
 起点课堂会员权益
起点课堂会员权益一个智能体帮你从传统PM进化成AI PM
AI产品经理转型路上,你是否也迷失在碎片化信息与模糊路径中?这款专为产品人打造的智能学习规划助手,通过精准分析岗位背景、经验级别与时间安排,生成个性化AI转型路线图。从电商推荐系统到NLP技术栈,本文将揭秘如何用LLM工作流架构实现千人千面的学习计划生成。

你有没有遇到过这样的困境?
作为产品经理,你看到AI技术越来越火,公司也开始要求产品接入AI能力。但当你真正要去做的时候,却发现:
- 不知道AI产品经理到底需要什么能力
- 不知道从哪开始学,网上资源太零散
- 不知道学什么方向,电商PM该学推荐系统还是NLP?
- 不知道如何安排学习时间,工作已经够忙了
- 不知道学完能不能真的转型成功
想转型,但不知道怎么做。
这就是我最近搭建的智能体:”AI产品进化论”——专门帮助产品经理从传统PM向AI PM转型的智能学习规划助手。
这篇文章分享一下这个智能体的搭建过程,帮助大家了解一下工作流架构和LLM应用开发的玩法。

为什么做这个?
AI转型是产品经理最迫切的需求之一,但也是最难系统化的。
共同的困境:
- 不知道从何开始学习,资源太零散,缺乏系统性
- 学习内容与自身背景脱节,学了用不上
- 工作繁忙,学习时间有限,不知道如何安排
- 缺乏进度跟踪和效果评估,学了也不知道有没有用
- 路径不清,不知道应该学什么、学到什么程度、什么时候能转型成功
所以我做了这个智能体:通过AI分析你的岗位背景、经验级别、学习方向、时间安排和转型周期,为你生成一份专属的AI转型学习计划。
它不想取代真实的学习,而是把学习规划的门槛降低——让你能够低成本、高效率地找到适合自己的AI转型路径,知道每一步该做什么。
定位&整体交互
产品定位
目标用户:想要向AI产品经理转型的传统产品经理、对AI产品感兴趣的产品经理、想要提升AI产品能力的产品经理
核心价值:通过AI分析用户背景,生成个性化的、可执行的AI转型学习计划
能力边界:
- 支持不同岗位类型(电商、社交、B端、工具产品经理)
- 支持不同经验级别(新手、初级、中级、高级)
- 支持不同学习方向(推荐系统、NLP、CV、通用能力)
- 支持不同时间安排(少于30分钟、30-60分钟、1-2小时、2小时以上)
支持不同转型周期(1个月、3个月、6个月)
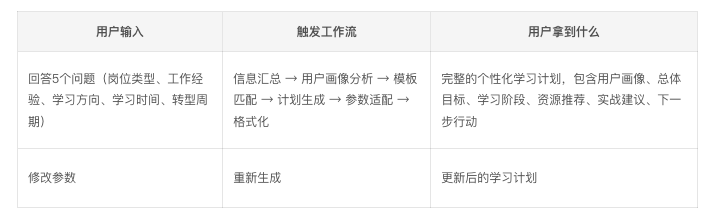
整体交互设计
交互流程非常简单直观:
工作流架构设计
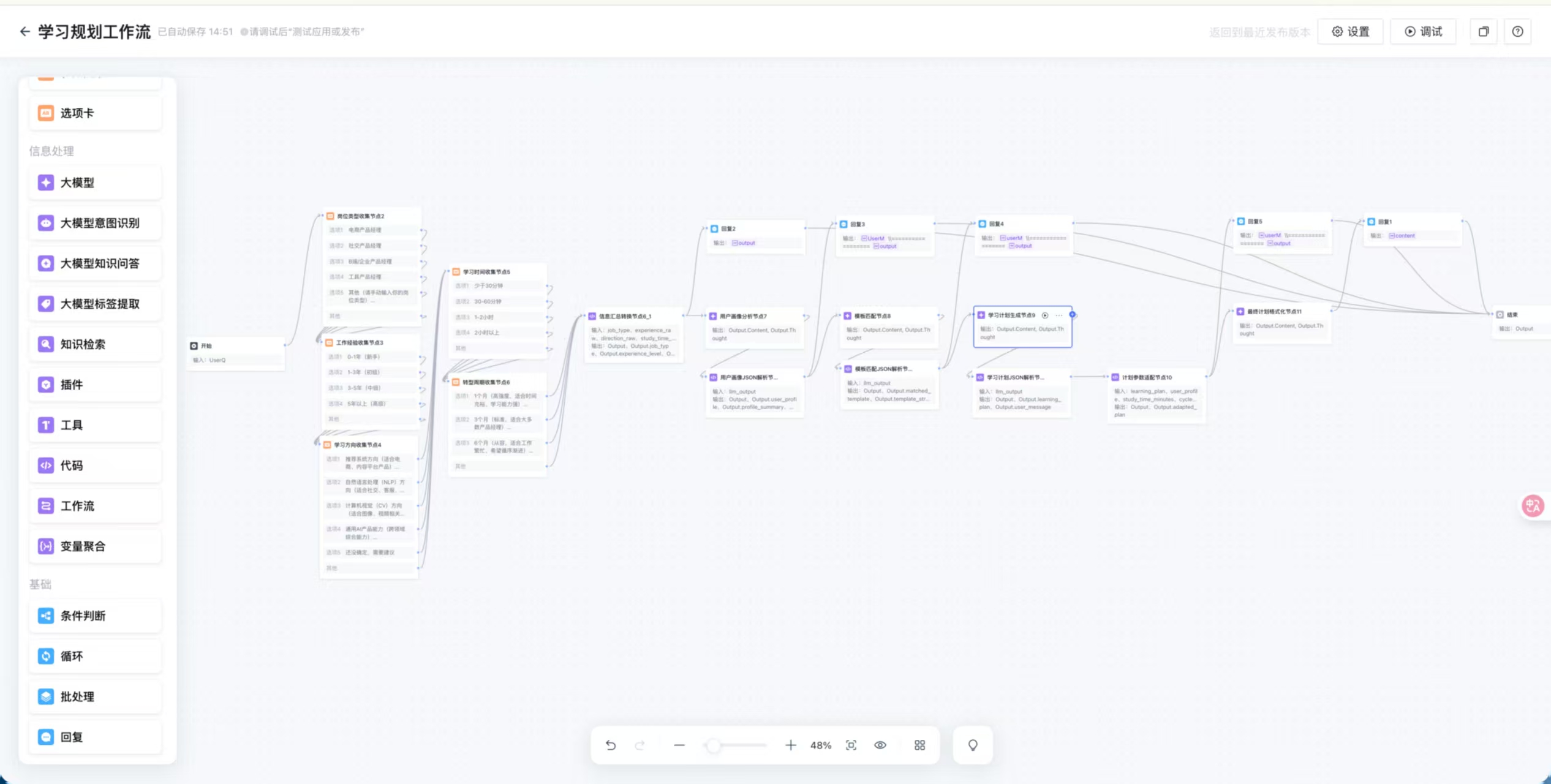
整个智能体基于工作流架构搭建,分为三个核心阶段:

阶段1:信息收集与标准化
处理流程:
- 岗位类型收集(卡片选择):电商/社交/B端/工具/其他
- 工作经验收集(卡片选择):0-1年/1-3年/3-5年/5年以上
- 学习方向收集(卡片选择):推荐系统/NLP/CV/通用/需要建议
- 学习时间收集(卡片选择):<30分钟/30-60分钟/1-2小时/2小时以上
- 转型周期收集(卡片选择):1个月/3个月/6个月
信息汇总转换节点(Python代码):将卡片选择的原始值转换为标准化变量
