
 起点课堂会员权益
起点课堂会员权益自动驾驶2.0时代已至:VLA与VLM如何重塑出行?
自动驾驶正在经历从感知到决策的质变飞跃。最新涌现的VLA和VLM技术不仅让车辆'看见'世界,更赋予其人类般的思考与行动能力。本文将深度解析这两种模型的差异与演进,揭秘它们如何攻克长尾场景、实现人车共驾,并推动汽车与机器人产业的跨界融合。

2026年,自动驾驶领域正迎来一场深度的技术变革。如果说早期的技术是让车辆“看见”世界,那么现在的VLA(视觉-语言-动作模型)和VLM(视觉-语言模型)则是在教车辆如何像人类一样“思考”并“行动”。
我们先认识一下什么是VLM和VLA
1. VLM(Vision-Language Model),称为视觉语言模型
是一种多模态人工智能模型,设计用来理解和处理视觉信息(图像、视频)和语言信息(文本)之间的联系。它们融合了计算机视觉和自然语言处理的技术。
核心能力是擅长将视觉内容与语言描述关联起来,例如:
- 图像描述生成(看图说话)
- 视觉问答(根据图片内容回答问题)
- 图文检索(根据文本找图或根据图找相关文本)
- 多模态对话(结合图像和文本进行交流)
输入: 可以接受图像/视频 + 文本的组合作为输入。
输出: 通常生成文本输出(描述、答案等)。
2. VLA(Vision-Language-Action Model),意思是视觉语言动作模型
