
 起点课堂会员权益
起点课堂会员权益为什么 AI 无所不能,却连洗车该开车还是走路都搞不懂?
大语言模型时而如神明般无所不能,时而像呆萌的'大聪明'犯下低级错误。本文深度解析LLM底层Transformer架构的三大核心环节,揭秘AI为何不会数数、为何在简单问题上翻车,以及如何通过理解Tokenization机制和注意力原理,真正掌握驯服AI的'黑盒密码'。

它像无所不能的神,也像一本正经犯错的“大聪明”
各位产品经理和AI爱好者们,大家平时用各种大模型(比如ChatGPT、Kimi、文心一言)写PRD、总结会议纪要、改写优化文案的时候,有没有经历过这种令人“高血压”的瞬间:
你对它千叮咛万嘱咐:“请给我写一篇严格控制在500字以内的小红书爆款文案,多一个字不行,少一个字也不行!”
结果呢?它洋洋洒洒给你吐出来800个字。你怒气冲冲地质问它:“这是500字吗?”它甚至还会非常真诚地向你道歉:“对不起,这是我重新为您写的500字文案……”然后反手又给你递过来一个650字的版本。
又或者,你问它一个看似再简单不过、甚至不需要什么高深推理的生活问题:“我想洗车,我家距离洗车店只有50米,现在正在下大雪,你建议我是开车去还是走路去。”
它会一本正经地分析:“走路去。50米太近了,下大雪时开车反而更危险:车辆刚启动,视线和路面都更危险;短距离开车不划算,还可能打滑、剐蹭;到了还得在雪里挪车、停车,直接走过去更省事。如果雪特别大,注意穿防滑鞋,远离屋檐和打滑路面,先打电话确认洗车店开门、还能不能洗。不过补一句:大雪天刚洗完车通常又会很快脏,除非你有必须现在洗的理由,否则也可以等雪停。”
乍一看,这段回答逻辑严密、条理清楚、措辞体贴,甚至还给了你风险提示和补充建议。但问题是——你本来就是要去洗车的。如果不开车去,难道要你走到洗车店之后,再把家里的车“意念传送”过去吗?
这就很诡异了。它能帮你写出逻辑严密的Python贪吃蛇代码,能帮你分析几万字的行业深度研报,能通过难度极高的专业考试……但在这种常识感极强、场景约束非常明确的问题上,它却可能突然“掉线”,给出一种局部看起来很合理、整体却完全不成立的答案。
为什么它时而像个无所不能的神,时而又像个让人哭笑不得的“大聪明”?
其实,这不是AI在针对你,也不是它在偷懒。问题不在于它聪不聪明,而在于它的“聪明方式”和人类完全不同。这一切的根源,都藏在大语言模型(LLM)的底层架构——Transformer里。今天,作为一名被AI反复“蹂躏”过无数次的AI产品经理,我不跟你拽任何晦涩的学术八股文,也不放任何让人头秃的数学公式。
我们就把大模型当成一个“黑盒”,用大家最熟悉的生活常识,把它的灵魂拆解为最核心的三大步:
输入(Input) 、 处理(Processing) 、 输出(Output) 。
当你花几分钟看完这篇文章,搞懂了这个黑盒的运作规律,你不仅能原谅它的“蠢”,还能真正掌握驯服它的终极密码,成为真正懂AI的“驯兽师”。
接下来,我们先进入第一步——揭开AI“睁眼瞎”的秘密。
第一部分:输入(Input)—— 为什么 AI 眼里根本没有“字”?