阶段2:智能分析与计划生成
关键技术点:
1、用户画像分析:
- 综合描述用户的基本情况
- 分析用户的学习背景和特点
- 评估用户的学习能力和时间条件
- 如果用户选择了“需要建议”,根据岗位类型推荐最适合的学习方向
2、模板匹配逻辑:
- 优先匹配:岗位类型 × 经验级别 × 学习方向
- 如果精确匹配不存在,则降级匹配(如:岗位×经验,或岗位×方向)
- 如果用户选择了“待建议”方向,使用推荐的学习方向进行匹配
3、学习计划生成:
- 1个月:按周划分(4个阶段)
- 3个月:按月划分(3个阶段)
- 6个月:按2个月划分(3个阶段)
根据转型周期划分学习阶段:
- 每个阶段包含具体的学习任务,任务要符合每日学习时间
- 推荐的学习资源要权威、实用、时效性强
4、计划参数适配:
- 根据每日学习时间调整任务量
- 如果任务时间过长,标记需要拆分
- 添加适配说明
阶段3:格式化与输出
主要功能:
最终计划格式化节点(LLM):
- 将学习计划格式化为Markdown文档
- 使用清晰的标题层级(#、##、###)
- 使用表格展示任务和资源信息
- 使用引用块突出重要提示
- 使用emoji增强可读性
- 直接输出纯Markdown文本,不使用JSON格式
技术实现细节
1. 卡片选择与信息标准化
整个工作流中,信息收集使用卡片选择组件:
卡片选择组件的特点:
- 用户点击卡片即可选择,体验流畅
- 只能有一个输出变量,不能有多个输出变量
- 节点2-6的每个节点都只有一个输出变量(如:job_type、experience_raw、direction_raw、study_time_raw、cycle_raw)
信息汇总转换节点的代码:
defmain(params: dict) -> dict:
# 获取输入变量,处理None值
job_type = params.get(‘job_type’) or”
experience_raw = params.get(‘experience_raw’) or”
direction_raw = params.get(‘direction_raw’) or”
study_time_raw = params.get(‘study_time_raw’) or”
cycle_raw = params.get(‘cycle_raw’) or”
# 转换工作经验
experience_info = experience_mapping.get(experience_raw, {‘level’: ‘初级’, ‘years’: ‘1-3年’})
experience_level = experience_info[‘level’]
experience_years = experience_info[‘years’]
# 转换学习方向
learning_direction = direction_raw if direction_raw else’通用’
needs_suggestion = (direction_raw == ‘待建议’)
# 转换学习时间
study_time_mapping = {
‘少于30分钟’: {‘time’: ‘少于30分钟’, ‘minutes’: 20},
