
 起点课堂会员权益
起点课堂会员权益解构多模态:跨越从“看懂”到“行动”的惊险一跃
多模态AI远不止是'能看懂图的聊天机器人',它正在将AI从抽象符号处理者转变为具象世界的理解者与行动者。这篇文章深度拆解了从感知融合到理解推理,再到具身智能的完整演进路径,揭示了多模态如何重构人机交互范式,以及产品经理在这场变革中需要扮演的全新角色。

最近和朋友聊天,发现大家对多模态的印象,基本都停留在“能看懂图的聊天机器人”这个层面。你给它一张图,它能给你讲个故事,或者你问它图里有什么,它能回答你。这没错,但这只是冰山一角,甚至可以说,这是一种普遍的误解,把一个可能重塑我们与世界交互方式的革命,看成了一次简单的功能升级。
我作为天天跟这些东西打交道的AI产品经理,心里总觉得有点憋屈,觉得这事儿没那么简单。多模态的真正威力,根本不在于让AI“会说话”或者“会看图”,而在于它正在把AI从一个处理抽象符号的“文科生”,变成一个能理解具象世界物理信息的“理科生”,甚至“工科生”。
你想想,我们人类是怎么理解世界的。我们看到一朵花,不仅是“看到”这个视觉信号,还会闻到它的香味,触摸到它花瓣的质感,听到风吹过花丛的声音,甚至联想到某个浪漫的瞬间。这才是完整的“理解”。
多模态要做的,就是让AI拥有这种跨越不同感官信息,形成统一认知的能力。它的终极目标,不是停留在“理解”层面,而是要跨越从“理解”到“执行”的鸿沟,让AI能够直接对物理世界进行交互和操作。
所以,别再把多模态当成聊天机器人的新皮肤了,它是一场关于AI如何真正“走进”我们世界的宏大叙事,而我们,正处在这场叙事的开篇。
01 多模态的感知与融合——世界如何被“数字化”
要让AI走进物理世界,第一步,得让它能“感知”到这个世界。这个过程,说白了,就是把五花八门的世界信息,翻译成机器能懂的语言。这里就得先掰扯清楚几个概念,不然很容易混。
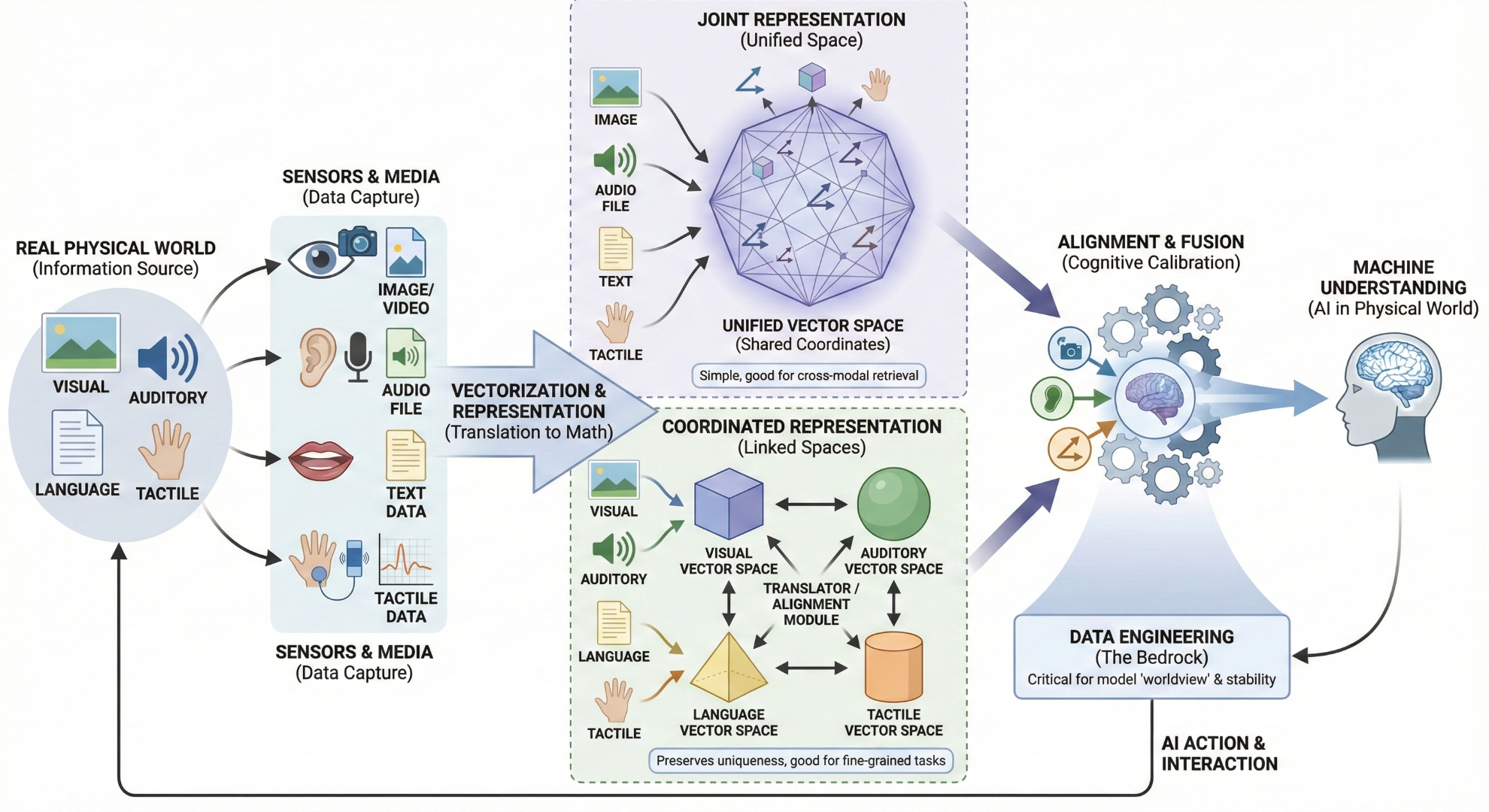
定义“模态”与“感知”
