
 起点课堂会员权益
起点课堂会员权益你早就在做 Harness 工程,只是不知道它叫这个名字
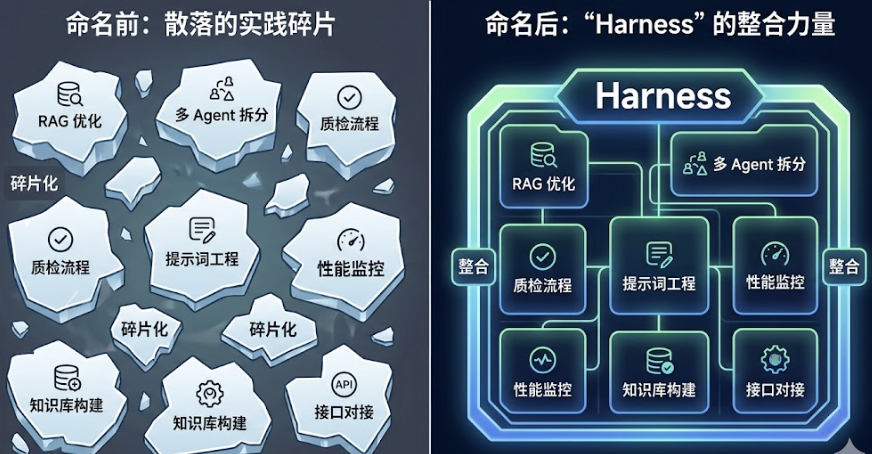
AI产品开发中,一个名为Harness的关键概念正引发行业热议。它并非新事物,而是对AI产品人长期实践却未被系统定义的方法论的正式命名——从多Agent拆分到安全边界设计,这些解决AI固有缺陷的架构决策终于有了统一框架。本文通过真实项目案例,揭示Harness如何通过系统层设计补偿AI弱点,以及为何命名本身就能推动经验传承与技术迭代。
最近 AI 圈又多了一个让人头疼的词:Harness。
有人说叫「线束」,有人说叫「驾驭层」,有人说叫「管控层」,Claude 自己给了五六个答案之后,最终建议——不翻译,就用 Harness。
但我想说的不是它该怎么翻译。
我想说的是:如果你认真做过任何一个 AI 产品,或者认真用 Agent 完成过复杂任务,你早就在做 Harness 工程了。只是没有人告诉你,这件事有一个名字。
Harness 不是 Anthropic 或 OpenAI 发明的新东西。它是一个迟来的命名——给一种所有认真的 AI 产品人都已经在实践、却从未被系统化定义过的工程方法,终于贴上了一个标签。
一、所有认真的 AI 产品,都在解决同一个问题
去年我在做一个 AI 教育产品,目标是帮大学生在期末复习时,从上传的课件里自动提取考点、生成复习材料。
听起来不复杂。但做到一半,卡住了。
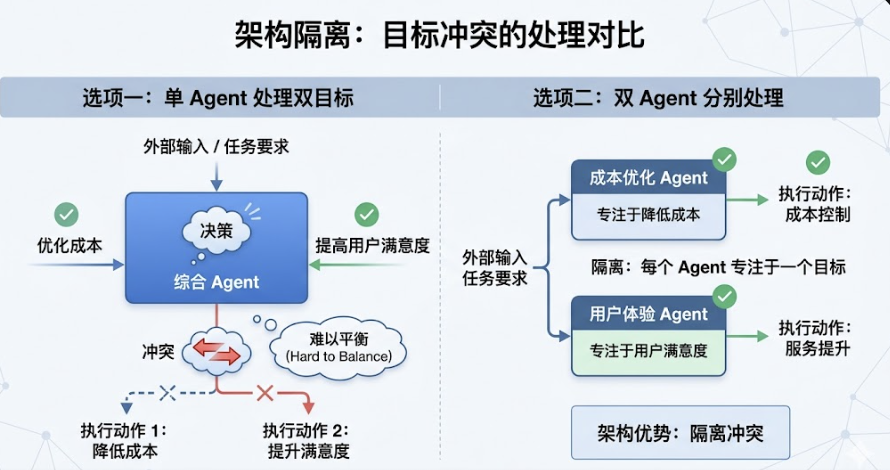
卡在哪里?同一套生成逻辑,给学生用要「通俗易记」,给教师用要「专业有区分度」。这两个目标表面上只是风格不同,实际上在模型里是相互撕扯的——让模型在同一个上下文里同时满足这两个要求,输出会系统性地劣化,两头都不讨好。
调 prompt 没用。加约束没用。换模型没用。
最后的解法是:把学生侧和教师侧拆成两个独立的生成 Agent,各自有独立的上下文、独立的 prompt 约束、独立的输出目标。两个 Agent 之间不共享状态,只共享上游解析层传递过来的结构化知识。
问题解决了。但当时我并不知道这个决策叫什么。
后来读到 Anthropic 和 OpenAI 关于 Harness 工程的博客,才意识到:我做的那个「拆 Agent」的决策,就是 Harness 工程里最核心的一个设计原则——用架构隔离目标冲突,而不是用 prompt 调和矛盾。