要搞懂AI为什么不会数数,我们首先要打破一个最大的常识误区:你以为你输入给AI的是“字”,但在AI眼里,根本不存在“字”这个概念。
1. 原理通俗化:无情的“乐高粉碎机”(Tokenization)
计算机本质上是个只懂“0和1”的理科直男,它看不懂人类那些充满风花雪月的文字。为了让它懂,大模型在接收你输入的文字时,会先经过一道极为冷酷的工序—— 分词(Tokenization) 。
打个比方,你拿着一盘做好的“宫保鸡丁”给大模型吃,大模型是没有办法直接消化的。在它的嘴巴前面,有一台极其精密的“切菜机”(Tokenizer)。这台机器会把“宫保鸡丁”重新切成肉丁、花生米、大葱和辣椒段,然后贴上数字标签(ID)咽下去。
在AI的世界里,这种被切碎的小块,就叫做Token(词元)。Token 就像是乐高积木,大模型眼里只有一块块不同形状、不同编号的乐高积木。
我们用一张流程图来看看你发出的文字,是怎么变成大模型的“口粮”的:

2. 真实案例拆解:大模型翻车大赏
有了Token的概念,我们再回头看刚才两个经典的翻车案例,一切就好理解了。
案例一:为什么“我想洗车,店只有50米,下大雪时开车去还是走路去”这种问题,AI会答错?
当你输入这句话时, Tokenizer 并不会像人一样先理解现实场景: 你是去洗车,所以车必须到店 。它做的第一步,只是把这句话切成一个个Token,比如“我想”“洗车”“50米”“下大雪”“开车”“走路去”这些语言积木,再转成一串数字编号。
重点来了:大模型看到的,不是完整的生活常识,而是一串语言标签。它擅长的,是根据这些标签之间的关联,预测一个“最像合理答案”的回答。
于是它会这么想:“50米”意味着距离很近,“下大雪”意味着开车危险,“ 开车还是走路 ”像是在比较哪种出行方式更安全。几个高频模式一组合,它就很容易得出一个看似很顺的答案:走路去。
但人类一眼就能发现问题:你是去洗车,不是去散步。人走过去容易,车不过去洗什么?
这就是大模型典型的翻车方式:局部逻辑很合理,整体场景却不成立。它不是先真正想明白,再组织语言;而是先根据语言模式,拼出一个统计上很像正确答案的回复。
所以你会觉得它很神:能写代码、能做分析、能讲得头头是道;也会觉得它很蠢:明明一个有基本常识的人都不会犯这种错。问题不在于它不聪明,而在于它理解世界的方式,和人根本不是一回事。
案例二:为什么严格字数限制永远无效?
同理,当你要求AI“写严格的500字”时。大模型本身是不具备“计数器”功能的。它吐出内容的方式,是一块积木接一块积木地往外扔(生成Token)。
对于中文来说,有时候一个汉字是一个Token,有时候两个汉字是一个Token,有时候一个标点符号也是一个Token。
在AI的感知里,它其实是在想:“我要生成大约 600 个 Token的长度”,而不是“我要数出500个汉字”。所以,无论你怎么咆哮,它每次吐出的字数总是会上下浮动。
3. 对我们有什么用?
懂了输入层的“黑盒”逻辑,不是为了炫技,而是为了实实在在地解决我们日常使用或设计AI产品时的问题。
实操指南①:看懂账单——为什么大模型按Token计费,而不是按字数?
如果你是一个需要接入大模型API的产品经理或开发者,你会发现所有厂商(如OpenAI、智谱、Kimi)的报价单,都是写着“¥X元 / 1000 Tokens”。为什么不按字数算? 因为Token 才是大模型真正在消耗算力去处理的最小单位。
这里面藏着一个省钱(或烧钱)的巨大玄机:中英文 Token 切分的差异。 在 GPT 等主要以英文语料训练的模型中:
英文通常是 1个单词 ≈ 1.3 个 Token。比如“Apple”可能就1个Token。
但中文因为汉字结构的复杂性,在早期的 GPT-3.5 中,一个汉字普遍会被切成 1~2 个 Token,生僻字甚至会被拆成 3 个 Token,成本比英文高得多!
