
 起点课堂会员权益
起点课堂会员权益模型微调从 0 到 1:4 种精度、2 条路线、3 道前置题,再附火山引擎全流程
微调大模型究竟是技术升级还是资源浪费?本文深度拆解模型微调的底层逻辑与实战边界,从Prompt工程、Agent架构到RAG方案层层递进,结合火山引擎实操案例,帮你避开90%企业正在经历的AI试错陷阱。

去年我面过一个做了三年 AI 产品的候选人,他和团队花了大半年微调一个客服模型,最后项目下线。我问他原因,他说:”老板后来发现,把客服话术写进 Prompt,再挂一个内部知识库做 RAG,效果比微调那版还好——成本不到原来的十分之一。”
这种事每天都在发生。
国内大厂喊”私有模型”喊了两年,但绝大多数公司其实根本不需要——你以为自己卡在工艺上,其实你是卡在审题上。微调一个 7B 模型,光算力账就能烧掉几万;70B 起步价就是几十万。钱花出去了,可大模型本身的能力你其实只用了 30%。
这篇文章我把”数据标注 + 模型微调”从概念到实操过一遍,重点回答三个问题:
- 微调到底在调什么?(Part 1 概念篇)
- 你真的需要微调吗?(Part 2 决策篇)
- 真要做,怎么动手?(Part 3 实操篇,以火山引擎为例)
读完你应该能判断:面前这个需求,到底该用 Prompt、Agent、RAG,还是微调;如果选了微调,下一步该点哪个按钮。
先搞懂:模型微调到底在做什么?
1. 模型微调,本质是给”通才”补一门专业课
GPT、Claude、Doubao、DeepSeek 这些大模型,你可以想象成一个读过全世界 90% 文献的研究生。它什么都懂一点,但让它写一篇地道的小红书爆款文案,它给你的东西自带“教科书的味道”——不出错,但没人爱看。
模型微调,就是把这个通才再送回学校读个研究生。你给它 1000 篇真实的小红书爆款文案,让它反复看、反复学,最后它生成的内容就带”小红书味”了——开头有钩子、中间分点、结尾会撒娇互动。
技术上严格的定义是:在已经训练好的预训练模型基础上,用一个小规模、有针对性的数据集,继续训练它的部分或全部参数,让它在特定任务上的表现变好。
翻译成人话:通用模型 → 加上私房菜谱 → 你专属的厨子。
2. 数据标注,是给模型当”教辅老师”
模型微调离不开数据,但喂给模型的数据不能是原始素材,得是标注过的。
什么叫标注?最简单的形式就是”问题 + 答案”对。比如你想训练一个小红书文案模型:
- 问题:写一段 25 岁通勤族的口红推荐
- 答案:(一段真实的爆款文案)
但 2024 年之后,业界标注的格式已经升级了。以前是结果导向,现在是过程导向——这就是所谓的 CoT 数据(Chain of Thought,思维链)。
老格式:问题 + 答案
新格式:问题 → 第一步思考 → 第二步思考 → 遇到子问题怎么处理 → 最终答案
差别在哪?老格式只教模型”对答案”,新格式教模型”对答案的推理路径”。一旦它学会了推理路径,遇到训练集里没出现过的新问题,它也能照着这个套路自己推一遍。
这就是为什么这两年所有顶级模型都在拼”推理能力”——本质上拼的是”高质量 CoT 数据”。数据标注是个力气活,但它真正决定了模型的天花板。 这部分我下一篇会专门写,今天先按下不表。
3. 微调能干的五件事(也只有这五件事)
很多人把微调想得太神秘,其实拆开来看就五类用途:
- 调风格:让输出符合特定调性(小红书、知乎、客服话术、法律文书)
- 灌知识:把企业内部的产品知识、行业术语、专有名词训进去
- 磨工具:让模型更准地判断”什么时候该调哪个工具”(Agent 场景的关键)
- 强推理:用 CoT 数据让它在数学、代码、逻辑题上更扎实
- 压成本:把一个大模型”蒸馏”成小模型,部署起来更便宜
注意:这五件事并不是只有微调能做。 比如调风格,Prompt 写得好其实就够用;灌知识,RAG 经常更划算。这是后面 Part 2 要讨论的”决策框架”。
4. 全量微调 vs 高效微调:99% 的人只需要后者
模型微调按”调多少参数”分两类。
全量微调(Full Fine-tuning)
整个模型的所有参数都跟着新数据重新调整。优点是上限高、效果好;缺点很直接——
- 算力贵:训练一个 7B 模型全量微调,至少要 4 张 A100(80GB)跑几天。按现在算力市场价,单次实验起步几万元。
- 显存吃紧:参数 + 梯度 + 优化器状态三件套加起来,一个 7B 模型全量微调要约 80GB 显存,单卡放不下。
- 容易学坏:训练过头,模型会把原本的通用能力也覆盖掉,这有个专业名词叫**”灾难性遗忘”**——它学会了你的事,但忘了世界。
千问、豆包、Llama 这些基础模型本身就是大厂全量训练出来的。全量微调一般只有 BAT、字节这种级别的公司会做。对绝大多数公司来说,全量微调不是“选不选”的问题,是“碰不碰得起”的问题。
高效微调(PEFT,Parameter-Efficient Fine-Tuning)
只调一小部分参数,通常是全模型参数的 0.1% ~ 1%,其他参数全部冻结。优点很直接:
- 显存小:一张消费级显卡(24GB)就能跑 7B 模型
- 速度快:单次训练几个小时
- 风险低:训练失败大不了重来,丢失通用能力的概率小很多
绝大多数公司、绝大多数场景,都是高效微调。这是行业默认选项。
5. LoRA 与 QLoRA:高效微调里的当红炸子鸡
