
 起点课堂会员权益
起点课堂会员权益AI产品经理必读,DeepSeek最新论文:当AI学会不思考,一个改变游戏规则的发现
DeepSeek的最新研究揭示了AI架构设计的重大突破:通过引入条件记忆模块,让AI学会区分需要深度思考的复杂问题和可直接检索的固定知识。这项技术不仅将事实查询响应速度提升至近乎瞬时,更意外地释放了模型的推理潜力——记忆模块接管基础模式识别后,注意力机制能专注全局理解,使长文本处理和多步骤推理能力获得质的飞跃。本文从产品视角深入解析这一架构革新如何重构AI系统的效率边界。

上周,有一位做AI客服的朋友Mark,找我聊他们遇到的一个问题,他们的客服系统处理用户问题平均要2.1秒,看起来不算慢,但是,这2秒多里面,有80%的时间都花在处理那些每天重复一百遍的破问题上——什么”你们周末营业吗”、”退货流程是啥”、”支持哪些支付方式”,这种问题他们每天都要被问上百次。
他的第一反应就是让技术优化模型呗,压缩参数啊,升级硬件啊。结果技术组长问了他一句话,把他问懵了。技术组长说:”Mark,咱们是不是一开始思路就错了?这种问题,AI有必要去’思考’吗?它直接记住答案不就行了?”
我一听,眼睛一亮:”诶,你这个问题来得太巧了!我前两天刚看了DeepSeek在今年1月新发的一篇论文,讲的就是这个事儿。”
Mark一听来了精神:”什么论文?快说说。”
我说:”你先别急,我给你好好讲讲。说实话,我一开始看这论文的时候,也觉得又是那种常规的模型优化套路,这种论文咱们见太多了。但看着看着,我发现它提出的问题特别本质——你说的这个情况,不就是在让AI干它不擅长的活儿吗?”
插入论文信息:
论文名称:《Conditional Memory via Scalable Lookup:A New Axis of Sparsity for Large Language Models》,这份论文由DeepSeek与北京大学合作完成,梁文锋是作者之一。它系统性地提出了一种名为 “条件记忆 (Conditional Memory)” 的新稀疏化维度,并开源了其核心实现模块 Engram。
咱们先说个最简单的道理
我接着跟Mark说:”你想想,人脑是怎么工作的?比如我问你,北京是中国首都吗?”
Mark:”那肯定是啊,这还用想?”
“对啊!”我说,”你看,你回答这个问题,脑子里根本没有’思考’这个过程吧?就是直接从记忆里调出来的,0.2秒就完事了。但如果我问你,怎么解决三四线城市的就业问题,你是不是得琢磨琢磨?得综合分析、逻辑推理,对吧?”
是不是会让你想起来,快思考和慢思考。
Mark点点头:”这不废话吗,肯定不一样啊。”
“问题就在这儿!”我拍了下桌子,”人脑处理这两种问题,用的根本就不是一套系统。简单的事实,走的是记忆检索,快速、准确;复杂的分析,走的是深度思考,慢但灵活。但你再看看咱们现在的AI产品,不管是’周末营业吗’还是’分析这份商业计划书’,全都是调用那三十层神经网络,从头推理一遍。”
Mark若有所思:”你这么一说,确实挺不合理的。就好比我每次想知道1+1等于几,都得拿草稿纸重新算一遍?”
“就是这个意思!”我说,”DeepSeek的这帮人,他们就发现了这个问题。语言处理任务其实分两种:一种是高度结构化的固定知识,像专有名词、常用短语、标准表达,这些东西本质上就是个查找问题;另一种才真正需要上下文相关的动态推理。但现在的Transformer架构,没有专门的知识查找模块,只能通过层层计算来’模拟’记忆检索。这不是脱了裤子放屁吗?”
DeepSeek做了什么?给AI装了两个”大脑”
Mark问:”那他们怎么解决的?”
我说:”简单说,就是给AI装了两套系统。一个叫Engram的记忆模块,专门存储固定知识,查询速度特别快,几乎是瞬时的。另一个就是原来的深度推理引擎,继续处理复杂分析。两套系统各干各的活,不打架。”
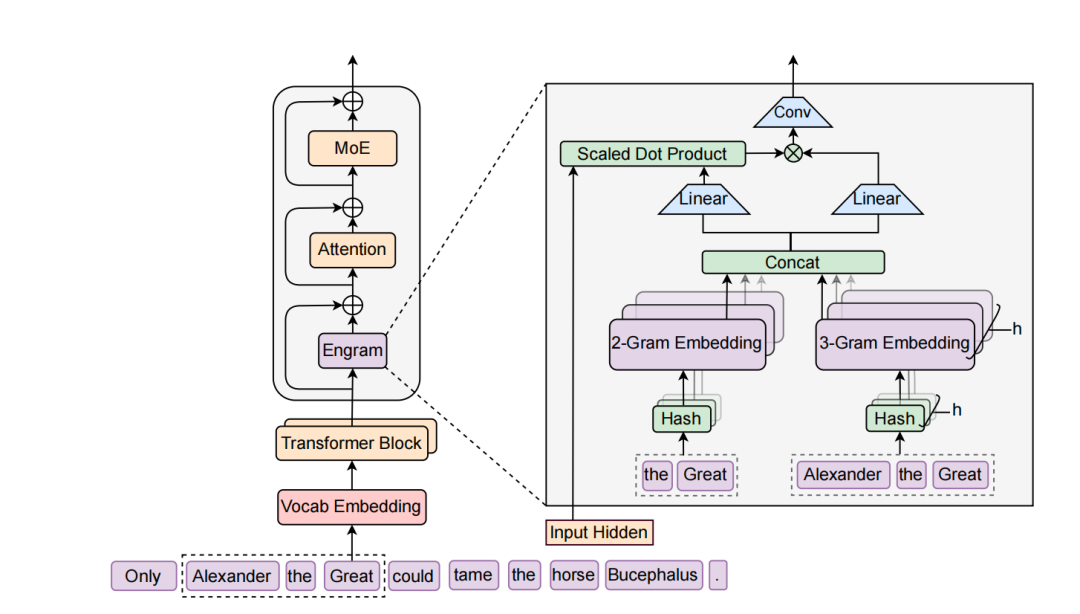
“你看这个架构图,”我指着屏幕说,”左边是标准的Transformer层——Vocab Embedding、Engram、Attention、MoE这样叠起来。关键看右边这个放大的Engram模块。”
我给Mark解释:”输入是’Alexander the Great’这个短语。系统会把它拆成2-gram(’the Great’)和3-gram(’Alexander the Great’),然后通过哈希函数分别查找对应的嵌入向量。这些向量concat在一起后,不是直接用,而是要经过那个’Scaled Dot Product’——就是用当前的隐藏状态作为Query,跟检索到的记忆做匹配,算出一个权重。最后再过一个轻量的卷积层增强表达能力。”
“听起来不错啊,”Mark说,”但具体怎么实现的?”