我之前看一篇关于多模态设计的思考文章,里面对这个定义讲得挺清楚的,我按我的理解复述一下。“模态”这个词,听起来很学术,其实就是信息存在的方式,比如视觉、听觉、语言、触觉这些。“感官”是我们人类接收这些模态信息的器官,眼睛看、耳朵听、嘴巴说。“媒介”是承载这些信息的载体,比如图片、声音文件、文字。
所以整个流程是:世界通过不同的“模态”呈现信息,我们通过“感官”接收,这些信息被记录在各种“媒介”上,最后AI来处理这些媒介。搞清楚这个关系,你就会发现,多模态AI要做的,就是模拟我们人类用多种感官协同工作的方式,去处理那些混杂在一起的图片、声音和文字。
如何“表示”世界
好,现在AI拿到了一堆图片、视频、声音文件,它怎么“看懂”呢?答案是“表示”,也就是把这些非结构化的数据,转换成机器能处理的数学形式——向量。你可以把向量想象成一个多维空间里的坐标,每个坐标都代表了原始信息在某个维度上的特征。比如,一张猫的图片,可能在“有毛”、“四条腿”、“可爱”这些语义维度上,都有特定的坐标值。
现在主流的表示方法,我看一些技术解析文章里提到了两种范式,我觉得挺有意思:
- 一种叫“联合表示”,就是不管三七二十一,把图片、文字、声音统统扔到一个巨大的“搅拌机”里,强制它们用同一种语言说话,也就是映射到同一个向量空间。这样做的好处是简单粗暴,便于模型进行跨模态的检索和生成,比如你输入文字“一只奔跑的狗”,它就能在那个统一的空间里找到最接近的图片向量。
- 另一种叫“协同表示”,这个就更精细一些。它承认不同模态有自己的“方言”,允许它们先在各自的小空间里自成体系,然后再通过一个“翻译官”来建立它们之间的联系。这种方式保留了每个模态的独特性,更适合做一些需要精细对齐的任务。
这两种思想,其实也反映了不同的人机交互设计哲学。“联合表示”追求的是一种无缝、统一的交互体验,而“协同表示”则更尊重不同信息渠道的差异性,允许更灵活、更定制化的交互。
如何“对齐”与“融合”
