
 起点课堂会员权益
起点课堂会员权益一个AI产品经理在真实项目里踩过的6个坑
一位资深AI产品经理在金融信贷审核项目中踩过的6个坑,恰好揭示了2026年AI产品经理必备的6项核心能力。从Agent编排的接口设计失误,到RAG技术中的知识库治理漏洞;从一行Prompt引发的AI幻觉灾难,到Demo胜过百页PRD的实战启示——这些血泪教训不仅关乎技术实现,更直指AI产品的本质:如何让机器与业务、与人的信任无缝对接。

去年,我接了一个金融AI项目。作为一个做了6年的AI产品经理,我以为自己够资深了。
需求听起来不复杂:把人工信贷审核流程交给AI来做。以前一个审核员要花45分钟翻资料、核数据、交叉验证,最后给一个”通过”或”拒绝”的结论。领导的期望是——AI能不能快一点?
我当时心想,这不就是搭个大模型接口的事吗。
后来我用了大半年,踩了6个大坑,把审核时长从45分钟压到了不到4分钟,误拒率从15%降到了2-4%。
这6个坑,恰好对应了2026年AI产品经理最需要的6项能力。不是我提前规划好的,是被现实打出来的。
今天想把这个项目从头到尾聊一遍。不是成功经验分享——更多是”当时怎么差点搞砸了、后来怎么活过来的”这种复盘。
如果你正在做AI产品、或者想转型AI产品经理,这些坑可能对你有用。因为我敢打赌,你迟早也会踩到。