我给他解释:”技术细节其实挺巧妙的。他们用了一个叫N-gram的老技术——就是根据前面几个词预测下一个词的统计模型,这玩意儿上世纪就有了。但他们做了很多现代化改造。系统维护一个超大的嵌入表,存各种常见的词组搭配。当模型处理输入时,通过哈希函数快速查找相关记忆,时间复杂度是O(1),也就是说不管记忆库多大,查询时间都是固定的。”
Mark:”等等,这不就是个超大号的查找表吗?那遇到歧义怎么办?同一个词组在不同语境下意思可能完全不一样啊。”
“好问题!”我说,”他们设计了一个很聪明的机制,叫’上下文感知门控’。简单说,就是用当前的上下文信息作为查询条件,跟检索到的记忆内容做匹配,算出一个0到1之间的权重。如果记忆内容跟当前上下文很匹配,权重就接近1,系统就用这个记忆;如果不匹配,权重接近0,系统就忽略它,改用推理能力。既保证了记忆检索的速度,又有根据上下文动态调整的灵活性。”
Mark眼睛亮了:”这个设计确实漂亮。那效果怎么样?”
意外的发现:记忆反而让推理更强了
我喝了口咖啡,接着说:”这才是最有意思的地方。他们一开始觉得,这个记忆模块主要帮助知识类任务嘛,像事实性问答、知识检索这种。结果测出来,知识任务确实提升了,MMLU提升3.4个百分点,中文知识测试提升4.0个百分点。”
“这不是预期之内吗?”Mark说。
“等等,”我摆摆手,”重点在后面。他们发现,在需要复杂推理的任务上,提升反而更大!复杂推理任务BBH提升了5.0个百分点,逻辑推理ARC提升了3.7个百分点,代码生成提升3.0个百分点,数学问题提升2.4个百分点。你想想,这些任务明明需要的是推理能力不是记忆,为什么加了记忆模块反而变强了?”
Mark愣了一下:”对啊,这不科学啊。”
“他们后来用了两种分析工具去研究这个现象,”我说着打开电脑,”我给你看看这个分析图。”
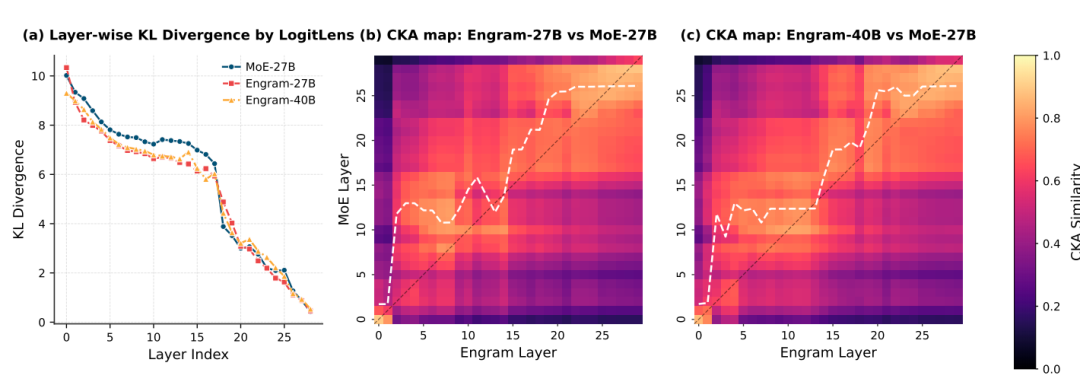
“你看这张图,”我指着屏幕左边,”第一个工具叫LogitLens,就是把模型每一层的输出都投影到最终的输出空间,看看它跟最终答案的差距有多大。这个KL散度越小,说明这一层的表示越接近最终答案。”
Mark凑近看:”三条线分别是MoE-27B、Engram-27B和Engram-40B?”
“对,”我说,”你注意看前面的层,比如0到10层这段。Engram的两条线(红色和橙色)明显比MoE的蓝线要低,而且下降得更快。这说明Engram模型在前几层就能形成接近最终答案的表示了,而传统MoE模型要到中后期才慢慢收敛。”
“所以记忆模块帮模型在早期就建立好了基础表示?”Mark说。
“没错!但更直观的是右边这两个热图,”我指着中间和右边的图,”这是用CKA(一种表示相似度度量)来比较Engram模型和MoE模型各层之间的相似度。横轴是Engram的层数,纵轴是MoE的层数。颜色越亮(黄色),说明两层的表示越相似。”
Mark仔细看:”这个白色虚线是什么意思?”
“这条线就是关键,”我说,”如果两个模型完全一样,这条线应该是45度对角线——也就是第1层对应第1层,第10层对应第10层。但你看Engram的这条线,它明显往上偏移了。比如Engram的第5层,对应的是MoE的大概第12层。”
Mark恍然大悟:”也就是说,Engram用5层就干完了MoE模型12层的活?”
“对头!”我拍了下桌子,”相当于’免费’多出来7层深度。原本MoE的前12层都在忙着组合基础特征、识别固定模式,现在Engram的记忆模块直接把这些工作接管了,从第3层开始就可以做高层推理。盖楼的比喻特别贴切——传统模型1到10层打地基,11到30层才盖主体;Engram直接地基做好了,从第3层就开始盖主体,当然最后能盖得更高。”
Mark点点头:”这个可视化太直观了。从热图上看,那条白线的上移幅度还挺稳定的,说明这个’深度增益’是系统性的,不是某几层的偶然现象。”
“你看得很准,”我说,”而且注意看Engram-40B(右图)的线,偏移得更明显。这说明记忆容量越大,这个效果越强。这也解释了为什么推理任务反而提升更大——因为推理任务最需要’深度’,而Engram恰好提供了额外的有效深度。”
“他们后来用了两种分析工具去研究这个现象,”我说,”发现了原因。第一个工具叫LogitLens,可以看模型每一层的输出跟最终答案有多接近。结果发现,用了Engram的模型,在前几层就能形成接近最终答案的表示了,而传统模型要到中后期才慢慢收敛。”
“所以记忆模块帮模型在早期就建立好了基础表示?”Mark说。
“没错!”我说,”第二个工具叫CKA,用来比较不同模型各层的相似度。结果更明显:Engram模型第5层的表示,跟传统模型第12层的表示高度相似。也就是说,Engram用5层就干完了传统模型12层的活,相当于’免费’多出来7层深度,这些深度全可以用在更高层次的推理上。”
Mark拍了下大腿:”我明白了!就像盖楼,传统模型1到10层都在打地基,11到30层才开始盖主体。Engram直接把地基做好了,从第3层就开始盖主体,当然最后能盖得更高。”
“对头!”我说,”还有个发现也很重要。传统模型的注意力机制得同时处理两件事:局部的固定模式识别,比如认出’by the way’这种短语;还有全局的语义关系。现在局部模式交给记忆模块了,注意力就能100%专注在全局理解上。这在长文本处理上特别明显。”
“有多明显?”Mark问。
“他们测试32k token长度的文档,”我说,”多文档信息检索准确率从84.2%提升到97.0%,变量追踪从77.0%提升到89.0%。这可不是小幅改进,是从’勉强能用’到’非常可靠’的质变。”
一个黄金比例:75/25法则
Mark问:”那按照这个思路,是不是应该尽量多搞记忆,少用计算?”