高效微调本身还有很多流派(Prefix Tuning、Adapter Tuning、Prompt Tuning…),但今天真正能打的就两个:LoRA 和 QLoRA。
LoRA(Low-Rank Adaptation,低秩适应)
核心思想:不去改原模型的参数,而是在原模型旁边并联一个”小补丁矩阵”。这个补丁矩阵很小——通常只占原模型 0.1% ~ 1% 大小——但训出来的效果接近全量微调。
打个比方:你不想重装电脑系统,那就装个外挂插件。插件只改变你想要的那部分行为,其他保持原样。这就是 LoRA。
QLoRA(Quantized LoRA,量化版 LoRA)
LoRA 还有个升级版叫 QLoRA。它做了一件关键的事:先把原模型压缩成 4-bit 精度(NF4 数据类型),再在压缩后的模型上挂 LoRA 插件训练。
QLoRA 论文里的关键结论是:用 QLoRA 微调出来的模型,效果能恢复到 16-bit 全精度微调的水平,但显存占用大幅下降。
具体多省?QLoRA 论文给的标志性数据:一个 65B 参数的模型,原本全量微调需要 780GB 显存,QLoRA 把它压到了 48GB——一张 A6000 就能搞定。
实操结论:新手起步用 QLoRA 就对了。LoRA 是 QLoRA 的”老前辈”,QLoRA 是现在的默认选项。火山引擎这种平台帮你包装好了,你点几下就行。
6. 四种精度:FP32 / FP16 / INT8 / INT4 怎么选
这部分容易把人绕晕,但概念其实很简单。模型里每一个参数都是一个数字,存这些数字要占空间。精度越高,数字越准,越占地方;精度越低,数字越粗糙,越省地方。
四种主流精度:
- FP32(32 位浮点数):全精度。一个参数占 4 字节。最准,最占地方。
- FP16(16 位浮点数):半精度。一个参数占 2 字节。比 FP32 少一半空间,实测精度损失通常小于 1%。
- INT8(8 位整数):用整数代替小数。空间又少一半。会有可察觉的损失,但很多场景能接受。
- INT4(4 位整数):极致压缩。一个参数只占半字节。损失更明显,但配合 QLoRA 这种技术,损失可控。
实操选型口诀:
- 训练:FP16 / BF16 起步(这是今天工业界默认精度)
- 推理部署:INT8 是性价比最高的折中
- 极端场景(手机、车机、嵌入式):INT4
7. 模型大小怎么选?7B ~ 16B 是甜蜜区间
很多教程会丢一句”16B 最合适”——这话不完全对,得加语境。
对于大多数 B 端垂类场景,7B ~ 16B 是最常见的甜蜜区间。原因:
- 太小(< 3B):能力上限低,复杂任务跑不出来
- 太大(> 70B):部署贵、推理慢,业务方接受不了
- 7B ~ 16B:能力够用,单卡 A100 能跑,响应速度可控
但如果你做的是端侧应用(App 内置 AI、车机助手),那 3B 甚至 1.5B 才合适;做专业代码生成或复杂推理,可能 32B 起步才够。
一个判断口诀:先想清楚部署在什么硬件上,再倒推模型该多大。 这比看任何论文都靠谱。
想清楚:你真的需要微调吗?
这是这篇文章的核心。我的观点很明确:绝大多数想做微调的人,其实根本不需要做微调。
为什么?因为大模型已经强到可以靠”外挂”解决 80% 的需求。下面这三道前置题,按顺序问自己一遍——前一题能解决,就别动后一题。
8. 第一道题:Prompt 工程能不能解决?
Prompt 就是你给模型的”指令”。听起来不起眼,但精心设计的 Prompt 能解决的问题远超你想象。
举个例子。客户希望模型输出固定格式的 JSON。你以为要微调?其实只需要在 Prompt 里写:
你是一个数据解析助手。请将用户输入解析为以下 JSON 格式:
{“name”: “…”, “age”: “…”, “city”: “…”}
只输出 JSON,不要输出其他任何内容。
示例:
输入:”张三 25 岁住北京”
输出:{“name”: “张三”, “age”: “25”, “city”: “北京”}
把这段写进 system prompt,再配 2~3 个 Few-shot 示例,准确率轻松上 95%。零成本、零部署,迭代起来就是改一行字。
Prompt 工程的能力边界:
- ✅ 风格调整、格式规范、固定话术
- ✅ 简单的分类、抽取、改写
- ✅ 多步骤推理(用 CoT prompt 引导)
- ❌ 需要模型不掌握的私有知识
- ❌ 高频调用且要降低 token 成本的场景
如果你的需求落在 ✅ 那一档,老老实实把 Prompt 写好,别折腾微调。
9. 第二道题:Agent 能不能解决?
Prompt 搞不定的,下一步试 Agent。
Agent 就是”会调用工具的模型”。比如你让模型回答”今天上海天气怎么样”,纯靠 Prompt 它只能瞎猜——但只要它能调用天气 API,问题立刻解决。
Agent 适合解决这几类问题:
- 需要实时数据(股价、天气、库存、订单状态)
- 需要精确计算(财务模型、报表汇总)
- 需要调用其他系统(CRM、ERP、内部数据库、邮件、日历)
举个常见场景:你想做一个”销售助手”,能回答”上个月客户 A 的订单情况”。这事 Prompt 解决不了(模型不知道你公司的订单数据),但 Agent 加一个查数据库的工具就能做。
Agent 不能解决的问题:当模型本身能力是瓶颈时——比如它就是不懂你这行的专业术语——给它工具也没用,它根本不知道该调哪个。
10. 第三道题:RAG 能不能解决?