坑一:设计了7个Agent,结果一个都跑不通
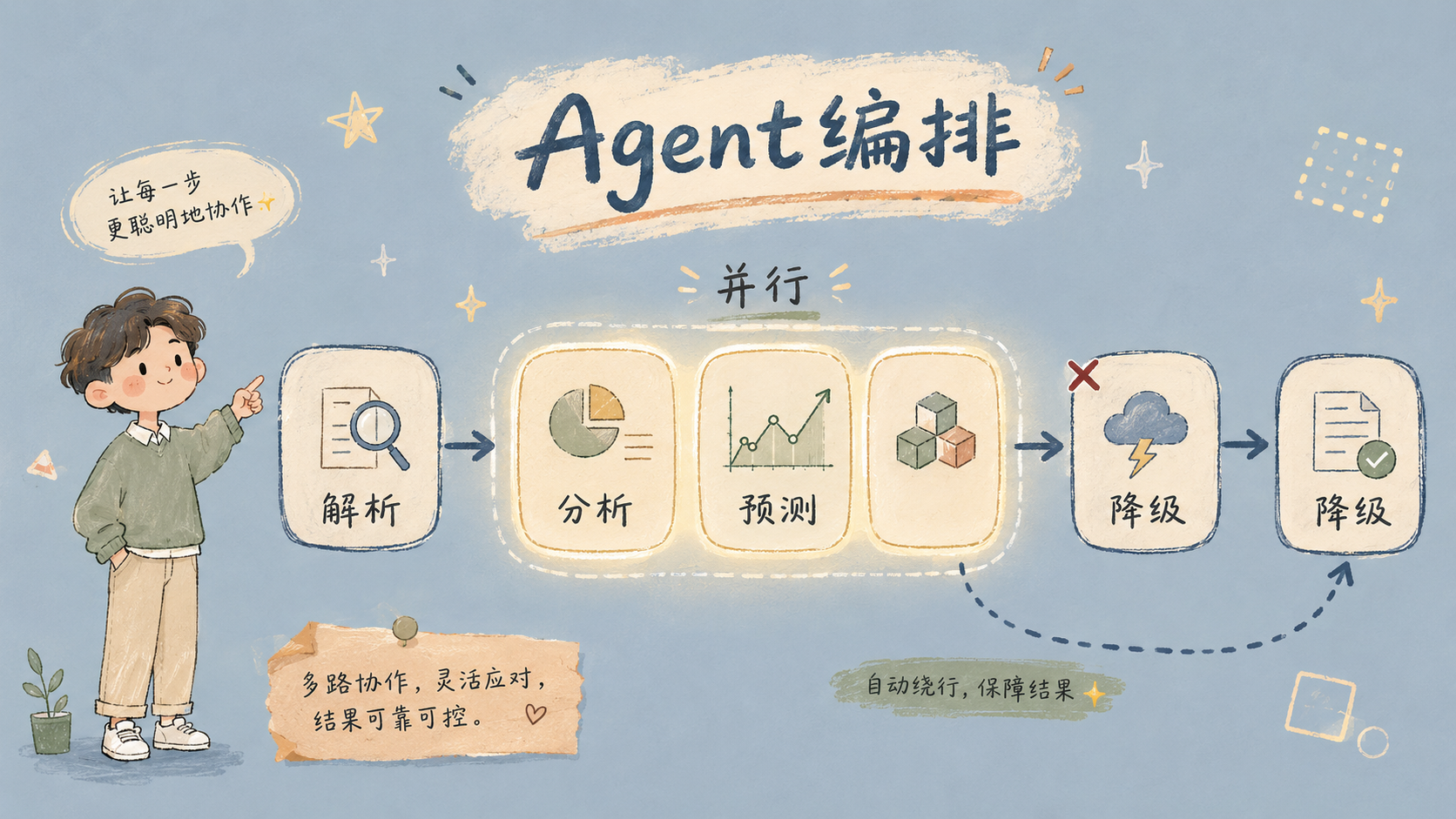
项目一开始,我把审核流程拆成了7个步骤,每个步骤交给一个独立的AI Agent来做。
什么叫Agent?你可以理解为一个”能自己干活的AI助手”——你给它一个任务,它自己去找信息、做判断、出结果。不是只会聊天的那种,是真的能干事的。
7个Agent各自负责一件事:读取申请材料、核验身份信息、检查征信记录、分析收入流水、评估抵押物、交叉验证数据一致性、给出最终审核结论。
我写了一份PRD,画了一张漂亮的流程图,信心满满地提交给算法团队。
算法lead看完,问了我三个问题:
“中间这3个Agent是串行还是并行跑的?”
我愣了。串行就是一个做完才做下一个——像排队买奶茶,前面的不走你就得等。并行就是几个同时开工——像一桌菜同时炒,快很多但厨房可能忙不过来。我的PRD里压根没提这件事。
“征信Agent如果查不到记录,下游的交叉验证Agent怎么办?是报错还是跳过?”
我又愣了。
“身份核验Agent返回的数据格式,和收入分析Agent期望的输入格式对得上吗?”
对不上。因为我根本没想过格式的事。