“这就是他们做的另一个很有价值的实验,”我说,”他们想搞清楚:在总参数固定的情况下,应该怎么分配记忆和计算的比例?”
“怎么测的?”
“他们设计得很严谨,”我说,”总参数量固定,比如27B;每个token的计算量也固定。然后就调一个变量:在MoE专家(提供计算能力)和Engram记忆(提供存储能力)之间改变分配比例。用一个参数ρ表示,ρ=100%就是全部用于计算,ρ=0%就是全部用于记忆。”
“结果呢?”Mark很好奇。
“画出来是个非常明显的U型曲线,”我比划着,”ρ=100%的时候,就是纯计算方案,验证损失是1.7248。随着加入记忆,性能开始提升,到ρ大约75-80%的时候达到最优,验证损失降到1.7109。继续增加记忆比例,性能反而下降,到ρ=40%又回到1.7248的水平了。”
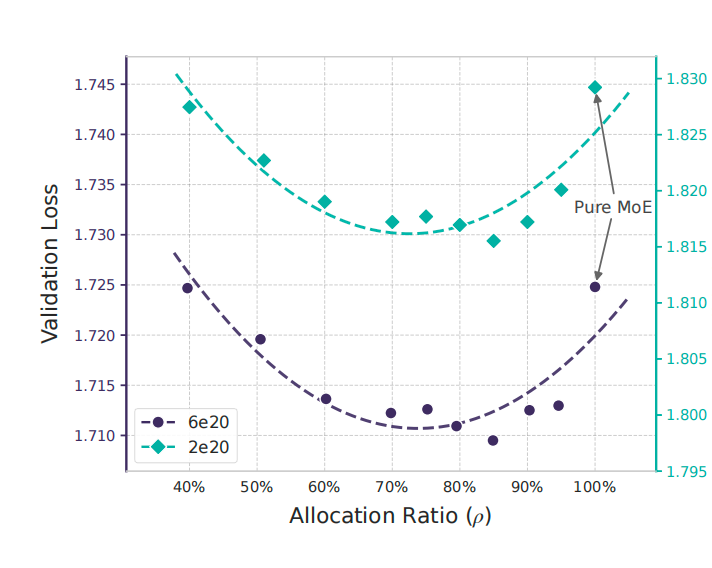
“你看这个曲线,”我把电脑转向Mark,”两条线分别代表不同的计算预算(2e20和6e20 FLOPs),但U型的模式是一样的,最优点都在75-80%这个区间。这说明这个比例反映了语言任务的内在结构。”
Mark仔细看着图:”所以极端都不行。纯计算浪费了深度去重建固定知识,纯记忆又缺乏推理能力。”
“对!还有个有意思的,”我切换到另一张图,”他们还测试了如果不限制记忆容量,持续扩大会怎样。”
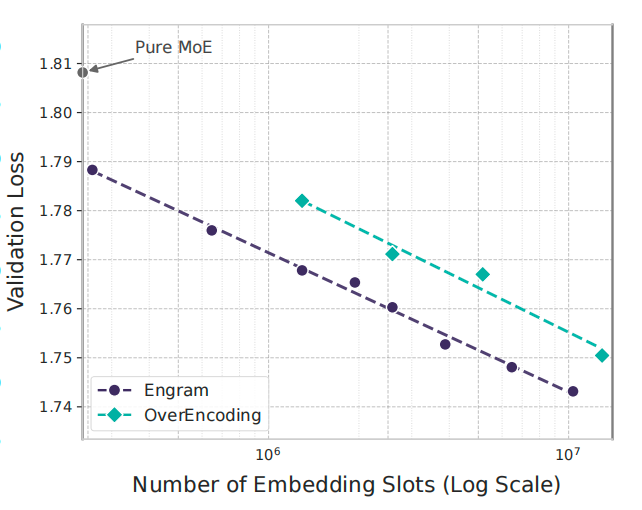
“看这条对数线性的曲线,”我指着屏幕,”横轴是记忆槽位数量(对数刻度),从100万到1000万,纵轴是验证损失。Engram这条黑线持续下降,而且是稳定的对数线性关系。这意味着记忆容量是一个可预测的scaling knob——你投入更多记忆,就能获得可预测的性能提升,而且不需要增加计算量。”
“所以最优比例是75%计算、25%记忆?”Mark总结道。
“对,而且这个比例在不同规模的模型上都很稳定,”我说,”不管是小规模实验还是大规模实验,最优点都落在这个区间。这说明啥?说明这个比例可能反映了语言任务的内在结构:大概20-25%的内容可以通过记忆直接处理,75-80%需要动态推理。”
Mark若有所思:”这个比例对产品设计太有指导意义了。”
设计中的关键选择:哪些细节真正重要?
Mark若有所思:”这个比例对产品设计太有指导意义了。不过我还有个问题,如果我要实施这个架构,是不是每个设计细节都很关键?比如你刚才说的上下文门控、记忆库放在哪一层,这些会不会影响很大?”
