
 起点课堂会员权益
起点课堂会员权益特斯拉高薪招标注员背后,藏着所有AI产品经理必须懂的数据飞轮逻辑
特斯拉以90万年薪招聘数据标注员的背后,藏着AI行业最残酷的竞争逻辑。当自动驾驶和人形机器人都在争夺真实世界的数据时,标注质量直接决定了模型能力的上限。本文深度解析特斯拉为何拒绝外包、自建标注团队的战略选择,以及数据标注行业正在发生的两极分化,揭示AI产品最容易被忽视的生死线。

这几天刷到一条消息,特斯拉急招数据标注员,年薪最高13万美元,折合人民币将近90万,朝九晚五,不需要AI经验
我当时看到这个,第一反应是:这不对劲
一家以自动驾驶AI著称的公司,花这么多钱,去招一个”不需要AI经验”的人,专门负责在图片里框框画画?
你没看错——特斯拉宁愿花90万年薪,也不愿意把这件事外包出去
这事儿怎么想怎么奇怪
但越想越觉得,这条招聘信息背后藏着的东西,比表面上有意思多了
数据标注,AI产品真正的地基
先说说数据标注是干什么的
简单来说,就是教AI”看懂”世界。在视频里框出行人,标注车道线,标记红绿灯的状态,识别路边的障碍物。听起来很简单对吧,拖个框,打个标签,谁不会
但我做AI产品这几年,越来越觉得这件事被严重低估了
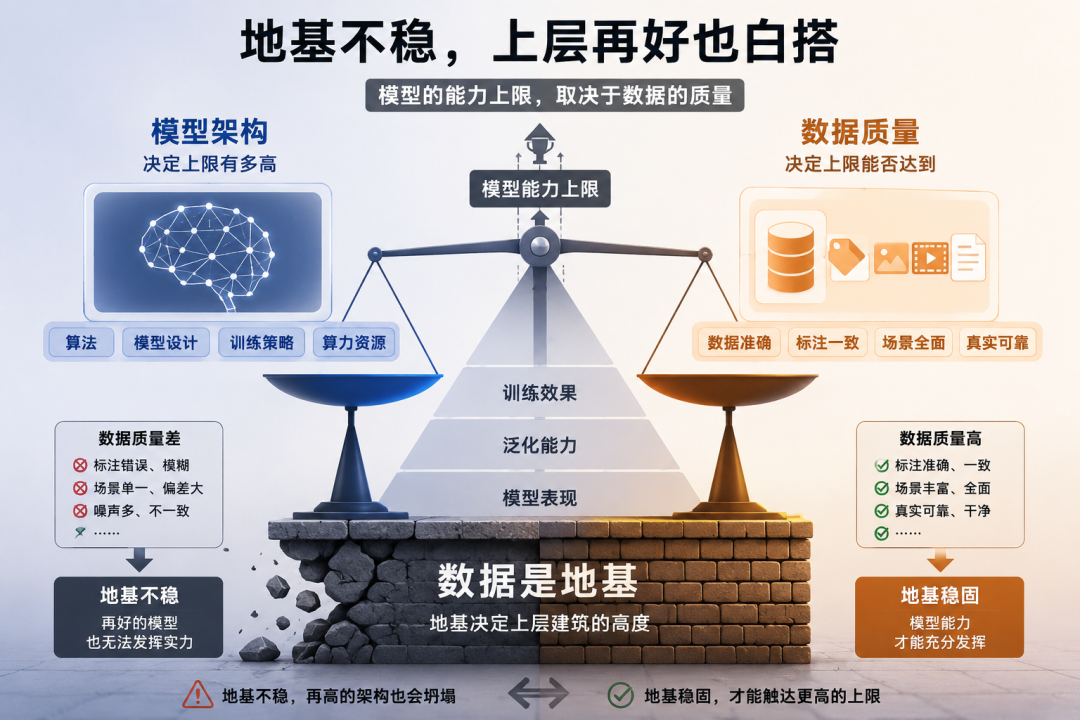
前特斯拉AI负责人Karpathy说过一句话,我一直记着:”模型决定上限,数据帮模型到达上限。标注质量差,再好的模型架构也白搭。”
这句话说的太准了
换句话说:你以为在招廉价劳动力,特斯拉其实在买它最贵的东西——模型能力的天花板
我之前做过一个视觉识别的功能,当时模型选的很好,架构也没问题,上线之后效果一直上不去。后来排查了很久,发现根源在标注——同一个场景,不同的标注员给出的框位置差了好几个像素,有的人把半遮挡的物体标上了,有的人没标,标准完全不统一
模型就是在这种混乱的数据里训练出来的,能好才怪
所以当我看到特斯拉内部维持着千人规模的标注团队,处理60亿个object label、1.5PB的数据,我一点都不觉得夸张
这不是在烧钱,这是在建地基
为什么特斯拉不外包
这是我觉得这篇招聘信息里最值得琢磨的地方
市面上专业的数据标注机构多的是,按件计费,成本低,速度快,理论上完全可以外包出去。特斯拉为什么非要自己招人,自己建团队,还要求现场办公?
