
 起点课堂会员权益
起点课堂会员权益Kimi-Researcher首秀:这一波“深度研究”,打出了王者归来的气势

最近有个问题,一直在困扰着我:为什么杭州和北京的AI公司那么多,而其他地方的相对就更少呢?
正好当时我申请内测的Agent通过了,于是我就用它跑了一个深度研究的任务,然后就电脑就挂在那,干别的事情去了。
当我再次点开它的界面之后,任务已经完成了,还为我生成了一份可视化的报告:

这是那份报告的头图。
讲真的,看到这张图片的那一刻,我脑中浮现了两个字——
“精彩”。
一、Kimi的荣耀与滑铁卢
如果你问我,国产AI这么多,哪一款让我最觉得可惜,我会告诉你,是Kimi。
在早期,这个AI是我使用的最多,也认为是最好用的。
无他,因为它的长文本处理能力,在2024年的国产大模型中,堪称顶流。
2023年10月,Kimi AI首次亮相,它主打的20万字上下文长度在当时已经是一个足够惊艳的数字。之后的几个月里,Kimi AI 的月活跃用户(MAU)持续增长,从50万到298万,从2023年12月到2024年2月,只用了3个月时间。
而它背后的公司——月之暗面,也开始走入人们的视野。
2024年3月,月之暗面宣布Kimi支持200万字的无损上下文输入,引起了一波轰动,在5个月时间内,上下文长度提升10倍,同时也引起了同行在长文本领域的“内卷”,各大互联网厂商纷纷跟进,开启了“军备竞赛”式的竞争,Kimi也及时在B站投流,实现了用户的快速增长。
之后的几个月里,Kimi的月活跃用户持续攀升,到2024年11月,据创始人杨植麟所说,已经达到了3600万。
按理说,如此猛的势头,Kimi应该继续牛逼下去,直到“封神”。
可是,在2025年,Kimi却遭遇了它最为强力的竞争对手。
2025年初,DeepSeek(深度求索)横空出世,凭借开源+强大的技术实力,直接打击了包括Kimi在内的一众竞品。
2025年3月,DeepSeek月活跃用户数达到1.94亿,位居AI原生APP榜首,而Kimi的月活跃用户则是从顶峰时期的3600万下滑到了1830万,位居第四。
在国内AI用户甚至是普通民众的口中,“DeepSeek”成为了大家口中频繁出现的词汇,AI顶流的代名词,直到今天。
而Kimi呢?
仿佛它的高光时刻,已经过去,沦为了众多新兴AI的垫脚石。
我个人就有很深的体会,说实话,我已经很久没有点开Kimi的网页或者APP了。
去年3月,Kimi风光无限,今年3月,Kimi却没能够再次震撼世界。
然而,在AI圈大战没落下帷幕的时候,乾坤未定,一切皆有可能。
6月20号,月之暗面官方发布的一篇文章,让我忍不住感叹:原来不是Kimi握不动刀了,而是它拿起了板砖!
二、Kimi-Researcher,专为深度研究而生的Agent
1、你是否也有同感?
GDR(Google DeepResearch)一直是我很喜欢用的一个产品,动辄输出十多页、二十多页的报告,总让我有种莫名的“量大管饱”的满足感…
- 不过,如果要说它有什么地方有待改进的话,作为资深用户,我还是能提几个出来的:对网络环境要求极高…大家都知道,由于Gemini是国外的AI,所以如果要使用它的话,不得不用些特殊手段,这点就在无形当中制造了门槛;
- 当你发出指令的时候,它会先列出执行步骤给你确认,但是假如我们自己都没想清楚,那自然也没有办法进行修正,这种感觉,就像点外卖的时候没选择“需要餐具”一样尴尬…
- 它开始干活的时候,真的是很严格地在按照流程来执行,但是有时候太“按规矩办事”,反而失去了一些灵动感,毕竟…哪位老板希望自己的员工只像老黄牛一样吭哧吭哧地埋头苦干呢…
但是这丝毫不影响我对Gemini的爱,充其量只是相当于,喜欢的女孩脸上长了青春痘,虽然影响了美貌,但是无伤大雅…
不过总是有些遗憾。
2、Kimi-Researcher,来了。
上周五,朋友群里转发了一篇来自Kimi官方的公众号文章,就讲了一件事——他们发布了一款专门为了深度研究而生的Agent,并且现在开始了内测。
这一下,好像平静的水面投入了一颗巨石,激起千层浪…群炸了。
我也在第一时间就申请了内测。
我也忘了是多久,反正就不超过一天的时间,当我再次点进Kimi官网的时候,输入框下面就出现了一个“深度研究”的按钮。
最近AI的活动贼多,群里几乎每天都能收到“某某AI举办活动,地址在北京/杭州”这样的消息。
每次有朋友说自己要去的时候,我内心都涌现出一堆很复杂的情绪,总结两个字:“羡慕”。
所以,我稍加思索之后,就输入了这段话:
引用可靠来源,经过多角度,多维度的分析,告诉我以下答案:
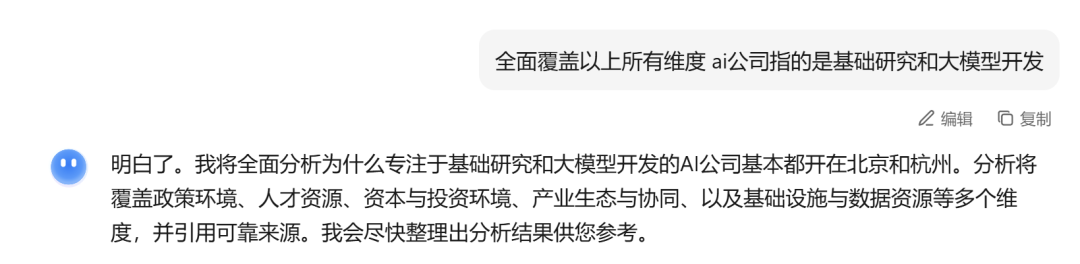
为什么AI公司基本都开在北京和杭州?
Kimi给我的回复是这样的:

我们可以看到,它不是着急干活,而是要先向我确认我的具体需求。
这一步骤,叫做“澄清问题”。是当它理解问题时,主动反问,向用户做确认,有的放矢。
其实我很怕麻烦,如果可以,我真想要的是当一名“甩手掌柜”,完全不插手,不参与。
但是这明显不太可能。
因为一旦我真的当了甩手掌柜,那么结果就完全不是我可以控制的,甚至可能输出一份与我的要求不符合的报告,不仅白白浪费时间,还给自己找罪受….
但是如果你要我说出个一二三来,准确表达我的需求,这又有点为难我了。
Kimi-Researcher直接像一名称职的助理一样,直接列出需要关注的点,让我自己选择,有了这一步操作,起码能够保证这份报告具有一定的聚焦。
然后,我就告诉它:
其实这一步我是感觉有些惊讶的。
因为我自己都没注意到,我提出的“AI公司”这个概念太庞大了,但是Kimi注意到了,并且还向我发起了提问。
那在之后的时间里,我原本应该去干自己的事儿,坐等报告就好,但是奈何Kimi Research执行任务的过程太精彩了,比小说还好看,一下子就吸引了我的眼球。
直到这里,我才想起,Kimi-Research,它就是一个Agent啊!
Kimi-Research并没有选择一条道走到黑——只关注在这些特定问题上不懂变通,而是学会了自己思考。
这个部分,是它的深入思考:能够自主梳理并理解需求,在这当中,我们只需要帮助它锚定需要聚焦的点就可以,其他的让其自由发挥。
我们同样,也能看到,它其实是有在提取关键词,根据关键词进行搜索的,而且它能够筛选,把那些信息质量高的来源主动摘取出来,作为报告的引用源。
而这,是它任务步骤中的“主动搜索”。
它在不需要人工干预的情况下,经过推理之后自行采取更加合理的策略,使用更加高质量的搜索来源。
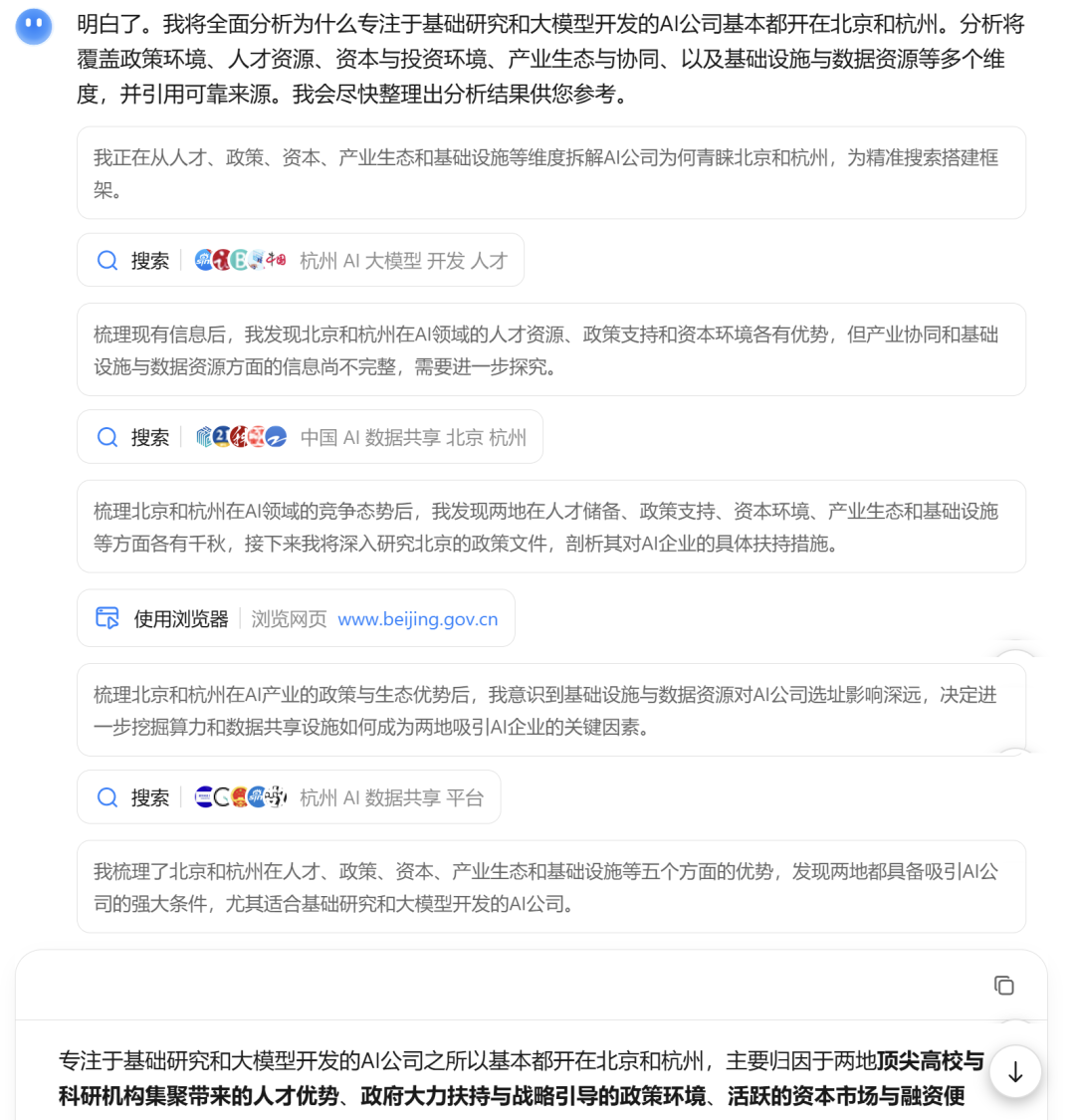
在经过不算太漫长的等待,大约5分钟左右之后,这份由我+Kimi-Research共同撰写的研究报告就完成了。
在这过程中,它出现了明显的自主性,调用合适的工具完成任务,交付结果。
随之输出的,不仅是一份文字报告,还有一份网页的可视化报告。
仔细看这份文字报告,它不止有文字,它还在每个引用的地方标注了参考来源。当我们点击文字旁边的方块后,在右侧会跳转到对应的引用内容,并且对于它引用的部分,还进行了高亮处理。
