
 起点课堂会员权益
起点课堂会员权益别只会调Prompt:AI PM 必须掌握的核心知识与实战话术
AI项目的失败往往源于产品评估体系的失灵,而非技术本身。本文深入剖析AI PM必须具备的四大核心能力:技术边界可控、人机协同可落地、数据飞轮可持续和商业测算可闭环。通过Golden Set、R-U-B计分板等实用工具,你将学会如何将模型能力转化为可执行的业务系统。

过去一年,我看到太多 AI 项目死在同一个地方: 算法准确率涨了,客诉也涨了;Demo 更惊艳了,续费却没起来。
周会上,技术团队说“模型效果提升了”;业务团队说“客户体验变差了”;财务团队说“成本还在升”。如果这三句话在同一家公司同时成立,问题通常不在模型本身,而在产品评估体系失灵。
一个合格的 AI PM,不只是把模型接进流程,而是要把不确定的模型能力,翻译成组织可执行、可复盘、可优化的业务系统。
真正的核心能力是四件事: 技术边界可控、人机协同可落地、数据飞轮可持续、商业测算可闭环。 而贯穿这四件事的底座,就是:Golden Set+ R-U-B 计分板 + LLM-as-a-Judge 自动评测流水线。
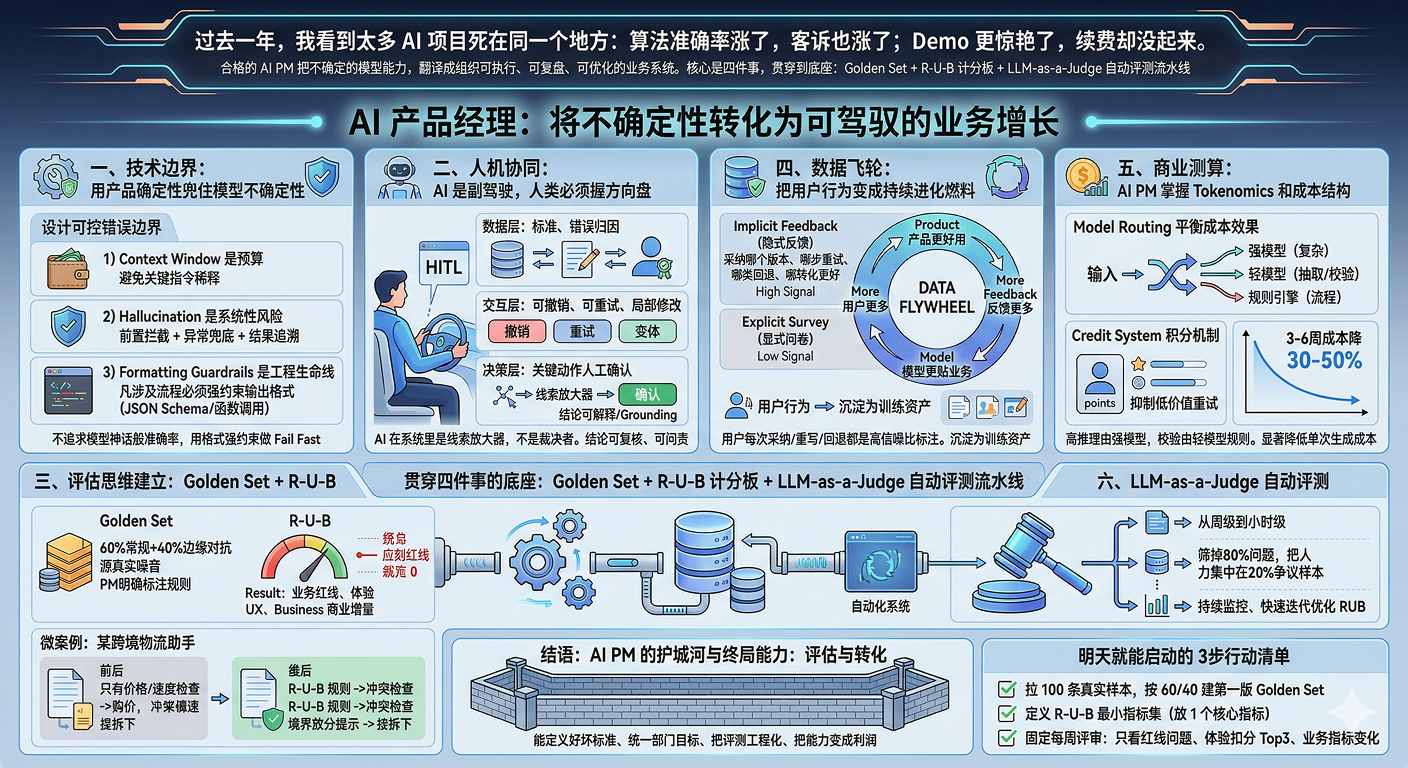
一、技术边界:用产品确定性兜住模型不确定性
传统软件是 If-Then 的确定性逻辑;AI 是概率输出。
所以 AI PM 第一原则不是“追求100%正确”,而是“设计可控错误边界”。
你至少要抓住三点:
1)Context Window 是预算,不是越大越好
上下文越长,成本越高,噪声越多,关键指令被稀释概率也越高。
AI PM 要做的是上下文管理:哪些信息必须保留、哪些结构化传参、哪些可裁剪。
2)Hallucination 不是偶发,而是系统性风险
AI 会“一本正经胡说八道”,这是概率模型属性,不是偶发事故。
产品层必须做好“前置拦截 + 异常兜底 + 结果追溯”。
3)Formatting Guardrails 是工程生命线
凡是涉及流程编排、前后端协议、数据库写入,必须强约束输出格式(如 JSON Schema/函数调用)。
文本可自由,系统不可自由。
实战话术: “我不追求模型神话般准确率,而是用格式强约束和任务拆解做 Fail Fast,让错误尽早暴露、尽早阻断。”
二、人机协同:AI 是副驾驶,人类必须握方向盘
AI 项目翻车,很多不是技术问题,而是责任边界模糊。 尤其在严肃场景(风控、法务、医疗、公安、金融),必须坚持:机器给建议,人类做决策并承担责任。
这就是 HITL(Human-in-the-Loop)的本质。
三层 HITL 设计
- 数据层:人类参与标注标准、错误归因、规则维护,防止训练偏航。
- 交互层:支持“可撤销、可重试、可局部修改”(如重绘、变体、多版本对比)。
- 决策层:关键动作必须人工确认,结论必须可解释、可溯源(Grounding)。
实战话术: “AI 在系统里是线索放大器,不是裁决者。我们通过渐进式展露+证据锚定,让每个关键结论都可复核、可问责。”
三、从功能思维升级为评估思维:建立 Golden Set + R-U-B 计分板
很多团队“会做功能”,但不会“做评估系统”,最终导致算法指标和业务指标脱节。
1)Golden Set:PM 必须主导,不可外包
建议结构:60%常规样本 + 40%边缘/对抗样本。 样本来源必须是线上真实噪音,而不是理想化问答。 PM 要明确标注规则:什么叫事实错误、过度承诺、机械回复、风险越权。
2)R-U-B:让跨部门说同一种语言
- R(Result)结果:业务红线是否触发(可设一票否决)
