
 起点课堂会员权益
起点课堂会员权益你写的每一个烂表单,都是因为校验顺序搞反了
表单校验的设计逻辑远比想象中更值得深思。从空值拦截到数据库查重,五层校验架构揭示了数据过滤的黄金法则——成本越低的检查越应前置。本文将拆解这套源于数据库优化思想的校验范式,揭示前端与后端校验的协同策略,以及如何用一张矩阵表彻底解决开发与测试的沟通难题。

上周review代码,后端同事写了个新增数据的接口。我点开一看,校验逻辑大概是这么个画风:
先查数据库看有没有重复记录,再校验字段格式,最后才判断必填项有没有传。
我说兄弟,用户连商品名都没填呢,你就去查库了?数据库它也是有感情的好吧。
他愣了一下:”这有啥区别吗?反正最后都会报错。”
区别大了。校验能不能拦住脏数据是及格线,校验的顺序才是你设计水平的分界线。
这事让我想起之前踩过的一个坑。
我们系统有个”新增周度数据”的表单——商品、企业、省份、周产量、周库存、价格、成本、毛利,十几个字段。刚上线那会儿,校验逻辑是前端同事”凭感觉”写的,想到哪验到哪。
结果呢,用户填了个负数的价格,系统没拦住,直接跑去做毛利计算了。算出来一个离谱的毛利率,存进了数据库。下游的价格分析模块一读这条数据——Loss预测直接飞了,分析师第二天跑来问我们”这个品种是不是出bug了”。
查了半天,就是因为范围校验被放在了关联计算的后面。价格是负数这件事,本来在第三层就该拦住的,结果漏到了第四层,还引发了连锁反应。
一个校验放错位置,链路上所有下游都跟着遭殃。
这事之后我就开始琢磨:表单校验这东西,到底有没有一套通用的、稳定的设计范式?
还真有。而且特别朴素。
五层过滤,越便宜的检查越先跑
我后来把校验逻辑梳理成了五层。不是我发明的,你去看任何一个成熟框架的参数校验,底层逻辑都是这个:
L1 — 存在性:传没传?
最便宜的检查。字段是不是null、空字符串、undefined。带星号的必填项,这一层全覆盖。用户点提交,先扫一遍,没填的直接标红,后面全部跳过。
为什么放第一层?因为一个空值,你去做格式校验没意义,做范围校验更没意义。就好比你拿到一个null去调.length(),不是校验失败的问题,是直接NPE给你看。
L2 — 格式类型:像不像?
字段有值了,看看这个值的”形状”对不对。周产量填了”哈哈哈”——类型不对。日期字段收到一个”2026-13-45″——格式非法。邮箱没有@符号。手机号混进了字母。
这一层本质上是做类型转换前的门卫。过了这关,后面的逻辑才能拿到一个”至少类型是对的”的值去做进一步判断。
很多前端框架(Ant Design的Form、Element的el-form)自带的validator其实就管到这一层。但光靠这层远远不够。
L3 — 范围边界:合不合理?
格式对了不代表值是合理的。价格不能为负数。库存不能是-500万吨。年度不能填2099年。百分比字段不能出现200%。
这一层过滤的是”格式正确但业务上离谱”的数据。我管这叫”合法的垃圾”——类型系统认它,业务逻辑不认它。
经常被忽略的一个细节:小数精度也属于这一层。价格保留两位小数,你传进来一个3.14159,后面计算会不会出精度漂移?该在这里就truncate或者round掉。
L4 — 关联逻辑:字段之间自洽吗?
单字段都合法了,但字段之间可能打架。
毛利 = (价格 – 成本) / 价格。这三个字段之间有硬约束。用户手动填了毛利和价格,但填的成本算出来对不上——这就是跨字段逻辑校验该干的活。
还有一类更隐蔽的:条件必填。比如选了某个商品工艺之后,产量单位的可选范围要联动变化。选了”省份”之后,”企业”的下拉列表要跟着过滤。
这一层的成本比前三层高不少,因为你要同时拿到多个字段的值做交叉判断。所以它排在第四。
L5 — 全局外部:跟系统里已有的数据冲突吗?
