
 起点课堂会员权益
起点课堂会员权益AI 产品经理必读:Anthropic 万字长文拆解,Agent 评估体系的“北极星”
在AI Agent赛道迅猛发展的今天,如何让产品不仅是Demo惊艳,更能经受真实场景的考验?Anthropic最新发布的《Demixifying evals for AI agents》为AI产品经理们提供了一套完整的评估体系框架。本文将深入解析Agent评估的六大核心要素,从代码评分器到人工评分策略,帮助产品团队构建真正可靠、可持续优化的AI Agent产品。

引言:你的 Agent,是“演示惊艳”还是“生产可靠”?
在 AI Agent 赛道狂飙突进的当下,每一个 AI 产品经理都在追问:如何确保我们精心打造的 Agent,不仅仅停留在 Demo 阶段的“哇塞”,而是能在真实业务场景中,持续创造价值,赢得用户信任?Anthropic 近期发布的重磅长文《Demystifying evals for AI agents》,无疑为我们点亮了一盏明灯。这不仅是一篇技术深度解析,更是一份面向 AI 产品经理的“Agent 评估实战手册”。本文将以最接地气的方式,为你拆解这份“万字长文”,提炼核心方法论,助你构建真正“能打”的 Agent 产品。
痛点直击:为什么你的 Agent 评估体系“形同虚设”?从“批改作业”到“观察实验”
Anthropic 一针见血地指出,许多 Agent 产品之所以陷入“演示即巅峰,上线即翻车”的窘境,根源在于缺乏一套系统且有效的评估体系。早期依赖“人肉测试”和“产品经理直觉”或许能快速验证 MVP,但一旦产品规模化,用户反馈的“AI 垃圾”(AI slop)和低质量输出,将迅速侵蚀用户信任,让你的产品陷入被动 。
更深层次的洞察是,随着 Agent 能力的增强,尤其是像 Opus 4.5 这样能发现政策漏洞、给出更优解的模型出现时,静态的评估标准将迅速失效。评估系统必须从传统的“批改作业”模式,进化为“观察实验”模式,以适应 Agent 的创造性和非确定性行为 。
一套健全的 Agent 评估体系,绝不仅仅是锦上添花,而是产品生命周期的核心驱动力:
- 风险前置,避免“事后救火”:在问题爆发前,通过评估机制发现并解决 Agent 的潜在缺陷和行为偏差,将风险扼杀在摇篮里。
- 数据驱动,告别“拍脑袋决策”:提供量化、可追踪的指标,让产品迭代有据可依,每一次优化都精准有效。
- 明确目标,统一“成功定义”:强制产品团队在 Agent 设计之初就明确其成功标准和预期行为,避免团队内部对“好 Agent”的理解偏差。
- 高效协同,打通“产研壁垒”:成为产品、研发和研究团队之间最高效的沟通语言,将前沿研究成果无缝转化为可优化的产品指标。
- 快速迭代,抢占“市场先机”:使团队能够迅速评估新模型、新算法的潜力,并快速将其集成到产品中,确保产品始终保持技术领先。
Agent 评估的“六脉神剑”:核心构成要素深度解析
Anthropic 将 Agent 评估体系拆解为以下核心构成要素,这为 AI 产品经理构建评估框架提供了清晰的蓝图 :

你的“评估天团”:三大评分器组合拳
Anthropic 建议,构建高质量的 Agent 评估体系,需要灵活运用三种评分器,形成“组合拳”效应 :
1. 代码评分器:Agent 的“硬核质检员”
适用场景:Agent 的基础功能验证、数据格式校验、工具调用的正确性、API 响应结构等硬性指标。
产品价值:确保 Agent 的“骨架”稳固,基础功能无懈可击。成本最低,效率最高,可无缝集成到 CI/CD 流程,实现自动化。