JD里其实已经给出答案了,只是需要你仔细读
数据保密
车队回传的是真实的生产环境数据,包含用户驾驶的真实场景。这些数据一旦流出去,麻烦就大了。自建团队、用内部工具、要求线下办公,这是三道保险,缺一不可
这三道保险背后的逻辑是:数据安全不是技术问题,是产品生死问题
我做AI产品的时候也遇到过类似的问题。有一次我们想把一批用户行为数据外包给第三方做清洗,法务直接拦住了,说涉及用户隐私,不能出公司。最后只能内部解决,效率低了很多,但没办法
数据安全这件事,在AI产品里的优先级,比大多数人想象的要高得多
标注标准的一致性
外包团队的问题是流动性太高。今天这批人,明天可能换一批。每换一批人,培训成本就来一遍,更要命的是标准会漂移
什么叫标注标准漂移?就是同样一个场景,前三个月标注的方式,和后三个月标注的方式不一样了。模型在这种数据里训练,学到的东西是混乱的
一套前后不一致的标注数据,比没有数据更危险——因为你根本不知道模型学歪了
特斯拉要求标注员懂交通规则,因为车道线的标注逻辑、复杂路口的判断标准,只有真正理解路况的人才能做对。这不是随便找个人培训几天就能搞定的
工具迭代的闭环
这个是我觉得最有产品思维含量的一点
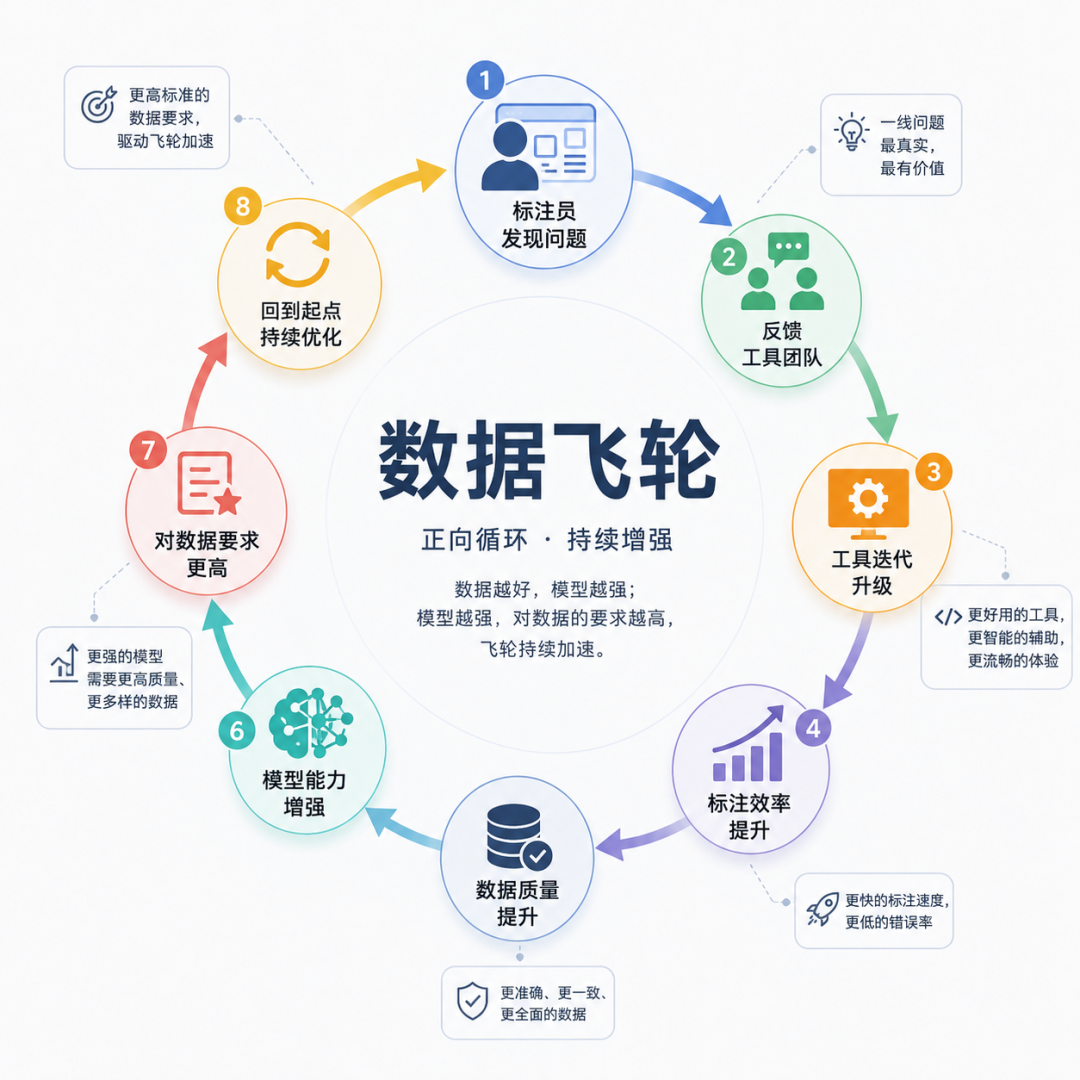
JD里有一条要求,标注员要参与改进标注工具