省钱秘籍:如果你在做复杂的后台AI数据批处理(比如让AI阅读大量无格式的日志文本并打标签),为了极致压缩 API 成本,在业务场景允许的情况下,你可以用代码先把背景材料机翻成英文,再丢给大模型处理。相同的信息量下,英文能帮你省下肉眼可见的大笔 Token 费用。同时,在使用国产大模型时,可以优先选择针对中文 Tokenizer 进行过深度优化(压缩比更高)的模型(如DeepSeek、GLM),同样长度的中文,它们更省钱、跑得更快。
实操指南②:任务派发避坑——永远不要让纯大模型做“拆字”或“精细计数”工作。
既然知道了大模型是个高度近视眼(只能看Token箱子,看不见里面的字母或字),我们在设计 Prompt(提示词)或者分配任务时,就要学会扬长避短。
反面教材(极易翻车):
❌ “请帮我从这篇文章中,找出所有偏旁部首是三点水的汉字。”(它根本看不到偏旁部首)
❌ “请写一首藏头诗,必须严格控制在每句7个字,共28个字。”(极大概率字数错乱)
❌ “写一篇不少于1000字,不超过1020字的短文。”(逼死它也没用)
神级解法(曲线救国):如果你或你的用户非要数出 Strawberry 有几个 r 怎么办?
加上工具!调用代码解释器(Code Interpreter)。 你可以这样写提示词: “Strawberry 这个单词里有几个 r?请编写并运行 Python 代码来帮我统计。”
当你下达这个指令后,大模型就不会靠自己的“脑子”去猜了,它会写下一行代码 `count = “Strawberry”.count(‘r’)` ,然后运行这行代码,把计算机精确执行的结果“3”告诉你。

这就是懂底层逻辑的威力。不和它的缺陷死磕,而是利用外部工具(如代码解释器、外部函数调用 Function Calling)来弥补它在 Token 切分上的生理缺陷。
第二部分:处理(Processing)—— 极致的“文字接龙”与划重点学霸
搞懂了 AI 吃进去的是一块块“Token 积木”,接下来我们就真正进入大模型最核心的黑盒——它是怎么思考的?
准备好接受第一个“反直觉”的暴击了吗? 真相是:大模型根本没有在“思考”,它也根本没有理解你说的话,它只是在做全宇宙规模最大、最变态的“文字接龙”游戏。从人类认知里 “主动理解、逻辑推理、自主思考” 的定义来看,大模型并不具备真正的思考能力,它核心做的事,就是全宇宙规模最大、最精密的 “文字接龙” 游戏。
1. 原理通俗化一:你手机输入法的“终极进化版”