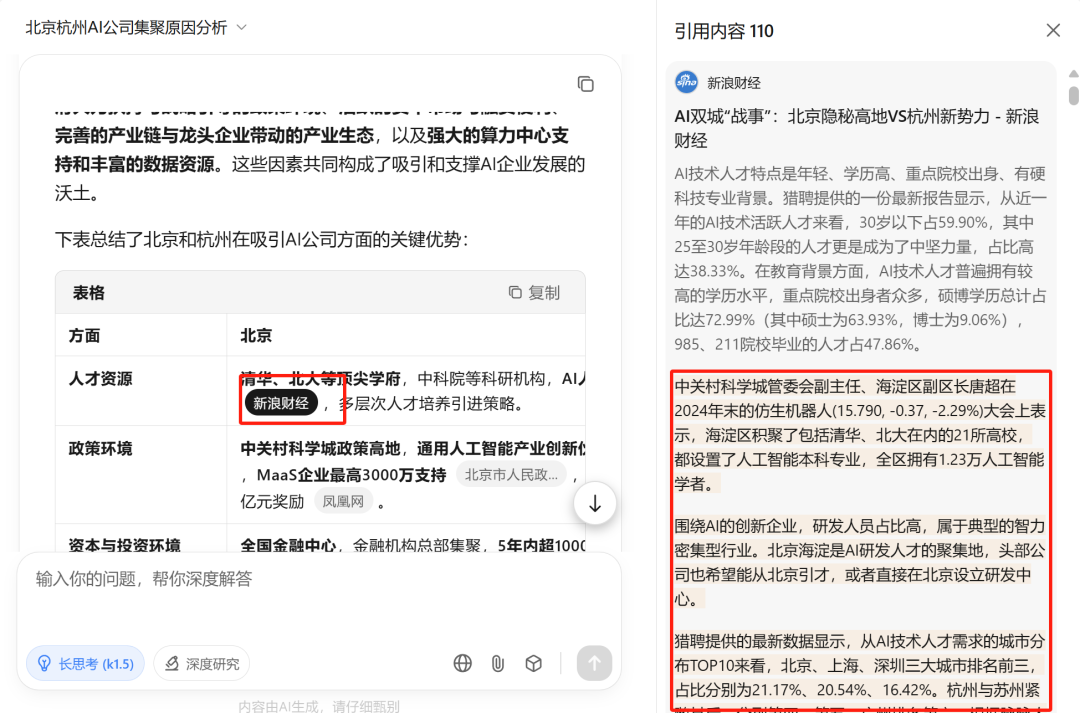
点进它引用的文章,跳转页面,我们又能看到一个细节:
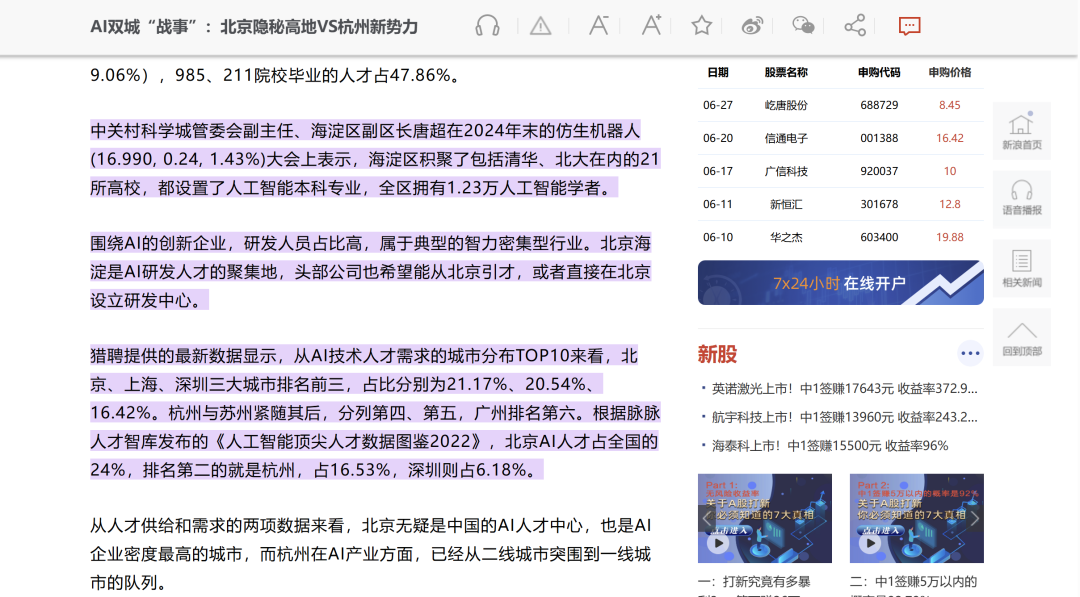
它从哪段开始引用的,在来源的网页里,也给你标出来了。
仿佛真的是一名严谨专业的研究员。
而且….
我写论文的时候,也没有这么严谨好吧。
真正的做到了“可溯源”,确保了信息来源的可靠性。
在以前,为了防止AI随意杜撰,捏造一些不存在的网页,我都会在提示词上加一段:“引用可靠的来源,不要随意杜撰”。
但是现在,完全不需要了。
因为Kimi会自己帮助你验证这些网站的可靠性,这就是它“懂我们没说的”。
完整的文字报告太长了,我就不放了,大家可以在评论区回复,我会私发给你。
可视化报告如下:
网页链接:https://www.kimi.com/preview/d1e1ln9sfuve986n5brg?blockId=18
在这个网页里,我们能看到,它的左边是有目录的,点击就能够跳转到对应章节。而且对于有需要的地方,它能够帮你绘制表格,形状,而且样式还特别精美,保证你看了之后不会想打瞌睡。