你想想这意味着什么。一线的标注员在用工具的时候发现了问题,这个反馈可以直接回流到工具开发,工具迭代了,标注效率和质量就提升了,数据质量提升了,模型就变好了,模型变好了对数据的要求又更高了……
这是一个真正意义上的数据飞轮
外包团队做不到这个,因为他们用的不是你的工具,他们的反馈也不会流回你的系统
这份JD里藏着一个更大的信号
特斯拉这次招聘,明确服务两个方向:FSD和Optimus
FSD就是完全自动驾驶,这个大家都知道。但Optimus这边有个细节,是我第一次在特斯拉的公开招聘里看到的——JD里首次出现了”Optimus Data Collectors”这个词
这五个字,意味着人形机器人已经开始大规模采集真实世界数据了
这意味着什么?
意味着人形机器人Optimus已经在工厂或者测试场地部署了专门的数据采集设备,正在大规模回传原始素材,等着人工来标注
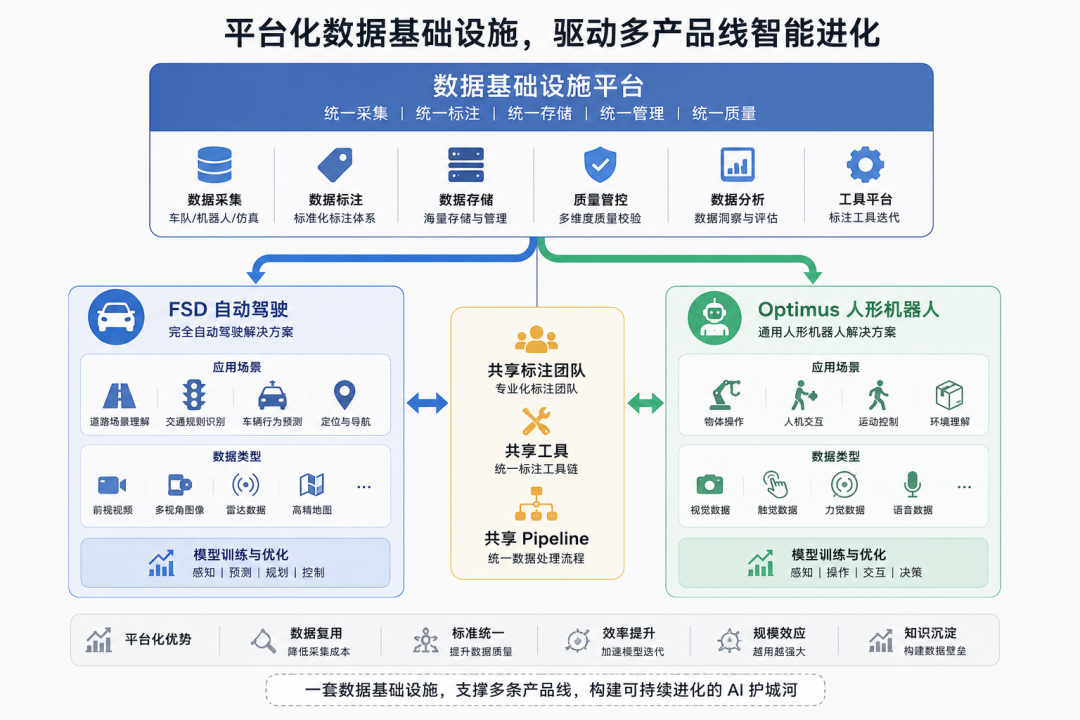
而且,Optimus和FSD共享底层数据基础设施,同一个标注团队,同一套工具,同一个pipeline
这个设计让我想了很久
从产品架构的角度看,特斯拉在做的事情,是把数据能力做成一个内部平台,横向服务多条产品线。FSD和Optimus,一个是自动驾驶,一个是人形机器人,业务形态完全不同,但底层的数据基础设施是共用的
