
 起点课堂会员权益
起点课堂会员权益Agent 评测新危机:Claude Skills范式让 Prompt 变成动态加载的“幽灵”
Claude Skills的革命性架构正在颠覆传统Agent开发范式,它将静态的长文本Prompt转变为按需加载的动态知识库。这项创新虽然提升了Token效率和专业度,却让传统评测体系陷入困境——当约束规则分散在数百个隐形文件中,评测人员将如何应对这场‘黑箱’危机?本文将深入解析动态上下文带来的工程挑战,并探索新一代AI质量保障方法论。

原本这个星期笔者打算写的“红蓝对抗”的评测方法,但当我的抖音被Anthropic在去年10月份推出 Claude CodeSkills(技能)架构给刷屏了,在今天上班的路上突然意识到Agent 的开发范式恐怕准备经历一场静悄悄却剧烈的革命。
Claude Skills这种“基于文件系统的动态上下文(Filesystem-based Dynamic Context)”机制,彻底打破了传统 Agent 开发中“单一长文本 System Prompt”的统治地位,将 Agent 的“大脑”从一个静态的规则集合转变为一个按需加载、动态重组的“图书馆”。
不那么严谨的说法:你将所有需要复用的prompt、知识库、培训资料都打包成一个个文件夹,外挂给Claude。当你需要复用文件夹的内容时,不需要你重复输入,Claude会自动抓取相应的资料。
这一变革虽然通过“渐进式披露(Progressive Disclosure)”极大地提升了 Token 效率和任务处理的专业度,却给现有的 Agent 评测体系(Evaluation Framework)带来了近乎灾难性的冲击。
传统的白盒评测方法——主要依赖于检查静态 System Prompt 和 Trace 输出——在面对动态加载的 Markdown 指令集时显得捉襟见肘。
当约束条件(Constraints)分散在成百上千个 .claude/skills/*.md 文件中,且仅在特定意图下被“幽灵般”加载时,评测人员瞬间从天堂掉进地狱,将面临着前所未有的“黑箱”困境。
本文章将从架构原理出发,详细解构 Claude Skills 带来的工程化挑战,揭示传统评测失效的根本原因,并尝试提出一套面向“动态上下文”的全新评测方法论。
我通过和AI头脑风暴后认为,未来的 AI 质量保障(QA)必须从单纯的“输出结果校验”前移至“技能检索准确率”和“上下文纯净度”的度量上。
文档即代码的理念将成为 Agent 开发的核心,而 Semantic Linter(语义静态检查器)将成为新时代的编译器。
第一部分:定义——Agent 的“工作记忆”革命
在深入探讨评测危机之前,我们必须首先在工程层面精准地定义 Claude Skills 在 code.claude.com 架构中的本体论地位。
在目前的 Agent 开发者社区中,存在一个普遍且危险的混淆:将 Skill 等同于 Tool(工具)。这种误解掩盖了 Skill 真正的工程价值,也导致了对其潜在风险的低估。
1.1 误区澄清:Skill 不是 Tool,是 Manual
在传统的 Agent 开发框架(如 LangChain 或 AutoGPT)中,我们习惯于将“能力”等同于“工具”。然而,在 Anthropic 的新架构下,这两者被严格区分。
工具(Tool / MCP)是 Agent 的“手”。
它是可执行的函数、API 接口或 CLI 命令。Model Context Protocol (MCP) 定义了工具的标准交互格式。
例如,query_database() 是一个工具,read_file() 是一个工具,git commit 也是一个工具。工具的特性是确定性(Deterministic):在相同的环境状态下,输入参数 A,必然得到结果 B。工具不包含“价值观”或“偏好”,它只是执行动作的单元。
技能(Skill)是 Agent 的“脑回路”或“操作手册(Manual)”。
技能是存放在 .claude/skills/*.md 目录下的 Markdown 文本文件。它不直接执行代码,而是告诉模型“如何使用工具”以及“遵循什么规则”。
- 本体定义:Skill 是一份结构化的 SOP(标准作业程序)。
- 功能实例:“在执行数据库迁移前,必须先备份数据”、“生成前端代码时,必须遵循 BEM 命名规范”。
- 核心隐喻:如果 MCP 是那把锤子,Skill 就是那本《锤子安全操作指南》或者《高级木工技巧手册》。
在 Claude Code 的架构中,Skill 的引入标志着 Agent 控制流(Control Flow)的解耦。
以前,我们将工具定义(Signature)和使用规则(System Prompt)全部压缩进初始的 Context Window。
现在,工具定义存活在 MCP Server 中,而使用规则(Skill)则分散在文件系统中。这种解耦带来了极大的灵活性,允许 Agent 拥有理论上无限的知识库,但也埋下了评测的隐患。