PM 视角:这是 Agent 产品质量的底线,必须确保。任何基础功能的 Bug,都可能导致用户体验的雪崩。
2. LLM 评分器:Agent 的“智能考官”
适用场景:处理开放式文本、模糊任务标准、对话质量、思路连贯性、用户意图理解等“软指标”。
产品价值:在保证一定效率的前提下,弥补代码评分器在语义理解上的不足。尤其适用于需要生成内容、进行复杂对话的 Agent。
PM 视角:这是提升 Agent“智能感”和“用户体验”的关键。但要警惕 LLM 的“幻觉”和偏见,务必建立人工校准机制,确保评估结果的可靠性。
3. 人工评分:Agent 的“终极体验官”
适用场景:评估 Agent 的“人性化”、创造力、处理复杂伦理问题,以及对用户体验的细微感知。
产品价值:提供最真实、最细致的用户反馈,是 LLM 评分器的“金标准”校准基准。在关键用户旅程和高风险场景中不可或缺。
PM 视角:虽然成本最高,但却是确保产品“温度”和“用户满意度”的最后一道防线。在产品上线前或重大功能迭代时,务必进行抽样人工评估。
应对“非确定性”:Pass@k 与 Pass^k 的产品策略
AI Agent 的一个显著特性是其行为的“非确定性”——即在相同输入下,每次运行可能产生不同结果。Anthropic 提出了两种关键指标,为产品经理提供了应对策略 :
1)Pass@k
在至少 k 次尝试中,至少有一次成功的概率。
产品策略:适用于用户可以接受重试、探索性较强的任务。例如,一个创意生成 Agent,用户可能愿意多尝试几次以获得满意的结果。
2)Pass^k
在所有 k 次尝试中,都需要成功的概率。
产品策略:适用于高风险操作、自动化流程或对用户体验一致性要求极高的核心功能。例如,一个金融交易 Agent,每一次操作都必须精准无误。
PM 启示:根据 Agent 的具体应用场景和用户对可靠性的容忍度,灵活选择评估指标。这不仅是技术决策,更是产品策略的体现。
不同类型的评估策略:进攻战与保卫战
Anthropic 强调,团队在评估 Agent 时常常混淆两种不同的策略,导致开发节奏混乱。清晰区分这两种策略至关重要 :
1. 能力评估 (Capability Evals) – 进攻战
目标:回答“这个 Agent 能做到什么?”旨在探索 Agent 的能力边界,挑战其极限。
特点:选择 Agent 目前觉得困难、经常失败的任务进行测试。即使通过率很低也无妨,这为团队设定了“登山目标”,指引未来的研发方向。
产品经理启示:用于新功能探索、模型升级后的能力验证,以及发现 Agent 的潜在应用场景。这是驱动产品创新的关键。
2. 回归评估 (Regression Evals) – 保卫战
目标:回答“这个 Agent 还能做它以前做过的事吗?”旨在确保 Agent 在新版本迭代后,不会出现功能退化。
特点:测试 Agent 过去已经成功完成的任务。通过率必须接近 100%,任何掉分都意味着新版本引入了 Bug。
产品经理启示:产品质量的“生命线”。每次迭代都必须进行回归评估,确保产品稳定可靠,维护用户信任。这是防止“盲飞”的关键。
3. 护栏评估 (Guardrail Evals)
目标:确保 Agent 的行为符合安全、伦理和政策要求,避免有害、不当或越界的内容生成和行为执行。
特点:专注于测试 Agent 在敏感话题、隐私保护、内容合规等方面的表现。通常需要结合人工审核和专门的检测机制。
产品经理启示:Agent 产品上线前的“安全审查”。在设计之初就应将护栏评估纳入考量,确保产品在提供价值的同时,也对用户和社会负责。
针对特定 Agent 类型的评估实践