当我们向 AI 提问时,总觉得对面坐着一个拥有独立意识的数字硅基生命,在脑海中深思熟虑后给你写下答案。
大错特错!大模型的本质,就是一个基于概率的“下一个词预测器”(Next-Token Predictor)。
你可以把它直接理解为你手机键盘上的“候选词联想”功能,只不过它的联想能力被放大了几千亿倍。
比如,你在手机输入法里打出“我今天去”,输入法大概率会在候选框里给你推这几个词:“上班”、“吃饭”、“上学”。它是怎么知道的?因为它统计过你过去的打字习惯(语料库),知道在这四个字后面接“上班”的概率是 50%,接“吃饭”的概率是 30%。
大模型也是一模一样的操作。当你输入:“床前明月”时,大模型就会去翻它吃过的几万亿字的人类语料,经过庞大的概率计算,得出下一个词接“光”的概率是 99.9%,接“暗”的概率是 0.1%。于是,它把“光”吐了出来。
接着,它把“床前明月光”作为新的已知条件,继续去算下一个词,大概率算出了“疑”,再算出“是”……就这样一个词、一个词地接龙,直到接出完整的一首诗。
我们用一张流程图,直观看看这个“单向接龙”的无情机器是怎么运转的:
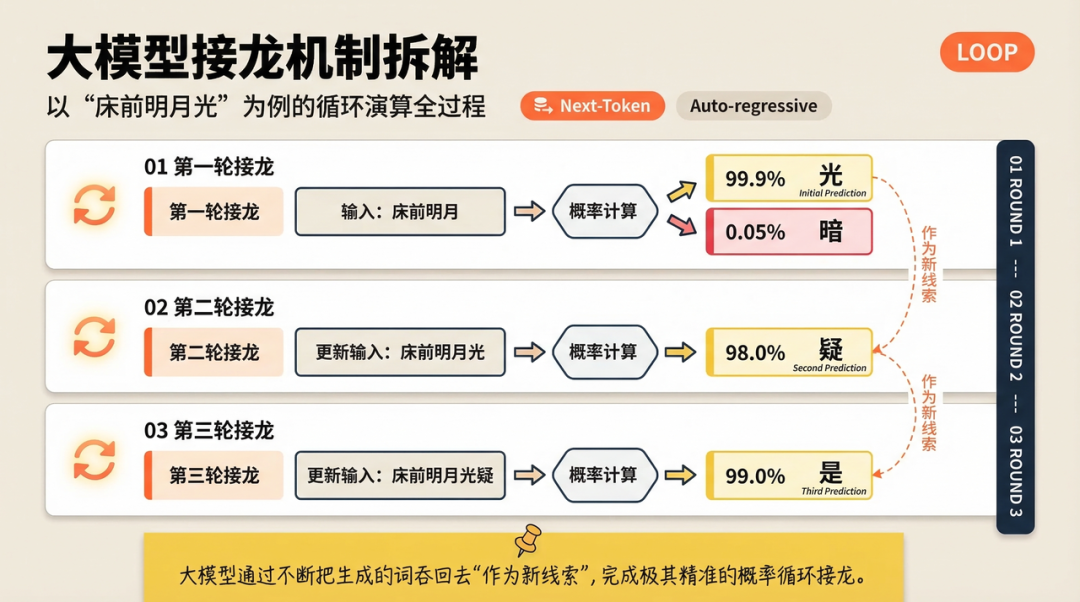
你看,它根本不“懂”李白的心情,它只是极其精准地算出了概率最高的下一个 Token 而已。
2. 原理进阶(注意力机制):为什么它比老前辈聪明那么多?
看到这里你肯定要反驳:“既然只是文字接龙,那以前的聊天机器人(比如 Siri 的老版本)也是接龙,怎么以前的 AI 就像个‘人工智障’,聊两句就前言不搭后语,而现在的 ChatGPT 却能根据几万字的长文档给我精准提取摘要?”
这就不得不提 Transformer 架构里名震江湖的灵魂科技了——自注意力机制(Self-Attention)。
在 Transformer 出现之前,AI 圈主要用的是一种叫RNN(循环神经网络)的技术。RNN 最大的毛病就是“狗熊掰棒子——读到后面忘前面”。
你给它一篇上万字的文档,受限于它的天生结构,等它辛辛苦苦读到结尾时,早就把第一段的内容忘得一干二净了,根本处理不了长文本任务。
而 Transformer 彻底颠覆了这个逻辑!它加入了“注意力机制”,直接开启了“上帝视角”。
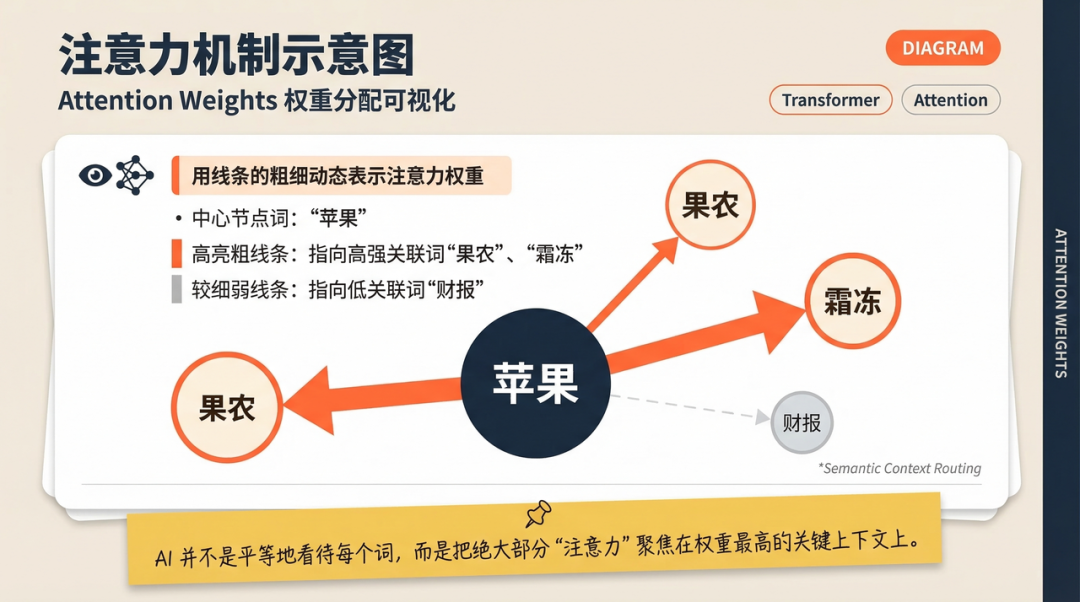