’30-60分钟’: {‘time’: ’30-60分钟’, ‘minutes’: 45},
‘1-2小时’: {‘time’: ‘1-2小时’, ‘minutes’: 90},
‘2小时以上’: {‘time’: ‘2小时以上’, ‘minutes’: 150}
}
study_time_info = study_time_mapping.get(study_time_raw, {‘time’: ’30-60分钟’, ‘minutes’: 45})
daily_study_time = study_time_info[‘time’]
study_time_minutes = study_time_info[‘minutes’]
# 转换转型周期
cycle_mapping = {
‘1个月’: {‘cycle’: ‘1个月’, ‘months’: 1, ‘intensity’: ‘高强度’},
‘3个月’: {‘cycle’: ‘3个月’, ‘months’: 3, ‘intensity’: ‘标准’},
‘6个月’: {‘cycle’: ‘6个月’, ‘months’: 6, ‘intensity’: ‘从容’}
}
cycle_info = cycle_mapping.get(cycle_raw, {‘cycle’: ‘3个月’, ‘months’: 3, ‘intensity’: ‘标准’})
transformation_cycle = cycle_info[‘cycle’]
cycle_months = cycle_info[‘months’]
intensity = cycle_info[‘intensity’]
return {
‘job_type’: job_type,
‘experience_level’: experience_level,
‘experience_years’: experience_years,
‘learning_direction’: learning_direction,
‘needs_suggestion’: needs_suggestion,
‘daily_study_time’: daily_study_time,
‘study_time_minutes’: int(study_time_minutes),
‘transformation_cycle’: transformation_cycle,
‘cycle_months’: int(cycle_months),
‘intensity’: intensity
}
关键设计:
- 卡片选择组件只能有一个输出变量,所以需要信息汇总转换节点来转换为多个标准化变量
- 转换逻辑要处理各种可能的输入格式,确保后续节点能正确使用
2. LLM节点与JSON解析的配合
整个工作流中,大部分LLM节点输出JSON格式:
{
“user_message”:”用户看到的内容(Markdown格式)”,
“context_data”:{
// 后续节点需要的结构化数据
}
}
每个LLM节点后都跟着一个Python代码节点来解析JSON,提取context_data供后续节点使用,同时提取user_message用于展示给用户。