把世界表示成向量,只是第一步,真正的价值核心在于“对齐”与“融合”。单一模态的信息,价值是有限的。一张图就是一张图,一段声音就是一段声音。可一旦它们融合起来,价值就呈指数级增长。比如,视频里一个人在说话,视觉信息(口型、表情)和听觉信息(声音)一对齐,我们就能判断他是不是在假唱,或者情绪是不是真实。
这个“对齐”的过程,听起来很技术,我倒觉得它更像是一场宏大的“认知校准工程”。我之前做项目的时候就深有体会。我们想让模型学会判断一张图“有没有感觉”,这个“感觉”是什么?对人来说,这是一种直觉。对机器来说,这就是一堆像素点。我们的工作,就是把这种人类的直觉,拆解成模型可以学习的结构化标签。比如,我们会告诉模型,这种“感觉”可能来自于特定的构图方式、柔和的色调、逆光的光影效果等等。这个过程,就是把人类的认知和机器的表示进行“校准”。
这也就是为什么在这个阶段,“数据工程”往往比模型本身更关键。你喂给模型什么样的“世界观”,它就会长成什么样。没有好的数据,再强的模型也只是空中楼阁。这部分工作,说白了,枯燥、繁琐,但它决定了多模态大厦的地基有多稳固。
02 多模态的理解与推理——从“看到”到“懂得”的惊险一跃
如果说“感知”和“融合”是打地基,那么“理解”和“推理”就是在这片地基上盖起高楼大厦。这是当前技术突破最集中的地方,也是商业化应用时风险最高、最容易翻车的环节。从“看到”像素,到“懂得”像素背后的意义,这一跃,真的挺惊险的。
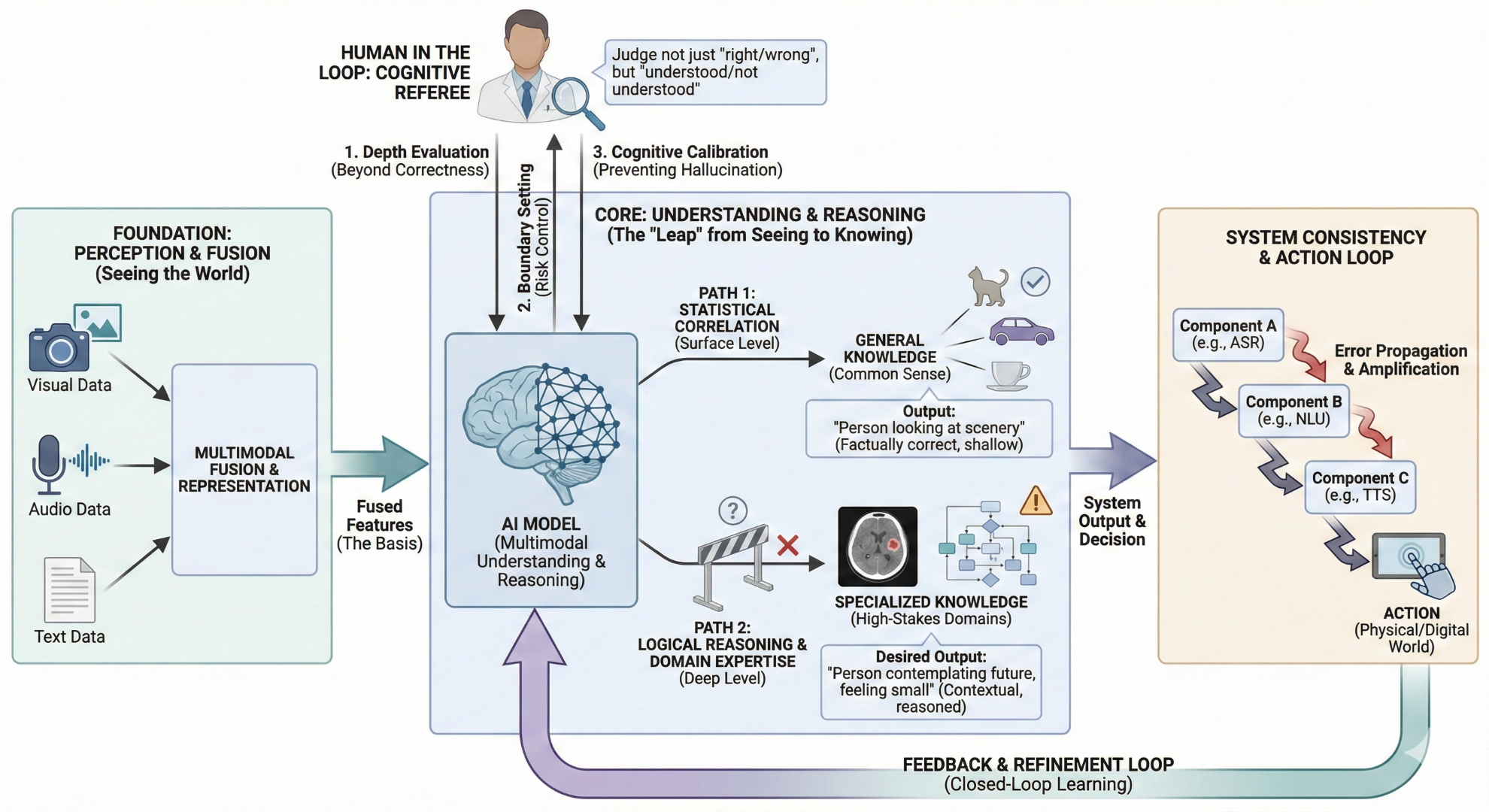
理解的飞跃与局限
在一些通用的、常识性的图文理解任务上,比如看图说话、识别常见物体,我们国内的顶尖模型已经不输国际先进水平了,甚至在某些中文场景下还有优势。这确实是个巨大的飞跃,说明我们的模型已经具备了基础的世界知识。