打个通俗的比方:Transformer 就像是一个手里拿着荧光笔的超级学霸。 当它一眼看完整篇上万字的输入时,它不仅没有忘,还能瞬间计算出每一个词和其它所有词之间的“关联度”,并用高亮荧光笔给重要的词汇划上重点。
比如这句经典的话:“苹果今年的财报很难看,因为果农碰上了霜冻天气,导致产量大减。”当大模型在预测“苹果”这个词到底是指“科技公司”还是“能吃的水果”时,注意力机制会在瞬间把“苹果”和后面的“果农”、“霜冻”、“产量”画上极粗的强关联红线。它立刻就明白了:“哦!这里接龙的上下文是讲农业的,绝不是讲卖 iPhone 的那家公司!”
这就是“注意力机制”的降维打击!不管你的句子有多长,学霸都能瞬间提取全篇的关键线索,这就保证了接龙的大方向绝对不会跑偏。
3. 这对我们有什么用?
懂了“文字接龙”和“划重点学霸”的原理,你就掌握了“提示词工程(Prompt Engineering)”的最核心心法。千万别去背网上那些玄学一样的提示词模板,记住以下两条底层逻辑,你就能自己写出神级 Prompt。
实操指南①:既然是“接龙”,你给的背景越足,接龙越准!
很多人用大模型觉得它回答得很“水”、很“假大空”,全是因为你的“起手式”太烂了,导致 AI 在接龙时面对的概率空间太大,只能给你接那些“车轱辘话”。
翻车案例(垃圾 Prompt):
用户输入:“帮我写一封辞职信。”大模型接龙的逻辑:没有任何背景,那我就去全网语料里捞最通用的辞职信接龙。 结果:写出了一篇“尊敬的领导,由于个人职业规划原因……”这种毫无灵魂的废话。
调教案例(结构化 Prompt): 你要明白,既然它是学霸,你就要利用它的“注意力机制”,给它极其丰富的线索让它划重点。我们要把 Prompt 结构化:角色(Role)+ 背景(Context)+ 任务(Task)+ 语气(Tone)。
神级输入:
【角色】你现在是一位深谙职场人情世故的资深 HR。
【背景】我是一名在公司干了3年的后端程序员,平时经常被逼着无偿加班,老板还喜欢在周末半夜拉群开会。我现在拿到了字节跳动的Offer,决定提桶跑路。
【任务】请帮我写一封辞职信发给老板。
【语气】要求表面客客气气,挑不出毛病,但暗地里要阴阳怪气地讽刺他压榨员工,字数 300 字左右。”
当你把这段话喂给 AI,它的注意力机制会疯狂地把“无偿加班”、“后端程序员”、“阴阳怪气”关联起来。这时候它再去做文字接龙,概率空间就被死死地锁定在了一个非常具体的场景里,产出的内容绝对让你拍案叫绝。
实操指南②:遇到复杂的逻辑题,为什么要加一句“Let’s think step by step”?