“好问题!”我说,”DeepSeek团队做了一系列消融实验,就是为了搞清楚哪些设计选择真正重要。我给你看个图。”
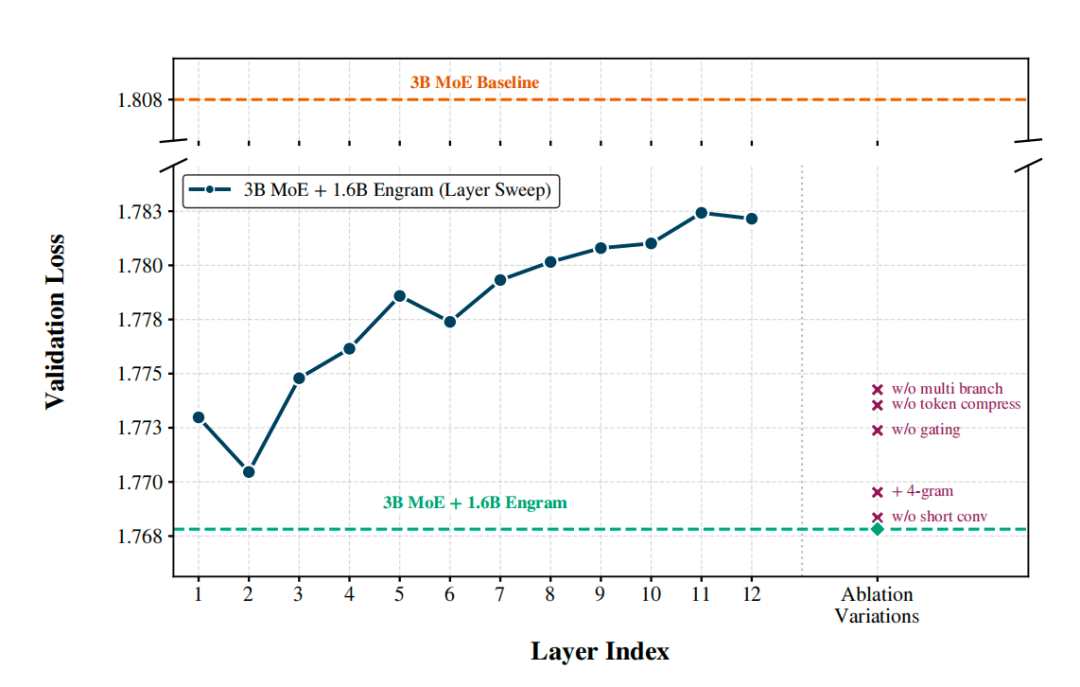
“这个图特别有意思,”我指着屏幕,”分两部分看。左边这条蓝色曲线是’层敏感性测试’——他们把一个固定大小的Engram模块(1.6B参数)放在不同的层,从第1层到第12层扫一遍,看哪个位置效果最好。”
Mark看着图:”第2层最优?验证损失大概1.770,但第1层反而是1.773?”
“对,这就是有意思的地方,”我说,”你可能觉得应该越早越好吧?但第1层不如第2层。这是为什么呢?因为第1层的时候,隐藏状态还没经过任何attention,上下文信息几乎为零,那个门控机制没法有效工作。到了第2层,经过一轮attention后,隐藏状态已经包含了一些上下文信息,门控就能准确判断哪些记忆该用、哪些不该用。”
“那为什么越往后放效果越差呢?”Mark问,”不是上下文越丰富越好吗?”
“这就是另一个权衡了,”我解释,”你看这条曲线,从第2层开始,随着层数加深,性能持续下降。到第10层以后,已经接近baseline了。原因是:如果记忆模块放得太深,模型前面的层已经花费了大量计算去重建那些固定知识——也就是说,记忆模块来得太晚了,该浪费的计算已经浪费了,起不到’节省深度’的作用。”
Mark恍然大悟:”所以这是个平衡。太早了,上下文不够用;太晚了,计算已经浪费了。第2层刚刚好。”
“对头,”我说,”但你注意,这还不是全局最优方案。曲线最低点是1.770,但图上有条虚线在1.768——那是什么呢?那是他们把同样1.6B参数分成两个小模块,分别放在第2层和第6层。这样既保证了早期介入,又在中期获得了更强的门控能力。”
“分层放置,各取所长,”Mark总结道。
“没错。再看右边这些标记点,”我指着右侧,”这是组件消融——就是把某个子模块去掉,看性能掉多少。你看这几个紫色叉号,每个代表去掉一个组件。”
Mark凑近看:”‘w/o multi branch’、’w/o token compress’、’w/o gating’这几个掉得最厉害?”
“对,”我说,”去掉multi-branch integration(多分支融合),loss从1.768涨到接近1.773,说明跟主干的融合方式很重要。去掉token compression(词表压缩),也有类似幅度的损失。去掉gating(门控机制),基本就废了,接近baseline。”
“这几个都是你刚才讲的核心设计,”Mark说。
“对,但你注意有些组件影响不大,”我指着另外两个点,”比如’+ 4-gram’和’w/o short conv’。加入4-gram反而略微变差(因为在固定预算下,4-gram稀释了2-gram和3-gram的容量);去掉短卷积层也只是略微下降。”
“所以不是所有设计都同等重要,”Mark若有所思,”如果我要简化实施,可以先不考虑4-gram和卷积层?”
“完全可以,”我说,”实际上这个图给产品经理一个很好的指引:优先级排序。第一优先级是门控机制、词表压缩、多分支融合这三个;第二优先级是层位置选择(确保在第2-3层介入);第三优先级才是那些锦上添花的东西。”
Mark拿出手机拍了张图:”这个太有用了。我回去设计方案的时候,可以先实现核心三件套,其他的后面迭代。”
“对,而且这个实验还告诉你一件事,”我说,”就是在固定1.6B记忆预算下,单层放在第2层能做到1.770,双层分散能做到1.768。提升不大,但如果从系统角度考虑——比如利用多层来做预取、利用缓存——分层放置可能有额外的工程价值。”
你的场景适合这个方案吗?
“明白了,”Mark说,”设计选择要同时考虑模型效果和系统效率。不过我还有个问题——”他停顿了一下,”你讲的这些优势,是不是对所有场景都有效?还是说某些场景特别适合,某些场景其实不太需要?”
“这个问题问到点子上了,”我赞许地点点头,”DeepSeek专门做了一个实验来回答这个问题。他们把训练好的Engram模型的记忆模块完全关闭,看看不同任务的性能会保留多少。如果保留得多,说明这个任务主要靠backbone就能完成,不太依赖记忆;如果保留得少,说明这个任务高度依赖Engram。”
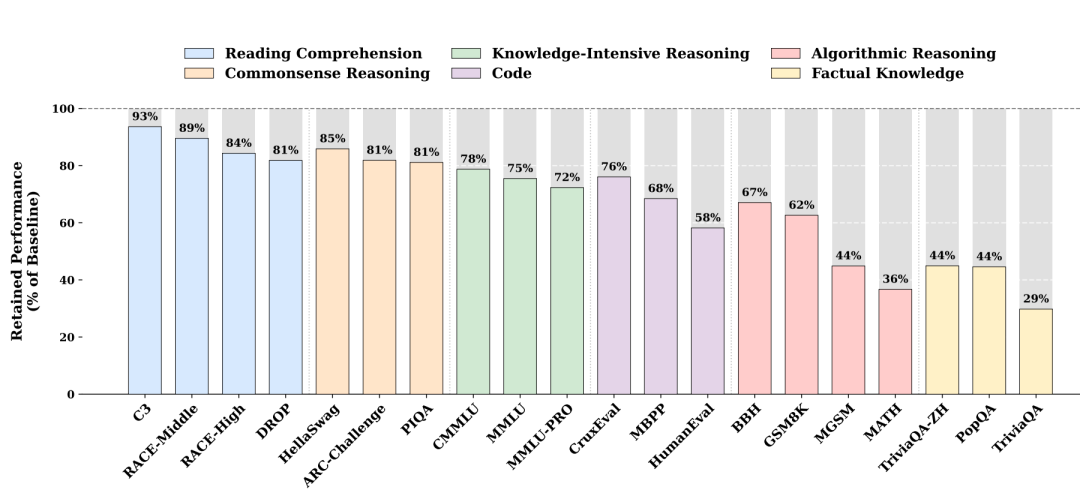
“你看这个柱状图,”我展开屏幕,”横轴是各种测试任务,纵轴是关闭Engram后保留的性能百分比。不同颜色代表不同任务类型:蓝色是阅读理解,橙色是常识推理,黄色是事实知识,绿色是知识密集推理,紫色是代码,粉色是算法推理。”
Mark仔细看着图:”差异挺大的啊。最左边的C3(阅读理解)保留了93%,但最右边的TriviaQA(事实知识)只保留29%?”