- U(UX)体验:是否给出边界提示、置信信息、解释依据
- B(Business)商业:是否改善北极星指标(一次通过率、赔付率、转化率、留存等)
关键原则: 业务红线一旦触发,再高“总体准确率”也应记为0分。
3)一个微案例(可复用)
某跨境物流助手项目里,模型“推荐准确率”看上去很高,但仍有大量扣关投诉。原因是评估只看了价格和时效,没把“禁限运规则冲突”设成红线。
改法很简单:把“禁限运冲突率”纳入 R 维度一票否决,同时在 U 维度要求系统必须给出边界提示(如“包含电池请走特货通道”)。两周后,投诉占比明显下降,团队也不再互相甩锅。
实战话术: “我们不再单看算法准确率,而是用 R-U-B 看板统一目标:先守红线,再提体验,最后看商业增量。”
四、数据飞轮:把用户行为变成持续进化燃料
AI PM 的长期护城河,本质是“对齐数据能力”。
你不能只靠低频问卷,要优先利用高频真实行为(Implicit Feedback):
- 用户采纳了哪个版本
- 在哪一步反复重试
- 哪类建议被高频回退
- 哪类输出在业务链路里转化更好
这些行为数据是高质量偏好样本。沉淀后会形成 Data Flywheel: 产品更好用 → 用户更多 → 反馈更多 → 模型更贴业务 → 产品更好用。
实战话术: “用户每次‘采纳/重写/回退’都是高信噪比标注。我们把行为数据沉淀为训练资产,而不是只靠问卷猜需求。”
五、商业测算:不会算账的 AI PM,做不出可持续产品
AI 产品不是“上线即胜利”,而是“上线后每次点击都在花钱”。
所以 AI PM 必须掌握 Tokenomics 和成本结构:输入/输出 token、长上下文成本、并发压力、功能级 ROI。
用 Model Routing 做成本与效果平衡
- 强模型:高认知复杂任务
- 轻模型:抽取、分类、校验
- 规则引擎/代码:确定性流程
再配合积分机制(Credit System)和免费增值策略(Freemium),把成本约束前置到用户行为层,抑制低价值重试。
一个可执行的管理目标是: 在不牺牲关键体验指标的前提下,3-6周把单次有效生成成本压降 30%-50%。
实战话术: “我们把高复杂推理路由到强模型,抽取与校验路由到轻模型和规则引擎,并用积分机制限制无效重试,显著降低单次生成成本。”
六、下一步:用 LLM-as-a-Judge 把评测从“周级”提到“小时级”
当数据规模变大,人工全量评测不可持续。
这时要引入 LLM-as-a-Judge:用更强模型做裁判,按标注 SOP 自动打分与归因。
作用不是“替代人”,而是“筛掉80%明显问题”,把人力集中在20%高争议边界案例上。这样你才能高频监控、快速迭代,持续优化 R-U-B 计分板。
结语:AI PM 的护城河,是评估与转化能力
会调 Prompt 的人很多,会接模型 API 的团队更多。真正稀缺的是:能把模型表现翻译成组织标准,并稳定转化为业务结果的人。
所以,AI PM 的终局能力不是“会用 AI”,而是:
- 能定义好坏标准(Golden Set)
- 能统一跨部门目标(R-U-B)
- 能把评测工程化(LLM-as-a-Judge)
- 能把能力变成利润(商业闭环)
当你能持续回答四个问题——
“为什么可靠、为什么可用、为什么会越来越好、为什么值得继续投钱”——
你就不再是“会用工具的 PM”,而是“能驾驭 AI 业务增长的产品负责人”。
本文由 @一亮AI 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Pixabay,基于CC0协议






- 目前还没评论,等你发挥!