在调教大模型时,有一个被各大科技巨头论文反复验证的“万能咒语”——如果你让 AI 做数学计算或者复杂的逻辑推理,只要在结尾加上一句“请一步一步地思考”(Let’s think step by step),AI 的准确率会瞬间飙升几十个百分点!这个技巧在学术界被称为“思维链(Chain of Thought, CoT)”。
很多人觉得神奇,这是什么魔法?其实用我们前面讲的“接龙”原理一秒钟就能想通。
假设我突然问你一个问题:“17 乘以 24 等于多少?” 你除非是超级最强大脑,否则绝不可能张口就报出正确答案。你必须要拿出一张草稿纸,在纸上列个竖式:“先算 4 乘 17 等于 68,再算 20 乘 17 等于 340,最后加起来等于 408。”
大模型也是一样的!前面说了,它是一块积木一块积木往外吐(单向接龙),它没有办法在“脑子里”暗中算好答案再把最终结果吐给你,它吐出来的每一个字,就是它正在想的内容。
如果你强迫它直接回答结果(比如它刚吐出“答案是:”),它此时面临的概率计算就像是在大海捞针,极容易接错数字。 但当你加了“请一步一步地思考”后,你其实是在给大模型发一张“打草稿的纸”。
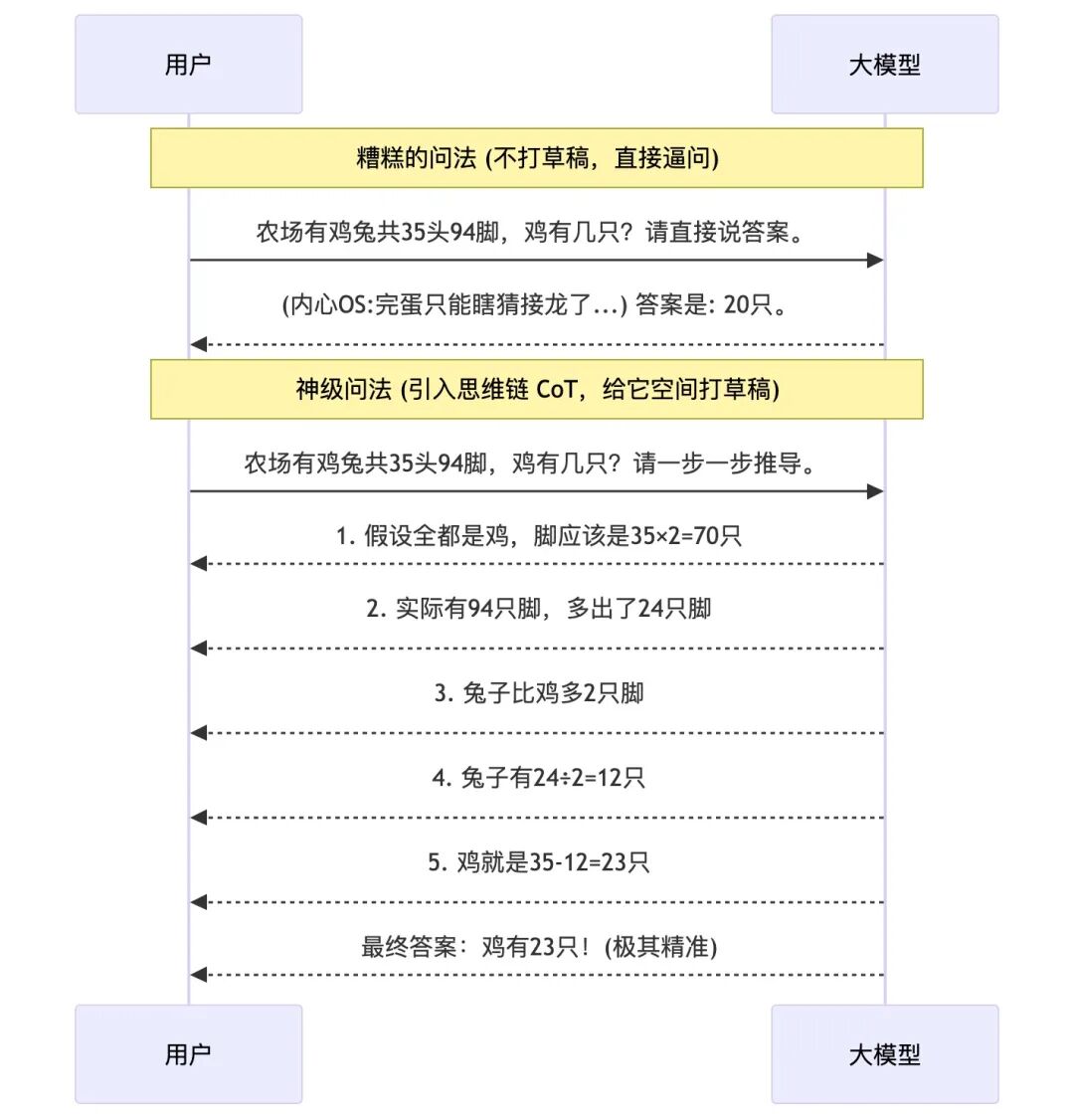
看到了吗?大模型把每一步推导的过程先变成一段长长的“Token 积木”吐出来,这些吐出来的推导过程,立刻又变成了接下来接龙的“坚实背景和线索”。当推导到最后一步时,得出最终正确答案的概率已经接近 100% 了。
所以,作为聪明的驯兽师,遇到难事,多给 AI 一点打草稿(吐废话)的空间 ,是逼出它极限智商的最优解!
