
 起点课堂会员权益
起点课堂会员权益Gemini地表综合能力最强模型,Native Multimodality的受益者!
AI竞争的战场已从参数规模转向原生能力与生态效率。Google Gemini系列凭借原生多模态、RLAIF、Ring Attention和软硬一体MoE四大架构创新,正在重新定义AI产品的天花板。本文将深度解析这些技术如何为产品经理打开自动驾驶、工业机器人和超长文档分析等高价值赛道的新机遇。

在 2026 年的 AI 战场上,模型参数的边际效应已经递减。业界公认的竞争高地已从单纯的“规模”转向了“原生能力”(处理现实世界复杂信号的本能)与“生态效率”(单位算力的产出比)。
Google Gemini 系列在 2025 年末到 2026 年初的多次权威评测中表现优异,彻底验证了其四大核心架构——原生多模态、RLAIF、Ring Attention 与软硬一体 MoE 的前瞻性。对于产品经理而言,理解这些底层逻辑,就是在定义产品的“天花板”与“护城河”。
https://blog.google/intl/zh-tw/products/explore-get-answers/gemini-3/#gemini-3
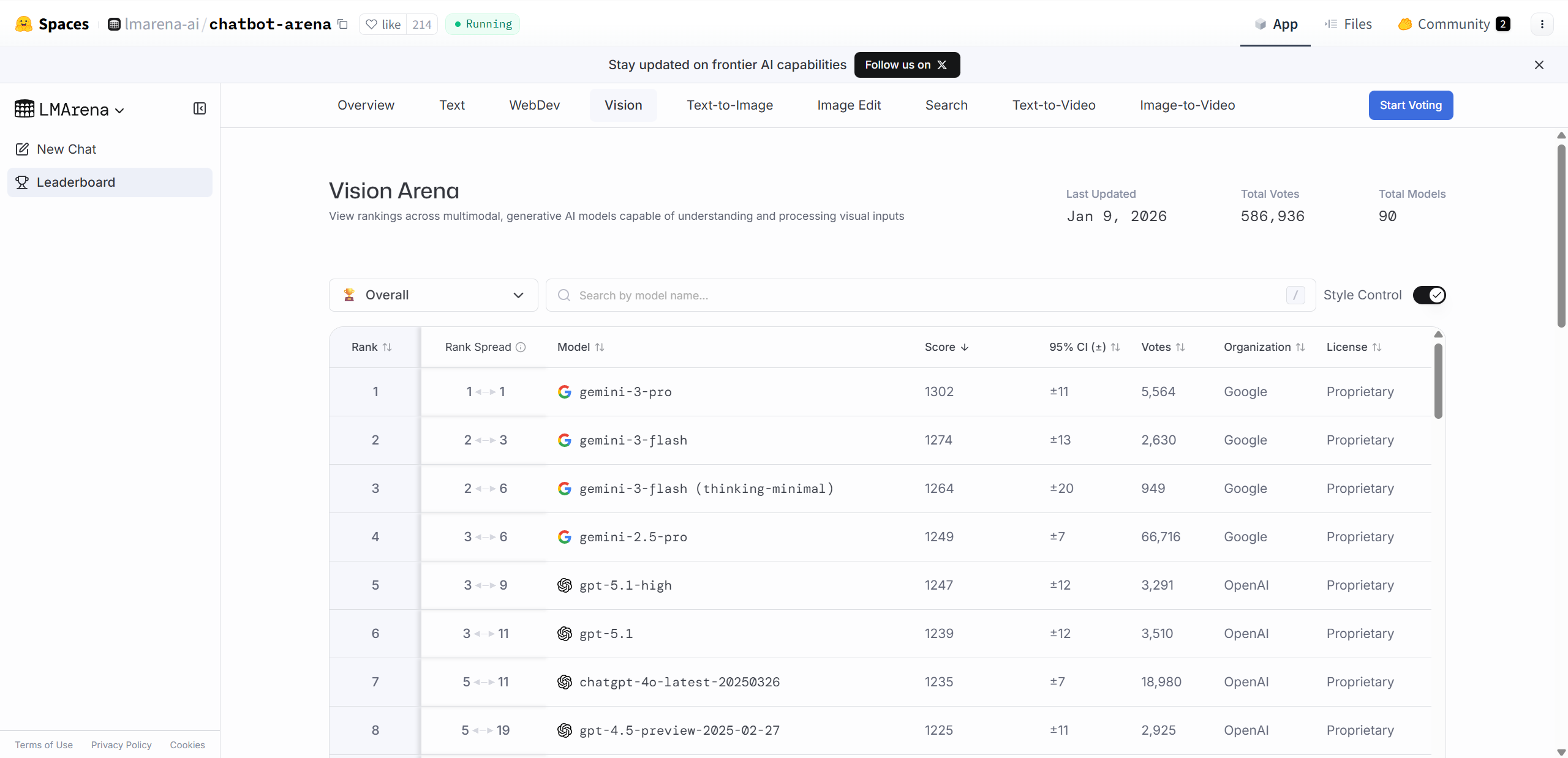
Gemini 3.0 pro
https://lmarena.ai/leaderboard/webdev
PM 视角洞察:> 过去我们通过“调优提示词”来补齐模型能力的短板,但在 2026 年,如果你的底层架构不是原生多模态,你将无法在自动驾驶、实时工业机器人、超长文档分析等高价值赛道中胜出。这些数据证明:Google 正在通过架构的系统化优势,将 AI 从“聊天机器人”推向“物理世界专家”。
一、原生多模态:从“翻译官”到“本能直觉”
1. 技术定义与深度解构
什么是原生多模态 (Native Multimodality)?
在 2026 年,领先的架构(如 Gemini 3.0)已经彻底摒弃了“视觉编码器 + 语言模型 + 音频解码器”这种拼凑式的“插拔架构”。
- 统一表征层 (Unified Tokenizer):图像像素、视频帧率、音频波形和文本字符,在进入模型的第一秒就被映射到同一个高维向量空间。
- 端到端学习:模型在预训练阶段就同时吞噬文本、图像和视频。这意味着它不是在“学习如何描述图片”,而是在“学习物理世界的运行规律”。
PM 必知:传统的“适配器”方案(如早期 GPT-4V)在多模态转换中会损失约 20%-30% 的语义细节。而原生多模态实现了“零损耗感官对齐”。
2. 深度类比:图书馆孩子 vs. 现实世界孩子

传统模型(图书馆孩子):他的所有知识来自书本。如果你给他看一张“锤子砸碎玻璃”的照片,他必须在脑子里搜索“玻璃、破碎、物理力”等关键词,然后拼凑出结论。
