
 起点课堂会员权益
起点课堂会员权益告别AI“假名言”!手把手教你用RAG搭建一个“走心”的世界名著语录助手
在情绪涌动却词不达意的时刻,你是否渴望真正精准的文学表达?本文揭秘如何利用RAG技术打造‘世界名著语录智能检索助手’,绕过AI编造的名言陷阱,直接从经典著作中挖掘直抵人心的金句。从知识库搭建到提示词设计,手把手教你打造专属文学智库。

场景洞察:为什么我们需要“精准”的文学?
你是否也有过这样的时刻:心中涌起一阵莫名的情绪——可能是暴雨将至的压抑,也可能是人到中年的无奈——想发个朋友圈,或者写一段文案,却发现词汇贫乏?
如果直接问ChatGPT“给我一句关于暴雨的名言”,它往往会一本正经地胡说八道,编造出鲁迅没说过的话,或者给你灌一碗毫无营养的“AI鸡汤”。
我们真正渴望的,是《双城记》里那种直抵人心的厚重,是《百年孤独》里那句精准的宿命感。我们需要的是“真迹”,而不是“仿品”。
基于这个痛点,我利用 RAG(检索增强生成) 技术,搭建了一个“世界名著语录智能检索助手”。它不瞎编,只从我上传的名著原文中“寻宝”。
️ 搭建思路:给大模型装一座“图书馆”
传统的AI像个什么都懂但记忆模糊的博主,而 RAG 则是给这个博主配了一座“图书馆”。
我的设计思路非常简单直接:
- 建库:把TXT格式的名著文件塞进知识库。
- 检索(The Librarian):用户问什么(如“悲伤”),系统先去书里翻出最相关的段落。
- 加工(The Curator):大模型读完这些段落,筛选出最金句,并附上书名和解析。
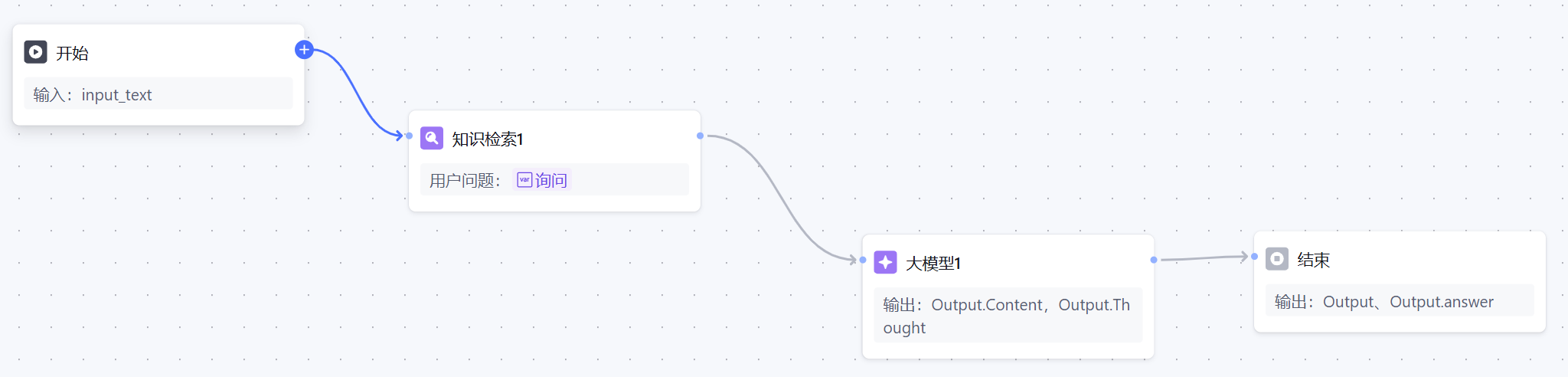
核心实现路径
整个搭建过程不需要写一行代码,完全通过可视化拖拽完成。
以下是我的“通关秘籍”:
第一步:知识库的“广撒网”策略
上传书籍只是基础,最关键的是**【知识检索】节点**的配置。
在实战中,我遇到了一个典型问题:我明明上传了十几本书,但AI每次都只给我《双城记》的句子。为什么?因为《双城记》关于那个话题的描述得分最高,挤占了所有位置。