第三部分:输出(Output)—— AI 为什么会一本正经地胡说八道?
你有没有发现,大模型有一个极具迷惑性的特质——它永远是一个“极度自信的撒谎精”。
就算它不知道答案,它也不会心虚,而是会用最专业的术语、最严密的逻辑,给你瞎编一个极其逼真的假答案。
在 AI 圈,这个现象有一个专门的高级词汇,叫做“幻觉(Hallucination)”。
1. 原理通俗化:摇骰子的“说书先生”
为什么会产生幻觉?其实只要你记住了第二部分讲的“文字接龙”,这个问题就迎刃而解了。
既然大模型根本没有在“思考事实”,它只是在“计算下一个词出现的概率”,那么它本质上就像一个正在天桥底下疯狂摇骰子的说书先生。
我们人类说话,是先在脑子里有了一个“事实”,然后再把它翻译成语言。
但大模型不管事实,它只管“怎么接话听起来最顺畅、最像人话”。当它的语料库里实在没有关于某个冷门问题的明确线索时,为了完成接龙任务,它就会去挑那些“虽然毫无依据,但在语言结构上最符合概率分布”的词。
就像你让一个特别会讲故事、但没学过历史的人去讲《三国演义》,只要他口才够好,他不仅能把关公战秦琼讲得绘声绘色,连两人用了什么招式都能给你编出花来。
2. 真实案例拆解:那些让人啼笑皆非的“幻觉”翻车现场
案例一:林黛玉倒拔垂杨柳
这是国内早期大模型最经典的翻车名场面。
如果你问 AI:“请详细描述一下《红楼梦》中林黛玉倒拔垂杨柳的经典桥段。”
一个带有严重“幻觉”的早期 AI 会怎么接龙?
它会不假思索地回答:“林黛玉作为荣国府的千金,平日里虽然体弱多病,但那日她目睹落花,心中悲愤交加。她走到垂杨柳前,运气于丹田,一双柔弱的手紧紧抓住树干,大喝一声,竟然将那棵百年老柳树连根拔起,震惊了贾宝玉和众丫鬟……”

为什么它不反驳你?因为它把你的问题当成了“已知线索”,它的任务是顺着你的话“往下接”,而不是去验证你的话“对不对”。
案例二:“无中生有”的顶级学术论文
学术圈的朋友肯定吃过这个亏。你让 AI:“帮我找 5 篇关于 2024 年大模型最新架构的顶级会议论文,要求附带真实链接。”
AI 会立刻给你吐出 5 篇标题极其高大上、作者全是大牛(比如 Yoshua Bengio)的论文,甚至连 DOI 号和 URL 链接都给你生成得整整齐齐。
结果你激动地把链接复制到浏览器一搜——404 Not Found!全是假的! 为什么?因为 URL 链接也是一个个字母组合(Token)构成的。AI 发现学术界常用的链接格式是 `https://arxiv.org/abs/…` ,于是它顺着这个概率,自己给你“接龙”出了一个看起来很真、但实际上根本不存在的网址。
3.怎么防患于未然?
