
 起点课堂会员权益
起点课堂会员权益物理AI的终极武器:从“模型驱动”到“数据飞轮”的进化
在大模型时代,物理世界AI的竞争焦点正在从参数规模转向数据飞轮机制。本文深度解析Physical AI Data Flywheel的五大关键环节,揭秘如何通过仿真生成、数据增强、智能筛选、模型训练和缺口评估构建自进化系统,为自动驾驶与机器人行业提供可规模化的突破路径。

在大模型时代,我们习惯讨论参数规模、算力堆叠和模型架构创新。
但当 AI 真正进入物理世界——自动驾驶、机器人、智能制造——决定上限的,不再只是模型,而是数据飞轮(Data Flywheel)。
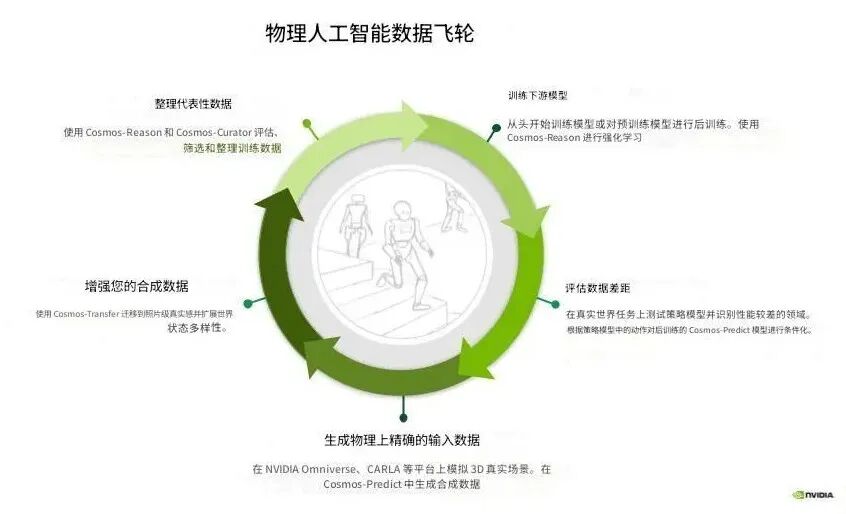
这张「Physical AI Data Flywheel」图,本质上揭示了一套面向物理世界智能的闭环增长机制。
它回答了一个关键问题:
如何让 AI 在真实世界中不断变强?
一、为什么“物理 AI”必须是数据飞轮?
在纯软件世界里,错误成本低,环境可控,反馈快速。但在物理世界中:
- 场景复杂度呈指数级增长
- 长尾场景不可穷举
- 真实采集成本高昂
- 安全性要求极高
因此,物理 AI 的核心不是“训练一次模型”,而是构建一个:
可持续迭代、自动发现问题、自动补齐数据、自动强化能力的系统。
这就是数据飞轮。
二、拆解Physical AI Data Flywheel的五个关键环节
1. 生成物理真实的输入数据
通过 3D 仿真平台构建高保真世界模型,例如:
- NVIDIA 的 Omniverse
- CARLA
在这些环境中可以:
- 构建完整物理约束(光照、碰撞、动力学)
- 获得精确 ground truth
- 快速扩展场景组合
这一步的核心价值是:
把“不可控现实”变成“可编排数据工厂”。
2. 增强合成数据(从可用到逼真)
仅有仿真还不够。
合成数据必须解决两个问题:
- 视觉真实感(Photorealism)
- 世界状态多样性(World Diversity)
通过数据迁移与增强模型,可以实现:
- 从结构化仿真 → 逼真视觉世界
- 从有限场景 → 组合爆炸扩展
这是从“工程数据”走向“可训练数据”的关键桥梁。
3. 精选与整理代表性数据
数据不是越多越好。
在物理 AI 体系中,真正稀缺的是:
- 关键长尾样本
- 决策边界样本
- 模型失效样本
通过数据批判、过滤与筛选机制:
- 删除低价值冗余数据
- 放大高影响样本
- 构建结构化训练集
这一步本质上是:用 AI 参与数据治理。
4. 训练下游模型(策略模型进化)
当数据被筛选后,进入策略模型训练阶段:
- 从零训练
- 或在预训练模型基础上强化学习
尤其在物理世界中:
强化学习 = 用环境反馈塑造决策能力。
策略模型不只是感知模型,而是:
感知 → 预测 → 决策 → 控制的综合能力系统。
5. 评估数据缺口(飞轮真正开始转动)
这是飞轮最关键的一环。
在真实世界或仿真闭环测试中:
- 找到性能下降区域
- 识别策略盲区
- 分析失败模式
然后反向驱动:
- 定向生成新场景
- 增强相关数据
- 再训练模型
这一步形成:
失败 → 数据 → 训练 → 再失败 → 再进化
飞轮开始持续加速。
三、为什么这套体系是 Physical AI 的终局形态?
传统 AI 开发流程是:
数据采集 → 训练 → 部署 → 结束
而 Physical AI 飞轮是:
生成 → 增强 → 筛选 → 训练 → 评估 → 再生成
这意味着:
- 数据生产自动化
- 数据评估自动化
- 问题发现自动化
- 模型强化自动化
真正进入“自进化系统”阶段。

四、对自动驾驶与机器人行业的启示
对于自动驾驶企业来说,这套体系意味着:
- 不再依赖纯真实路测规模
- 不再被长尾场景拖慢
- 不再线性增长
而是进入:
数据 × 仿真 × 模型的指数型飞轮增长
对于机器人行业,这更关键:
- 真实训练成本极高
- 物理交互风险大
- 可重复性低
仿真驱动的物理数据飞轮,是唯一可规模化路径。
五、未来核势
未来三年,Physical AI 的竞争,不再只是模型架构之争,而是:
- 谁拥有更强的仿真能力
- 谁拥有更高效的数据筛选机制
- 谁能构建真正闭环的数据飞轮
模型会趋同,飞轮则决定上限。
最后
大模型改变了语言世界。
但改变物理世界的,不是单次训练的模型,而是:持续旋转的数据飞轮。
谁能让飞轮转起来,谁就掌握了 Physical AI 的未来。
本文由 @OpenAIer 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