那天晚上我回去重新梳理。用纸画了一张巨大的编排图——每个Agent是一个方框,方框旁边写着”输入什么格式、输出什么格式、超时了怎么办、返回空了怎么办”。箭头标清楚数据怎么流、在哪里分叉、在哪里汇合。
画了整整两天。
画完我才理解一件事:多Agent系统的核心不是每个Agent多聪明,而是它们之间的”接口”设计得有多严谨。 就像一条流水线,任何一个工位和下一个工位的衔接出了问题,整条线就停了。
这就是Agent构建与编排的能力。 不是让PM写Python,是让你能想清楚——7个Agent之间到底怎么配合、挂了怎么降级、数据怎么传递。这些想不清楚,写出来的PRD就是一堆漂亮但跑不起来的废纸。
坑二:AI查政策文件,把三年前的旧版当成最新的返回
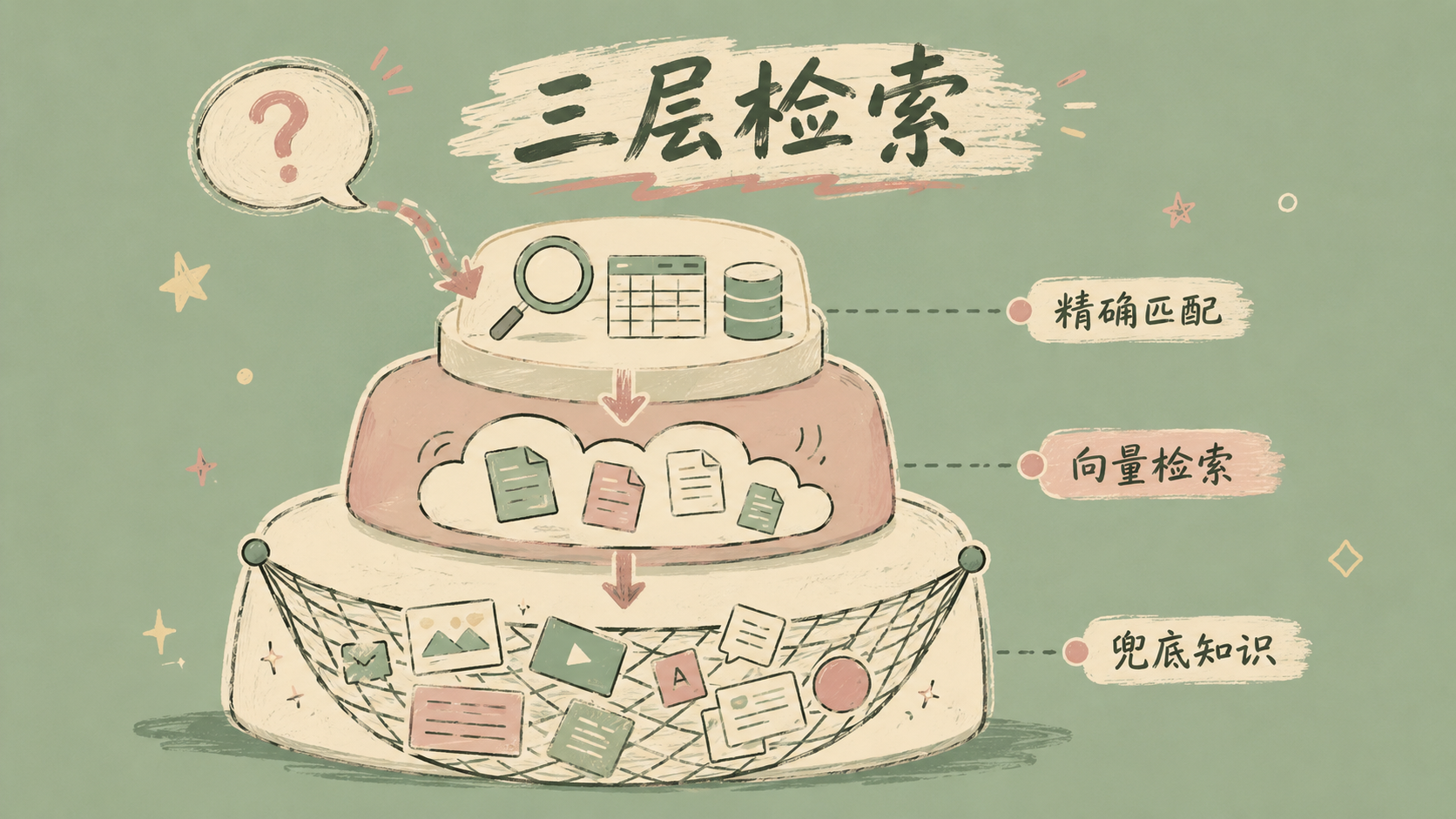
审核系统要查大量政策法规——利率红线、准入标准、风控指标这些。我们用了RAG技术。
RAG是什么?简单说就是给AI配一个”专属资料库”。AI自己回答问题容易编——专业术语叫”幻觉”,它不是故意骗你,是真的分不清自己知不知道。所以先从资料库里查到相关内容,再让AI基于查到的内容回答。
我以为RAG就是”把文件丢进数据库,用户问啥就去搜”。
上线第一周,审核主管打电话过来:”你们的系统用的什么政策?这个利率标准是2023年的,去年就改了!”