Gemini(现实世界孩子):他从小就看着玻璃碎掉、听着破碎的声音、感受着打击的速度。当你展示同样的场景,他不需要文字中转,他的神经元会直接产生“破坏”与“危险”的本能直觉。这种直觉让他对视频中的时间序、重力感、运动轨迹有着天然的理解。
3. 案例拆解:智能远程维修助手 (AR + AI 联动)
传统方案的痛点:
当工人戴着 AR 眼镜维修复杂的航空发动机时,传统模型会因为“帧率丢失”无法判断螺丝是拧了三圈还是四圈。它只能识别“扳手”和“发动机”这两个静态物体。
Gemini 的表现(时空连续性):
Gemini 能捕捉到微小的角速度变化。它能实时提醒:“停!左侧轴承的受力不均,你刚才拧动扳手的扭矩过大,可能导致垫片变形。” 这种对连续物理动作的闭环反馈,是“翻译官”模型永远无法触达的领域。
4. 落地指导方案:产品化路径
A. 数据端:从“标注图片”转向“时空序列数据”
策略转变:停止采购昂贵的“图片问答对”数据。
行动:重点收集“多模交互语料”。例如:一段手术视频 + 医生的实时口述 + 监护仪的实时波形。将这三种流数据进行交织对齐 (Interleaved Data),这是训练垂直领域“直觉”的核心秘籍。
B. 产品设计:定义“零延迟”的交互体验
策略转变:摆脱“用户输入文本 \rightarrow AI 生成文本”的对话框限制。
行动:开发实时视觉交互界面。例如,在体育教学 AI 中,让用户直接展示挥拍动作,AI 通过原生多模态能力在 200ms 内给出姿势修正的语音反馈,实现像“真人教练”一样的实时同步。
C. 测评指标:引入“多模态幻觉”评估
行动:建立专门的视频一致性测试集。重点考察模型在复杂动态背景下,对物体运动方向和逻辑顺序的判断准确率。
二、RLAIF:开启“模型自我进化”的流水线
1. 技术定义与解构
什么是 RLAIF (Reinforcement Learning from AI Feedback)? 在 2026 年,大模型的对齐技术已经从依赖肉眼的 RLHF(人类反馈强化学习)全面演进到 RLAIF。
- 从“人教机”到“机教机”:传统的 RLHF 存在“人类天花板”——当模型在写量子物理代码或分析万页法律条文时,普通标注员根本无法判断其对错。RLAIF 则是利用一个具备极致逻辑能力的“导师模型”(如 Gemini 3.0 Ultra),通过预设的“宪法/原则 (Constitutions)”,自动对数十亿条学生模型的输出进行评价、打分和纠偏。
- 超级对齐 (Superalignment):这解决了模型能力超越人类后,人类无法对其进行有效监督的难题。
PM 必知:RLAIF 的出现让模型训练的“对齐成本”下降了 90% 以上,同时让模型的逻辑严密性首次超越了人类专家标注的平均水平。
2. 深度类比:从“作坊式批改”到“全自动阅卷系统”

RLHF(作坊式批改):就像一所学校请了几千名老师,每人手里拿着红笔改卷子。老师会累、会困、甚至会因为看不懂深奥的题目而乱改。这种方式不仅慢,而且很难教出超越老师水平的学生。