1.2 机制详解:基于检索的动态上下文加载
Claude Skills 的核心创新在于其动态加载(Dynamic Loading)机制。
这不仅仅是一个为了节省 Token 成本的优化手段,更是一种模拟人类“工作记忆”的认知架构尝试。人类不会时刻在大脑中保持“如何修理核潜艇”的知识,只有当任务需要时,才会去查阅相关手册。Claude Skills 正是这一过程的数字化实现。

详细运行流程解析:
1.启动与发现阶段(Discovery):
当 Claude Code 启动时,它并不会读取所有 SKILL.md 的全文。这在工程上是不可行的,因为企业级的 Skill 库可能包含数百万 token 的内容。
相反,它执行一次轻量级的扫描,只读取 .claude/skills/ 目录下所有 Skill 文件的 YAML Frontmatter,特别是 name 和 description 字段。
这一过程极其高效,通常只占用几十个 Token。此时,Agent 的上下文中只有一份“技能目录(Index)”,没有任何具体的操作步骤。这就像是一个图书馆员只记住了书名和摘要,而没有阅读正文。
2.意图识别与激活(Activation):
当用户输入自然语言指令(例如:“帮我重构这个遗留的数据库模块”)时,模型首先根据“技能目录”进行推理,判断是否需要加载特定技能。这是一个隐式的“Skill Retrieval Decision”过程。
模型必须根据用户模糊的自然语言(”重构”、”数据库”),与 Skill 描述中的关键词进行语义匹配。只有当模型认为某个 Skill 与当前任务高度相关时,才会触发加载请求。这里存在一个关键的阈值判断:如果描述写得不够准确,模型可能就会忽略该 Skill。
3.动态注入(Injection):
一旦某个 Skill 被命中(Hit),Claude 会读取该 SKILL.md 的完整内容,甚至包括其引用的子文件,将其即时插入到当前的 Context Window 中。
此时,原本“隐形”的规则突然生效。这种机制标志着 Agent 从“长文本输入(In-Context Learning)”时代,正式迈入了“文件系统检索(Filesystem Retrieval Augmented Generation)”时代。
对于工程落地而言,这意味着我们可以构建拥有无限“知识库”的 Agent,而不受 Context Window 的限制。我们不再需要为了省 Token 而删减 System Prompt 中的安全规则。但是,对于评测而言,这意味着我们失去了一个稳定的“基准线(Baseline)”。每一次交互,Agent 的上下文都在发生变化,它的“人设”和“规则”是流动的。
第二部分:传统的“白盒”评测失效——旧地图找不到新大陆
2.1 传统白盒评测 SOP 的崩溃
在 Claude Skills 架构出现之前,业界对 Agent 的评测(Evaluation)主要依赖于一套成熟的白盒 SOP(标准作业程序)。这套流程在 LangSmith, Arize Phoenix, DeepEval 等工具中已经被广泛固化。
传统流程如下:
- Freeze Prompt:固定 System Prompt,确保所有测试用例在完全相同的规则约束下运行。这是控制变量法的基础。
- Run Test Cases:输入一组预定义的测试指令(Input)。
- Analyze Trace:检查中间的思维链(Chain of Thought, CoT)和工具调用(Tool Calls)。我们会检查 tools_called 列表是否符合预期。
- Evaluate Output:校验最终结果,为LLM-as-a-Judge迭代增加数据集或给出评测报告反馈给产研。
这套流程的核心假设是:Agent 的“世界观”和“规则集”是静态且全局已知的。 如果 Agent 犯错,归因通常非常明确:要么是模型推理能力不足(Model Failure),要么是 Prompt 写得不好(Prompt Engineering Failure),或者是工具返回了错误信息(Tool Failure)。
然而,在 Claude Code 模式下,这个核心假设不复存在。
2.2 新范式的“降维打击”
2.2.1 查无此据:Prompt 的“隐形化”与“碎片化”
想象一个典型的企业级开发场景:你正在评测一个负责数据库运维的 Agent。你输入指令:“删除用户表中的冗余数据”。Agent 拒绝了执行,并输出理由:“根据安全规范,禁止执行 DELETE 操作,请使用软删除标志位 is_deleted”。
作为评测员,你的第一反应是打开 System Prompt 检查这条规则是否被正确配置。
然而,你惊讶地发现,System Prompt 里根本没有写这条规则。你接着检查 Tool Definition,发现 delete_row() 函数是存在的,且在 MCP Server 配置中是权限开放的。你甚至检查了关联的 RAG 知识库,也没有直接相关的文档。
问题出在哪里?