只因你…你的报告,你做主。
考虑到大家的观感…请点击上面的网页移步观看,记得回来,因为精彩的内容,才刚刚开始。
三、案例测试
之后,我又跑了好几个案例,我将它的问题澄清部分和我的回复都放在下面,是不是够强大,有没有严格遵循我的指令,交给朋友们来评判,如果你要文字版本,欢迎在评论区留言:
1、提示词的输入对AI输出结果的决定作用
提示词:提示词的输入对于AI的输出结果起到怎么样的作用?请参考可靠的信息来源,从多方查证后,为我输出一份深度研究的报告。
Kimi确认需求:

我的回复:

生成的可视化网页:https://www.kimi.com/preview/d1e2pvope77i9aeu4itg?blockId=52
2、那艺娜为什么还能这么火?
提示词:
那艺娜明明被拆穿了俄罗斯人的身份,为什么现在还那么火?
Kimi确认需求:

我的回复:

生成的可视化网页:https://www.kimi.com/preview/d1e2ujo52cekgv1uhep0?blockId=18
3、Kimi从发布到今天的月活用户变化
提示词:
Kimi AI发展情况是怎么样的?它的月活用户量变动情况如何?未来它有可能怎么样发展?请从Kimi的发布时间开始算起,直到今天2025年6月24日,参考可靠来源, 从多视角、多维度进行深度研究,为我生成报告。
Kimi确认需求:

我的回复:

生成的可视化网页:https://www.kimi.com/preview/d1e36njlmiuf20s294n0?blockId=38

在这当中,Kimi-Research出现了一个很有意思的行为:它在没有任何干预的情况下,察觉到了代码存在问题,所以果断放弃了代码,选择了直接撰写报告。
具体为什么会这样?
所谓“知其然知其所以然”,在研读了月之暗面发布的技术解析博客后,我想试试看,用大家能听得懂的语言,来为大家讲解,在发起任务到完成交付的过程中,Kimi的这个Agent,用了怎么样的技术,如果有不完全的地方,请大家见谅哈~
四、技术原理解析
1、端到端自主强化学习
首先,我们应该知道,什么是“端到端”,指的是“用户输入”到“交付结果”中间,没有任何的人工干预,也不出现既定的套路模板,而是由Agent自行完成。Open AI的深度研究也采用了这样的方式。
其次,“自主强化学习”,指的是模型能够自动调用相关的工具,并且根据任务的进度能够自行判断哪个工具最为合适,不依赖我们的提示词,自己就能够走完全程。
2、奖励机制
这是强化学习中很重要的一个概念。它能够帮助模型分辨“好”与“不好”。
为什么会这样?
在一开始的时候,就由人工进行标注,让人类为模型的回答打分。
例如,面对“今晚去哪里吃饭”这个问题,模型给出的回答是“去找家餐厅吧”,对这个回答给予高分;而对“去厕所”这个回答给予低分,这样就得到了原始的标注好的数据。
再根据标注好的数据,来训练一名“打分员”(奖励模型),让模型自己来判断好与不好。每次生成回答后,“打分员”会对回答进行打分,模型再根据回答调整自己的解题思路(参数),这个过程中,模型的回答会越来越偏向于人类满意的回答,这个过程就叫“强化学习”。
而在Kimi-Researcher中,使用的奖励机制是两种:
- 格式奖励:每当模型的操作不符合“操作手册”的规范,它就会被扣钱(获得负奖励),从而帮助它的操作具有规范性和有效性,变成一名听话的好员工。
- 正确性奖励:基于格式奖励,对于模型符合操作规范的情况,将它最终输出的答案与标准答案进行比较,这就促使它的每一步都是为了产生更好的。
然而,对于操作流程完全正确,答案符合标准的两条答复,路径较短、更高效的回答,会在一开始就能够得到奖励,从而帮助模型能够更加有效率的完成任务。
3、上下文管理
对于更复杂、流程更繁琐的任务,模型引入了上下文管理的方法,它就像聪明的学生,并不是每条消息都去记,而是会选择更重要的,丢弃不必要的,从而有选择性地去记忆,这样就能获取更多信息,实现更高的性能。
4、并行工具调用
为了完成任务,Kimi-Researcher携带了三样工具。
- 并行的实时内部搜索工具:可以同时发起多个请求,缩短信息检索的时间,从而更高效地找到答案,如果任务需要大量背景信息、专业知识,或者是某些特定的数据,这个工具是很关键的。
- 用于交互式网页任务,基于文本的浏览器工具:它会模拟人类在网页上的操作,例如点击链接、提取特定区域的内容,使得模型能够在一些交互式的网页中提取数据。
- 用于自动执行代码的编码工具:还记得刚刚截图里我们看到的使用python编码的操作吗?它就是来自于这个编码工具,它赋予了模型计算能力和数据处理能力,可以运行python代码,对于收集到的数据进行分析和处理。
而这三个工具,都被放置在端到端的自主强化学习框架下,供模型自己选择什么时候用什么工具,能够更好完成任务。
五、怎么样才能用上?
目前,Kimi官网已经开放了对Kimi-Research的内测申请。
电脑进入Kimi官方网站:https://www.kimi.com/
在输入框下方,点击“申请Kimi Research内测”:
现在通过的时间应该蛮快的,不会超过半天,你填写的手机号会收到一条短信,告诉你申请通过。
再次进入官网,你会发现,输入框里多了一个按钮:

这就说明你已经可以用Kimi-Research,为你完成任务了。
需要注意的是,每个月20次使用额度,别一不小心就用完了~
Kimi-Research虽好,可别贪用哦~
谁需要Kimi-Research?
如果你是一名学生,你可以用它来帮你搞懂复杂难懂的概念,让Kimi来当你的老师,陪伴你在学习道路上过五关斩六将;
如果你是数据分析从业者,那就更好办了——Kimi会帮你自动筛除掉那些无用的、低质量的信源,采用高质量的、有效的,对你需要整合的数据进行深入分析;
如果你是一名学术研究人员,或者正在撰写学术论文,你可以让Kimi来帮你查找可靠的资料,省去你辛苦跑知网、维普、万方,查找、阅读论文的时间;
如果你是酷爱冲浪的选手,你也可以用Kimi,轻松得知一个梗的前世今生,就像我用它来分析为什么那艺娜会那么火的原因一样,让你轻松踩在浪潮前端,打破信息差,不掉队。
….
更多好玩的场景,等你来发现。
六、Kimi,尚能饭否?
在以上的内容中,我们一起跑了几个任务,但是我心中仍旧有所怀疑,那就是:它和传统意义上的深度研究,区别在哪?官方说它是一个Agent,真的做到了吗?
于是,我把这个问题扔给了ChatGPT。

它对于Agent的定义,有点意思。
ChatGPT认为,合格的Agent应该做到五个方面,将单词“Agent”拆分开来:
🐏
A-G-E-N-T
Awareness(有感知):能识别用户意图,哪怕用户没说,它也能做得好。能理解上下文,也能看懂网页,读懂文档。
Goal-oriented(有目标):并不是像无头苍蝇一样到处乱转,而是有着清晰的结果导向,并且为了达到目标,而调用自身一切的资源。
Execution(能行动):能操作工具,完成任务。
Navigation(能规划路径):不只是将大目标拆分为子任务,而是有规划的去执行,不墨守成规。
Tuning(能自我调整):面对查询到的数据有冲突,策略有错误的时候,它不钻牛角尖,而是自己做决定,选择更好的方案。
那从这一点看来,Kimi发布的首个Agent,确实成了。
为什么Kimi的第一个Agent,要做Researcher,这个看似好像没有必要再继续扩展的赛道?
官方的一句话,让我泪目:

并且,在不久的将来,Kimi-Researcher 的基础预训练模型以及其背后的强化学习模型,会被开源出来,让我们每个人都实现“研究自由”。
Kimi,尚能饭否?
答案是:能!并且肯定会继续变好。
让我们期待,Kimi重现辉煌的那一天。
感谢你的观看,如果你觉得这篇文章有帮到你,是我的荣幸~
欢迎点赞、推荐、转发给你那还在为了论文、为了报告而焦头烂额的朋友。
如果你也用Kimi-Researcher整了更好玩的活,欢迎在评论区分享~
本文由 @ Simonlin(公众号同名)原创投稿或授权发布于人人都是产品经理。未经作者许可,禁止转载
题图来自 Unsplash,基于CC0协议,该文观点仅代表作者本人。






- 目前还没评论,等你发挥!