最贵的一层。要查库。
同一个”商品 + 企业 + 省份 + 周度时间”的组合,不能重复录入。这个判断必须发请求到后端,后端去数据库里跑一条select。网络IO + 数据库查询,这是整个校验链路里成本最高的操作。
所以放在最后。只有前面四层全部pass了,才值得发这一趟请求。
你想想,如果把L5放在L1前面会怎样?用户连必填项都没填全,你就发了一次数据库查询。并发高一点,这种无效查询能把你的DB连接池吃得干干净净。
本质就是个短路求值。任何一层挂了,后面不跑。这不是什么高深的设计模式,就是最朴素的成本排序——选择性高、代价低的条件先执行。
你去看数据库查询优化器选执行计划的逻辑,一模一样的思路。MySQL决定先走哪个索引、先过滤哪个条件,背后也是这套”便宜的先来”。
这套思路不只管表单
你再想远一点。
API接口参数校验,是不是同一套?收到请求 → 必传参数在不在 → 类型对不对 → 值域合不合理 → 参数间逻辑(start_date < end_date)→ 权限校验(查Redis/查DB)。任何一个成熟的API框架,中间件链的排列顺序就是按这个来的。
ETL数据清洗,也是。拿到一批CSV → 空行删掉 → 格式统一(日期转ISO、数字去逗号)→ 异常值过滤(价格为负的行剔除)→ 跨字段一致性校验 → 跟主表去重。你要是把去重放在第一步,几百万条数据先全量join一遍,跑到天荒地老。
甚至代码review的时候,你看一个PR,下意识的扫描顺序也是:这个改动有没有(L1,别是个空PR)→ 改的对不对地方(L2,文件和模块对不对)→ 改动幅度合不合理(L3,是不是改了不该改的)→ 跟其他模块有没有冲突(L4)→ CI跑过没有(L5,外部验证)。
同一套模型,不同的皮肤。
落地的时候,一张表搞定
回到实际工作。我现在写PRD里的表单需求,直接用一张校验规则矩阵表跟开发对齐:
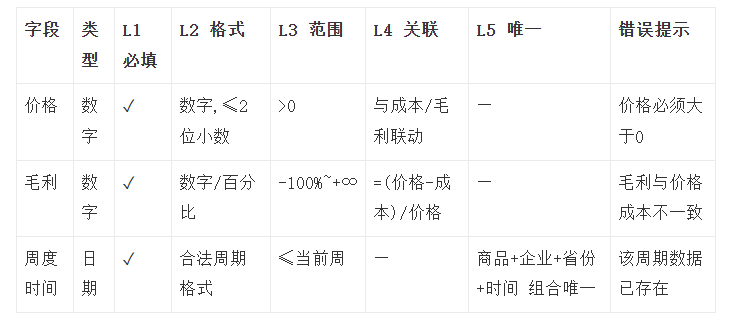
比在PRD里写一大段”当用户输入价格时,系统应判断价格是否为空,如果为空则提示……如果不为空则继续判断格式……”清楚十倍。开发拿到这张表,每个字段每一层该干嘛,一目了然,不用反复对齐。
测试同事也爱这张表。写测试用例的时候,每一层就是一组case。L1的case:每个必填字段分别传空。L2的case:每个字段分别传非法格式。这么列下来,漏测的概率小很多。
前端校验和后端校验的关系
顺便说一个容易吵架的点。
前端该不该做校验?当然该做。用户体验好,即时反馈,不用等网络往返。
但前端校验能不能当安全防线?不能。因为前端校验可以被绕过——随便开个Postman直接打接口,你的前端校验跟没有一样。
所以正确的做法是:前端做L1到L4,体验层面拦一道。后端L1到L5全部重跑一遍,这是安全兜底。 L5本来就要查库,只能在后端做。
别觉得后端重复跑一遍是浪费。安全领域有个原则叫”纵深防御”——不是一道墙够高就行,是多道墙叠在一起,每道都有可能拦住一类攻击。校验也是一样。
有些团队为了省事,前端做了校验后端就不做了。我只能说,等哪天被人用脚本往你接口里灌脏数据的时候,你就知道这个偷懒有多贵了。
说到底,校验设计这件事没有什么花活。就一条原则:
先做便宜的判断,再做贵的判断。先用本地信息,再用外部信息。先查格式,再查语义。
把这条刻进DNA里,不管是写表单、设计API、搭数据管道还是做消息消费,你的校验逻辑都不会太离谱。
至于那个把查库放在第一步的同事——他后来重构了。现在那段代码的注释写着:
“L1→L5,别改顺序。改了请客。”
本文由 @尤里卡高 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议





- 目前还没评论,等你发挥!