前两个都不行,再上 RAG(Retrieval-Augmented Generation,检索增强生成)。
RAG 的思路:把你的私有知识做成一个外挂”图书馆”(向量数据库),每次提问时,先从图书馆里检索出最相关的内容,再把内容拼到 Prompt 里让模型回答。
打个比方:模型本来是个不带书的学生,RAG 让它考试时可以翻书。
RAG 最适合的场景:
- 企业内部知识库问答
- 产品文档客服
- 法律、医疗、专业文献检索
- 任何“内容更新频繁”的场景
为什么 RAG 经常比微调香?
- 更新成本低:知识更新了,只要把新文档塞进向量库就行;微调要重新训练
- 可解释:模型回答时可以”引用”原文出处,监管和合规上好交代
- 不容易瞎编:模型只在检索到的内容里作答,幻觉率显著降低
我见过最离谱的反例:一家公司花三个月微调一个”产品知识问答模型”,结果产品手册一更新,模型就过时了,又得重新训。做 RAG 三天能搞定,并且永远不会“过期”。
11. 实在不行,再考虑微调
什么时候才轮到微调出场? 满足下面一条以上,再认真考虑:
- 前三种都试过,效果就是不达标
- 业务对延迟极度敏感(微调过的小模型比”大模型 + RAG”快得多)
- 业务对调用量极大(微调小模型的 token 成本能省一个数量级)
- 涉及强风格化输出,Prompt 怎么写都不像(比如必须模仿某位作家的笔调)
- 需要在端侧部署(手机、车机),大模型放不下
记住一句话:不要为了微调而微调。 微调是手段,不是 KPI。第一性原理是回到问题本身:用户到底要什么、最便宜的解法是什么。
动手做:火山引擎微调全流程
讲完概念和决策,最后实操。我以”小红书爆款文案生成模型”为例,从 0 到 1 走一遍火山引擎(火山方舟)的完整流程。
为什么选火山引擎?几个原因:
- 平台化操作,不用自己搭训练框架
- 基座模型可选 Doubao 系列,国内可商用
- 计费透明,小数据集训练几十块就能跑完
