完全不同。
(主工作流)
(子工作流)
写在最后
这个智能体的核心价值不在于技术有多复杂,而在于它把”第一性原理思考”这件事的门槛降低了。
通过AI自动层层追问,我们可以在几分钟内完成一次深度的第一性原理分析,从现象到本质,找到行为背后的底层逻辑。这种体验虽然不能完全替代人类的深度思考,但足以让我们获得宝贵的洞察和可执行的行动方案。
如果你也想搭建类似的智能体,或者对技术实现细节感兴趣,欢迎交流。
体验链接:https://yuanqi.tencent.com/webim/#/chat/PedpBb?appid=2006613871076734592
欢迎体验“第一性:真相挖掘Agent”,并反馈任何建议或BUG。
本文由 @崔峻 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议









文中提到的智能体体验地址https://yuanqi.tencent.com/webim/#/chat/PedpBb?appid=2006613871076734592
试用了一下。真的好用
感谢体验,有问题或建议随时交流哈~