
 起点课堂会员权益
起点课堂会员权益预见2024:大模型成长进入关键期,探究AI背后的算力需求
各行各业都对大模型保持着高度关注,而在这股大模型浪潮背后,算力需求无处不在,算力问题也成为了未来大模型行业需面临的发展挑战之一。一起来看看本文的解读。

距离大模型横空出世已经过去一年有余,在AI大模型的浪潮下,各大科技企业争先恐后地推出了自家的大模型产品。
与此同时,各行业企业也对大模型保持着高度关注,一些其他行业的企业也纷纷跨界布局大模型相关产品。
面对着全球都在追逐的大模型浪潮,这也使其对算力需求无处不在,但算力供给相对有限,“缺口”或许将影响人工智能的发展。未来,算力问题也成为各行业实现人工智能普惠的最大难点。那么,这一困局如何破解呢?
一、大模型在流行
《北京市人工智能行业大模型创新应用白皮书(2023年)》中显示,截至2023年10月,我国10亿参数规模以上的大模型厂商及高校院所共计254家,分布于20余个省市/地区。
商业咨询机构爱分析的报告称,2023年中国大模型市场规模约为50亿元,预计到2024年这一数字将达到120亿元。
显然,2024年,大模型将继续其火热的现象,在2023年形成的百模大战竞争将会进一步白热化,进一步渗透到各行各业的数字化进程中。
我们看到,大模型真正的价值在于行业侧的应用落地,就目前业内对大模型的认知来看,绝大多数人对大模型相关产品的发展观点类似于互联网,消费级只是开始,产业级价值更大。
但如同互联网一样,消费互联网发展迅速,甚至已经接近“天花板”;产业互联网也仅是近年来在政策引导,数字技术驱动下,逐步发展提速。
二、为什么大模型技术是产业界的一次革命呢?
一直以来,AI在产业化的进程当中,发展得非常慢。那么在大模型的技术出来后,我们认为它来到了一个转折点。
需要了解的是,大模型不仅是一个聊天机器人,也不是像抖音、快手这样让人消磨时间的娱乐软件。它是一个提高生产力的工具,不仅仅是公司间竞争的利器,更重要的是,它像发电厂一样,把以前很难直接使用的大数据从“石油”状态加工成了“电”。而“电”是通用的,就能赋能百行千业,就能够在实体经济转型数字化、智能化的过程中发挥重要的作用。
据有关机构预测,未来三年,在生产经营环节应用AI大模型的企业占比将提高到80%以上。
为了进一步释放AI的效果,我们需要推动产学研用的深度融合,强化高价值的数据、高性能的算力、高质量的算法和协同创新,加快关键技术突破和产业应用,让AI不仅会写文章做PPT,更能够实际应用于各个领域。
然而,随着大模型的不断发展,我们也面临着一些挑战。
比如,目前的大模型是万事通,但不是行业通。如果你真的用过大模型,在震惊完它什么都会之后,你会发现一旦问它一些行业的问题,它就会说很多概念性的正确废话。也就是说,大模型对行业理解的深度还远远不足。
大模型无法保证生成的内容完全可信,或者说大模型能产生知识模糊、制造知识幻觉。比如它会输出“贾宝玉打虎”“林黛玉三打白骨精”等不符合事实的信息。
我们认为,相比于AI大模型自身发展的问题,算力不足的问题更显突出。由于大模型的规模庞大,需要巨大的计算资源来进行训练和推理。
但现有的计算基础设施还无法满足这一需求,这导致了训练时间过长、推理速度缓慢等问题。这不仅限制了大模型的应用范围,也制约了我们的创新步伐。
三、AI时代,算力需求增加
我们看到,GPT-3实际上是生成语言生成模型,他参数量大概1750亿,而随着GPT-4和未来GPT-5的推出这个发展趋势还会延续。
比如,对标GPT-3和GPT-4模型,GPT-3模型训练使用了128台英伟达A100服务器(训练34天),对应640P算力,GPT-4模型训练使用了3125台英伟达A100服务器(训练90—100天),对应15625P算力。从GPT-3至GPT-4模型参数规模增加约10倍,但用于训练的GPU数量增加了近24倍(且不考虑模型训练时间的增长)。
从全球算力的表现状态分析来看,从22到23年经历了疫情,数字经济其实在这几年增长还比较快。
尤其数字化优先成为企业重要的战略发展途径。所以算力已经成为整个行业里面科技的更新和迭代的一个重要支撑。
四、未来算力发展的趋势
众所周知,人工智能实现方法之一为机器学习,而深度学习是用来实现机器学习的技术,通常可分为“训练”和“推理”两个阶段。
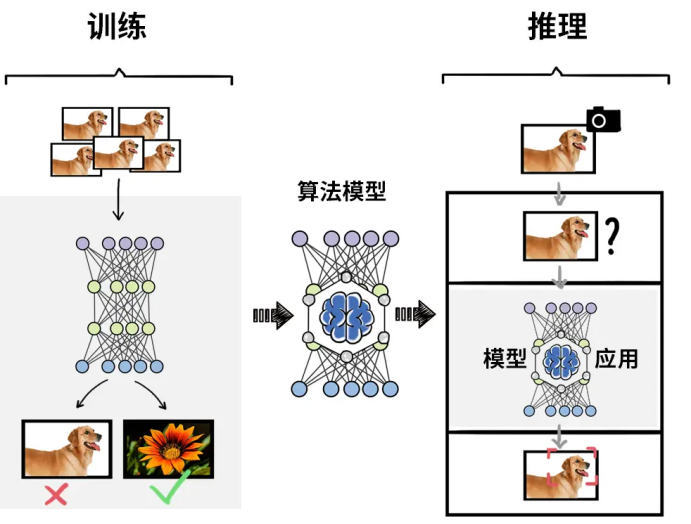
训练阶段:需要基于大量的数据来调整和优化人工智能模型的参数,使模型的准确度达到预期,核心在于算力。
推理阶段:训练结束后,建立的人工智能模型可用于推理或预测待处理输入数据对应的输出,这个过程为推理阶段,对单个任务的计算能力不及训练,但总计算量也相当可观。
虽然,目前算力的需求在不断增加,也导致了出现“算力危机”,但我们看到突破这些危机的一些技术趋势。
第一个趋势,在算力层面,我们看到通用算力正在转向专用算力,也可以称为智能算力。专用算力包括以GPU为核心的并行训练加速,例如,英伟达DPU,谷歌的GPU,还有新型的算力形态,如NPU等,用于加速 AI 载体。