- 训完直接通过 API 调用,省去部署环节
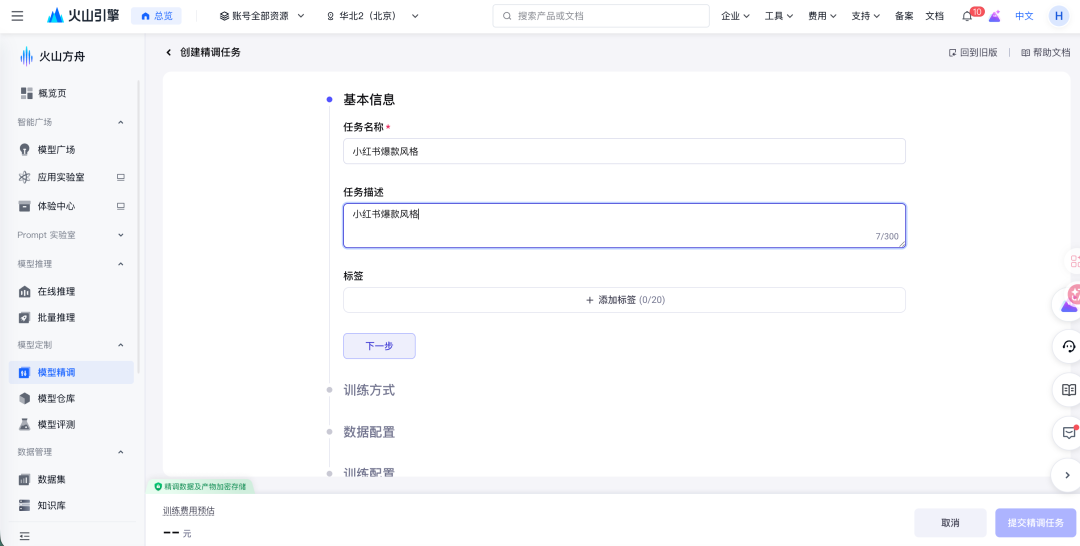
前置准备:你需要一份至少 200 ~ 500 条的标注数据集(1000 ~ 5000 条最佳),格式通常是 JSONL,每行一条”问题 – 答案”对。数据怎么标注,下一篇细讲。
12. Step 1:明确目标 + 选基座
登录火山方舟控制台,进入”模型精调”模块,新建任务。
第一件事是写清楚目标。别只写”训一个小红书模型”,要具体到——
训练一个能生成”25-35 岁女性、家居好物、轻松吐槽风”的小红书爆款文案模型。要求开头有钩子、中间分点、结尾有互动话术。
目标越具体,后面选模型、配参数、做评测都更顺。
第二件事是选训练类型和基座。
训练类型选 SFT(Supervised Fine-Tuning,监督微调)——这是最常用、最稳的微调方式,本质就是”看着标准答案学”。
基座模型推荐 Doubao-Seed-1.6-flash。原因:
- 它是个轻量级模型,推理速度极快,时延约 10ms 级
- 价格便宜,训练和推理都省钱
- 适合“风格类、轻量任务”,正好对上我们的需求
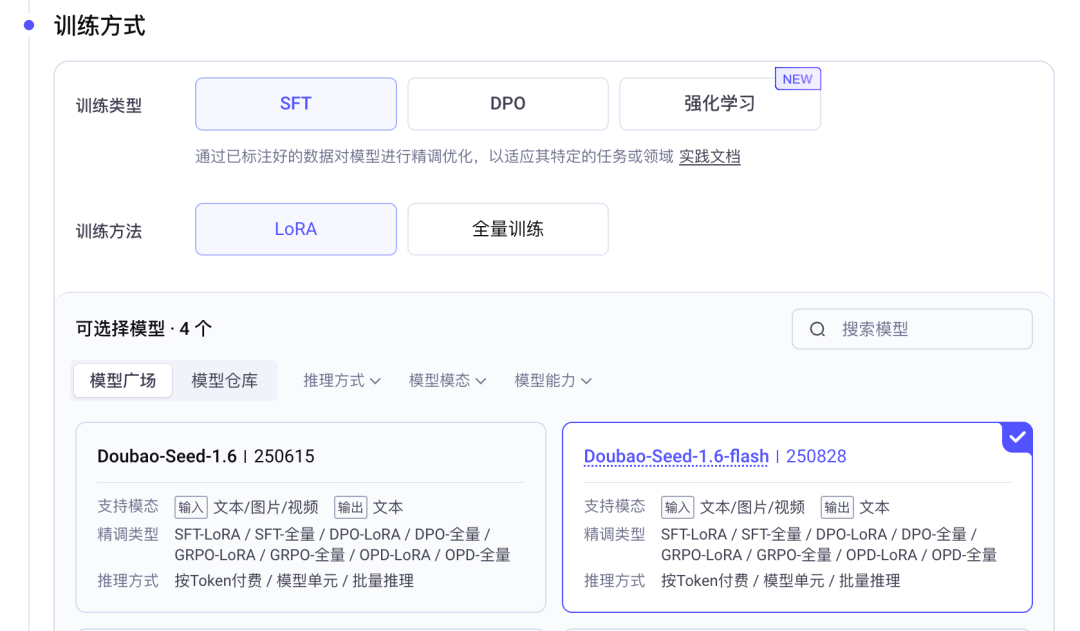
如果你的任务更复杂(比如长文档理解),可以选 Doubao-Seed-1.6 或 Doubao-Seed-1.6-thinking,但价格会上去。
13. Step 2:上传数据集
把准备好的 JSONL 数据集上传到平台。两个参数要注意:
采样倍率:调整不同数据集之间的比例。如果你只有一份数据,填 1 就行。如果你同时有”小红书爆款”+”知乎好文”两份,想让小红书占主导,就把小红书设成 3、知乎设成 1。
验证集分割:训练集和验证集要分开。验证集的作用是判断模型”学过头了没”。最常见的做法是按比例分割——比如 80% 数据用来训练、20% 留作验证。火山引擎支持自动分割,选”按比例分割 0.8 / 0.2″即可。