但一到专业领域,短板就暴露无遗。比如,让模型去看一张医疗影像,判断里面有没有病灶,或者分析一张复杂的工业流程图,找出异常环节。这时候,模型的表现就急转直下。为什么会这样?原因很简单,它在通用数据里“看到”过无数猫猫狗狗,但它没“见”过几张真正的CT片。它的“理解”是基于海量数据的统计规律,而不是真正的逻辑推理和专业知识。这就引出了一个很现实的问题:模型的“理解”和我们人类的“懂得”,到底是不是一回事?目前来看,还不是。
“人”作为认知裁判
这就不得不提“人”在这个环节中扮演的关键角色。很多人以为,在AI时代,人的工作就是给机器喂数据,做个“标注工”。在多模态理解这个环节,人的角色远不止于此。我们是“认知裁判”。
当模型对一张图片给出一个回答时,我们的工作不是简单地判断“对”或“错”。我们要判断的是,这个回答是“语法正确但理解偏差”,还是“真正看懂了”。举个例子,你给模型一张“一个人在悬崖边上眺望远方”的图片,问它这个人什么心情。模型可能会回答:“这个人正在看风景”。这个回答语法正确,也符合事实,但它没有“懂”。一个更好的回答可能是:“这个人可能在思考未来,也可能感到孤独和渺小”。这才是带有“理解”的回答。我们作为产品经理或者数据标注的管理者,就要引导模型去学习后者,而不是满足于前者。
更重要的是,我们要为模型的理解“定边界”。要告诉它,在什么情况下可以自由发挥,在什么情况下必须给出精确、保守的答案。尤其是在医疗、金融这些高风险领域,一个“似是而非”的理解,可能会造成无法挽回的后果。防止这种错误的理解成为模型的学习范式,是我们作为“认知裁判”最重要的责任,也是产品风险控制的核心。
系统一致性的挑战
对了,还有个事情想说,就是系统链路上的问题。当多模态能力被集成到一个真实的产品里时,它往往不是一个单一的模型在工作,而是一个级联的系统。比如一个智能客服,它可能先用一个语音识别模型把你的话转成文字,再用一个自然语言理解模型去分析你的意图,最后用一个语音合成模型把回答说出来。