这不是巧合。几乎所有认真做过 AI 产品的人,都会在某个时刻遇到类似的困境,然后摸索出类似的解法。只是大家用不同的词描述它:「多 Agent 拆分」、「流水线设计」、「分层架构」……
说的其实是同一件事。
二、Harness 是什么:不只是「多 Agent」
在 Anthropic 的定义里,Harness = Agent 的运行容器 + 安全边界 + 调度控制器。
但这个定义太工程化,对产品经理来说更实用的理解是:Harness 是一套用来「补偿当前 AI 不擅长的事」的系统架构。
AI 不擅长长期记忆——Harness 用结构化文件和检索层来补。AI 在复杂任务里容易偏航——Harness 用任务分解和角色约束来补。AI 评价自己的输出太宽松——Harness 用独立的评估 Agent 来补。
Anthropic 在内部实验中发现,Claude 执行长周期代码任务时,一旦感觉到上下文窗口快填满,就会开始「上下文焦虑」——像快下班的打工人,疯狂敷衍,试图赶紧结束任务。更要命的是,它自己发现不了这个问题,让它评估那些「为了下班赶紧交差」的代码,它给出的评分依然是合格。
这种问题,提示词解决不了。它需要架构层面的干预:引入一个独立的评估 Agent,用真实的测试环境去检验输出,而不是让生成者自己给自己打分。
这就是 Harness 和「堆 prompt」的本质区别。Prompt 工程是在单个 Agent 的语言层做优化;Harness 工程是在多个 Agent 的系统层做设计。前者解决的是「这一步怎么说」,后者解决的是「谁负责哪一步、出错了怎么兜底」。
三、你已经在做的那些决策,都有了名字
让我列几个你可能做过或见过的产品决策,看看它们在 Harness 框架里叫什么。
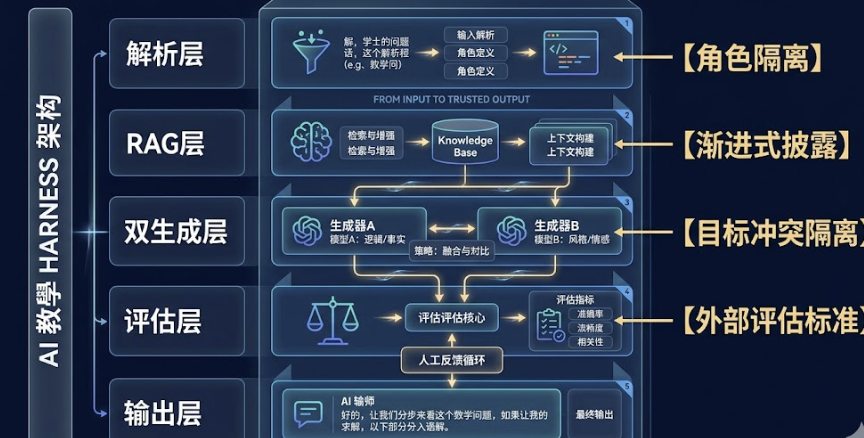
「把知识库放进 RAG 检索,而不是塞进 system prompt」——这是 Context 工程里的「渐进式披露」。把所有知识预加载进上下文,会让模型注意力涣散,大部分信息在当前任务里根本用不到。正确的做法是给模型一个「目录」,让它在需要的时候自己去检索对应的知识块。我在 AI teaching 项目里,把考纲权重放在 RAG 检索层而非直接注入 prompt,就是这个逻辑——不是所有信息都应该进 prompt,有些信息应该按需注入。
