
 起点课堂会员权益
起点课堂会员权益数据基础(二)数据表关系
在数据分析与建模中,表关系是最基础却最容易被忽视的环节。合理的关系设计不仅能提升查询效率,还能避免冗余与逻辑混乱。本文将系统梳理数据表关系的类型与应用场景,为你打下坚实的基础。

在《数据基础(一)双向关联》文章中,讲述了数据表双向关联的优缺点,以及引入中间数据关系表的优缺点。本篇进一步厘清和扩展两种数据关联方式的优缺点。
被关联字段必须具备的特征
两数据表发生关联是通过数据表中的字段,即一个数据表的字段指向另一个数据表的字段。例如,数据表users的字段department_id存储数据表departments的id字段值,通过字段department_id的值D2可以找到数据表departments字段id=D2的一整条数据信息。
示意图:
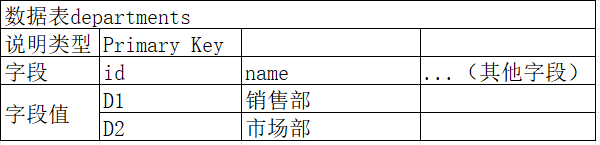

在上述例子中,数据表users外部链接数据表department的id值,但关联字段并非必须是数据表主键。
关联字段必需具备的特征:①唯一性;②非空性。
通常数据表主键满足上述条件,若不是主键字段需要添加约束条件保证字段值“唯一”且“非空”。
业务关系“一对多”:两个数据表关联
为什么直接关联能很好支持 “一对多关系”?
一对多关系的核心是 “一个主表记录可对应多个子表记录,而一个子表记录只能属于一个主表记录”,如 “部门(一) – 员工(多)”。
(图,见上表)departments被称为主表,users被称为子表。
主表(如departments):无需存储子表信息,仅维护自身业务数据(id、name等);
子表(如users):通过外键字段(department_id)关联主表的唯一且非空字段(department.id),每条用户记录明确指向唯一部门。
优势:
1、无冗余:子表的外键字段仅存储对应主表的ID,每条记录的关联关系唯一且清晰;
2、易维护:新增、删除、更新子表记录时,只需操作自身的外键字段,无需改动主表;
3、查询高效:通过JOIN子表的外键与主表主键,可快速实现双向查询(如“查用户的所有订单”或“查订单所属用户”)。
为什么直接关联无法支持“多对多关系”?
假设业务支持一个员工属于多个部门。
方案1:两表互设外键
上述数据表例子,在数据表departments中加字段users_id,设为Poreign_Key。
departments表的users_id只能关联一个员工;users表的department_id只能关联一个部门。实际为“一对多”的双向冗余,不能通过一个语句实现“多对多”查询。
方案2:在A表中添加B表的ID列表
users表加department_ids。
问题:department_ids需存储多个部门ID(如1,2,3),违反 “原子性” 原则(字段应只存单一值),且查询、更新时需解析字符串,效率极低;
冗余:若多个用户选同一部门,部门ID会被重复存储多次。
业务关系“多对多”:引入中间关系数据表
引入中间数据表departments_users

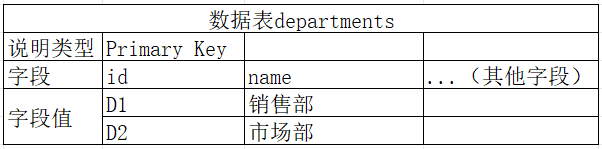
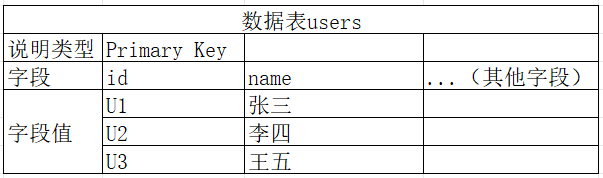
如上图三张表,其中数据表departments_users同时关联两张表,存储主表departments和users的主键。
优势:
1、完美表达多对多关系
通过查询数据表departments_users直接获得多对多数据查询结果,如属于销售部或市场部的全部员工。
2、可以存储关系本身的属性
如数据表departments_users加字段date记录员工加入部门的时间。
3、保证查询高效
补充:幽灵数据
产生原因
1、外键约束缺失或失效
当两个表存在关联关系(如“订单表”关联“用户表”),若未设置外键约束,或外键约束被临时禁用/删除,可能导致“子表引用了主表中已删除的记录”。
例如:用户表中某用户记录被删除后,订单表中关联该用户的订单未被同步删除,这些订单就成了“幽灵订单”(因为找不到对应的用户)。
2、业务逻辑漏洞
程序代码中未处理数据删除/更新的联动场景,导致关联数据未被同步清理。
3、异常流程中断
事务执行过程中因崩溃、网络中断等异常终止,导致部分数据已写入但未完成后续清理。
4、历史遗留与需求变更
①旧版本系统中的数据字段或表结构被废弃(如业务模式调整后不再使用的“会员等级历史”表),但未被彻底删除;
②需求变更后,某些数据失去业务意义(如原需存储的“用户兴趣标签”因功能下线而不再更新,沦为无效数据)。
5、临时数据未及时清理
系统运行中产生的临时数据(如缓存中间结果、会话数据、日志快照)若未设置过期清理机制,会逐渐积累为幽灵数据。
6、误操作或测试数据残留
①开发/测试阶段插入的测试数据(如模拟用户、虚假订单)未在上线前清理,混入生产环境;
②人为误删除关联数据的一部分(如误删 “商品分类” 却未删除该分类下的商品),导致剩余数据成为幽灵。
影响
浪费存储资源,增加数据库备份、迁移的成本;
- 干扰查询结果(如统计“有效订单数”时包含幽灵订单,导致数据不准);
- 降低查询效率(无效数据增加索引体积和扫描范围);
- 可能引发业务逻辑错误(如程序误读取幽灵数据并进行处理)。
本文由 @产品-子鱼 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