这个链路上的每一个环节,都可能产生误差。语音识别错了一个字,理解环节可能就谬以千里,最后合成出来的回答就牛头不对马嘴。这种误差的层层放大效应,在多模态系统里尤其严重。因为模态越多,链路就越长,不确定性就越大。这也是为什么,单纯提升某一个模型的能力是不够的,必须从系统层面去考虑一致性和鲁棒性。这也自然而然地把我们引向了下一个话题:光“理解”还不够,AI必须学会“行动”,通过行动的结果来验证和修正自己的理解,形成一个闭环。
03 多模态的决策与行动——迈向物理世界的具身智能
聊到这里,我们其实已经触及了多模态的终极形态。如果说感知和理解是AI在“学习”这个世界,那么决策和行动,就是它开始“改造”这个世界。这就是具身智能,Embodied AI。这是多模态逻辑的必然延伸,也是这篇文章我想升华的重点。
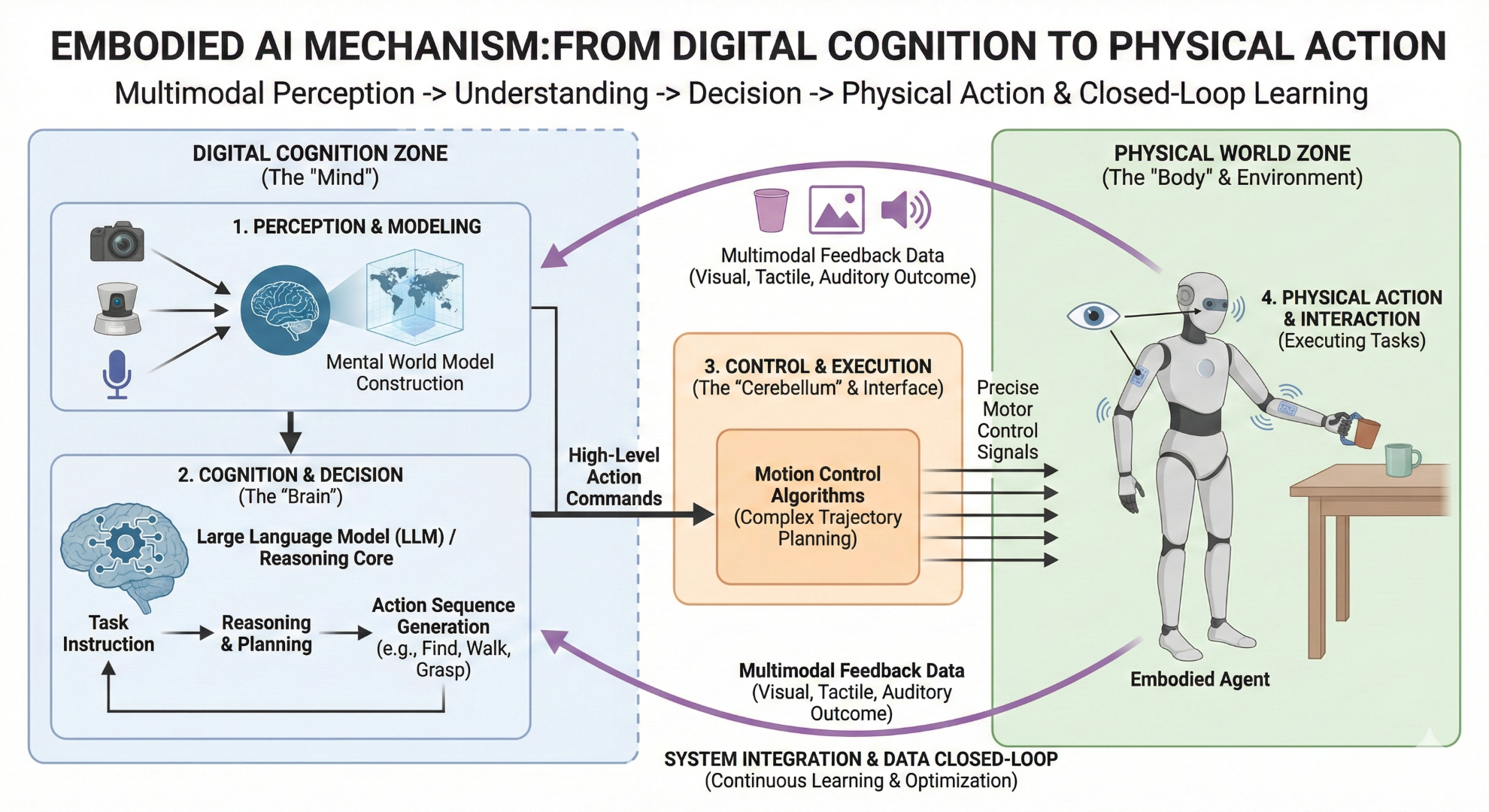
从“数字”到“物理”
很多人把具身智能看作是AI的一个新分支,我觉得这个看法不太准确。它不是一个平行的分支,而是多模态技术树上长出来的顶端果实。它是“感知-理解-决策-行动”这个完整链条的终点。没有前面的多模态感知和理解,行动就是无源之水。没有最后的行动,所有的理解都只是纸上谈兵,无法在物理世界中得到检验和闭环。
所以,具身智能的本质,就是让AI拥有一个“身体”,让它能够通过这个身体去执行任务,去与环境互动,从而真正地、物理地存在于我们这个世界。这才是从数字世界到物理世界最彻底的跨越。
技术框架解析
具身智能听起来很科幻,但它的技术框架其实已经越来越清晰了:
- 第一个支柱是“感知与建模”。这就是我们前面花大量篇幅讨论的多模态感知能力,机器人通过摄像头、激光雷达、麦克风等传感器,收集环境信息,然后在自己的“脑子”里构建一个关于世界的“心智模型”。
- 第二个支柱是“认知与决策”。这部分,现在普遍认为大语言模型可以扮演“大脑”的角色。它负责理解任务指令,基于对环境的建模,进行推理、规划,并生成一系列需要执行的动作步骤。比如,你对机器人说“帮我倒杯水”,它的大脑就需要把这个指令分解成:找到杯子、走到饮水机旁、拿起杯子、接水、把水杯拿给你等一系列子任务。
