
 起点课堂会员权益
起点课堂会员权益工业AI落地失败,90%不是技术问题 一个让甲乙双方都不舒服的真相
工业AI项目的失败率高达91%,技术瓶颈并非主因,真正的挑战隐藏在需求错位、数据混乱与组织滞后的三重困境中。本文通过真实案例与行业数据,揭示工业AI落地难的深层次原因,并指出那些成功突围的9%项目背后的关键策略。

一、先说一个让人沉默的数字
德勤做过一项专门针对中国制造业AI项目的调查。
结果只有一个数字值得记:认为项目达到80%-100%预期的企业,只有9%。
换句话说,91%的工业AI项目,没有达到预期。
这9%不是个例,是行业平均水平。
如果你在工业AI圈子里待过,这个数字不会让你惊讶——它只会让你沉默一下,然后点头。每个人都见过”PPT上很美好、现场一地鸡毛”的项目。大家默认工业AI落地难,但鲜少有人追问:它到底难在哪里?
多数人的第一反应是:技术不够成熟、模型精度不达标、算力成本太高……
这些答案不能说错,但它们是表象。
真正让工业AI项目死掉的,往往不是技术——而是技术之外的三件事:需求错位、数据烂摊子、组织没跟上。
二、第一个真相:需求错了,技术再好也没用
工业AI项目最常见的死法,不是做不出来,而是做出来了没人用。
有一个真实案例流传甚广:某大型制造企业投入数百万,开发了一套”企业知识助手”,初衷是让员工随时查询公司政策。项目上线三个月,日活跌到个位数,最终被叫停。
事后复盘只有一句话:员工的真实痛点不是查休假政策(低频需求),而是生产线上的设备故障诊断(高频、高价值需求)。
两个需求,一字之差,方向完全相反。
工业场景为什么特别容易出现这种错位?
工业AI项目的需求通常经过了至少三层传递:决策层拍板立项→信息化部门提需求→技术供应商来实施。每过一层,需求就模糊一分。等项目真正开始,做的东西和一线工人的实际痛点,可能已经没有任何关系。
更麻烦的是,工厂里懂业务的人(老师傅、班组长)往往不会写需求文档;会写需求文档的人(信息化部门)往往不懂生产流程。
于是,技术团队拿着一份”正确但没用”的需求文档,做出了一个”功能完整但没人用”的系统。
三、第二个真相:数据不是”有”就行,而是要”可用”
工业AI的另一个高频死法,叫”数据陷阱”。
很多工厂在立项的时候,都会说:”我们数据很多,传感器装了一大堆,SCADA系统也有,完全够用。”
然后项目真正启动,数据工程师进场,才发现——
传感器数据有,但格式五花八门,不同设备、不同年代、不同厂商,根本无法直接拼接。SCADA系统的数据能看但没法用,实时数采上来,却和ERP、MES系统完全割裂。历史数据有,但标注全靠人工,懂标注的老师傅三年前就退休了。至于缺陷样本,正常品几十万张,缺陷品只有二十几张——模型根本训不出来。
工业AI从业者之间流传着一个段子,听完就懂:
算法ok,部署ok,标注-训练-部署的闭环也ok。然后客户问:每次更换型号,能不能不训练?
这不是在刁难乙方,这是工厂的真实诉求——产品型号可能每周都在换,重新训练模型意味着停产等待,成本无法接受。
数据问题的本质,是工业场景几十年的历史欠债。过去工厂的建设逻辑是”能生产就行”,数据从来不是核心资产,高质量的可训练数据几乎没有积累。现在想用AI,才发现地基根本没打。
英特尔的调研数据印证了这一点:企业AI落地面临的六大挑战中,”数据安全顾虑”和”现有系统与AI工具整合困难”均高频出现,而这两者本质上都是数据基建缺位的结果。
不是AI不行,是数据的底子根本没打好。
四、第三个真相:技术交付了,但组织没准备好接
假设需求对了,数据也有了,模型也跑通了。
然后呢?