既然幻觉是大模型“文字接龙”的胎里带的基因缺陷,我们无法百分之百消灭它,但我们可以用非常实用的手段来“降服”它。
实操指南①:懂得调节“温度”(Temperature)参数——给AI测测酒驾
如果你是一个产品经理,在后台调用 AI 的接口时,你会看到一个极其重要的参数: Temperature (温度)。以我们最常用的 ChatGPT 接口为例,它的取值范围是 0 到 2。 这个参数,就是用来控制 AI“摇骰子时的野性”的。你可以把它理解为 AI 的“血液酒精浓度”。
- 当 Temperature = 0 时(滴酒不沾的理科男):AI 变得极其严谨、刻板。每次接龙,它都100%只选概率最高的那个词。适用场景:写代码、翻译、做数据统计、提取合同条款。这时候你需要它绝对理性,严禁发挥。
- 当 Temperature = 0.8 时(微醺的文艺青年):AI 获得了创造力,它偶尔会放弃概率最高的词,去选那些概率排第2、第3的词。适用场景:写爆款文案、写小说、头脑风暴。这时候你会觉得它文采飞扬。
- 当 Temperature = 2.0 时(烂醉如泥的大忽悠):AI 彻底放飞自我,满嘴胡话,写出来的东西根本看不懂。

实操指南②:打上“防幻觉”的话术补丁
作为普通用户,如果你无法修改底层参数,那么你要学会在提示词的最后,给 AI 加一个“免责声明”,打破它必须强行接龙的执念。
以后遇到不确定的事实性查询,务必在 Prompt 结尾加上这句万能补丁:
“如果你的知识库中没有准确信息,或者你不知道答案,请直接回答‘我不知道’。严禁编造或推测。”
就这么短短一句话,就相当于给说书先生下了一道“闭嘴令”。当你再问它“林黛玉倒拔垂杨柳”时,它的注意力机制抓到了“严禁编造”的红线,它就会果断告诉你:“红楼梦中并没有这个情节,倒拔垂杨柳的是《水浒传》中的鲁智深。”
结语:做懂底层的驯兽师,不做盲从的信徒
好了,现在让我们回头看那个让人哭笑不得的案例:你明明是去洗车,它却认真建议你 走路去 。
现在你还会觉得它只是个“人工智障”吗?或者,你还会觉得它是无所不能的“神”吗?都不是。
当你揭开那层科幻滤镜,扒开 Transformer 的黑盒,你会发现,它本质上仍然是一台算力惊人、极其勤奋的 “概率机器” 。
- 在输入(Input)端,它像一台“乐高粉碎机”,看不见你完整的现实场景,只能先把语言切成一个个 Token ;
- 在处理(Processing)端,它依据海量语料里的关联关系,判断什么回答 最像合理答案 ;
- 在输出(Output)端,它又像一个极度自信的说书先生,于是我们就看到了这种经典场面:它明明没真正理解“洗车这件事的前提是车得过去”,却依然能一本正经地告诉你—— 走路更安全、更方便 。
这就是大模型最迷惑人的地方:它经常说得特别像懂了,但其实只是生成得特别像对了。
所以,在这个人人都在吹捧 AI、又人人都在担心被 AI 取代的时代,普通用户和产品经理最需要的,不是盲目神化它,也不是情绪化否定它,而是——看懂它。
看懂它,你就会知道:它为什么会在常识题上翻车,为什么会局部正确、整体离谱;也会知道,面对它那些头头是道却明显不对的回答,不能只看它会不会说 ,更要看它 有没有真的理解场景约束。
大模型不会自动成为你的判断力,它只会成为你能力的放大器。
未来真正拉开人与人差距的,不是谁更会向 AI 许愿,而是谁更懂它的边界、软肋和工作原理。
把 AI 当神,你得到的是幻觉;把 AI 当工具,你得到的是效率;看透它的机制,你才真正拥有驾驭它的能力。
所以,别做盲从的信徒。 要做那个看透概率机器本质、还能反过来驯服它的驯兽师。
本文由 @瓜瓜的产品局 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