我去查。发现知识库里新旧版本混在一起,2023年的文件和2026年的文件同时存在。AI检索的时候按”语义相似度”排序——旧版文件里的表述方式碰巧和用户问题更”像”,所以排到了前面。
还有更离谱的:一份文件被切分的时候,”利率不得超过”和”24%”被切到了两个不同的片段里。AI搜到了前半句但没搜到后半句,就自己”补全”了一个完全错误的数字。
算法同事说了一句我记到现在的话:”这不是算法问题,是你的知识库太脏了。”
RAG的效果,80%取决于知识库的数据治理,只有20%取决于算法。
后来我重新设计了知识库架构——分三层。第一层是结构化数据精确查询(”某条法规第几条”这种有编号的需求直接精确匹配,不靠AI猜);第二层是语义检索(模糊问题用向量匹配在文档库里找);第三层是兜底(前两层都找不到就告诉用户”未找到明确依据,建议人工确认”,不让AI瞎编)。
还加了一条铁规则:所有文档入库前必须标版本号和生效日期。过期文档自动降权,不再参与检索。
这就像你请了一个米其林大厨做饭,但冰箱里的食材有一半是过期的。你得先把冰箱清干净,再讨论菜谱的事。
坑三:Prompt写了一行就上线,结果AI疯狂编造不存在的法规
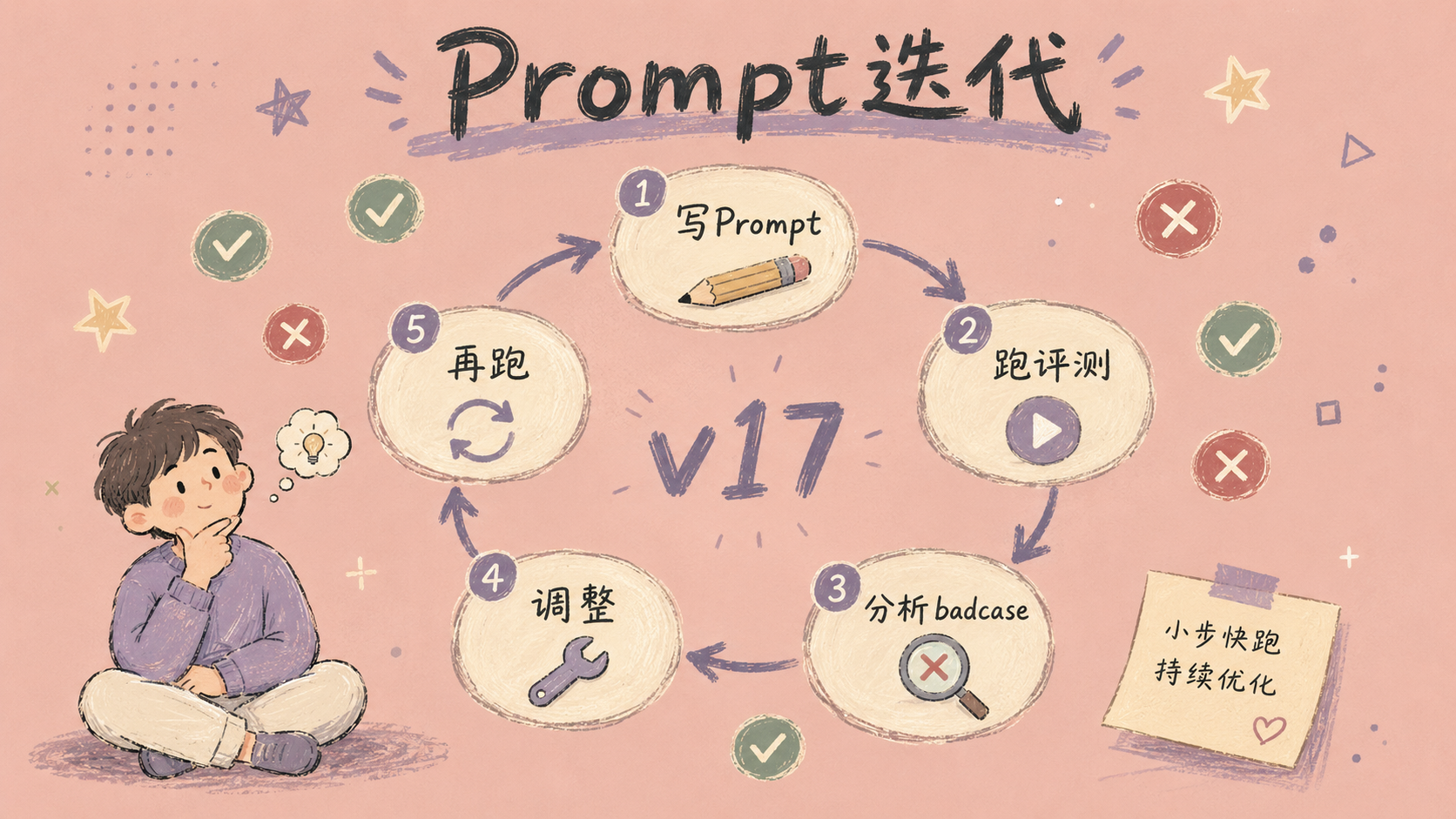
审核系统里有一个Agent专门负责合规检查——输入一份信贷申请,输出这份申请有没有违反什么法规。
我写的第一版Prompt只有一行:”请检查这份信贷申请是否符合相关法规要求。”
上线后这个Agent干了一件让人头皮发麻的事:它编造了三条听起来非常专业、格式非常规范、但完全不存在的法规,然后一本正经地说”根据《XX管理办法》第12条,该申请不符合规定”。
审核主管拿着这个结果去查了半天,发现这条法规人类法律体系里根本不存在。
AI幻觉。
算法同事反问我:”你的Prompt有配评测用例吗?”我说没有。”那你怎么知道它什么时候会编?”
从那天起我学到了一个铁律:先写评测用例,再写Prompt。