这才是真正的平台化产品思维:不是做一个产品,是搭一套可以无限复用的数据基础设施
这种思维,国内很多AI公司其实还没做到
我见过太多公司,做第一个AI产品的时候,数据这块随便搭一搭,等到做第二个产品的时候,发现数据基础设施完全不通用,每条产品线都在重复建设,成本高得离谱,效率也上不去
特斯拉提前把这个问题想清楚了
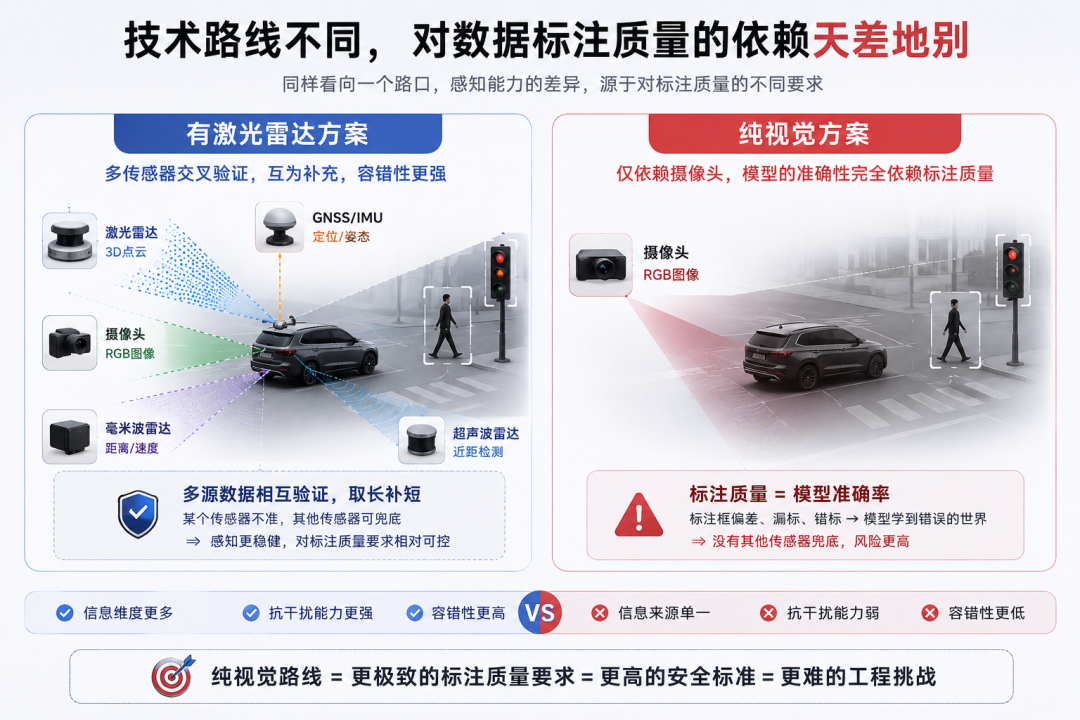
纯视觉路线意味着什么
马斯克一直坚持纯视觉路线,不用激光雷达
这个技术路线选择,直接决定了特斯拉对标注质量的要求比任何竞品都严
用激光雷达的方案,多个传感器之间可以互相交叉验证,某个传感器的数据不准,还有其他的兜底。纯视觉就不一样了,模型的准确性完全依赖标注员画出来的框够不够准
没有激光雷达兜底,就意味着标注员画的每一条线,都直接关系到路上几百万辆车的安全
换句话说,标注员的判断,直接影响到路上那几百万辆车的安全
这个压力不小
所以你就能理解,为什么特斯拉要求标注员必须具备道路交通法律法规方面的知识,为什么要现场办公,为什么要自建团队严格管控标注质量
这不是在卷,这是没有退路
数据标注行业正在悄悄分裂
说说行业现状,因为这个对AI产品经理来说其实挺重要的