关键设计:user_message必须是对当前步骤执行结果的概括,而不是”正在处理”等过程性提示,这样用户能实时看到进度。
JSON解析节点的通用代码:
import json
import re
defmain(params: dict) -> dict:
input_str = params.get(‘llm_output’) or params.get(‘input’, ”)
ifnot input_str:
return {}
# 处理可能被markdown代码块包裹的情况
input_str = re.sub(r’^“`json\s*’, ”, input_str, flags=re.MULTILINE)
input_str = re.sub(r’“`\s*$’, ”, input_str, flags=re.MULTILINE)
input_str = input_str.strip()
try:
parsed_data = json.loads(input_str)
context_data = parsed_data.get(‘context_data’, {})
user_message = parsed_data.get(‘user_message’, ”)
return {
‘context_data’: context_data,
‘user_message’: user_message
}
except json.JSONDecodeError:
return {}
关键细节:
- 处理可能被markdown代码块包裹的JSON(去除“`json标记)
- JSON解析失败时的降级处理(返回空字典)
- 确保提取的字段都有默认值,避免后续节点报错
3. 提示词工程的精细化
每个LLM节点都有详细的提示词,包含:
- 角色设定:明确LLM扮演的角色(如”你是一个用户画像分析助手”)
- 输入说明:清晰说明输入变量的含义和格式
- 输出格式:严格要求输出格式,提供示例
- 风格要求:强调专业性、实用性、个性化等
用户画像分析节点的提示词关键部分:
你是一个用户画像分析助手。请基于用户提供的信息,生成用户画像摘要和分析。
用户信息:
– 岗位类型:{{job_type}}
– 工作经验:{{experience_years}}({{experience_level}})
– 学习方向:{{learning_direction}}
– 每日学习时间:{{daily_study_time}}
– 转型周期:{{transformation_cycle}}({{intensity}})
请完成以下任务:
1. **用户画像摘要**(100-150字):
– 综合描述用户的基本情况
– 分析用户的学习背景和特点
– 评估用户的学习能力和时间条件
– 如果needs_suggestion为true,需要根据岗位类型给出学习方向建议
2. **学习需求分析**:
– 根据岗位类型,分析用户最需要的AI能力
– 根据经验级别,确定学习计划的起点和深度
– 根据学习方向,确定重点学习内容
3. **学习条件评估**:
– 评估每日学习时间是否充足
– 评估转型周期是否合理
– 给出学习强度建议
请严格按照以下JSON格式返回:
{
“user_message”: “使用Markdown格式输出…”,
“context_data”: {
“user_profile”: {…},
“profile_summary”: “…”,
“learning_needs”: […],
“condition_assessment”: {…}
}
}
关键点:
- 必须使用结构化输出(JSON格式),确保后续节点能正确解析
- 输出格式要严格规定,包含示例,避免模型自由发挥
- 风格要求要明确具体(专业性、实用性、个性化等)
4. 错误处理与容错
代码节点中实现了完善的错误处理,确保流程不会因为数据格式问题中断。
JSON解析失败时的降级处理:
try:
parsed_data = json.loads(input_str)
context_data = parsed_data.get(‘context_data’, {})
except json.JSONDecodeError:
# 解析失败时返回空字典,而不是抛出异常
return {‘context_data’: {}}
数据格式不一致时的类型检查:
# 确保study_time_minutes和cycle_months是int类型
study_time_minutes = params.get(‘study_time_minutes’)
if study_time_minutes isNone:
study_time_minutes = 45
else:
try:
study_time_minutes = int(study_time_minutes)
except (ValueError, TypeError):
study_time_minutes = 45
计划参数适配时的安全处理:
# 如果任务预计时间超过每日学习时间,需要拆分或调整
estimated_time = task.get(‘estimated_time’, 0)
ifisinstance(estimated_time, str):
# 尝试从字符串中提取数字
try:
estimated_time = int(estimated_time.replace(‘分钟’, ”).replace(‘min’, ”).strip())
except:
estimated_time = study_time_minutes
# 如果任务时间过长,标记需要拆分
if estimated_time > study_time_minutes * 1.5:
task[‘needs_split’] = True
task[‘split_suggestions’] = f”建议将此任务拆分为多个子任务,每个子任务约{study_time_minutes}分钟”
实际效果展示
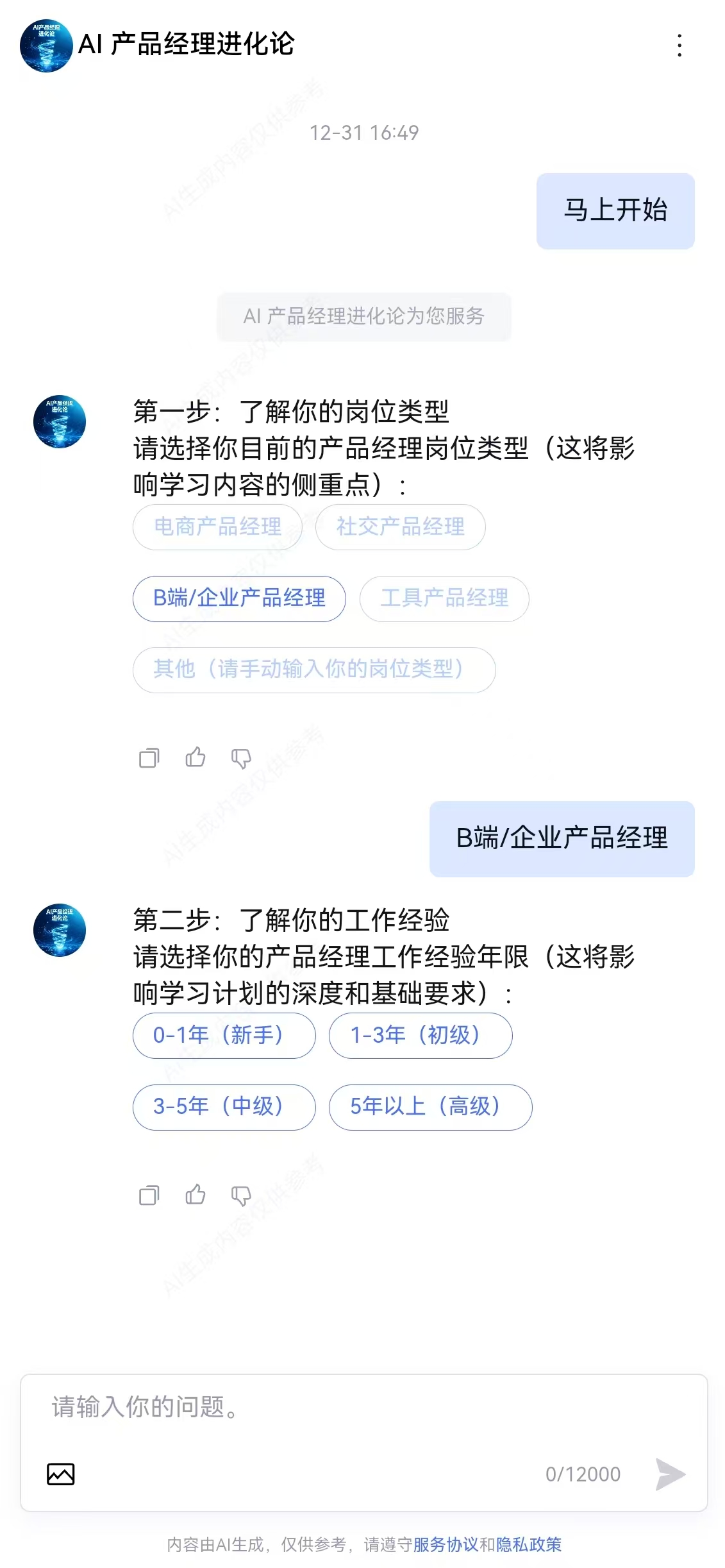


- 用户选择“电商产品经理”、“1-3年”、“推荐系统方向”、“30-60分钟”、“3个月”
- 生成的用户画像摘要
- 匹配的学习计划模板