“对,这就是关键,”我说,”你看不同颜色柱子的高度差异。蓝色的阅读理解任务,像C3、RACE-Middle、RACE-High、DROP,都保留了80%以上的性能,最高93%。
这说明阅读理解主要靠backbone的语言理解能力,记忆模块的贡献不大。”
“为什么呢?”Mark问。
“因为阅读理解是上下文依赖的,”我解释,”给你一篇文章,问你文章讲了什么、作者的观点是什么,答案就在文章里,不需要额外的外部知识。这种任务天然适合attention机制,记忆帮不上什么忙。”
“明白了,”Mark点头,”那事实知识呢?黄色那几根柱子特别矮。”
“对!这才是Engram的主战场,”我指着右边的黄色柱子,”TriviaQA只保留29%,TriviaQA-ZH保留44%,PopQA也是44%。这说明事实知识类任务对Engram的依赖度极高——关掉记忆模块,性能直接腰斩甚至更惨。”
Mark眼睛亮了:”这不正好对应我们的客服场景吗?我们那60%的高频查询,本质上都是事实性问题——’周末营业吗’、’退货流程是什么’、’支持哪些支付方式’。
按这个图的逻辑,我们的场景对Engram的需求应该是最强烈的。”
“完全正确!”我说,”你们的客服系统就是这张图里黄色柱子代表的场景。现在你关闭Engram(也就是不做架构改造),就相当于只保留29-44%的性能。反过来说,引入Engram,你能获得的提升空间是原来的2-3倍。”
“那中间这些呢?”Mark指着绿色、紫色、粉色的柱子,”看起来保留的性能在50-80%之间。”
“这些是中度依赖,”我说,”比如知识密集推理,像CMMLU、MMLU、MMLU-PRO,保留72-78%。这类任务既需要知识,又需要推理,所以关掉记忆后,推理能力还在,只是缺了知识支持,性能打折扣。”
“代码任务也是中度依赖?”Mark看着紫色柱子。
“对,CruxEval保留76%,MBPP保留68%,”我说,”代码任务对固定模式(比如API调用、语法结构)有一定依赖,但核心还是逻辑和算法理解。所以Engram有帮助,但不是决定性的。”
“算法推理呢?”Mark指着粉色柱子,”这几个柱子高低不一啊。”
“对,算法推理类任务的依赖度差异很大,”我说,”BBH保留67%,还算可以;GSM8K保留62%,说明数学计算对固定模式(比如数字、符号)有中等依赖;但MGSM只保留44%,MATH只保留36%。这可能是因为这些任务涉及更多的专业符号和表达方式,记忆帮助更大。”
Mark沉思了一会儿:”所以如果我来总结,Engram最适合的场景是:事实知识查询占比高、固定模式多、答案确定性强。对吧?”
“太精准了,”我赞道,”你可以拿这个作为决策标准。评估你的业务场景时,问三个问题:第一,有多少查询是事实性的?第二,有多少内容是固定模式?第三,答案的确定性有多高?如果这三个答案都是’很多’、’很高’,那就是Engram的理想场景。”
“反过来,”Mark接着说,”如果我的业务主要是开放式的创意生成、文学创作、或者完全依赖上下文的对话,那Engram的帮助可能就没那么大。”
“对,”我说,”比如你要做一个写作助手,帮用户写小说、写诗,这种场景主要靠backbone的生成能力和创意,Engram帮不上什么忙。但如果是写商务邮件、技术文档、产品说明,里面有大量固定的术语、模板、表达方式,Engram就很有用了。”
Mark拿出手机拍了这张图:”这张图对我的价值可能比前面所有图都大。因为它直接告诉我:我的场景是不是Engram的最佳应用场景。现在我可以非常确定地说,客服系统的事实查询场景,正是Engram最擅长的。”
“而且这张图还有个隐藏价值,”我说,”它可以帮你规划产品路线图。你可以先从最依赖Engram的场景开始改造——也就是那些事实查询,快速见效;然后逐步扩展到中度依赖的场景——比如需要一些领域知识的分析任务;最后再考虑那些低依赖的场景。”
“分阶段实施,降低风险,”Mark总结道。
“对。而且每个阶段的ROI是清晰的,”我说,”事实查询场景,Engram能贡献50-70%的性能提升;知识密集推理场景,能贡献20-30%;纯推理或创意场景,可能只有5-10%或者不需要。你可以根据ROI排优先级。”
说回你的客服系统
“好了,”我看了看时间,”理论、数据、场景适配性都讲清楚了。现在最实际的问题是:你回去怎么开始第一步?我给你讲个真实案例,去年我一个朋友做的项目,跟你的情况很像。”
“什么项目?”Mark来了兴趣。
“一家大型制造企业的内部知识管理系统,”我说,”6000多份技术文档,员工每天问2000多次问题。一开始用的是标准RAG架构——你知道的,先检索相关文档,然后让大模型生成答案。平均响应时间2.秒。”
“跟我们一样慢,”Mark说。
“问题就在这儿,”我说,”工人在车间最常问的就是’设备X的安全距离是多少’、’这个螺栓扭矩标准是多少’、’换班检查清单有啥’。这些问题答案都是确定的数字和流程,但系统每次都要检索文档、理解文档、生成答案,白白浪费2秒多。”
“后来怎么改的?”
我说:”他们先分析了那2000次查询,发现可以分三类。第一类是事实性查询,占60%,就是你说的那种’周末营业吗’、’退货流程是啥’,答案固定。第二类是分析性问题,占25%,需要综合判断。第三类是混合型,占15%,既要查事实又要分析。”
“然后呢?”