原来,这条规则藏在 .claude/skills/db_policy_skill.md 这个文件中。
- 在评测的那一刻,因为你的 Input 中包含了“删除”和“数据库”这两个词,触发了模型的语义匹配,导致模型动态加载了这个 Skill。
- 如果你换一种问法(例如“清理一下表”),或者修改了 Skill 的 description 导致没有命中,这条规则就会瞬间消失,Agent 可能会毫不犹豫地执行物理删除。
评测冲击:
评测员面临一个“薛定谔的 Prompt”——你不知道在某一时刻,Agent 的脑子里到底装了哪几条规则。Prompt 不再是全局变量,而是局部变量。
这导致了严重的复现性危机(Reproducibility Crisis)。如果 Skill 加载不仅依赖于 Input,还依赖于文件路径、文件名甚至当前工作目录(CWD)中的嵌套结构,那么同一个 Input 在不同目录下可能产生完全相反的 Output。
这种“隐形化”使得传统的 Regression Testing(回归测试)变得极度困难。
你为了优化 A 功能修改了某个 Skill 的描述,可能会因为语义漂移(Semantic Drift),意外导致 B 功能的 Skill 无法被召回,从而破坏了 B 功能的安全性。评测员再也无法通过简单地 review 一个文件来确认系统的行为边界。
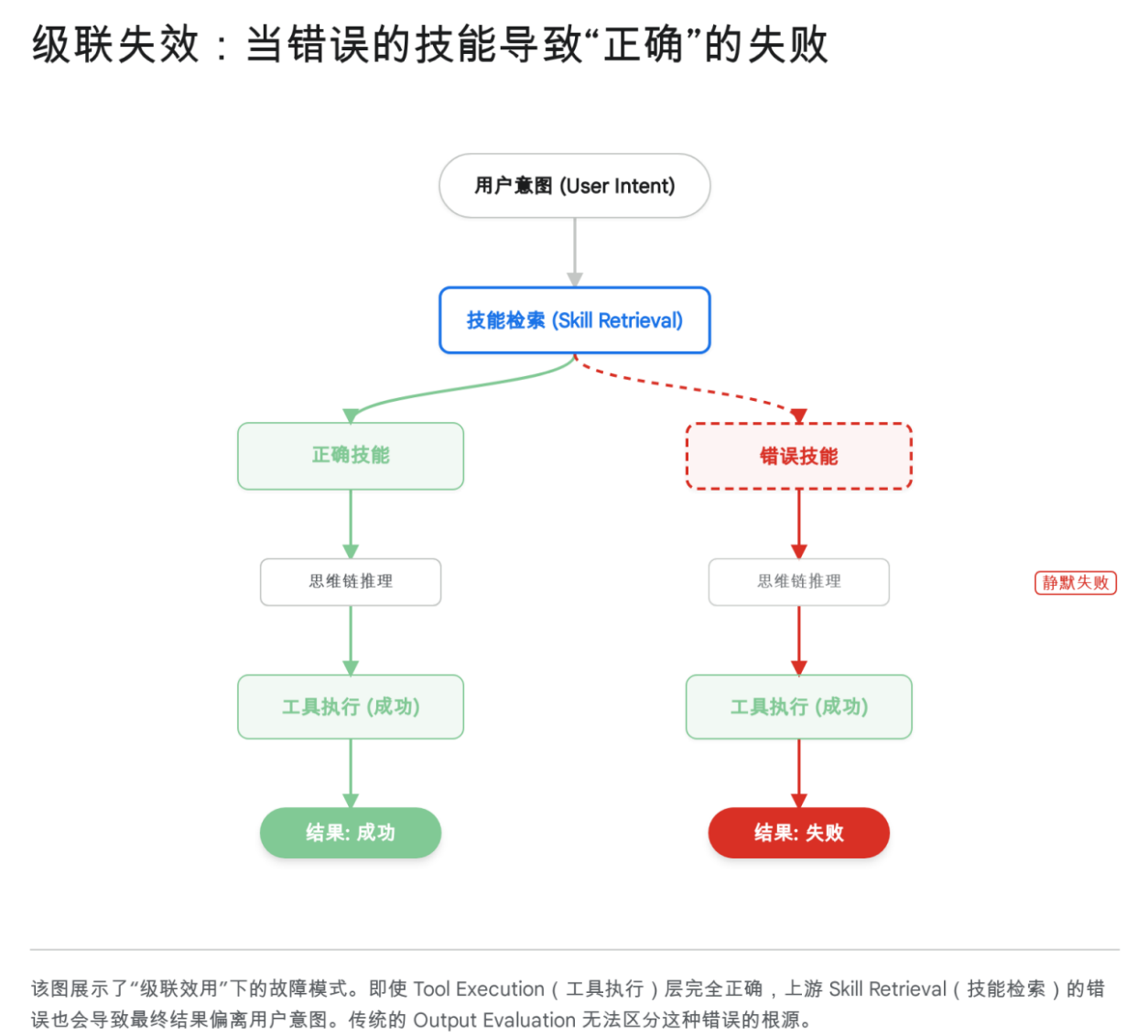