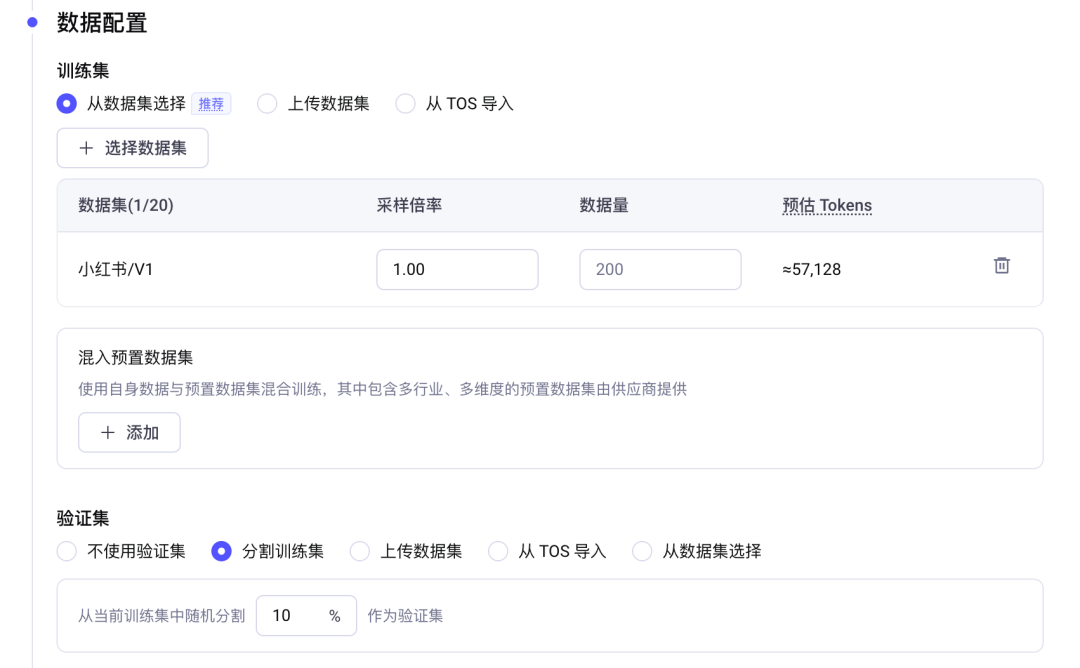
为什么必须有验证集?因为模型很容易过拟合——把训练集背得滚瓜烂熟,但一遇到新问题就抓瞎。验证集就是用来抽考它的,看它是真学会了还是只会背书。
14. Step 3:调参(最容易翻车的一步)
参数页能看到一堆配置项,但绝大多数不用动。真正要重点调的就两个:epoch 和 learning rate。

Epoch(迭代轮次):模型把整个数据集”读几遍”。
- 太少(< 2):学不透,效果差
- 太多(> 10):学过头,过拟合
- 推荐范围:3 ~ 5 轮
具体几轮合适?看数据集大小。数据量大(5000+)就 3 轮;数据量小(500 以下)可以试到 5 轮。
Learning Rate(学习率):每一步学习的”幅度”。
这是新手最容易翻车的参数。学习率太大,模型一上来就跑偏(梯度爆炸);学习率太小,模型半天没进展。
- LoRA / QLoRA 微调的常用范围:0.00002 ~ 0.0001(即 2e-5 ~ 1e-4)
- 火山引擎默认值通常是 0.00002,新手直接用默认值就行
- 进阶玩家可以从 0.00002 起步,效果不够再往上调一档
两个常见坑:
- 过拟合:训练 loss 一直降,但验证 loss 反而上升 → 减少 epoch,或降低学习率
- 梯度爆炸:训练 loss 突然飙到极大值或 NaN → 立刻把学习率砍一半重训
其他参数(batch size、warmup steps、weight decay)保持默认基本够用。新手记住一条原则:控制变量,一次只调一个参数。 一次改三个,出问题你都不知道是哪个的锅。
15. Step 4:产物保留 + 开始训练
参数调完,最后一个设置是产物保留上限——训练中会自动保存多个 checkpoint,你想留几个。