什么叫评测用例?就是你提前出20道”考试题”——这份申请输进去,AI应该输出什么。写完Prompt让AI跑这20道题,对比答案。错的就是badcase,分析为什么错,改Prompt,再跑。
第一版Prompt那一行话,经过17次迭代,最终变成了一份将近500字的指令——包括角色设定(”你是一个有10年经验的信贷审核员”)、输出格式(”必须分三个维度分析,每个结论必须标注法规来源”)、硬约束(”如果检索不到对应法规,必须明确标注’未找到依据’,禁止编造”)。
改了17版。每一版都是评测用例逼出来的——没有评测用例,你甚至不知道你的Prompt哪里有问题,因为它大部分时候是对的,只在某些边界case上会突然编造。
Prompt工程不是写一段话的创作,是持续迭代的工程。 就像写代码要跑单元测试——你不跑,就不知道bug藏在哪个角落。
坑四:业务方看了三次PRD都没看懂,一个下午做了个Demo他们5分钟就拍板了
审核系统开发到一半的时候,需要加一个新功能:自动从银行流水里提取收入信息。
我写了一份很详细的PRD——输入格式、处理逻辑、输出字段、异常场景,写了将近20页。
业务方开了三次会,每次都说”我还是不太理解这个功能最终长什么样”。
第三次会散了之后,我有点上头。回到工位打开Claude Code(一个AI编程工具——你说需求,它帮你写代码),花了一个下午搭了一个粗糙的Demo:上传一份PDF银行流水→AI自动识别→提取月均收入和大额异常→表格化输出。
界面丑得不忍直视。CSS完全没调。
第二天我把Demo拿给业务方看。5分钟他就懂了。当场拍板。
他说了一句话我到现在都记得:”我之前看了三次PRD都没想明白。你这个我一点就懂了。”
那一刻我意识到:一个能演示的Demo,胜过一百页需求文档。
从那以后我开始用Vibe Coding做原型——”Vibe Coding”其实就是:你不用真的会写代码,你告诉AI工具你想要什么样的页面,它帮你生成,你再手动调调。
做过最大的一个原型是2800多行的单文件HTML。面试的时候双击打开给面试官看,他点了半个小时没抬头,最后问:”这真的是你一个人做的?”