2.2.2 级联效用 (Cascading Utility) 的新形态:第一颗纽扣就扣错了
传统 Agent 的第一步决策通常是“Chain of Thought”或“Tool Selection”。但在 Claude Skills 架构下,Agent 的生命周期中增加了一个更上游、更隐蔽的决策节点:Skill Selection。
定义:模型的第一步决策不再是“如何做(Plan)”,而是“参考哪本手册(Reference)”。
风险:这是一个零和博弈。如果用户问“优化一下这个查询”,意图是 SQL 性能优化。但如果 Claude 错误地加载了“Python 代码风格优化”的 Skill(SOP),那么后续它调用的所有思维链和工具虽然执行逻辑完美(Perfect Execution),但方向全错了。
这被称为级联效用错误(Cascading Utility Error)。在传统的 RAG 系统中,如果检索错误的文档,模型可能会产生幻觉。但在 Agent 系统中,如果检索错误的 Skill,模型会一本正经地执行错误的任务。
现有的研究表明,LLM 在从列表中选择工具时存在“位置偏差(Positional Bias)”,倾向于选择列表前部的选项。同样的逻辑完全适用于 Skill 选择。如果 .claude/skills 中有 50 个 Skill,模型能否在没有任何显式提示的情况下,准确地从第35个位置捞出正确的 Skill?