设 2 ~ 3 个就够了。设太多浪费存储费;设太少万一最后一个效果不好就没救了。
确认无误后点”开始训练”。
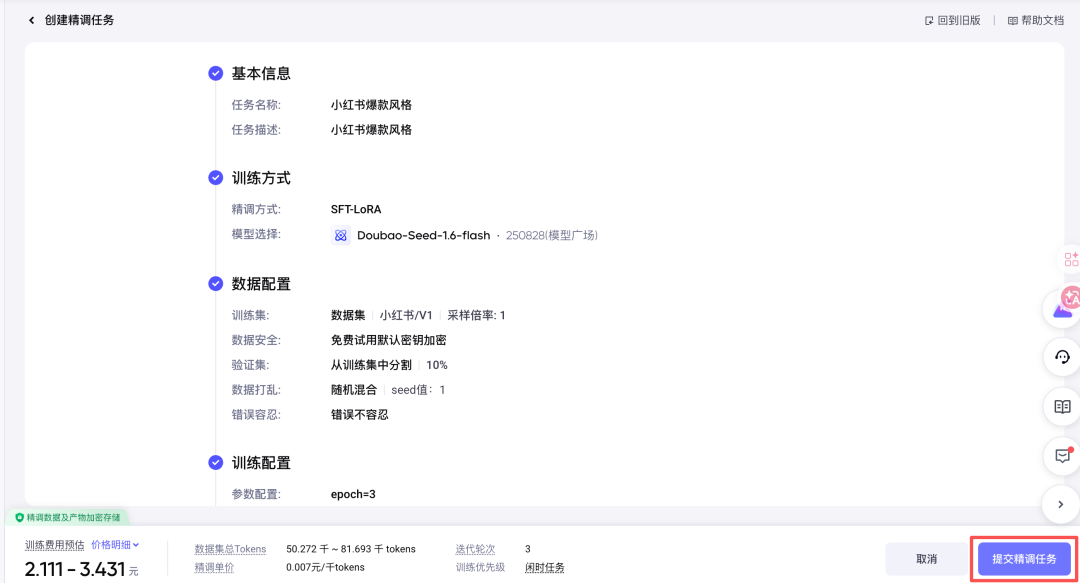
费用怎么估? 主要看三件事:
- 数据集大小(token 数)
- 训练轮次
- 基座模型规格
参考一个典型数字:500 条数据 + 3 轮 epoch + Doubao-Seed-1.6-flash 基座,总费用通常在百元以内。如果换成 5000 条数据 + 5 轮 + 更大基座,费用可能就是几百到几千。
温馨提示:开训前一定要看清楚平台的预估费用,避免你点完按钮一觉醒来欠平台一辆车的钱。
16. Step 5:模型评测 + 拿到调用三件套
训练完成后,模型不能直接上业务,要先评测。
评测的本质是拿测试集(最早留出来的 20%)跑一遍,看模型输出和标准答案差距多大。火山引擎平台内置自动评测指标,但更靠谱的方式是人工抽检。
抽检建议设三档:
- 完全合格:风格、内容、格式全到位
- 基本合格:风格对了,但内容有偏差
- 不合格:跑偏、瞎编、格式崩坏
判断标准:
- 1 类比例 > 70% → 可以上业务
- 50% ~ 70% → 还能再训一轮
- < 50% → 回头看数据集质量,多半是数据问题不是参数问题
评测过了,要把模型接出去用,需要三样东西:
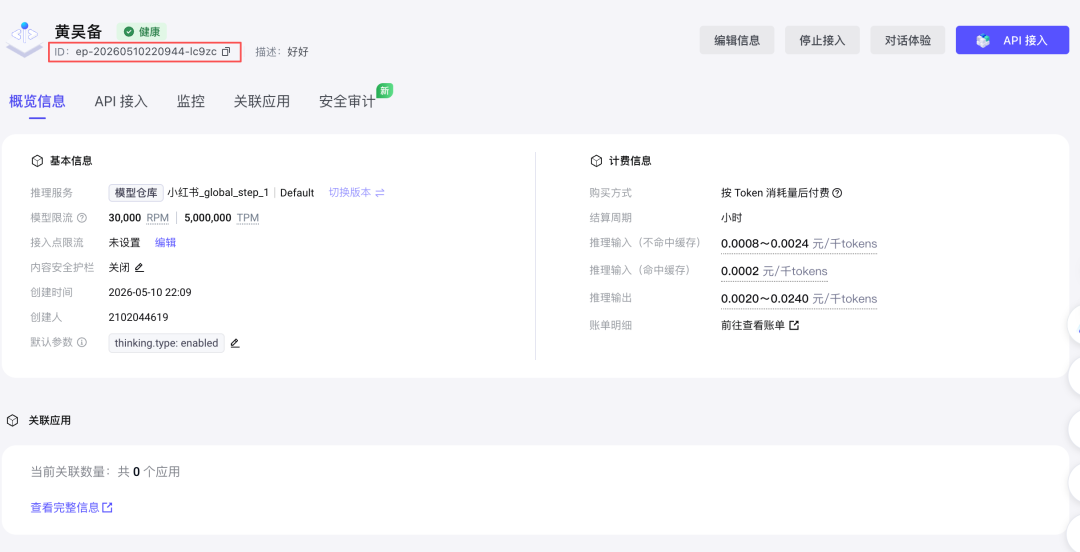
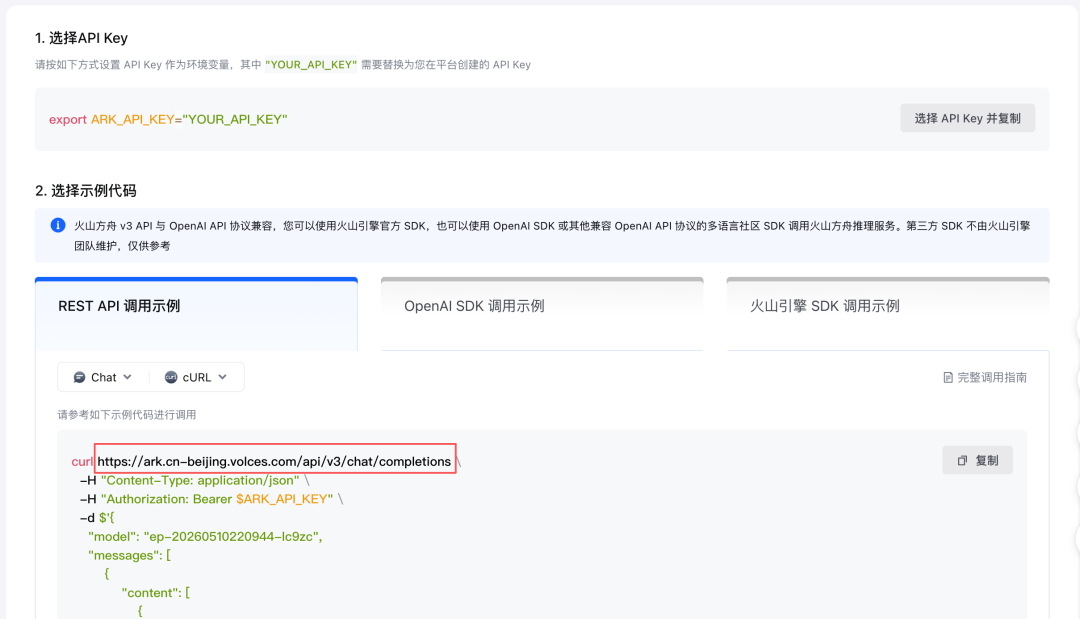
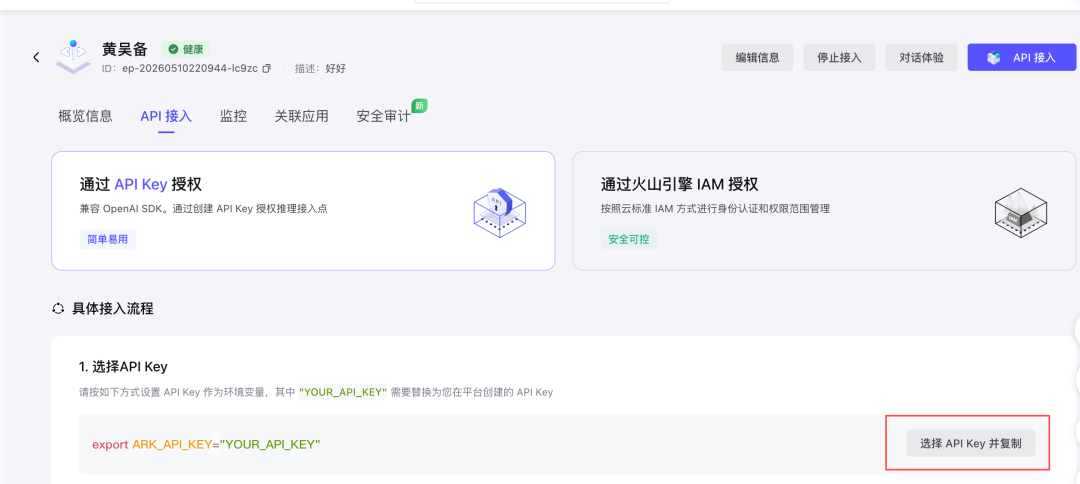
- 模型 ID:在”我的模型”列表里点进去就能看到
- API Key:在”API Key 管理”里新建一个
- Base URL:火山方舟默认地址是 https://ark.cn-beijing.volces.com/api/v3(不同区域可能不同,以平台页面为准)