RLAIF(全自动阅卷系统):Google 为 Gemini 打造了一个“超级机器人老师”。这个老师背下了人类所有的逻辑法则和行业规范,一秒钟能批改几亿份作业,且标准始终如一。最重要的是,它能通过逻辑推导发现学生模型中“看似正确实则逻辑断层”的隐蔽错误。
3. 案例拆解:企业级私有代码/法律助手
传统方案的痛点:某全球律师事务所在训练私有模型时,发现人类标注员在处理“跨国并购中的复杂税务穿透逻辑”时,错误率高达 15%。模型学到了人类的错误,导致在关键合同审查中出现逻辑幻觉。
Gemini 的表现(高阶逻辑对齐):通过 RLAIF,Gemini 3.0 作为“导师”,对私有模型生成的每一项推导步骤进行“形式化验证”。它不看结果是否好听,只看逻辑链条是否闭环。最终,该私有模型在复杂法理推导上的表现超过了高级合伙人的平均水平,且迭代周期从 6 个月缩短至 2 周。
4. 落地指导方案:产品化路径
A. 对齐策略:构建“导师-学生”模型闭环
执行:不要试图用普通模型去解决所有问题。
方案:采用“蒸馏 + RLAIF”模式。用最强的 Gemini 3.0 作为“离线教练”,生成高质量的带有逻辑链标注的数据集(Chain of Thought),去训练你的垂直行业小模型(如 7B 或 10B 版本),实现“小身材、大智慧”。
B. 生产效率:预算重构——从“买人工”到“买种子”
执行:停止维持庞大的低端标注团队。
方案:将 80% 的标注预算转向“高质量种子数据”的策划。聘请 5-10 名行业顶尖专家(而非几百名普通标注员),编写核心的“逻辑评价准则”,由这些专家定义 RLAIF 的“宪法”,剩下的重复性打分工作全部交给模型自动化完成。
C. 监控机制:引入“反向对齐”测试
方案:在产品发布前,利用 RLAIF 系统进行“红队测试 (Red Teaming)”,让导师模型专门寻找学生模型的逻辑死角和安全漏洞,确保在医疗、金融等高风险场景下的安全性。
三、Ring Attention:打破记忆的“物理围墙”
1. 技术定义与解构
什么是环形注意力 (Ring Attention)? 在 2026 年,百万甚至千万级 Token 的上下文窗口已成为标配,这全赖于 Ring Attention 对底层计算逻辑的重构。
- 破解二次方诅咒:传统的 Transformer 架构中,计算开销随序列长度成平方级 (Quadratic) 增长。这意味着处理 100 万字所需的算力是 10 万字的 100 倍。
- 环形通信 (Ring Communication):既然单颗芯片放不下这么长的数据,Google 就将超长序列切成碎片,分配到成百上千个 TPU 芯片上。这些芯片连接成一个“环”,数据在环中像传送带一样循环流动,计算与通信完全重叠(Overlap)。
- 近乎无限的容量:通过这种方式,内存不再是瓶颈,只要算力集群足够大,模型理论上可以拥有“无限”的记忆长度。