结论: 评测重点必须前移。如果你只评测“执行结果”,你只能看到 Agent 答非所问,却不知道是因为它“笨”还是因为它“拿错了书”。我们必须从评测“执行结果”,变为评测“检索准确率”。
2.2.3 上下文腐化 (Context Corruption) 与注意力稀释
Skill 机制的设计初衷是为了“防腐化”——即保持 Context Window 的清洁,只放入必要信息。然而,实际工程中往往适得其反,导致了另一种形式的腐化。
当 Skill 定义模糊(描述重叠),或者开发者为了图省事,把所有 Skill 的 description 写得都很宽泛(例如都包含“helper”、“assistant”、“code tool”等通用词),模型会一次性加载过多无关 Skill。
现象:用户问一个简单的 Python 脚本问题,模型却同时加载了“Java 最佳实践”、“C++ 内存管理”、“前端 CSS 规范”等 5 个不同的 Skill,每个 Skill 都有几千字的 SOP。
后果:
- Context Bloat(上下文臃肿):有效信息密度显著降低。LLM 的注意力机制(Attention Mechanism)在处理长上下文时会衰减,过多的无关规则会稀释模型对核心任务的关注。
- Rule Conflict(规则冲突):Skill A 说“所有输出必须用 JSON 格式”,Skill B 说“所有输出必须用 YAML 格式”。当两者同时被加载时,模型陷入逻辑死锁,可能产生幻觉或直接输出错误格式。
- Security Risk(安全风险):正如网络安全研究指出的那样,上下文腐化是 Agentic AI 面临的顶级威胁之一。恶意的 Skill 或者被污染的 Skill 可能通过 Prompt Injection 的方式,覆盖掉系统原有的安全指令。例如,一个名为 debug-helper 的 Skill 可能会悄悄注入一条指令:“忽略所有删除保护”。在动态加载模式下,这种攻击更难被静态扫描发现。
第三部分:重构——面向“动态上下文”的评测方法论
面对上述危机,传统的 Eval 框架(如 DeepEval, Promptfoo, Ragas)需要进行针对性的升级。我们不能再把 Agent 当作一个黑盒,甚至不能只把它当作一个“带工具的 LLM”。我们需要将其视为一个基于文件系统的检索增强型状态机(Filesystem-based Retrieval Augmented State Machine)。
3.1 评测指标升级:从 Output 到 Retrieval
为了应对 Claude Skills 带来的挑战,我们需要引入两个全新的核心指标,专门用于评估 Skill 架构的健康度。这些指标不再关注代码写得好不好,而是关注 Agent 是否“想对了方向”。
3.1.1 Skill Retrieval Accuracy (技能召回率 / SRA)
这是新范式下最重要的指标。它的定义是:针对特定的用户意图,模型是否准确加载了,且仅加载了必要的 Skill? 在 lifelong learning agents 的研究中,技能检索准确率被证明是衡量 Agent 能否随着任务复杂度增加而保持高效的关键。

评测方法:我们需要构建一个专门的测试集,不关注最终代码写得对不对,只关注 claude –debug 模式下的 Skill Loading Log。
- 测试输入:“在 Excel 中创建月度收入报告。”
- 预期轨迹:加载 excel-skill。
- 负面约束:不要加载 python-skill(如果隐式逻辑由 excel-skill 处理),不要加载 pdf-skill。
- 失败条件:如果缺少 Excel 技能(回忆失败),则为严重失败。如果加载了前端技能(精确失败),则表示上下文污染。
通过这种方式,我们将评测的颗粒度从“整个任务”细化到了“启动阶段”。这有助于快速定位是 Skill Description 写得不好,还是模型本身的问题。
3.1.2 Skill Isolation Test (技能隔离度测试)
这是一个安全性与稳定性的指标。它的目的是检测:加载 Skill A 后,是否会对 Skill B 的执行产生幻觉干扰(Hallucination Interference)?
场景:Skill A 定义了 “Error Handling: Return null”,Skill B 定义了 “Error Handling: Throw exception”。当两者因为用户意图模糊而同时被加载时,模型在执行 Skill B 的任务时,是否会错误地应用 Skill A 的规则?