“针对这三类设计了不同的处理机制,”我说,”第一类问题,他们建了个结构化知识库,把所有确定性的信息抽出来建索引。这个库不是简单关键词匹配,而是理解语义的,比如’螺栓紧固力矩’和’拧螺丝要用多大劲’会映射到同一个知识点。系统识别出是事实性查询后,直接从知识库返回,响应时间降到0.4秒。”
“60%的查询直接解决了,”Mark眼睛发亮。
“对!第二类问题保留原来的RAG+LLM流程,因为确实需要深度推理。第三类问题,先从知识库提取事实,再送给LLM分析,比让LLM从头检索文档高效多了。”
“最终效果呢?”Mark问。
“整体平均响应时间从2.3秒降到0.9秒,60%的查询在0.5秒内完成,”我说,”更关键的是准确率,从74%提升到89%。因为事实性问题不再经过LLM生成,避免了’理解偏差’或’过度推理’。运维成本也降了40%左右,因为大部分查询不用调大模型了。”
Mark激动了:”这个思路完全适合我们的场景啊!我们也可以先把高频问题整理成知识库。”
“没错,”我说,”而且不需要一开始就完美。他们当时先整理了300个最高频问题,占60%查询量,花了两周时间。就这么个小改动,效果就立竿见影了。后面再慢慢扩展覆盖范围。”
长文本处理:另一个意外收获
“对了,还有个点特别值得说,”我继续讲,”就是长文本处理能力。我另一个朋友是做法律AI的,他们遇到的问题是:律师需要分析案卷材料,但材料太长了,一个复杂案件可能几百页。”
“传统AI处理不了吧?”Mark说。
“对,要分段输入,”我说,”但问题是,律师如果已经知道哪部分相关,也就不太需要AI了。真正需要AI的场景,是信息分散在大量材料里,需要AI帮忙识别和整合。”
“用Engram架构能解决?”
“他们用支持长上下文的版本后,律师可以一次性传整个案卷,然后问’对方诉求有啥法律漏洞’、’我方证据链有什么薄弱点’,”我说,”AI能在整个案卷里找答案,跨文档建立连接。比如注意到诉状里的一个时间点跟证人证言里的另一个时间点矛盾,而这两个信息可能相隔上百页。”
Mark点头:”这确实是质的飞跃。不只是节省时间,是改变了AI的角色定位——从’回答问题的工具’变成’分析助手’。”
“你悟性不错,”我笑着说,”这就是Engram架构带来的改变。记忆模块接管了局部模式识别,让注意力专注全局理解,长文本能力自然就上来了。”
成本这件事:省钱省到家了
Mark突然想到一个问题:”这套架构听起来挺好,但实施成本高吗?我们公司最近预算卡得死死的。”
“这恰恰是另一个亮点,”我说,”成本反而降了。你想啊,传统大模型的成本主要是GPU,所有参数都得在显存里。Engram的记忆模块查找不需要矩阵运算,可以把大量参数放在便宜的CPU内存里,只在需要时传到GPU。”
“能省多少?”Mark很关心这个。
我给他算了笔账:”假设你要部署27B参数的模型,传统方案需要8张A100,每张80GB显存,每小时成本约20美元。用Engram架构,可以把18B参数的记忆模块放CPU内存,只需要4张A100跑计算部分,成本降到每小时10美元。一年能省8万多美元。”
“这么多?”Mark惊讶了。
“关键是扩展性更好,”我接着说,”你想增加知识容量时,传统方案必须加GPU,因为所有参数得在GPU上。Engram方案可以通过加便宜的CPU内存来扩展,甚至可以用SSD做第三级存储。”
“为啥SSD也能用?”Mark不太明白。
“因为语言里的N-gram分布符合幂律,”我解释,”少数高频模式占大部分使用,长尾的低频模式很少访问。所以可以建多级缓存:热门的在GPU内存,常用的在CPU内存,冷门的在SSD。这样能支持TB级的记忆容量,增量成本很低。”
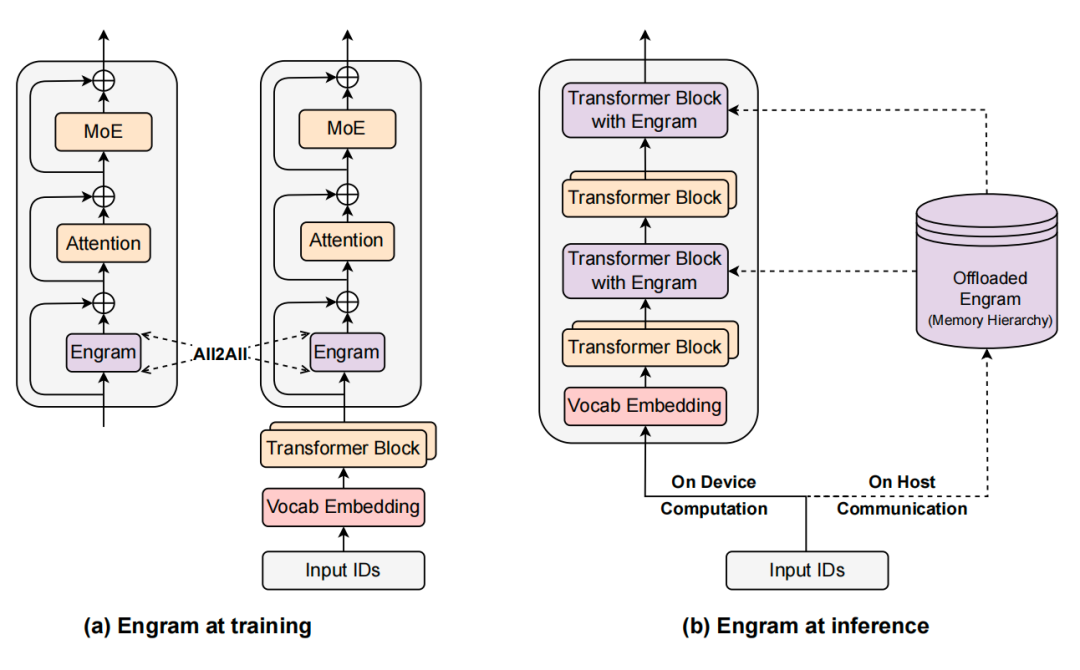
“你看这个系统设计,”我展开图片,”左边是训练阶段,右边是推理阶段。训练时,因为记忆表太大了,会切分到多张GPU上,通过All2All通信来同步。但推理时就聪明了——把整个记忆表放到Host Memory(CPU内存),然后利用Engram查询的确定性(因为是基于token ID的哈希,可以提前知道要查什么),在GPU计算前面的Transformer Block时,CPU就异步预取下一个Engram层需要的嵌入向量。”
Mark眼睛亮了:”所以通信和计算可以overlap,基本上hide掉了传输延迟?”