「引入人工审核节点」——这是 Harness 里的「安全边界」设计。不可逆的操作需要确认机制,高风险的输出需要人类介入判断。在 AI 教育场景里,AI 生成的出卷草案在交给教师之前,有一个教师审核确认的节点,这不是产品不够智能,而是 Harness 设计里必要的边界。
「定义可量化的验收指标」——这是 Harness 里的「外部评估标准」。我在项目里定义了三类验收指标:考点提取准确率、学生主观评分、教师出卷时间缩短幅度。这三个指标分别对应学生、教师、学校三方的价值主张。用外部的、可量化的标准强制 AI 系统接受检验,而不是在内部自我评价——这就是 Harness 里评估器角色的产品层映射。
「把解析层单独拆出来作为独立 Agent」——这是 Harness 里的「角色职责隔离」。课件质量差异是一个结构性问题:有的 PPT 逻辑清晰、层级分明;有的则是一堆碎片化的文字堆砌。用 prompt 描述「这份 PPT 可能逻辑混乱,请注意」是没用的,因为模型无法在生成阶段同时处理「解析质量差异」和「生成高质量内容」这两件事。把解析层独立出来,让它专门负责把各种质量的课件统一转化为结构化的知识表示,再传递给生成层——这才是架构层面的解法。
四、为什么现在需要这个命名
你可能会问:既然大家都已经在做了,这个命名有什么实际价值?
有,而且价值比你想的大。
第一,有了名字才能系统化传承。之前这些实践是分散的、依赖个人经验的。一个工程师摸索出「解析层要独立」,换一个团队可能又要重新踩一遍坑。Harness 这个概念把这些分散的实践统一到一个框架下,让团队可以用同一套语言讨论架构决策,让经验可以被结构化地积累。
第二,有了名字才能被系统性地质疑和迭代。这是 Harness 工程里最反直觉、也最重要的一个原则:你为补偿模型弱点而造的每一层,都应该带着一个到期日。
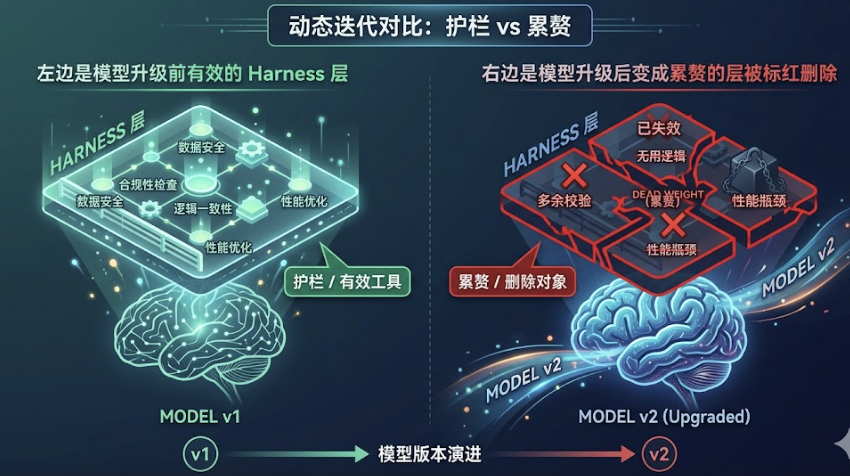
Anthropic 自己就经历了这件事。他们为对抗「上下文焦虑」设计的上下文重置机制,在升级到 Opus 4.5 之后发现新模型已经能自己处理这个问题了——那套重置机制直接成了 Harness 里的 dead weight,拆掉之后成本省了 37%。
没有命名之前,这些「为旧模型弱点设计的补偿层」是隐性的,很难被系统性地审视。有了 Harness 这个框架,你才能定期问:我们的哪些设计是真正的护栏,哪些已经是 dead weight?