全球数据标注服务市场规模预计到2031年会增至328亿美元,中国市场2027年预计超过150亿元,这个盘子不小
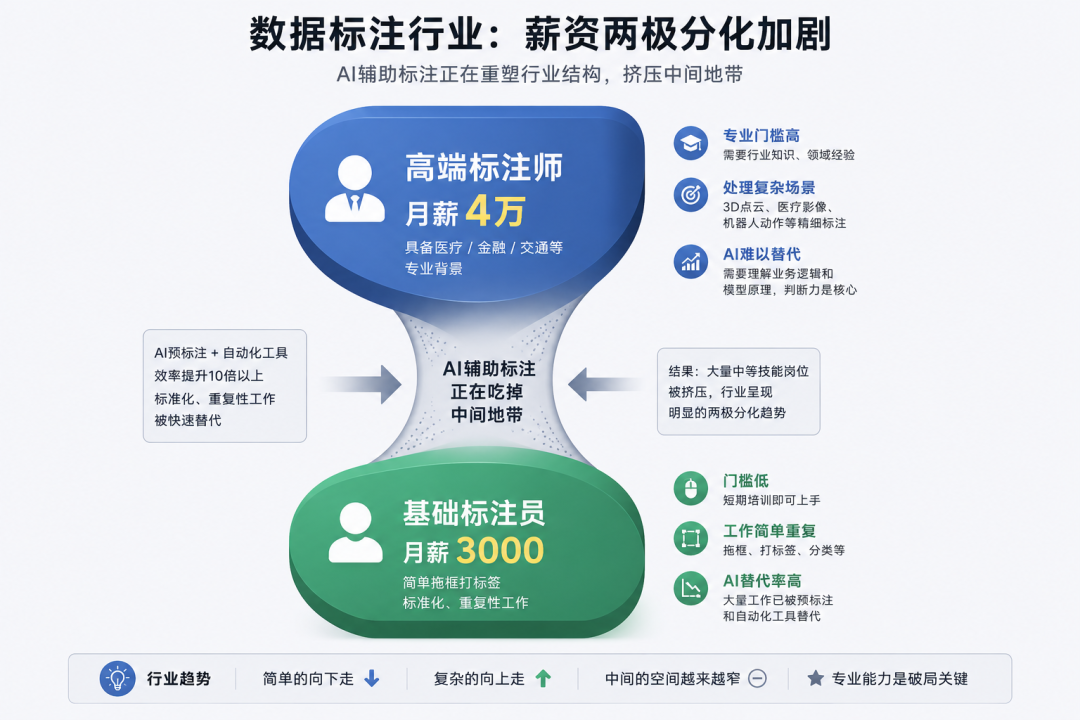
但行业内部正在发生一件很有意思的事:薪资两极分化越来越严重
同样叫”数据标注员”,一个月薪3000,一个月薪4万,这个行业正在撕裂成两个完全不同的世界
基础标注员,就是那种拖框打标签的,月薪还停留在3000元左右。但具备医疗、金融等专业背景的高级标注师,月薪可以到4万
这个差距,比很多人想象的大
为什么会这样?因为AI辅助标注已经成为标配了。用模型做预标注,人工只负责审核和修正边缘案例,效率能提升10倍以上。简单的框框,AI自己就能搞定,不需要人了
但复杂场景的精细标注,AI搞不定
自动驾驶的3D点云标注,机器人动作标注,医疗影像标注,这些不是”拖框”能概括的,需要标注员真正理解业务逻辑,甚至要理解模型训练的原理,这种判断力是AI替代不了的
所以行业在分裂:简单的往下走,复杂的往上走,中间的空间越来越窄
特斯拉裁员再招聘,这个轮回说明了什么
有个细节我觉得很值得说
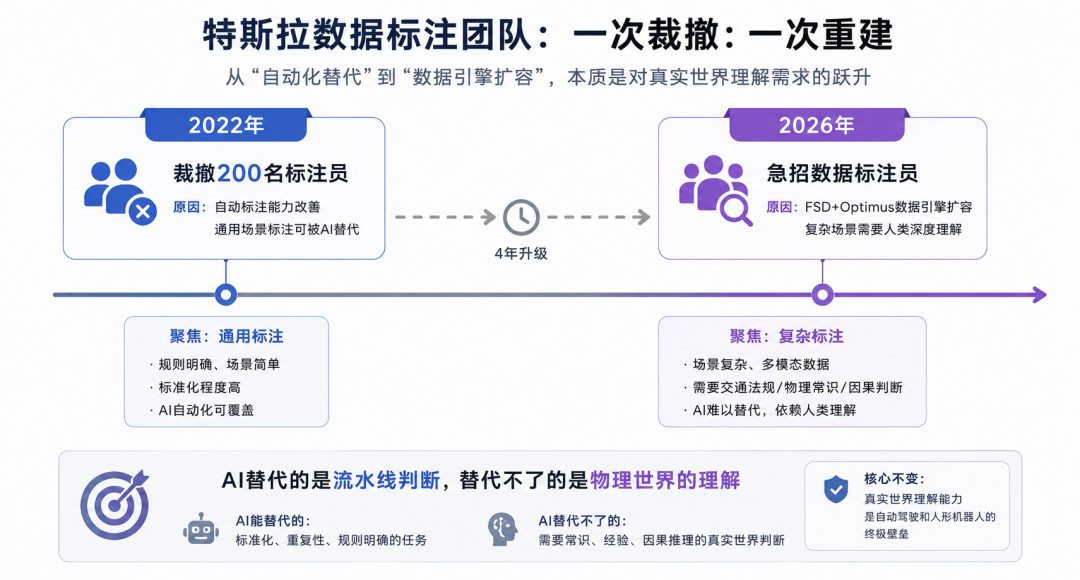
2022年,特斯拉裁撤了200名数据标注员,理由是自动标注能力已经大幅改善,不需要这么多人了
然后,四年后,又急招