Anthropic 还针对不同类型的 Agent 提供了更具体的评估建议 :
1. 编程 Agent (Coding Agents)
评估重点:对于编程 Agent,Outcome(代码功能正确性)只是及格线,Transcript(代码质量、实现过程)才是分水岭。不能只看代码能不能跑,还要看它写得“烂不烂”。
实战方法:采用“混合双打”策略。一方面,使用确定性评分器(如单元测试、集成测试)确保功能正确性;另一方面,引入静态分析工具(如 ruff, mypy, bandit)检查代码规范和潜在漏洞,并利用 LLM 裁判评估代码质量、思路连贯性,避免暴力试错和“屎山”代码的产生。
产品经理启示:在评估编程辅助工具时,不仅要关注其能否解决问题,更要关注其解决问题的“方式”和“质量”,这直接影响开发效率和维护成本。
2. 计算机使用型 Agent (Computer Use Agents)
评估重点:这类 Agent(如浏览器自动化、软件操作型 Agent)的评估需要搭建真实或沙盒环境,检查是否真正达成目标。
实战方法:利用“黄金轨迹”(Golden Trajectories),即人类专家操作 Agent 完成任务的录制路径。通过对比 Agent 的执行轨迹与黄金轨迹,评估其效率、准确性和鲁棒性。
产品经理启示:在设计自动化工作流 Agent 时,应充分考虑真实环境的复杂性,并利用人类专家的经验来指导评估设计。
AI Agent 评估体系的“增长飞轮”:实践路线图
Anthropic 提供了从零开始构建评估体系的实用步骤,为 AI 产品经理提供了清晰的执行路径 :
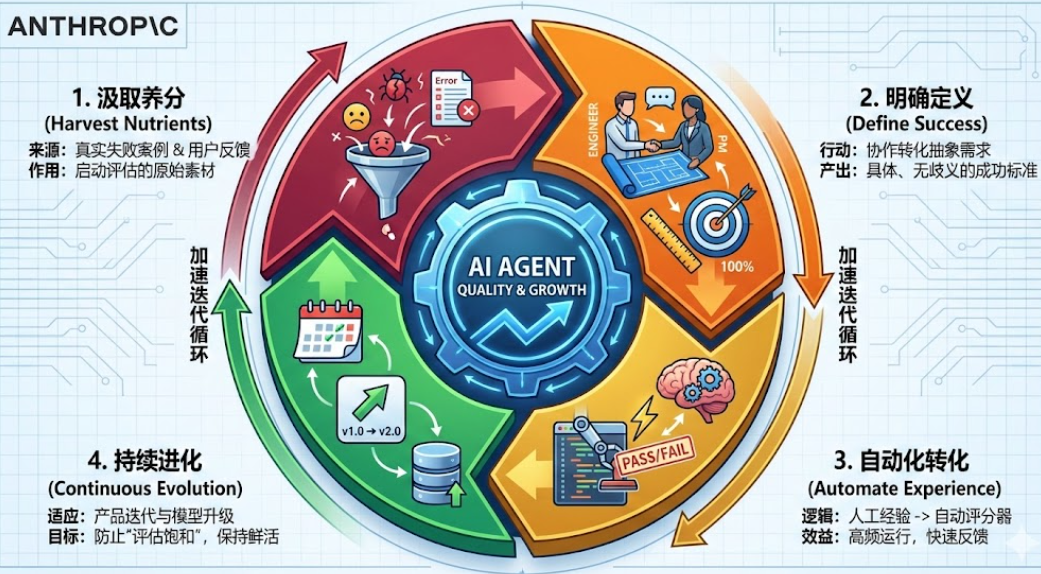
1.从“真实失败”中汲取养分:不要浪费任何一个用户反馈的 Bug 或内部测试的失败案例。这些都是构建初始评估集的宝贵财富。几十个真实案例,足以启动你的评估飞轮。
2.明确“成功”的定义:与工程师紧密协作,将抽象的用户需求转化为具体、可衡量、无歧义的成功标准。模糊的定义是评估失效的根源。
3.将“人工经验”转化为“自动化能力”:将手动测试和人工审核的逻辑,逐步转化为可自动执行的评分器。这能极大提升评估效率,让团队能够频繁运行评估,快速获得反馈。
4.持续“进化”你的评估套件:评估体系并非一劳永逸。随着产品迭代、功能更新和模型升级,评估套件也必须同步更新和扩展。确保评估信号始终能反映 Agent 的最新表现,避免“评估饱和”效应。
评估驱动开发:AI 产品经理的“新范式”
Anthropic 强调,“评估驱动开发”(Evaluation-Driven Development)是构建可靠 AI Agent 产品的核心理念。评估不再是开发流程的末端环节,而是贯穿始终,驱动产品设计、开发和迭代的“新范式” 。
产品设计:评估帮助 PM 将用户需求转化为 Agent 行为和可衡量指标。
开发迭代:评估为工程师提供快速反馈,加速 Bug 修复和性能优化。
持续优化:评估追踪 Agent 在生产环境的表现,捕获回归,指导产品优化方向,确保 Agent 持续进化。
结语:让科学的评估维度成为Agent 评估体系的“北极星”
在 AI Agent 竞争日益激烈的今天,谁能更早、更系统地建立起评估体系,谁就能在产品质量、用户信任和市场迭代速度上占据优势。让这套评估方法成为你 Agent 产品的“北极星”,指引产品不断前行,最终实现商业成功。
本文由 @AI漫步 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