解决方案: 我将 “问答召回数量 (Top K)” 从默认的 3 强行拉大到了 5。 这就像把“采购篮子”变大,不仅装入排名第1的书,也要把排名考前的书都装进来,确保AI手里有足够多样的素材。
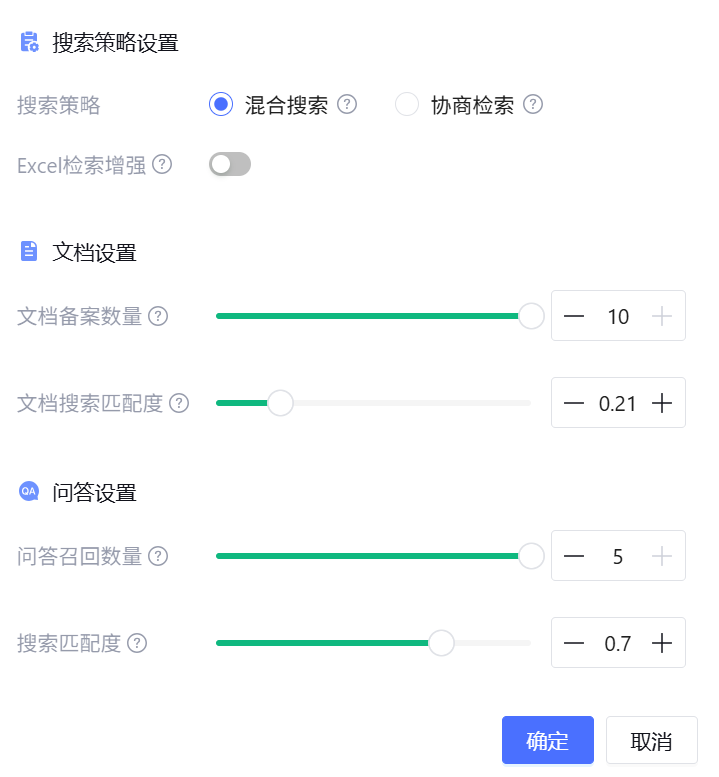
第二步:提示词的“去重指令”
素材多了,AI容易偷懒,对着一本书薅羊毛。我在【大模型】节点的 Prompt 中加入了严格的逻辑约束:
- “如果参考片段中包含多部作品,务必让输出结果包含3部及以上。”
- “同一部作品(书名)下的语录最多输出 2-3 句。”
- “严禁瞎编,必须基于【参考片段】。”
第三步:调试与发布的“坑”
在最后上线前,我遇到了“调试正常,发布后报错”的经典玄学问题。报错提示 运行失败 – 开始。
排查后发现,这是因为在修改变量名(从 query 改为 input_text)后,机器人外壳与工作流内部的参数映射断开了。 经验总结:如果发布后报错,最快的修法是把工作流卡片删掉,重新添加一次,强制系统刷新参数连接。
实战心得与效果展示
经过反复打磨,这个助手现在已经能像一位真正的文学教授一样与我对话。当我输入“关于暴雨的句子”时,它不再只给我一句干巴巴的描述,而是同时呈上了《双城记》里的阴郁、《呼啸山庄》里的狂野,并且每一句都带着书名出处。

给想动手的朋友3个建议:
- Top K 是灵魂:做语录类应用,一定要把检索数量拉大,否则内容不仅单一,还容易漏掉好句子。
- Prompt 要有“强迫症”:明确告诉AI“不要什么”,比告诉它“要什么”更管用,尤其是防幻觉和去重。
- 变量名要对齐:90%的运行错误都是因为“开始节点”的变量名和后面没对上,保持变量名一致(如统一用 input_text)能省去很多麻烦。
AI 不仅仅是效率工具,它也可以很浪漫。希望这个小教程能帮你搭建出属于自己的“精神避难所”。
本文由 @杨阳 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