这个轮回本身就是一个教训:别轻易相信”AI已经解决了数据问题”这句话
这个轮回,很多人看到的是”AI没有完全替代人”,但我觉得背后的逻辑更复杂
2022年那次裁员,裁掉的是做通用标注的人,那部分工作确实被自动化了。但现在招的,是同时服务FSD和Optimus两条产品线的标注员,要求懂交通规则,要参与改进标注工具,要处理Optimus这种多模态数据
这根本不是同一种工作
AI替代的,是流水线上的那部分判断,标准化的、重复性的、规则明确的。它替代不了的,是那些需要真正理解物理世界的判断
一辆车在复杂路口的行为是否合法?一个机器人抓取物体时的姿态是否正确?这些判断,需要人类对现实世界的理解作为基础,而这种理解,是没法被简单编码进模型的
具身智能时代,真正稀缺的不是算力,不是模型,是能把物理世界”翻译”给机器的人
作为AI产品经理,我从这件事里想到了什么
说点实在的,跟做AI产品直接相关的
数据治理要从第一天就想清楚
我见过太多AI产品,在早期规划的时候,数据这块是留给算法团队”随便解决”的。功能设计、交互设计、用户体验,都想得很细,但数据怎么采集、怎么标注、怎么形成闭环,没人认真想过
等到产品上线,模型效果上不去,才开始补救,成本高,效果还差
数据标注体系没设计好,就像盖楼忘了打地基,等楼盖到一半才发现,拆了重来的代价是灾难性的
