
 起点课堂会员权益
起点课堂会员权益大模型面试/分析必备:从原理到面试题,一篇就够
大模型技术正重塑AI应用生态,但背后的Transformer架构、训练三阶段与RAG/Agent等核心概念仍令非技术从业者困惑。本文系统拆解LLM从预训练到RLHF的对齐逻辑,深入剖析检索增强与智能体两大应用范式,更提供数据构建方法论与高频面试题解析,助你跨越理论与实践的认知鸿沟。

最近大模型(比如豆包、Deepseek)概念很火,你是不是经常应用AI大模型去问答但对背后原理云里雾里?是否也经常听到“Transformer”、“微调”、 “RAG”、 “Agent” 这些词?
我在学习过程中系统梳理了LLM的核心原理、训练流程、RAG/Agent应用、数据构建方法以及面试常见问题。
这篇文章主要面向大模型分析师、产品经理、运营等非算法岗位,帮助大家建立从理论到实践的完整认知。无论你是扩展新兴行业知识面,还是准备求职面试,相信都能有所收获。建议收藏,随用随查。
第一部分:核心理论概念
1. LLM 基本架构与工作原理
大模型(LLM)通常基于Transformer 架构,其中最核心的是自注意力机制(Self-Attention)。通俗理解:当你读一句话“他昨天在公园遛狗”,你会下意识地把“他”和前面提到的人名关联起来。自注意力做的就是这件事——模型在理解一个词时,会并行“关注”句子中所有其他词,并计算每个词与当前词的相关度。这种机制使得模型能高效处理长文本、捕捉全局依赖。
工作流程简化版:
- 输入与嵌入:把每个词(token)转成一个向量(词嵌入),同时加入位置信息(位置编码)。
- 自注意力计算:为每个词生成三个向量:Q(查询)、K(键)、V(值)。用Q与所有K的相似度决定“该看谁”,然后用这些权重对V加权求和,得到融合了上下文的新向量。
- 前馈网络 + 残差连接:经过非线性变换,并通过“残差连接+层归一化”防止梯度消失,让超深网络也能稳定训练。
- 训练目标:通过海量文本进行无监督预训练,核心任务是 “预测下一个词”。模型在反复猜测中学会了语法、语义、事实知识乃至推理能力。
2.训练与对齐三个核心阶段
这是将一个“博学的学生”培养成“专业且可靠助手”的过程。
预训练
- 目标:让模型学习语言的统计规律和世界知识,建立一个广阔的知识基础。
- 方法:在海量无标注文本上训练模型,让其完成“下一个词预测”任务。
- 数据影响:这是模型能力的基石。数据的规模、质量、多样性和新鲜度直接决定了模型知识库的广度与深度、语言建模能力以及内在的推理能力。所谓 “Garbage in, Garbage out”,此阶段的数据缺陷是根本性的。
- 案例:如果预训练语料中缺乏高质量的金融文本,模型在回答关于“期权定价”的问题时,就很可能出现事实性错误或无法理解专业术语。
有监督微调(SFT)
- 目标:教会预训练模型如何遵循人类的指令,以特定的格式(如对话)进行交互。这是“对齐”的第一步。
- 方法:使用高质量的(指令, 期望输出)配对数据,对预训练模型进行有监督训练。
- 数据影响:决定模型的指令遵循能力、回答风格与格式、以及特定领域的专长。SFT数据的质量是模型对话能力的天花板。
- 案例:通过向模型投喂大量如(指令:”请总结以下文章…”, 期望输出:”本文主要讲述了…”)的高质量数据,模型才学会了“总结”这个技能,并按照要求的格式输出。
基于人类反馈的强化学习(RLHF)
- 目标:让模型的回答在“正确”的基础上,更符合人类的价值观和偏好,即更安全、更有用、更人性化。
- 收集人类反馈:给定一个指令,让标注员对模型生成的多个回答进行质量排序(例如 A > D > B > C)。
- 训练奖励模型:利用成千上万条这样的排序数据,训练一个能够判断回答好坏的奖励模型。这个RM学会了给符合人类偏好的回答打高分。