PM 必知:Ring Attention 让模型告别了繁琐的“数据切片”,它能一次性“吞下”一个包含 20 万个文件的代码库,或者一整季的高清电视剧,并保持对细节的秒级索引。
2. 深度类比:从“便签本”到“超级数据中心”
普通模型(便签本):它记忆力不错,但手里只有个小笔记本。看一本书时,看到第 100 页,前面的内容就被新纪录覆盖了。如果你问它第一章的细节,它只能靠猜(幻觉)。
Gemini(超级硬盘):它的脑子里装了一块几十个 PB 的高速固态硬盘。它不是在“读”书,而是在“扫描”书。它能同时摊开 50 本书放在桌面上,一眼扫过去,精准找出第 10 本书第 20 页和第 45 本书末尾的逻辑关联。
3. 案例拆解:十年财务深度回溯与“蝴蝶效应”分析
传统 RAG (检索增强) 的痛点:面对一家跨国公司十年的财报,RAG 会先进行“语义搜索”。但问题是,如果你问:“十年前的一个风险预警,是如何在十年间演变成今天的财务危机的?”——RAG 很难通过片段检索把这长达十年的线索串联起来,容易产生断章取义的幻觉。
Gemini 的表现(全知视角):凭借 Ring Attention,模型直接将十年间所有的审计报告、会议纪要、市场新闻全部加载进上下文窗口。它能像拥有上帝视角一样,清晰地指出:“2016 年 Q3 会议中提到的供应链风险,在 2019 年通过资产折旧体现,最终导致了 2025 年的流动性枯竭。” 这种长程因果链条的分析,是 RAG 架构无法实现的。
4. 落地指导方案:产品化路径
A. 架构选型:从“RAG 优先”转向“长上下文优先”
执行:重新评估你的知识库方案。
方案:对于那些逻辑严密性要求极高的场景(如:合规性审查、代码库重构、深度学术调研),优先使用支持 Ring Attention 的原生长文本架构,而非依赖向量数据库的 RAG。这能大幅减少因分段检索导致的“上下文丢失”。
B. 产品体验:设计“一次性导入”与“深度溯源”
执行:简化用户的数据准备工作。
方案:设计支持“全工程文件夹拖拽”或“全季视频上传”的功能。利用超长窗口,让用户可以直接问:“这个项目里所有关于‘加密算法’的逻辑在哪?”并让 AI 给出带超链接的原件定位。
C. 测评指标:引入“长程大海捞针”测试 (Long-context NIAH)
方案:在 10M(一千万)Token 的压力下,测试模型对随机插入的细微事实的召回率。如果你的业务涉及法律、医疗或精密工程,这个指标比单纯的对话流畅度重要 100 倍。
四、软硬一体 MoE:兼顾“博学”与“省钱”
1. 技术定义与深度解构
什么是混合专家模型 (MoE) 与 Soft MoE? 在 2026 年,万亿参数的“稠密模型 (Dense Model)”已成为过去式。Gemini 3.0 采用的是更进化的 Soft MoE 架构。