这三样收齐,就可以接到任何客户端了。
17. Step 6:用 ChatBox 实测,左右对比基座模型
把模型接到 ChatBox(一个常用的桌面 LLM 客户端)做最后验收。
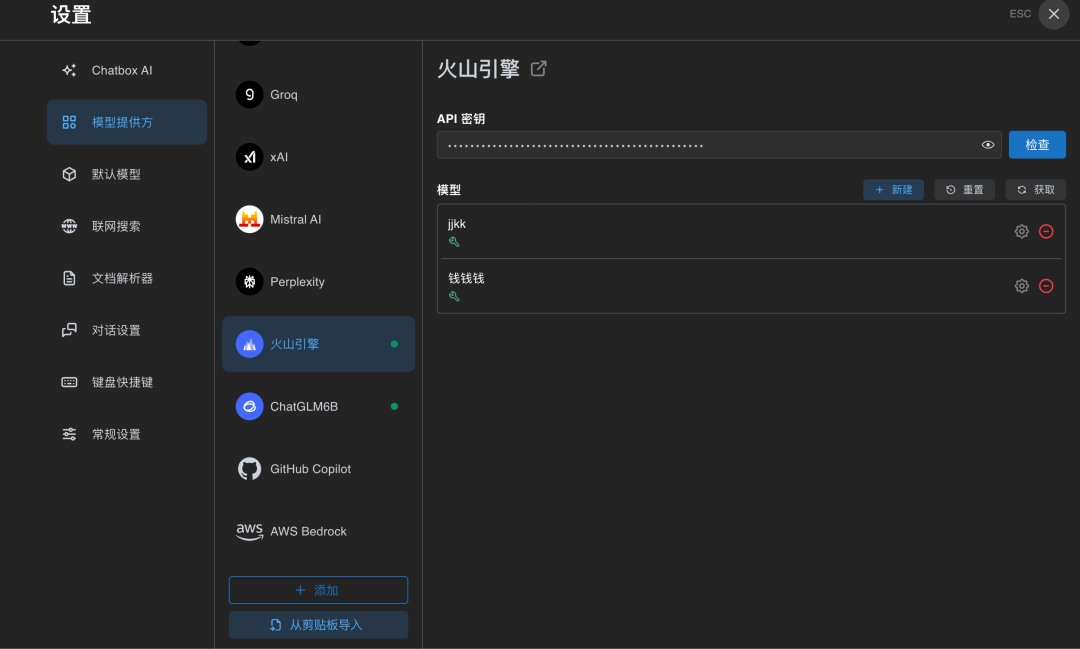
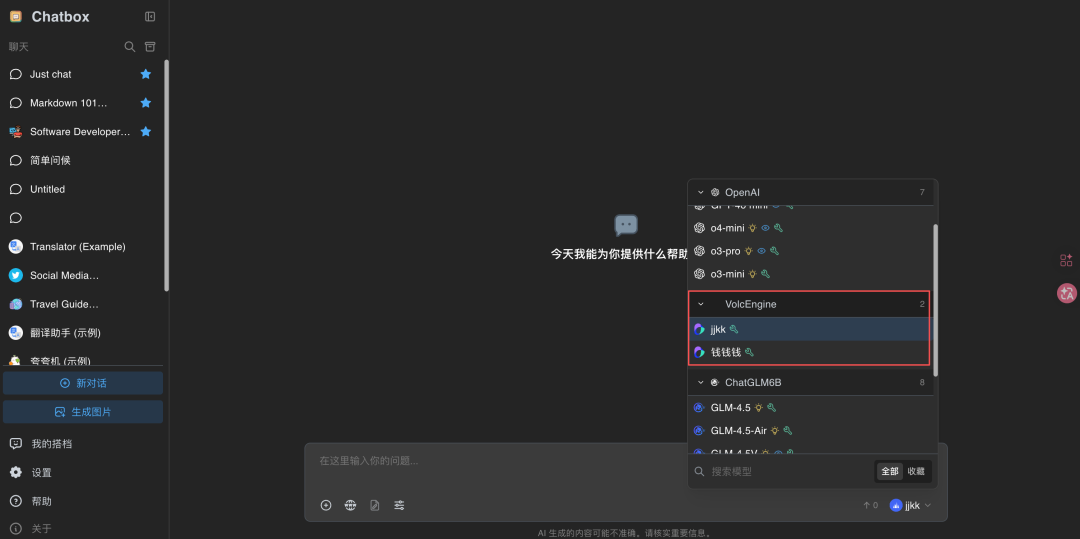
操作步骤:
- 打开 ChatBox,进设置
- 找“模型提供方”→ 选“火山引擎”
- 填入 API Key
- 点“新建模型”,填入刚才拿到的模型 ID
- 测试连接 → 保存
最关键的一步:把基座模型也同时接进来,开两个对话窗口左右对比。
测试方法:从你最初准备的数据集里抽 20% 作为测试集,用同一个问题分别问“微调后模型”和“基座模型”,看哪个的回答更接近你想要的风格。
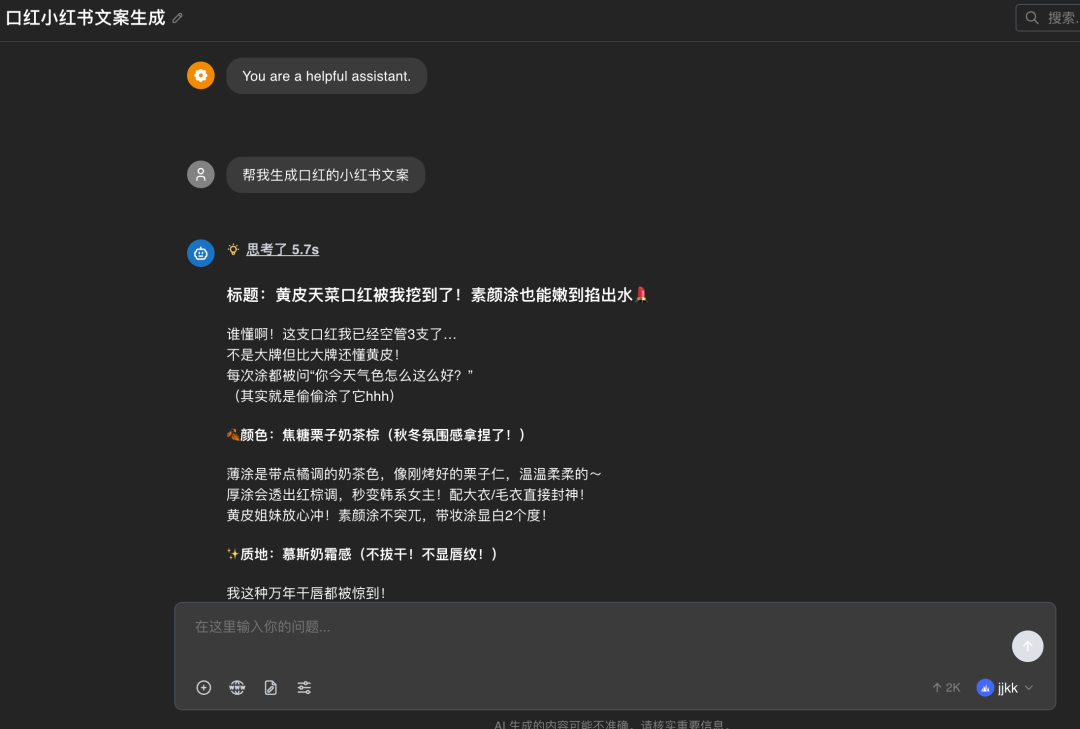
- 如果微调后的明显更好 → 恭喜,模型上线
- 如果差不多,甚至比基座还差 → 回去看是哪一步出了问题(最常见是数据集质量,其次才是参数)
到这里,从 0 到 1 走完了。
最后:一套能直接套用的方法论
这篇写了五千多字,但你只要记住一张决策图就够了:
新需求来了 → 能用 Prompt 解决吗?
├─ 能:写 Prompt + Few-shot,今天就上线
└─ 不能 → 需要实时数据 / 调用工具吗?
├─ 需要:上 Agent
└─ 不需要 → 是私有知识检索吗?
├─ 是:上 RAG
└─ 否 → 高频/低延迟/强风格/端侧?
├─ 满足任一条:考虑微调
└─ 都不是:回去再审一遍需求,你可能只是把问题想复杂了
给三种角色的具体行动清单
如果你是 AI 产品经理:
- 收到业务方”我们要个垂类模型”的需求时,先反问三个问题:调用量多少?延迟要求多少?私有数据多不多? 这三个答不上来,方案设计就是空中楼阁。