- 强化学习优化:使用PPO等强化学习算法,以SFT模型为初始策略,以RM为奖励信号,优化模型参数,鼓励其生成能获得RM高分的回答。同时,一个KL散度惩罚项会防止模型变得“面目全非”,偏离其在SFT阶段学到的良好基础。
- 数据影响:精细地雕刻模型的价值观、安全边界和审美偏好。它可以修正SFT阶段可能存在的偏见,或让模型在“忠实于知识”和“满足用户需求”之间做出更佳权衡。
- 案例:RLHF前,模型可能会直接生成一个复杂的法律文书模板。RLHF后,模型会先解释相关法律要点,然后强烈建议用户咨询专业律师,并附上免责声明。这个更“负责任”的行为,就是通过偏好数据教导给模型的。
关键认知:预训练决定模型“智商”的上限、SFT教会模型“对话格式”和“基础技能”、RLHF塑造模型的“价值观”和“情商”。
3. 两大应用范式:RAG vs. Agent
RAG(检索增强生成)
- 核心思想:在模型生成答案前,先从外部知识库中检索相关信息,作为上下文增强用户问题,再交给模型生成答案。
- 核心价值:解耦“知识记忆”与“生成推理”。模型不用死记硬背所有知识,知识库可随时独立更新,有效缓解知识陈旧和模型幻觉。
- 数据关键点:知识库必须权威干净;检索质量依赖嵌入模型和文档切分策略;需要同时评测答案正确性和检索相关性。
AI Agent
- 核心思想:大模型作为“大脑”,能够理解复杂任务、规划执行步骤、调用外部工具(计算器、API、搜索引擎等),并执行行动。
- 案例(法律咨询Agent):理解用户劳动纠纷 → 规划所需信息 → 调用法律知识库RAG检索《劳动合同法》条款 → 调用案例API查类似判决 → 调用赔偿计算器 → 合成信息生成《法律咨询摘要》。
一句话区分:
RAG:给模型配一个“随时可查的资料库”。
Agent:让模型成为“能干活的大脑”。
4. 高质量数据构建(进阶篇)
什么是“高质量数据”?通用核心定义:高信息密度、低噪声、强目标对齐。具体因阶段而异:
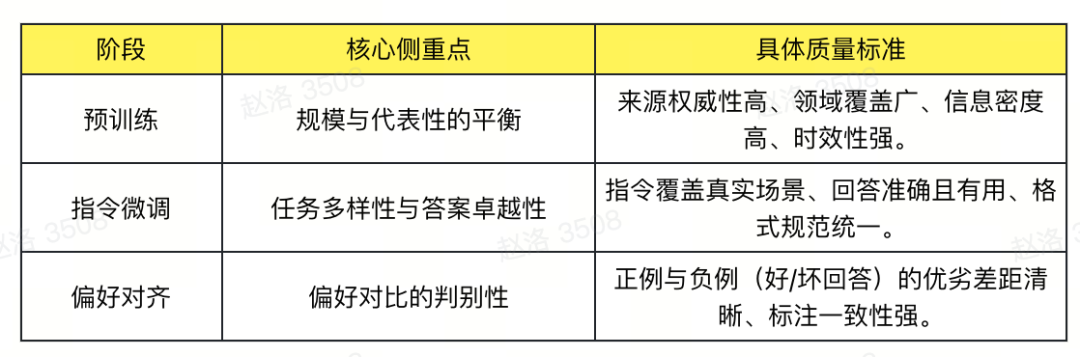
这些方法共同构成了一个 “AI增强、人机协同” 的智能化工程体系:
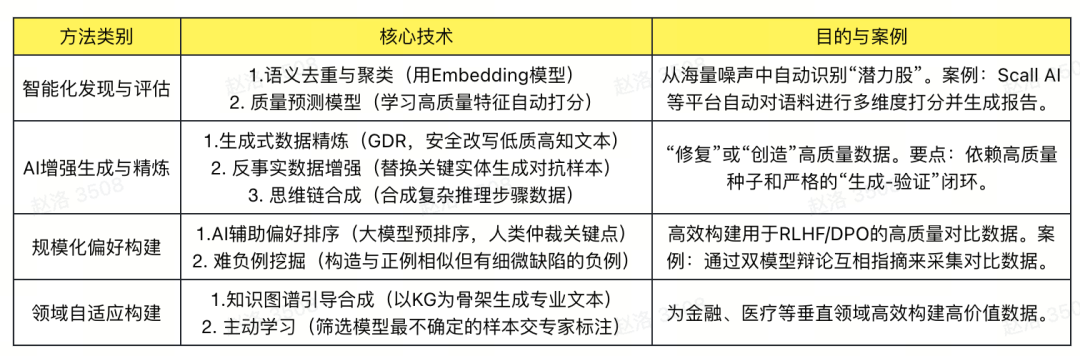
合成数据:价值与风险管控
- 价值:填补隐私敏感领域(如医疗、金融)和长尾场景的数据空白、精准定制特定能力(如多步推理)、大幅降低标注成本。
- 风险与管控:模型崩溃:过度依赖合成数据导致输出退化。→管控:合成数据占比≤30%;与真实数据混合;动态过滤低质样本。
- 分布偏移:合成数据与真实业务分布不一致。→管控:基于真实数据特征做规则约束,定期做分布校验(如KL散度)。
- 合规风险:隐含敏感信息。管控合成前脱敏,合成后实体识别二次核查。
数据质量与效率的平衡(经济学视角 + ML视角)
- 经济学视角:边际收益(MR)= 边际成本(MC)时最优。数据准确率从85%到90%成本可能翻倍,从95%到98%成本增加五倍。
- 平衡策略:分阶段投资(早期用低成本数据快速验证,产品化时投资优质数据);对关键类别(如罕见病诊断)投入更多资源。
- 机器学习视角:在固定预算下,数据量(N)与数据质量(Q)之间分配资源,最小化泛化误差。
- 前沿实践:课程学习(从简单干净数据到复杂噪声数据)、主动学习(优先标注模型“最不确定”的数据)、噪声感知训练等。
- 整合动态框架:探索期(经济学优先)→ 扩展期(工程效率优先)→ 成熟期(ML优先)。最终,平衡不是静态妥协,而是基于明确目标和实时指标的动态优化。
5. PE打标(提示词工程)
PE打标(Prompt Engineering for Annotation) 的确切含义是:一个系统性的工程流程,其核心是利用和优化提示词工程,来高效、高质量地完成数据标注任务。它包含两个层面:
第一层:为“优化提示词”而进行的打标(打标的对象是“提示词”)
- 目的:不是直接生产业务数据,而是为了找到某个任务下最优的Prompt。这是“提示词工程”本身的研究活动。
- 过程:对同一个任务设计多个不同的Prompt变体 → 让模型生成不同结果 → 人工或AI裁判对这些结果进行质量打分(这就是“打标”) → 分析哪个Prompt得分最高,从而沉淀出最佳Prompt模板。
第二层:用“优化后的提示词”去为海量任务打标(打标的对象是“业务数据”)
- 目的:这是将PE能力应用于实际生产,批量生成训练或评估数据。
- 过程:针对某个标注任务(例如“判断回答是否含有广告”),我们已经通过第一层研究找到了一个可靠的Prompt → 用这个设计好的Prompt,去指挥大模型为成千上万条数据自动分类或打分。
总结一下两者的关系:
第一层(研究性) 是因,目标是找到好用的“指令”(Prompt)。
第二层(生产性) 是果,利用这个好用的“指令”去规模化地完成标注工作。
案例:为内部客服助手优化问答提示词
目标:提升模型从知识库中提取答案的准确率和完整性。
打标流程:
- 设计变体:针对“查询产品退货政策”任务,设计20个提示词变体,变量包括:是否要求引用原文、是否先理解用户场景、回答格式等。
- 批量测试:用100个历史用户真实问题,分别用20个提示词变体提问,获得2000个回答。
- AI打标:使用GPT-4作为裁判,为每个回答在“准确性”(是否与官方政策一致)和“完整性”(是否覆盖关键条款)上打分。
- 分析发现:带有 “请先判断用户意图,然后严格引用知识库原文相关段落,最后进行总结” 结构的提示词,平均得分显著高于其他变体。
- 成果:将该提示词模板固化到客服系统中,使答案的准确率从75%提升至92%。
第二部分:面试问题与参考答案(精选)
以下问题适合大模型分析师、产品、运营等岗位的面试准备。
一、基础概念类
Q1:大模型训练的三个阶段分别是什么?各自的能力提升关键点是什么?
参考答案:
大模型的训练分为三大核心阶段,各阶段目标、数据特点和能力提升关键点差异显著:
预训练阶段
核心特点:目标是让模型学习通用语言规律和海量知识,数据为无标注的通用/领域广谱文本(如网页、书籍、论文),数据规模达万亿token级别;
能力提升关键点:一是保证数据的领域广度和分布均衡,避免知识盲区;二是优化tokenizer的分词效率和语义覆盖率;三是通过大批次训练、混合精度优化提升模型对通用知识的拟合能力,核心评测指标为困惑度(PPL)、下游任务零样本/少样本准确率。
指令微调阶段
核心特点:目标是让模型理解人类指令意图并生成符合格式的回复,数据为标注的指令-回复对/多轮对话,数据规模百万到千万级别;
能力提升关键点:一是数据需高度贴合真实用户指令的形式(如包含多轮追问、工具调用需求);二是统一指令格式(如 {“instruction”:”xxx”, “input”:”xxx”, “output”:”xxx”} ),降低模型格式学习成本;三是按能力维度(推理、创作、总结)分层训练,核心评测指标为指令遵循度、回复相关性。
RLHF(基于人类反馈的强化学习)阶段
核心特点:目标是让模型输出符合人类偏好的高质量回复,数据为人类标注的回复质量排序/奖励分数,分为奖励模型训练和强化学习两个子阶段;
能力提升关键点:一是标注数据需覆盖多样化的偏好维度(如安全性、有用性、流畅性);二是奖励模型需避免过拟合标注数据,防止模型“讨好”标注标准而偏离真实用户需求;三是通过PPO等算法平衡模型能力与偏好对齐,核心评测指标为人类偏好评分、安全风险触发率。
Q2:RLHF是否更容易带来模型“提分”?