特斯拉这次招聘告诉我们,数据标注体系的设计,应该和功能设计放在同等优先级。甚至更早,因为它是地基
区分”可以AI辅助”和”必须人工判断”的边界
这是做AI产品数据规划时很容易忽略的一件事
不是所有的标注都需要人,但也不是所有的标注都能交给AI。产品经理需要在早期就把这个边界想清楚,哪些场景的数据可以用模型预标注,哪些必须保留人工判断,对应的资源分配完全不同
这个判断做错了,要么浪费人力,要么数据质量出问题,都是代价
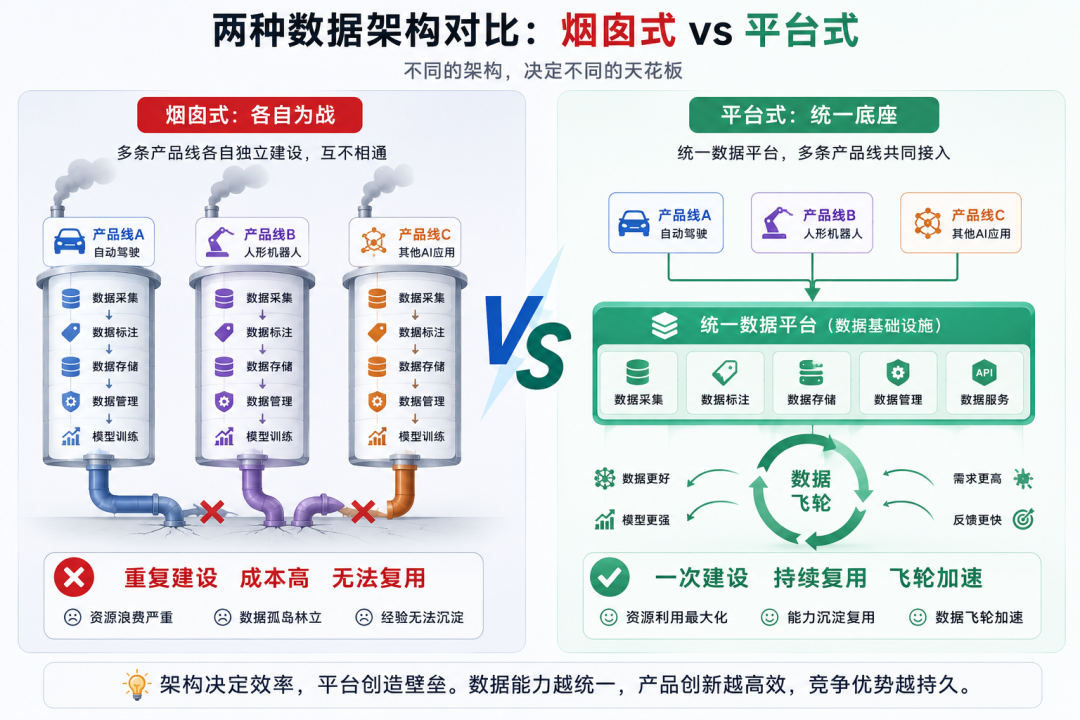
把数据能力做成平台,而不是烟囱
这个想法是我看到FSD和Optimus共享数据基础设施之后想到的
很多公司做第一个AI产品的时候,数据管道是为这一个产品专门搭的。等到做第二个产品,发现没法复用,又重新搭一套。每条产品线都是一个独立的烟囱,既浪费资源,又积累不了跨产品线的数据资产
如果从一开始就把数据能力做成内部平台,标注工具、数据管道、质量管控体系统一管理,后续每条新产品线都能复用,数据飞轮转得越快,产品壁垒就越厚
一句话:数据飞轮转起来的那一刻,护城河就开始加深,而且这条护城河,是竞争对手最难复制的那种
谁控制了真实世界的数据,谁就控制了产品上限
最后想说一件事
有句话说得很好:谁控制了真实世界的数据,谁就控制了下一代AI的上限