Web Coding不是让PM变成程序员。是让你能在下午把脑子里的想法变成一个可以点击、可以演示、可以让所有人看懂的东西。 这个速度差异在AI团队里的价值已经不是一点半点了。
坑五:选了排行榜第一的模型,上线后被合规团队一秒叫停
审核系统的核心是大模型——给它材料,它出判断。
我选了一个在公开评测排行榜上排第一的模型。确实聪明——推理能力强、理解复杂规则准、回答质量高。
上线后被安全合规团队一个电话叫停了。
原因:金融场景的客户数据绝对不能传到海外服务器。这个模型只有公有云API,不支持私有化部署。数据一旦出境,违反《个人信息保护法》和金融监管要求。
合规红线。没得商量。
就好比你买了一辆顶配跑车,结果你家小区的停车位只有1.8米宽,车门打不开。性能再好,用不了。
后来换了一个支持私有化部署的国产模型。聪明度差了一档,但能合规上线。然后花了两周调Prompt和RAG来弥补——用更精准的指令和更好的知识库让一个”85分的大脑”做出”95分的判断”。
这件事教会我一个道理:模型选型不是比谁更聪明,是看谁能在你的业务红线内把事情做好。
C端产品(比如聊天机器人)追求”最聪明”没问题。B端金融场景,合规>性能。政府项目,国产+等保认证>一切。
现在我做选型会准备50道真实业务场景的题,让候选模型各跑一遍,逐道打分。不看排行榜,只看自己的业务数据。用公开benchmark选模型,和用高考成绩招员工一样不靠谱。
坑六:系统做完了,业务方不信——”机器怎么可能比人准?”
这是整个项目里最大的坑。不是技术坑。是人的坑。
系统开发完了,准确率测下来比人工高8个百分点。按理说应该皆大欢喜。
但审核主管的反应是一脸冷漠。他原话是:”信贷审核涉及几十个维度的交叉验证。我们团队每个人都有五年以上经验。你跟我说一台机器比人准?你信吗?”
我不信。他也不信。
后来我做了一件事。从历史档案里抽了100份已审核的案件——审核结论已定、结果已知。让AI系统跑一遍,把AI的结论和当初人工的结论放在一张表里对比。
结果:AI的一致率比人工高出8个百分点。
为什么?
不是AI比人聪明。是人工审核员连续工作4小时后注意力下降——该交叉验证的维度跳过了、该看的风险指标漏看了。AI不会累,它每一份材料都查同样的维度、同样的深度。
审核主管看完那张对比表,沉默了很久。
然后说:”先让AI跑初筛,人工复核有争议的案件。”
从”完全不信”到”愿意让AI参与”,就是靠这一张100份案件的对比表。
做B端AI产品,最大的坑不是技术不行,是业务方不信你。 你不能上来就说”AI要替代人”——没人愿意被替代。你要做的是”AI辅助人”——让业务方看到数据,自己得出结论。信任建立了,再逐步放权。
这需要的不只是技术能力,是一个PM完整的全链路设计能力——你要懂业务痛点、懂人的心理、懂怎么用数据说服人、懂怎么把一个复杂系统设计成一个业务方”愿意用、用得起、离不开”的东西。
45分钟→3分52秒,背后是什么
项目最后跑通的那天,我看着系统面板上的数字:平均审核时长3分52秒。
从45分钟到不到4分钟。效率提升了10倍以上。
但让我真正有感触的不是这个数字,而是回头看的时候发现——这个项目逼着我练出了6项能力:
Agent编排、RAG设计、Prompt工程、Web Coding、模型选型、全链路设计。
这6项能力不是6个独立的技能点。它们是一套完整的”从想法到产品”的交付能力——让你从一个”写PRD等排期”的PM,变成一个”自己就能把东西做出来”的PM。
这就是2026年AI产品经理的真正门槛。
不是懂AI。是能自己把东西做出来。
市场上真正称得上AI产品资深专家的人,不是看他懂多少概念,是看他独立做出过多少东西。
那些还在用2020年的方法论做产品的PM,不是能力不行——是游戏规则变了。你不适应新规则,就会被新规则淘汰。
这话不好听。
但这是我在这个项目里看到的真实趋势。
本文由 @桃子AI产品 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Pixabay,基于CC0协议









很有收获,感谢!另外想请教一下知识库的体量是怎样的,运维负责主体与工作量如何?