- 第三个支柱是“控制与执行”。如果说大模型是“大脑”,那这部分就是“小脑”和“肢体”。它负责将大脑发出的高层指令,翻译成精确的电机控制信号,驱动机器人的手臂、腿脚去完成具体的物理动作。这个过程需要非常复杂的运动控制算法,来保证动作的平稳、精准和安全。
- 最后一个支柱,也是让整个系统能够不断进化的关键,是“系统集成与数据闭环”。机器人执行任务的整个过程,包括它看到的、听到的、做的,都会被记录下来,形成新的数据。这些数据又会被用来优化它的感知模型、决策模型和控制模型,让它下一次做得更好。这就是一个完整的学习闭环。
应用与壁垒
理论框架有了,实际落地怎么样了呢?其实我们身边已经有具身智能的雏形了。最典型的例子就是自动驾驶汽车,比如那些“萝卜快跑”之类的无人车。它就是一个轮式机器人,通过全身的传感器感知路况,用“大脑”决策如何行驶,用“小脑”控制方向盘和油门刹车,在真实的物理世界里执行驾驶任务。
更前沿的,就是那些人形机器人了。它们的目标是在更复杂的、非结构化的环境里,完成更通用的任务。当然,理想很丰满,现实的瓶颈也很突出。
一个核心瓶颈就是“身体”本身。高性能、低成本的核心零部件,比如灵活的机械手、高效的能源系统,目前还非常昂贵,技术也不够成熟。另一个瓶颈是“小脑”,也就是运动控制。在实验室里走走路、挥挥手还行,一到复杂多变的真实环境,比如一个堆满杂物的房间,如何保持平衡、如何灵巧地避开障碍,都是巨大的挑战。还有一个难题,是“仿真到真实”的迁移。我们可以在模拟器里训练机器人千百万次,但模拟器和真实世界总是有差距的。如何让机器人在虚拟世界里学到的“技能”,能够无缝地应用到现实中,这是一个至今没有完美解决的问题。这些壁垒,也正是未来几年,无数工程师和科学家需要去攻克的山峰。
04 趋势与展望:通往2026年的人机协同生态
聊了这么多技术细节和挑战,我们不妨站得高一点,看看未来几年,多模态技术会把我们带向何方。结合我看到的一些趋势报告和自己的观察,我感觉一条清晰的技术演进图景正在浮现。