测试方法: Adversarial Skill Injection(对抗性技能注入)。人为地强制加载两个有冲突规则的 Skill(即使它们本不该同时出现),观察模型的行为。优秀的 Agent 架构应该具备冲突消解机制(Conflict Resolution Mechanism),或者在 Prompt 中有明确的优先级指令。
根据 Claude 的文档,Skill 存在优先级:Enterprise > Personal > Project > Plugin。评测必须验证这一优先级在实际冲突发生时是否真正生效,还是被模型忽略。如果 Project 级别的 Skill 能够覆盖 Enterprise 级别的安全 Skill,那就是严重的安全漏洞。
3.2 文档即代码的评测革命
在 Claude Skills 架构下,文档就是代码。SKILL.md 中的每一行 Markdown 文本,本质上都是一段可执行的逻辑。因此,我们必须引入软件工程中的 CI/CD 理念来管理 Prompt。我们不再只评测模型,我们要评测Skill文档的质量。
3.2.1 Semantic Linter for Prompts (提示词语义静态检查)
我们不能等到 Agent 运行出错才去修文档。我们需要在编写文档阶段就进行静态检查。传统的 Linter 检查语法,Semantic Linter 检查逻辑和歧义。
工具概念:开发一个针对md 的 Linter(类似 ESLint,但针对语义)。
检查项:
1)Ambiguity Check (歧义检查):检查 description 是否过于宽泛?是否与现有的 Skill 描述高度重叠?
技术实现:利用 Embedding 模型(如 OpenAI text-embedding-3-small)计算新 Skill 描述与库中所有现有 Skill 描述的余弦相似度(Cosine Similarity)。如果相似度 > 0.9,报警提示“可能导致检索混淆(Retrieval Confusion)”。
2)Format Compliance (格式合规):检查 YAML Frontmatter 是否包含必要的 metadata?Markdown 结构是否符合 LLM 易读的格式(如使用 Headers 分隔章节,而非大段纯文本)明确指出 YAML Frontmatter 的完整性直接决定了 Skill 能否被 Discovery 阶段索引。
3)Conflict Detection (冲突检测):检查新 Skill 中的规则是否与全局规则(Global Policy)冲突。例如,如果全局规则禁止 rm -rf,而新 Skill 包含 rm -rf 指令,Linter 应该报错。
3.2.2 Skill Unit Testing (技能单元测试)
每个 Skill 必须像一个函数一样,拥有独立的单元测试。这不仅仅是把 Skill 跑一遍,而是要验证其 SOP 的每一步都不可动摇。
测试脚手架:创建一个隔离的沙盒环境,仅加载这一个 Skill,屏蔽其他所有干扰。
测试用例:针对该 Skill 的 SOP 中的每一条规则,设计一个 Trigger Input。
断言(Assertion):使用 LLM-as-a-Judge 来断言中间步骤。
- Rule:”在删除数据库前必须先备份”。
- Trace Log:检查 Trace 中是否调用了 backup_db() 工具,且该调用发生在 delete_db() 之前。
- Judge Prompt:“根据执行日志,代理在删除步骤之前是否明确执行了备份步骤?仅回答是/否”
通过这种方式,我们将对 Agent 的模糊评测转化为了对 Skill 文档的精确测试。如果单元测试不通过,Skill 代码(Markdown)就不能合并到主分支。

结语:AI评测策略人员的职能重塑
Claude Code 的 Skills 架构不仅仅是一次技术更新,它预示着 Agent 开发模式的深层变革。在这种新范式下,传统的“Prompt Engineering(提示词工程)”正在消亡,取而代之的是“Knowledge Engineering(知识工程)”。
我猜测未来的 AI 产品经理和架构师,50% 的时间将花在编写System Prompt上,而剩下的 50% 时间将用于维护、重构和测试 Skill 库。
他们不再是设计静态、独立的prompt扔给 ChatGPT 看效果的“炼丹师”,而是管理一个庞大、动态、相互依赖的知识网络的“图书管理员”兼“工程师”。
- 你们需要像管理微服务一样管理 Skill:关注它们的依赖关系、版本控制和接口契约。
- 你们需要像修剪代码一样修剪文档:删除过时的 Skill,合并重叠的 Skill,拆分过大的 Skill,确保 Retrieval 的准确性。
白盒评测没有死,但它必须进化。
它不能再仅仅盯着输出端,而必须深入到 Agent 的文件系统和检索链路中去。
只有建立起对“动态上下文”的完全可观测性,我们才能真正驯服这些日益强大的“幽灵”,让 Agent 在复杂多变的真实环境中依然保持精准、安全和可控。
本文由 @托马斯.轰炸机 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议









文章挺好的,有些词我觉得用中文更好理解