第二个趋势是从单点到分布式的发展。在十多年前,我们可能只需要使用CPU进行AI模型训练,然后逐渐转向GPU加CPU的方式。当时由于CPU和GPU的编程方式不同,需要重新编译两次才能在CPU和GPU上运行,因此在那个时候,AI模型通常在单台机器上单卡上运行。随着模型参数的增加和模型类型的多样化,从单机单卡逐渐演变成了单机多卡,然后随着GPU的崛起,从单机多卡又发展为分布式训练。这也使得模型训练的速度更快。
第三个趋势是能耗和可持续性。随着训练集群的出现,能耗上升成为一个问题,数据中心需要进行改建和升级以满足能耗要求,这也引发了合规和可持续性的关注。高能耗需要政府批准,因此降低能耗、实现绿色和节能成为趋势。
第四个趋势是软硬结合。从纯硬件走向软硬件结合,尤其是英伟达等公司的带领,软件生态系统变得至关重要。软件工程师和人工智能算法工程师的参与推动了这一趋势。
就我国而言,未来,随着新的算力芯片到来的,还有国内各地出台的一系列利好政策,也积极引导大模型研发企业应用国产芯片,加快提升算力供给的国产化率,提升算力资源统筹供给能力,携手企业共同推动算力市场发展。
五、写在最后
可以说,算力是数字经济时代最底层的驱动器,无人驾驶、智慧城市、智能交通、智慧金融、仿生科技、生命医学、气候预测以及农业精细化等,都离不开超大算力的支持。在未来的大国竞争中,算力之强弱将直接深度影响到新技术的研发效率和研发成果。
未来,大模型时代的全面到来,注定充满挑战,而挑战往往孕育着机遇。以计算为代表的颠覆技术成为大模型时代的重要底座。最终,谁将主导这场算力的变革,让业界看到大模型市场的新机会,在广阔的市场中率先突围呢?我们拭目以待。
作者:贾桂鹏
原文标题:预见2024:大模型成长进入关键期,探究AI背后的算力战争
本文由 @元宇宙新声 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。





- 目前还没评论,等你发挥!