就像《银翼杀手2049》那样的未来世界,很快就会到来。
交互范式的革命
这个演进过程,最终将带来一场深刻的交互范式革命。过去几十年,我们一直在学习如何使用机器的语言,我们学习点击、滑动、输入命令。我们作为产品经理,大部分时间都在“设计界面”,设计按钮放在哪里,流程怎么跳转。
多模态技术的发展,将彻底颠覆这一点。未来,我们将不再需要去适应机器,而是机器来适应我们。交互将回归人类最自然的状态,用语言、用眼神、用手势。到那时,产品经理的角色也会发生根本性的变化。我们可能不再是“界面设计师”,而是“认知翻译官”。我们的核心工作,是理解用户的真实意图,并将这种复杂的、模糊的、跨感官的意图,“翻译”成机器能够理解和执行的任务。我们要设计的,不再是界面,而是认知本身。
多模态,是一场关于如何“理解世界”的漫长跋涉。写到最后,想回归到最初的那个问题:多模态到底是什么?聊了这么多,从技术到应用,从现状到未来,我感觉它本质上是一场持续性的、关于如何“理解世界”的漫长跋涉。这场跋涉的核心任务,就是如何将我们人类对这个世界的多感官、整体性的认知,稳定、高效、安全地“翻译”给机器。并且,最终让机器能够基于这种翻译过来的“世界观”,在真实的物理世界中,做出“笃定”的行动。
这个过程充满了挑战,每一步都像是在走钢丝。从像素到语义,从理解到推理,从数字模拟到物理执行,每一步都是一次“惊险的一跃”。对于我们这些身处其中的互联网从业者来说,多模态绝不仅仅是一个新的技术热点或者功能模块。它是一种底层的力量,正在从根基上重塑我们设计产品的方式、我们与用户交互的方式,甚至是我们构建商业模式的方式。理解它,跟上它,甚至去引领它,可能就是我们未来几年最重要的功课。
这趟跋涉,才刚刚开始。
本文由 @高乐 AI 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供









读完心潮难平!原来冰冷的代码,正生出温暖触角,这趟从冰山到星辰的旅程,实在震撼人心。