“对头!”我说,”论文里测试了一个100B参数的记忆表完全放在CPU内存,额外延迟不到3%。这就是为什么成本能降这么多——你不需要把所有参数都塞进昂贵的GPU显存里。”
Mark若有所思:”这不就是一种新的竞争优势?如果我们在客服领域积累了足够多的知识库,这个库本身就是护城河,竞争对手短期复制不了。”
“对头!”我赞同道,”这比单纯的算力竞争更有价值。知识库的构建需要时间,你运营得越久,积累越厚,优势越明显。”
这个改进靠谱吗?让数据说话
听完案例,Mark点点头,但我看得出他还有些犹豫。果然,他问了一个很实在的问题:”你说的这些提升,我都信。但你怎么保证这不是过拟合?或者说,万一我们照着做了,结果发现只在某些特定场景有效,其他场景不行,那就麻烦了。”
“这个顾虑很合理,”我说,”所以我专门留了这张图给你看。”
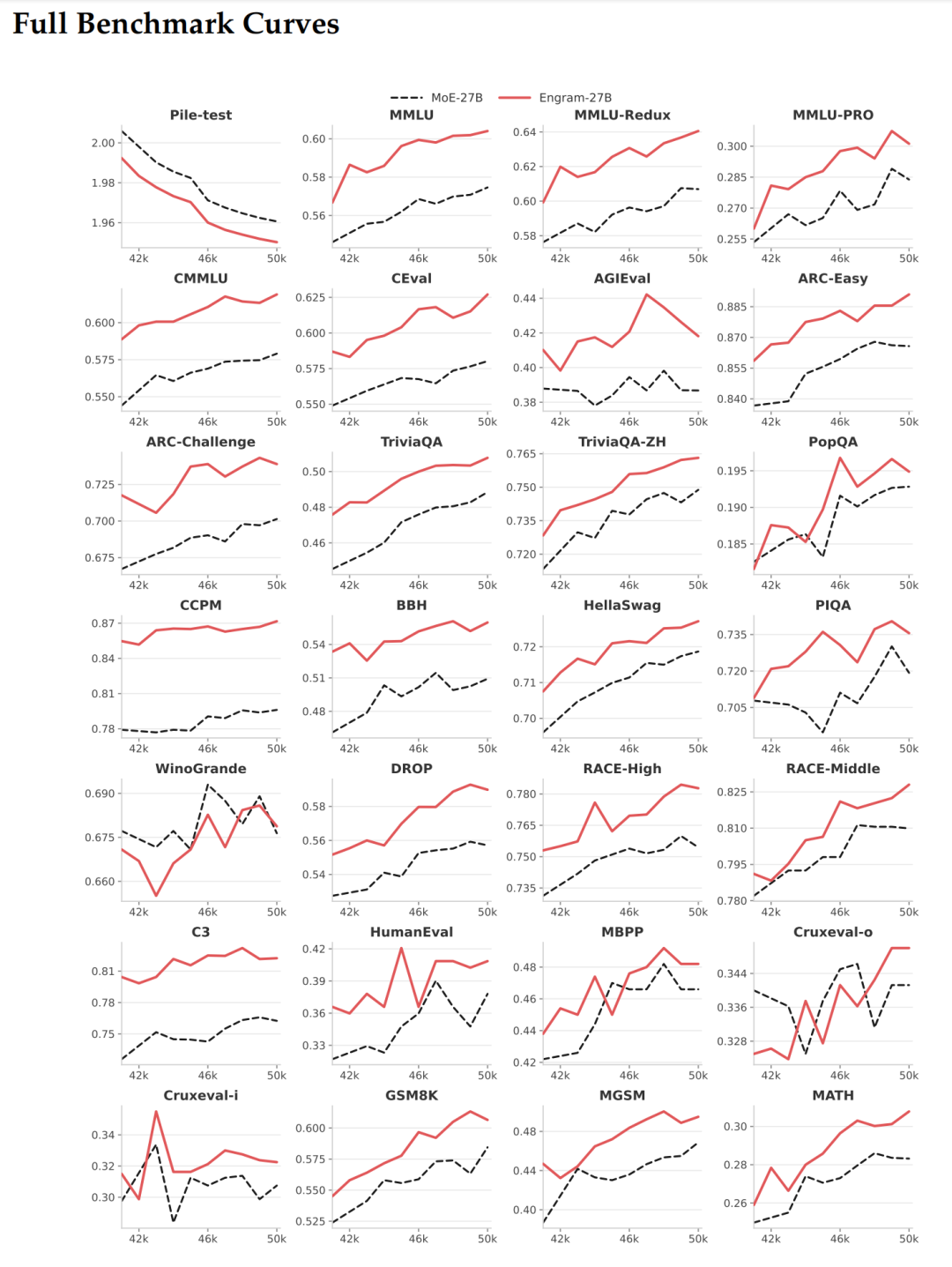
“这张图有点密集,但信息量巨大,”我说,”一共26个子图,每个代表一个测试任务。横轴是训练步数(42k到50k,也就是训练的最后阶段),纵轴是各个任务的得分。红线是Engram-27B,黑虚线是MoE-27B基线。”
Mark凑近看:”所以这不是单次测试结果,而是训练全程的动态追踪?”
“对!这就是关键,”我说,”如果一个改进只是偶然有效,你会看到两条线交叉纠缠,时好时坏。但你看这26张图,红线几乎在所有任务上都稳定地跑在黑线上方,而且差距随着训练推进越来越稳定。”
“让我看看具体的,”Mark说着指向几个图,”比如这个MMLU(知识问答),红线确实一直领先,而且是平稳上升。BBH(复杂推理)也是,虽然波动大一些,但红线明显占优。”
“你注意到波动大小的差异了,很敏锐,”我说,”这恰恰反映了任务的特性。知识类任务(MMLU、CMMLU、C-Eval)曲线比较平滑,因为知识积累是渐进的;推理类任务(BBH、ARC-Challenge、DROP)波动大一些,因为推理能力的提升不是线性的,会有顿悟的时刻。但不管波动大小,Engram的红线都稳定领先。”
Mark翻看着不同的子图:”代码任务呢?HumanEval、MBPP这些?”
“你看这几个,”我指着代码相关的图,”HumanEval红线领先大概3个百分点,MBPP也类似。而且有个有意思的现象:代码任务的Engram优势出现得比较早,大概在42k-44k步就拉开差距了。这说明记忆模块对代码中的固定模式(比如API调用、常见语法)的帮助是立竿见影的。”
“数学任务呢?”Mark问,”GSM8K、MATH这种。”
“数学更明显,”我指着对应的图,”GSM8K从42k步开始,红线就持续领先,到50k步时差距稳定在2个百分点左右。MATH也是类似的趋势。这说明虽然数学主要靠推理,但记忆模块帮助模型记住了常见的数学符号、公式表达,节省了推理容量。”
Mark若有所思:”所以这26个任务,覆盖了知识、推理、代码、数学、阅读理解各种类型,Engram在所有类型上都有稳定提升。这确实不是偶然现象。”
“对,而且还有个细节特别值得注意,”我说,”你看训练的最后阶段,42k到50k这8000步,黑线(MoE基线)在很多任务上已经趋于平缓了,说明模型快训练饱和了。但红线(Engram)还在持续上升,尤其是在推理类任务上。这说明什么?”