第三,有了名字才能定义新的能力边界。Harness 工程的命名,实际上在重新定义 AI 时代产品经理和工程师的核心能力——不是写代码,不是写 prompt,而是设计 AI 的工作环境。OpenAI Codex 团队的实践把这件事做到了极致:所有代码由 Codex 写,工程师的工作是设计让 AI 能可靠工作的 Harness。这个能力之前是隐性的,现在它有了名字,也就有了被培养、被评估、被要求的可能。
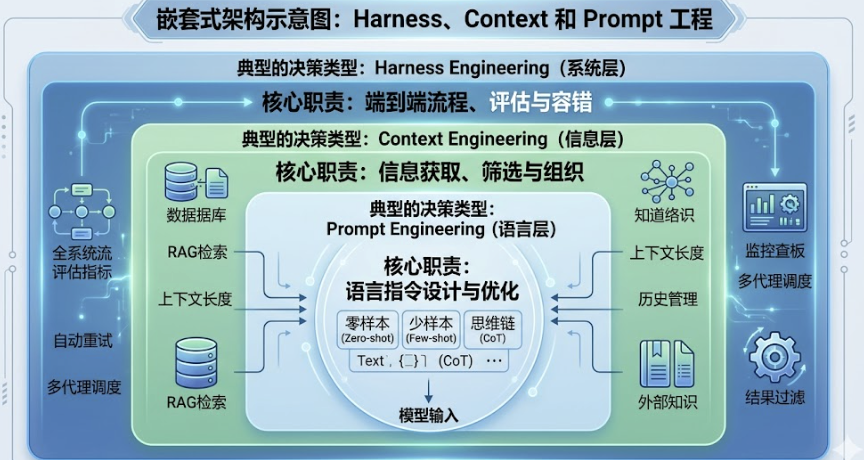
五、Prompt、Context、Harness:三层工程,各司其职
在很多团队里,AI 产品效果不好,第一反应是「prompt 写得不够好」,然后花大量时间在 prompt 上反复调优,效果依然有限。
根本原因往往不在 prompt 层,而在更上层的架构设计上。
这三者的关系是嵌套的,不是并列的:
Prompt 工程是单个 Agent 在「当下这一步」的语言层——它决定这个 Agent 怎么理解任务、怎么组织输出、用什么语气和格式说话。这一层决定的是单次交互的质量上限。
Context 工程是单个 Agent 在「当下这一步」的信息层——它决定这个 Agent 能看到什么信息、信息以什么顺序呈现、哪些信息应该按需注入而不是预加载。Anthropic 的数据显示,仅仅调整「让模型自己过滤工具输出」这一个 Context 层决策,在 BrowseComp 基准上准确率就从 45.3% 跳到了 61.6%,提升了 16 个百分点。
Harness 工程是多个 Agent 的系统层——它决定谁负责哪一步、步骤之间怎么传递信息、出错了怎么兜底、什么时候需要人类介入。这一层决定的是整个系统在复杂、长周期任务中的可靠性上限。
很多团队在 Prompt 层反复调优却效果有限,是因为问题出在 Context 层或 Harness 层,却被错误地归因到「prompt 没写好」。找对了层,才能在对的地方发力。
六、Harness 是动态的,不是一次性的架构设计
最后一个认知,也是最容易被忽视的。
很多人把 Harness 当作一次性的架构决策——设计好了就放在那里,等着模型来适配。但 Harness 工程的本质是动态的:它随着模型能力的进化,需要持续地被审视、被拆解、被重建。
Harness 编码的是「当前模型做不到什么」的假设。但这些假设会随着模型变强而过时。你为旧模型的弱点设计的每一层补偿机制,在新模型出来之后,都应该被重新问一遍:模型自己能做这件事了吗?能了,就干掉。
这对 AI 产品经理意味着一个新的工作习惯:每次模型升级,不只是测试新模型的能力边界,还要审视现有 Harness 里哪些层已经成了 dead weight。AI 产品的技术债,不只来自代码,还来自过时的 Harness 层。
Build to delete. 造了就要敢拆。
回到开头的那个问题:Harness 该怎么翻译?
我现在觉得,这个问题没那么重要了。
更重要的问题是:你现在的 AI 产品里,有没有一套清晰的 Harness 设计?你知道哪些层是真正的护栏,哪些已经是 dead weight?你的团队有没有一套共同语言,可以系统性地讨论这些架构决策?
提示词是战术,Harness 是战略。真正决定 AI 产品上限的,不是谁的 prompt 写得更好,而是谁能设计出更好的 AI 工作环境。
这个能力,现在有了名字。
本文由 @van ner 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