参考答案:不一定。需要区分能力型评测(MMLU, GSM8K等)和对齐型评测(MT-Bench, 安全性等)。能力型评测:RLHF通常不会显著提分,有时甚至轻微降分(因为优化目标是“人类偏好”,可能与标准答案冲突)。对齐型评测:RLHF几乎总是带来巨大提升。结论:RLHF的主要目标是对齐,而非客观能力提升。不能简单说“更容易提分”。
二、数据分析与归因类
Q3:模型在回答新能源汽车问题时频繁出现事实性错误,如何从数据角度分析优化?
参考答案:遵循“定位-回溯-假设-验证”四步法。
量化错误率,分类错误类型(政策时效、地域适用、金额错误等)。
回溯预训练数据(是否包含最新权威政策文件)、SFT数据(是否有足够多的高质量政策问答对)。
提出假设:知识陈旧 → 更新预训练语料或引入RAG;指令遵循能力不足 → 构造高质量SFT问答对。
设计专项评测集,对比优化前后准确率。
Q4:为什么模型在Benchmark上得分高,但用户体验差?
参考答案:采用“指标拆解→数据溯源→场景匹配”三步法。
指标拆解:Benchmark侧重通用推理,应用侧可能是垂直领域(如医疗),导致错配。
数据溯源:若垂直领域差,核查预训练阶段领域数据占比及SFT阶段专业样本数量。若话术风格不符,核查SFT数据的话术模板。
针对性优化:补充垂直领域高质量标注数据,搭建业务专属评测集,结合Benchmark和业务评测做联合评估。
Q5:如何处理“会话长度上升但用户满意度不变甚至下降”的矛盾现象?
参考答案:维度下钻 + 案例深挖。
按用户分层(新用户 vs 老用户)、会话类型(任务型 vs 闲聊型)、话题分层。
抽样人工分析,归因:模型幻觉需要不断纠正?理解偏差导致重复?生成内容冗长不精炼?
若大部分属于冗长或理解偏差,问题可能出在SFT数据的简洁性和指令遵循能力上,建议优化对应数据。
Q6: 现在豆包COT比较长,如果想维持推理性能不变,但减少COT长度,可能可以从哪些角度入手?
参考答案:不一定。需要区分能力型评测(MMLU, GSM8K等)和对齐型评测(MT-Bench, 安全性等)。能力型评测:RLHF通常不会显著提分,有时甚至轻微降分(因为优化COT(思维链)是一种引导大模型进行复杂推理的技术。其核心是在输入中提供少量(或通过指令激发)逐步推理的示例,从而激发模型模仿这种“问题-分步推理-最终答案”的输出模式。它将一个需要多步计算的复杂问题,分解为一系列中间步骤,有效提升了模型在数学、逻辑、常识推理等任务上的性能。如何减少COT长度同时保持性能?这是一个经典的“推理效率”优化问题。可以从以下几个角度入手:
数据与训练层面:提炼高质量、简洁的COT示范:分析现有长COT数据,识别哪些步骤是冗余的、重复的或解释性过强的。请专家或通过自蒸馏技术,生成更精炼、逻辑跳步更合理但结论正确的COT数据,用这些数据对模型进行微调。进行“简洁性”偏好训练:在RLHF阶段,除了“正确性”偏好,额外加入“简洁性”偏好。即,在奖励模型中,对同样正确的两个回答,更短的给予更高奖励。这可以直接引导模型产出更紧凑的推理链。提示工程与解码策略层面:优化COT提示词:在Few-Shot示例中,使用本身就非常简洁的推理示例。在指令中明确要求“用最少的必要步骤进行推理”或“避免重复和冗述”。后处理与压缩:允许模型先生成完整的(可能较长的)COT,然后设计一个轻量级的“反思与压缩”模块,让模型自己总结或删减推理步骤,保留核心逻辑链路。
模型架构与推理优化:
探索更高效的推理结构:例如,引导模型使用符号化或更抽象的语言进行推理,减少自然语言描述中的冗余。潜在方向:研究是否可以通过条件生成来控制COT的粒度,例如在生成时指定“推理深度”或“步骤数”超参数。
核心思路:本质是在不损失信息量(关键逻辑跃迁)的前提下,压缩语言表达。这需要结合高质量数据重建和基于偏好的行为调优。
Q7:如何使用数据视角定位模型缺陷,提出并推动有效的优化策略?