- 立项前算一笔账:Prompt + RAG 的成本 vs 微调的成本。给老板看 ROI,比你给他讲技术原理有用一百倍。
- 把“我们要不要做私有模型”这种宏大问题,拆成“这个具体 case 用什么方案最划算”一个一个 case 评估,别一刀切。
如果你是技术负责人:
- 微调起步不要直接上全量,从 QLoRA 开始。一张 24GB 显卡就能试,失败了不肉痛。
- 数据集质量永远比模型架构重要。 与其花一周调参数,不如花一周清洗数据。
- 训练前一定要把 train / val / test 三个数据集划分好,严禁互相污染。这是新手最常翻的车。
如果你是一线执行(开发 / 标注 / 训练工程师):
- 火山引擎、阿里百炼、智谱 BigModel 这几个平台都支持平台化微调,先把界面摸熟,不用上来就啃 PyTorch。
- 第一次实验用小数据集(300 ~ 500 条)、小模型(< 10B)、小轮次(3 epoch)。跑通流程最重要,效果第二。
- 把每次实验的“参数 + 结果 + 反思”记成 Excel 表,三次实验下来你就有手感了。
最后说点实在的——
模型微调在今天已经不是技术问题,而是判断问题。 技术工具被火山、阿里、智谱这些平台铺得到处都是,门槛已经低到平民价。真正贵的,是你判断”什么时候该用、什么时候不该用”的能力。
那个面试候选人花六个月教训告诉我的事是:AI 项目能不能成,70% 决定在需求审题阶段,20% 在方案选型,剩下 10% 才是技术执行。 顺序千万别搞反。
下一篇我会专门讲数据标注——为什么说”标注比微调还难”,以及一份 1000 条数据集到底该怎么搞出来。点个关注,等更新。
本文由 @Barry设集屋 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议









真棒,太有用了