- 稀疏激活 (Sparsity):想象模型是一个拥有 1.8 万亿参数的超级大脑,但它并不会为了回答一个“1+1=2”的问题而动用全部神经元。通过路由算法,它只激活其中最相关的 5%-10% 的参数(专家模块)。
- Soft MoE 的突破:传统的 MoE 经常遇到“专家分配不均”的问题(有的专家累死,有的闲死)。Google 引入的 Soft MoE 通过全微分的分配机制,实现了任务在不同专家间的平滑调度,彻底消除了推理时的瓶颈。
- 软硬深度耦合:这是 Google 的杀手锏。MoE 这种算法在通用 GPU 上运行往往会有较高的通信延迟,但 Gemini 是针对 TPU v6 (Trillium) 芯片原生定制的,实现了“算法找芯片,芯片等算法”的极致协同。
PM 必知:这种架构让 Gemini 在处理复杂任务时拥有“大模型的智力”,但在消耗算力时却仅相当于“中型模型的开销”。
2. 深度类比:从“全员大会”到“精准专科门诊”

传统模型(全员大会):无论病人是感冒还是骨折,医院里所有的医生(几千亿个参数)都必须全部到场会诊。不仅诊费极高,而且效率极低,病人等得焦头烂额。
Gemini(顶级三甲医院):医院里住着一个“专业小分队”。当你问数学题,系统自动挂号给“数学专家”;当你需要写诗,自动转诊给“文学专家”。每个专家各司其职,又快又省电,而你只需要支付那个专家的“门诊费”。
3. 案例拆解:万人级高并发实时协作平台
挑战:一家全球 500 强企业部署了 AI 助手,要求全员 5 万名员工在编写文档、审核代码、分析财报时实时调用 AI。如果使用传统稠密模型,每月的 GPU 租赁费用将高达数百万美元,且在早高峰时段延迟会超过 10 秒。
Gemini 的表现(极致能效比):由于运行在 TPU v6 上的 Soft MoE 架构,Gemini 实现了动态资源分配。简单的语法纠错请求仅触发微量专家模块,复杂的战略分析则调用核心专家。最终,该企业在相同预算下,推理吞吐量提升了 4 倍,平均延迟稳定在 300ms 以内。
4. 落地指导方案:产品化路径
A. 垂直集成:算力生态的“降维打击”
执行:在进行产品大规模上线(Production)时,不要只看模型参数,要看“单位算力性价比”。
方案:利用 Google Cloud 的软硬一体优势,针对 Transformer 优化的自研芯片(如 TPU)进行推理部署。在 2026 年,这种“算法+芯片”的垂直优化能为你节省至少 40% 的运营成本。
B. 成本模型:动态定价与资源分级
执行:针对不同难度的用户请求,建立动态的成本控制逻辑。
方案:
- 基础任务:强制调用 MoE 架构中的小型专家子集,保持极低成本。
- 核心任务:开放更多专家模块,通过高溢价提供“专家级”服务。
这种基于架构特性的阶梯式产品设计,是 2026 年 AI 产品盈利的关键。
C. 监控维度:引入“专家利用率”看板