这句话放在具身智能时代,比以前任何时候都更准确
大模型时代,数据来源很广,互联网上的文本、图片,可以大规模抓取。但具身智能需要的数据,是真实物理世界里的交互数据,机器人怎么抓东西,自动驾驶车辆怎么处理复杂路口,这些数据没法从互联网上爬,只能靠真实的设备在真实的场景里采集
这种数据,供不应求
互联网数据,人人都能爬。真实物理世界的数据,只有真正跑在路上的车、真正动起来的机器人,才能产生
特斯拉有几百万辆车在路上跑,每天回传海量的真实道路数据,这是任何竞争对手都没法复制的数据壁垒。Optimus部署了专门的数据采集设备,开始大规模回传机器人交互数据,这个壁垒还在加厚
所以特斯拉花高薪招标注员,本质上不是在招人,是在购买一种”不可外包的产品壁垒”
数据飞轮转起来的那一刻,护城河就开始加深了
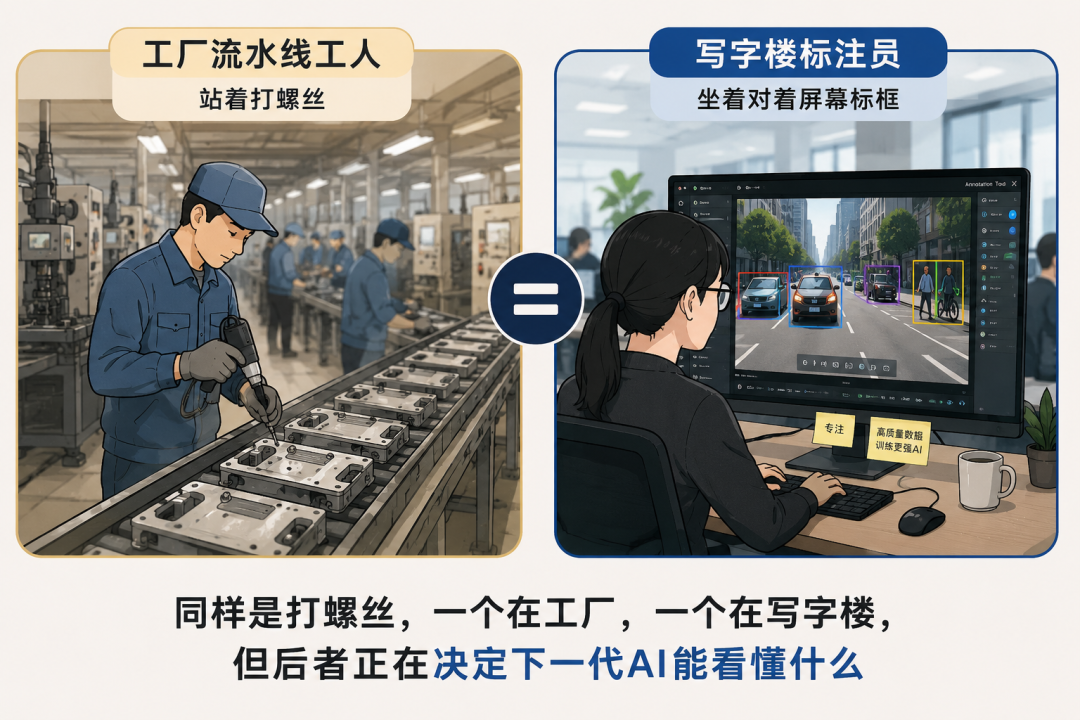
当然,数据标注这份工作本身,确实有点枯燥。有从业者说,跟在工厂打螺丝差不多,每天上班就是标框,完成了下班,唯一的区别是一个坐在写字楼,一个站在工厂
但在国内,这份写字楼里打螺丝的活,月薪最高三四万
你愿意做吗
本文由人人都是产品经理作者【哲子在*** pm】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