很多工业AI项目倒在了最后一步:系统上线了,但工厂的人不会用、不想用、用了也没人管。
- 工人不会用电脑。 有从业者分享,去工厂培训数据标注,找来的是有十几年经验的目检老手,结果到了现场才发现——他不会用电脑。AI系统的操作界面对他来说是陌生语言。
- 老师傅不信AI。 识别系统准确率已经达到99%,但工人看到AI判”良品”,还是要拿起来自己再看一遍。不是系统不准,是人没有建立信任。这不是培训两天能解决的问题。
- 系统上线,但没人维护。 乙方交付完撤场,工厂没有人懂怎么迭代模型、怎么处理新增缺陷类型。系统慢慢”退化”,准确率下降,最后被悄悄关掉。
制造业的AI落地,还面临一个互联网行业根本不存在的挑战:”整合成本”极高。软件系统更新,推一个新版本就完成了。但工厂引入AI,往往意味着旧设备改造、新设备安装、生产流程重排、工种重新定义、岗位培训……每一步都涉及真实的停产成本和人的阻力。
这是变革管理的问题,跟算法精度没有关系。
五、那么,技术本身呢?
说了这么多,可能有人会问:技术本身真的完全没问题吗?
当然不是。工业AI在技术层面确实有真实的硬骨头。
工业数据的小样本困境:消费场景可以靠海量数据堆,但工业缺陷可能一年才出现几十个样本,传统深度学习根本训不出可靠模型。毫秒级的实时推理要求边缘计算能力远超一般部署场景。光线变化、设备磨损、原材料批次差异,持续侵蚀模型的泛化能力。更不用说那个根本性的刚性——消费AI出错,用户刷新重试;工业AI出错,可能是一批废品,甚至是安全事故。
技术挑战是真实的。但项目在触及技术天花板之前,大多数早就死在了需求不清、数据不通、组织没跟上这三道坎上。
打个比方:工业AI失败,很少是因为运动员能力不够,更多是因为还没上场就在更衣室里吵架、找不到鞋、或者根本搞错了比赛项目。
六、为什么工业比金融、互联网难那么多?
同样是AI落地,金融行业的成功率远高于工业。原因不是金融公司的技术团队更强,而是结构性的差异:
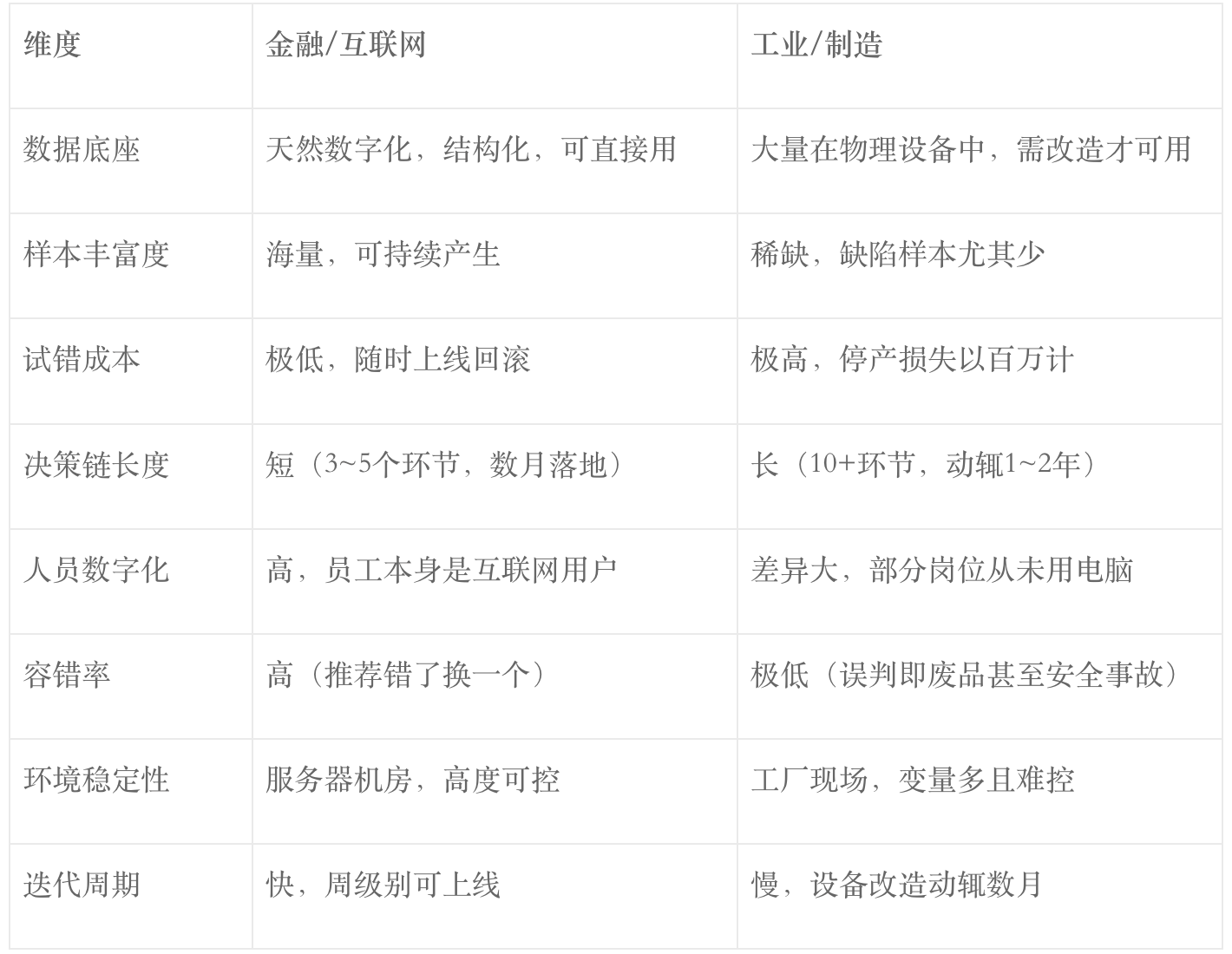