方案:PM 应关注模型在处理业务请求时的“稀疏度”表现。如果发现某些“专家”长期闲置,应通过 RLAIF 技术(见第二章)重新训练或微调这些模块,使其更贴合业务场景,避免算力浪费。
五、2026 落地执行指南:从“功能叠加”到“架构驱动”
在 2026 年,平庸的 AI 产品只是在调用接口,而卓越的产品则是在“压榨架构”。以下是针对四大核心技术的具体执行建议:
1. 战略优先级矩阵 (Priority Matrix)
不要试图一次性堆叠所有技术。请根据你的产品阶段进行选型:
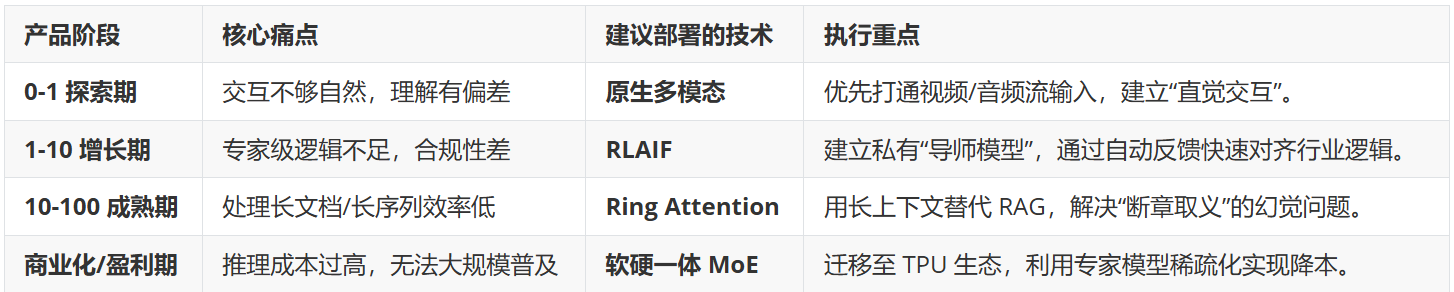
2. 资源分配的“三项调整”
PM 洞察:在 2026 年,如果你的预算表里还有大规模的“人工标注”费用,你的产品在财务上已经输了。
调整一:数据策略从“量”转为“交织” (Interleaved Data)
建议:停止单纯购买文本或图片数据。应重点投入“交织多模态数据”的采集。例如:记录一名资深工程师在操作设备时的“视频+解说词+传感器读数”。这种数据是培养模型“工业直觉”的燃料。
调整二:人才结构从“调优师”转为“规则制定者”
建议:减少招聘只会写 Prompt 的人员。你需要的是能够定义 RLAIF 宪法的行业专家,以及能够管理 MoE 专家路由逻辑的系统架构师。
调整三:算力投入从“通用 GPU”转为“自研加速器”
建议:随着 MoE 与芯片的深度绑定,尽早与 Google Cloud 等提供软硬一体(TPU v6+)的云厂商建立战略合作。利用硬件级的优化来获取至少 30% 的毛利空间。
3. 防坑指南:警惕“虚假的长文本”与“伪多模态”
警惕 RAG 陷阱:不要相信用简单的向量数据库(RAG)就能达到 Ring Attention 的效果。在处理需要全局逻辑关联的任务(如分析整个代码仓库)时,RAG 的“碎片化检索”会导致严重的逻辑断裂。
验证原生性:在测试多模态模型时,直接测试其对“空间关系”(如:视频中左边的杯子在翻倒后水流向哪里)的理解。如果模型需要先转文字再回答,那它就不是原生的,无法处理高频实时任务。
4. 首席执行官/产品负责人(CPO)的最终 Check-list
在你的产品立项书里,请确认以下三个问题:
- 直觉化:我们的产品是否能像人一样,直接通过视觉或音频识别用户的隐含意图?(原生多模态)
- 自我迭代:如果今天没有人类参与,我们的模型能否通过“导师模型”在 24 小时内完成逻辑纠偏?(RLAIF)
- 经济效益:当并发用户突破 10 万时,我们的 MoE 架构能否确保每一单请求都是盈利的?(软硬一体 MoE)
总结
2026 年的 AI 竞争不再是“谁的参数多”,而是“谁的架构更符合现实世界”。理解并应用这套说明书,意味着你已经掌握了通往下一代“数字生命”的密钥。
本文由 @Junliu 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