参考答案:遵循一个‘观测-定位-归因-施策-验证’的闭环流程来定位和优化模型缺陷。首先,多维定位。我不会只看单一指标,而是结合评测集横向对比、版本纵向对比,并对Bad Case进行聚类分析(这和我之前做用户反馈聚类归因一样),将问题归纳为知识、推理、安全等几大类根因。
然后,数据归因。我会追溯训练数据,分析缺陷是否对应数据缺口、质量低下或分布偏差。例如,如果发现法律推理差,我会去查法律类数据的占比和质量。
接着,提出精准策略。基于归因,我会提出像‘补充高质量法律COT数据’或‘优化安全对齐的RLHF数据’这样的具体方案。在这里,我会用类似之前做ROI模型的思路,评估不同数据策略的预期收益与成本。

最后,也是最重要的一步,实验驱动落地。设计一个小规模数据实验,比如将新数据以5%的比例进行增训,然后用一个严格的评估框架来衡量其真实效果。只有数据验证有效的策略,才会推动全面上线,并持续监控。
这套方法的核心在于,它把模型优化从一个‘黑盒调参’过程,变成了一个可分析、可解释、可验证的数据科学工程闭环。”
三、数据方案与基准构建类
Q8:如何从零构建一个SFT数据集(以“法律咨询”场景为例)?
参考答案:采用“专家牵头、人机协作、多重质检”流程。
- 数据设计:与法律专家定义场景(劳动纠纷、合同审查等)和边界(什么必须建议咨询律师)。
- 数据生产:专家撰写种子答案 → 大模型生成候选 → 法律背景标注员修改优化。
- 质量保证:专家抽查 → 交叉审核 → 模型一致性校验。
- 效果评估:准确性(事实错误率<1%)、有用性(95%的答案直接解决问题)、安全性(100%不包含过度承诺)。
- 工具支持:模板化指令生成、答案自动初筛、质检看板。
Q9:如果给你一笔预算,用于提升模型“多轮复杂对话中维持角色一致性”的能力,如何分配?
参考答案:按照7:2:1比例分配:
- 70% 数据工程:投资构建高质量角色扮演对话数据集。重点不是简单标注,而是聘请编剧撰写种子对话 → AI扩展(角色、话题转换)→ 设计“一致性”偏好标注(例如第十轮对话是否违背第一轮的性格)。
- 20% 评测基准:开发自动化评测工具,用量化指标(如人格特征向量一致性、知识回溯准确性)评估效果。
- 10% 算法实验:探索角色记忆模块或损失函数优化(高风险)。核心思路:用数据定义问题,用评测驱动迭代,算法作为辅助。
Q10:如何看待合成数据的价值与风险?如何设计合成方案弥补多步推理短板?
参考答案:价值:填补长尾、精准定制、降低成本。风险:模型崩溃、分布偏移、合规问题。管控:混合训练(合成≤30%)、动态过滤、多样性激励、生命周期管理。
针对多步推理短板:
方案设计:种子数据(优秀推理样本)→ 变化实体/条件生成新问题 → 用可执行验证器(如代码解释器)确保逻辑正确 → 加入“红队”合成负例(中间步骤设置逻辑陷阱)。
防崩溃:合成占比≤20%;引入鉴别器过滤低质数据;小比例A/B测试验证正向收益后再全量使用。
第三部分:总结与延伸
大模型的世界远不止这些,但掌握了以下核心骨架,你已经超越了90%的初学者:Transformer + 自注意力→ 并行处理、全局依赖。预训练 → SFT → RLHF→ 知识、技能、价值观。
- RAG vs. Agent→ 查资料 vs. 动手干。
- 高质量数据→ 基石,合成数据是放大器但有风险。
- 数据与模型的平衡→ 分阶段、看ROI、动态优化。
如果你是大模型分析师或产品经理,建议进一步关注:
- 评估体系设计(如何构建三层评估:基础能力层、用户体验层、场景深度层)
- 数据飞轮(如何从用户反馈中构建数据迭代闭环)
- 模型能力平衡(创造性与事实性、流畅度与知识性的 trade-off)
本文由@赵小洛 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自 Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