每一个维度,工业都是更硬的模式。换一个更聪明的模型,解决不了数字化底座缺失、组织变革阻力大这些本质矛盾。
七、什么样的工业AI项目能活下来?
那9%的成功案例,有几个共同点值得拆。
从小场景切入,不要上来就做”智慧工厂全面升级”。 找一个具体、高频、数据相对干净的场景——比如某一类零件的某一种缺陷检测,验证完再复制。
需求要有一线工人参与定义,不能只靠管理层拍板。 成功的项目,一定有一个懂业务的”内部推动者”,既能翻译工厂语言,也能和技术团队对话。没有这个人,项目大概率失控。
数据治理要放在AI项目之前,而不是之后补。 不是”先上AI,再补数据”,而是”用AI场景牵引数据治理”——先把一个场景的数据梳理清楚、建立标准,再谈模型。
交付不是终点,运营才是。 成功的工业AI项目,乙方在交付后仍然保持深度参与,帮工厂建立自己的模型迭代能力,而不是一次性交付完走人。
八、结语:技术不背这个锅
91%的工业AI项目没有达到预期,这口锅不该全扣在技术头上。
需求没定准、数据底子薄、组织没准备好——哪一件出了问题,都足以让一个技术上完全可行的方案彻底失败。
甲方不愿听的是:你们的问题不是不懂AI,是不懂自己的业务和数据。乙方不愿听的是:技术能力不是核心壁垒,深入场景的工程能力才是。整个行业都不愿承认的是:工业AI不是一个”技术成熟了就自然爆发”的赛道,它需要艰难的、一个场景一个场景的磨合。
工信部的专家说,AI将以”小步快跑”的态势在制造业落地,从完成简单任务到实现高级功能。
这话听起来保守,但是实话。
工业AI的战场不在实验室,在车间。车间里最难攻克的敌人,从来不是算法——是那些年久失修的数据孤岛,是搞不清楚需求的沟通鸿沟,还有那个不会用电脑、但缺陷检出率比你的AI还高的老师傅。
本文由 @正正 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议





- 目前还没评论,等你发挥!