- 最终生成的完整学习计划(包含总体目标、学习阶段、资源推荐、实战建议)
体验一个完整流程后,用户能够:
- 理解自己的AI产品能力现状和学习需求
- 获得一份系统化的、个性化的学习计划
- 知道每个阶段应该学什么、怎么学、学到什么程度
- 获得精准的学习资源推荐和实战建议
拓展和延伸
场景延伸
这个智能体的核心是基于LLM的个性化分析和计划生成能力。
类似的玩法可以延伸到:
- 职业规划:为不同职业的人生成职业发展路径
- 技能学习:为不同背景的人生成技能学习计划
- 项目管理:为不同项目生成项目执行计划
- 内容创作:为不同主题生成内容创作计划
技术延伸
工作流架构的优势在于模块化和可扩展性:
- 知识库增强:可以为不同岗位类型添加专门的知识库,提高计划生成的准确性
- 多维度匹配:可以增加更多匹配维度(如行业、公司规模、个人兴趣等),让计划更加个性化
- 进度跟踪:可以增加学习进度跟踪功能,让用户能够记录学习进度和成果
- 社区功能:可以支持用户分享学习计划、交流学习心得、互相监督学习
其它细节
1. 个性化设计
为了让用户真正感受到”量身定制”,我在提示词中强调:
- 根据岗位类型分析最需要的AI能力:不同岗位对AI能力的需求不同
- 根据经验级别确定学习计划的起点和深度:新手和高级PM的学习路径完全不同
- 根据学习方向确定重点学习内容:推荐系统、NLP、CV的学习重点不同
- 根据学习时间和转型周期调整计划强度:时间有限时需要更聚焦的学习计划
- 推荐的学习资源要符合用户背景和需求:确保资源实用性和可获取性
2. 阶段性输出
因为过程中选择了结构化输出,没办法实现流式输出,为了让用户的体验相对好一点,我在关键节点提供阶段性输出。
例如,在用户画像分析完成后,立即输出用户画像摘要给用户看;在模板匹配完成后,输出匹配结果;在计划生成完成后,输出计划概览,让用户知道接下来会看到什么。
关于智能体平台
搭建这个智能体使用的是工作流平台,它提供了完整的工作流搭建能力:
- 可视化工作流:通过拖拽节点就能搭建复杂的业务流程
- LLM节点:内置多种大模型,支持灵活的提示词工程
- 代码节点:支持Python代码,实现复杂的数据处理逻辑
- 卡片选择组件:支持用户友好的交互方式
- 变量管理:完善的状态管理和变量传递机制
最关键的是,你可以把搭建好的智能体直接发布到小程序,不需要自己搞备案、买服务器,用户体验流畅,价值完全不同。
写在最后
这个智能体的核心价值不在于技术有多复杂,而在于它把”AI转型规划”这件事的门槛降低了。
通过AI分析,我们可以在几分钟内获得一份个性化的、系统化的AI转型学习计划,知道应该学什么、怎么学、学到什么程度。这种规划虽然不能完全替代真实学习,但足以让我们获得清晰的转型路径和方向。
如果你也想搭建类似的智能体,或者对技术实现细节感兴趣,欢迎交流。
欢迎体验“AI产品经理进化论”,并反馈任何建议或BUG。
https://yuanqi.tencent.com/webim/#/chat/vvQFvw?appid=2006199404765244416
本文由 @秋水 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