Mark眼睛一亮:”说明Engram架构的性能上限更高!如果继续训练更长时间,差距可能更大。”
“完全正确,”我说,”这就是为什么论文里说,Engram-40B(那个有18.5B记忆参数的版本)虽然还没完全训练饱和,但已经在多数任务上超过了Engram-27B。给它足够的训练token,潜力会更大。”
Mark拿出手机拍了这张图:”这张图对我说服老板太重要了。老板一定会问’万一效果不稳定怎么办’,我就拿这26条曲线给他看——这不是lab里调参调出来的,是实实在在训练出来的系统性优势。”
“而且你还可以这么说,”我提醒他,”你们的客服系统主要是知识问答和简单推理,对应MMLU、ARC-Easy这些任务。你看这几个任务的曲线,红线优势特别稳定,几乎没有任何一个时间点被黑线反超。这说明在你的应用场景,Engram的优势是板上钉钉的。”
“对,而且就算在一些波动大的任务上,”Mark指着WinoGrande那张图,”虽然两条线有交叉,但整体趋势红线还是占优。这说明即使在最不利的场景,Engram也不会比baseline差,顶多持平。”
“你看得很准,”我说,”这就是架构改进的可靠性。不像超参数调优可能over-fit某个测试集,架构层面的改进会在广谱任务上都有提升。当然,提升幅度会因任务而异,但方向是一致的。”
Mark收起手机:”现在我完全有信心了。有这26个任务的动态曲线背书,我可以放心大胆地推进这个改造方案。”
“还有最后一个细节,”我说,”你注意到图上的横轴是42k到50k吗?也就是最后8000步,大概20%的训练过程。这个阶段是模型性能最敏感的时期——前面已经学到了基础能力,现在在fine-tune细节。Engram在这个阶段的持续领先,说明它不只是’速成’的,而是真正提升了模型的内在能力。”
从理论到实践的最后一步
“好了,”我看了看时间,”理论和数据都讲完了。现在最实际的问题是:你回去怎么开始第一步?”
怎么开始?从最小可行方案做起。
Mark说:”听你讲了这么多,我有点跃跃欲试了。但说实话,我还是有点担心,实施起来会不会需要重构整个系统?团队的开发资源有限。”
“不用担心,”我说,”这个思路可以渐进式实施,不需要推倒重来。我给你讲讲具体怎么做。”
“第一步,分析你的查询日志,”我说,”把用户提问按主题聚类,计算每个聚类的频次和稳定性。高频且稳定的查询是最适合放进记忆库的。我那个朋友当时就发现,300个问题占了60%的查询量,而且这些问题的答案都是固定的,只是表述方式不同。”
“我回去马上让数据分析师拉日志,”Mark说。
“先搞定这300个高频问题,”我说,”把它们整理成精准的记忆库。实施成本很低,主要是人工整理标注,大概两周时间。但这个小改动就能让60%的查询从2秒多降到0.5秒以内,立竿见影。”
“然后呢?”
“第二步,逐步扩展覆盖范围,”我说,”设个阈值,当某类查询频次达到一定水平,自动触发记忆库更新流程。可以半自动化:系统识别高频查询模式,提取候选知识点,人工审核确认,然后加入库。”
“第三步呢?”Mark问。
“建立质量控制机制,”我说,”记忆库跟普通数据库不一样,它要理解语义不只是匹配关键词。需要定期评估召回率和准确率,找出那些被误检索或漏检索的case,不断优化匹配算法。”
“最后是更新机制,”我说,”领域知识会变,产品会迭代,记忆库得跟上。一个好做法是给每个记忆条目加时间戳和来源信息,设置定期审查流程。当底层知识源更新时,比如产品手册改了,能追踪到相关记忆条目并更新它们。”
Mark拿出手机记笔记:”这个实施路径很清晰,风险可控。我周一就可以启动第一步。”最后聊聊更深层的东西
看Mark记完笔记,我端起咖啡杯:”其实啊,这篇论文最大的价值,在我看来,不是给了一个现成的技术方案。”
“那是什么?”Mark抬起头。
“它提醒我们重新思考AI系统的架构设计,”我说,”咱们是不是太习惯把AI当黑盒了?输入问题,得到答案,模型越大越好。但这种思维忽略了一个基本事实:不同任务有不同处理需求。试图用一个通用机制应对所有场景,必然导致资源错配。”
Mark点头:”就像你刚才说的人脑,记忆和思考是两套系统。”
“对,”我说,”Engram告诉我们,AI系统可以而且应该是异构的。记忆和计算是两种本质不同的能力,应该区别对待。这不是说抛弃端到端的神经网络,而是说在端到端框架内,可以有不同处理路径。”
“就像现代处理器,”Mark接话说,”有多级缓存、有专门的向量计算单元、有分支预测器,每个组件针对特定任务优化,但整体还是统一的系统。”
“你这比喻太贴切了,”我赞道,”对产品经理来说,这意味着设计AI产品时,要更深入理解任务特性,识别哪些适合记忆处理,哪些需要深度推理。这种分析不能凭直觉,得基于数据。”
Mark沉思了一会儿说:”我觉得咱们正在进入AI产品竞争的下半场。上半场拼的是谁能更快用上最新模型,谁能率先推出AI功能。但现在OpenAI、Anthropic、Google的模型能力都差不多了,产品差异化越来越难建立。”
“没错,”我说,”下半场的竞争,我觉得会转向架构层面的创新:如何更好地组织和使用通用能力,如何针对特定场景做深度优化,如何建立难以复制的竞争壁垒。DeepSeek这项工作,就指出了一个方向。”
“一个值得深入思考的方向,”Mark说。
我笑了:”回去好好分析你们的数据吧,我觉得你们的客服系统大有可为。两周后咱们再聊,我想听听你们的进展。”
“一定!”Mark站起来跟我握手,”今天这顿咖啡喝得太值了,比看十篇论文都管用。”
看着Mark兴冲冲地离开,我想,或许这就是技术的真正价值——不是停留在论文里的公式和图表,而是能真正解决实际问题,让产品变得更好。DeepSeek的这项工作,触及了某些本质的东西,值得每一个AI产品从业者认真琢磨。
后记
Mark回去一天后,给我发消息说,他们数据分析师拉出来的日志显示,排名前280个问题占了他们58%的查询量,而且95%以上都是事实性查询。他们决定先从这280个问题开始建记忆库,预计两周上线A/B测试。
我很期待他们的结果。有时候,改变不需要推翻重来,只需要换个角度思考问题。
附:论文信息:

这份论文由DeepSeek与北京大学合作完成,梁文锋是作者之一。它系统性地提出了一种名为 “条件记忆 (Conditional Memory)” 的新稀疏化维度,并开源了其核心实现模块 Engram。
论文核心思想:针对当前大语言模型(LLM)用昂贵的动态计算来模拟静态知识检索的效率问题,Engram模块引入了基于哈希查找的 “条件记忆” ,与混合专家模型(MoE)的 “条件计算” 形成互补,实现了“查表”与“计算”的分离。
本文由人人都是产品经理作者【Blues】,微信公众号:【BLUES】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