是一种扩展了 VLM 能力的多模态模型。它不仅理解视觉和语言信息,还能基于这些理解来规划或执行具体的动作或任务。它是迈向具身智能(Embodied AI)的关键一步。
核心能力: 在 VLM 能力的基础上,增加了决策和行动的能力:
- 理解环境(通过视觉)
- 理解指令(通过语言)
- 规划并执行动作来实现目标(如机器人操作、游戏控制)。
输入:图像/视频 + 文本(指令或任务描述)。
输出:文本 + 动作序列/决策(例如,控制机器人的指令、在虚拟环境中的下一步操作)。
它们之间的主要差异:
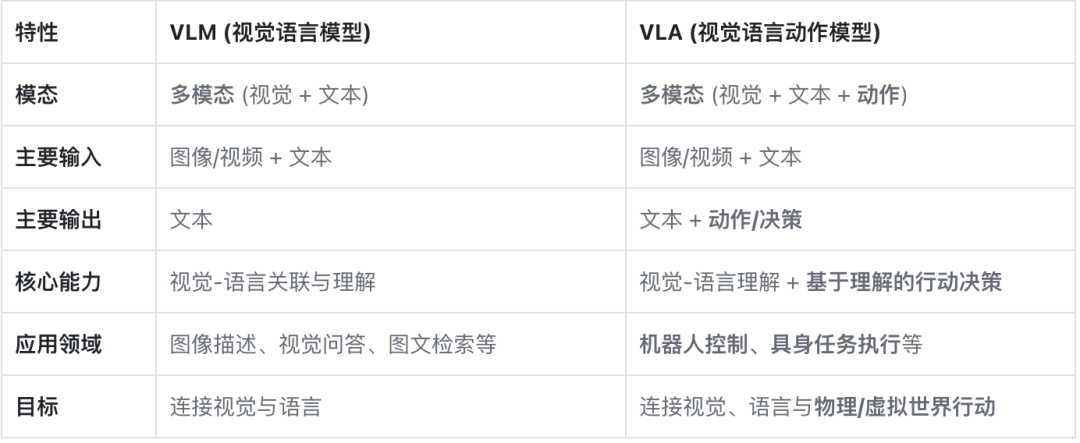
简单来说:
- VLM是理解图像和语言之间关系的高手。
- VLA是在 VLM 的基础上,增加了根据视觉和语言信息来采取实际行动的能力。
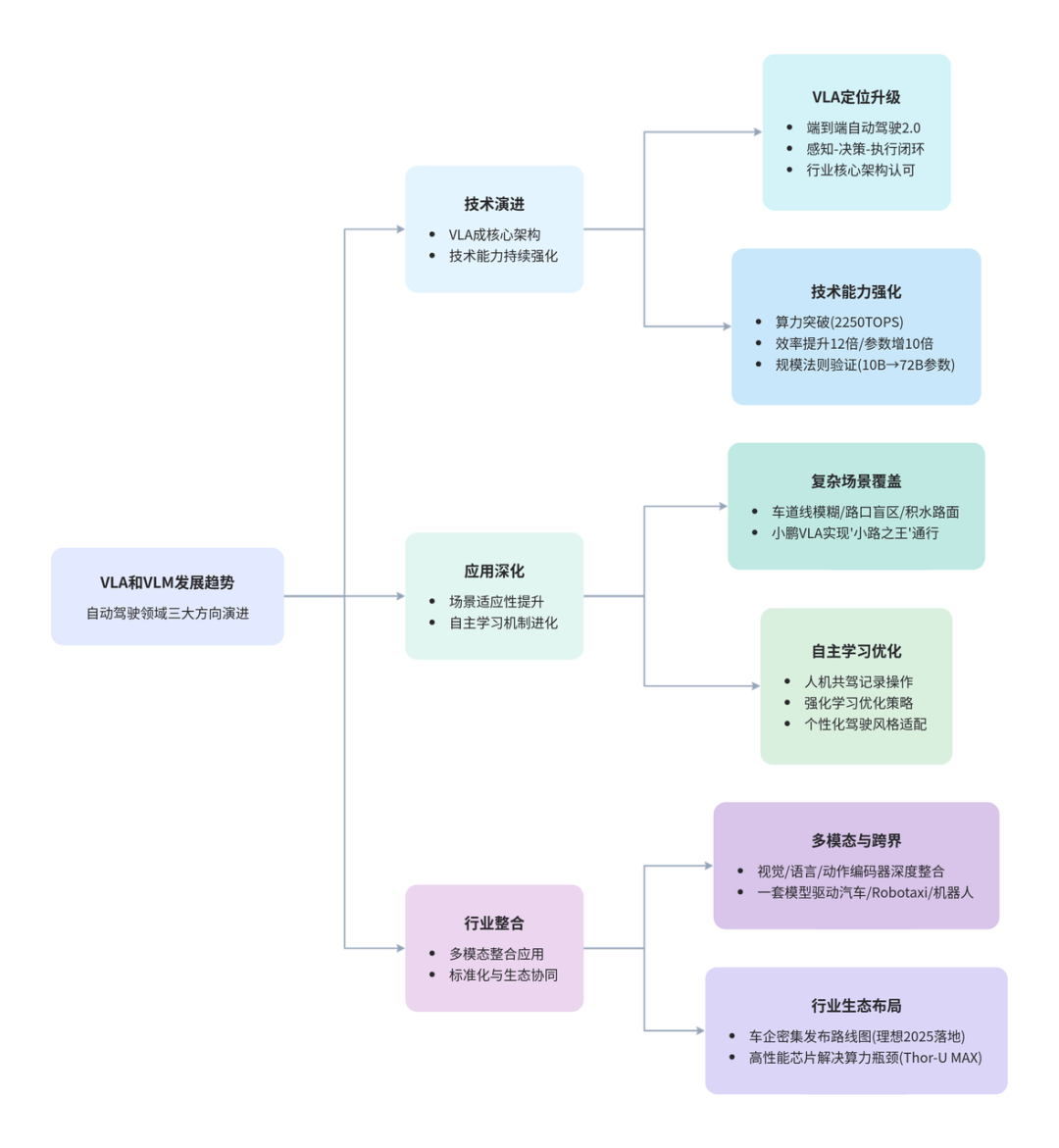
作为端到端自动驾驶的“2.0版本”,VLA正从幕后走向台前,成为重塑行业格局的核心力量。

一、从“辅助分析”到“直接控车”:VLA的定位升级
过去,VLM主要扮演“场景分析师”的角色,负责提供文本描述和环境理解。而VLA的出现实现了质的飞跃:
- 感知-决策-执行闭环:VLA深度融合了视觉输入、语言理解和动作输出,能够直接生成驾驶控制指令。
- 核心演进方向:业内普遍认为,VLA是通往L4级别自动驾驶的关键跳板,也是“端到端+VLM”架构的终局形态。
二、暴力美学:算力与规模的全面进化
为了支撑复杂的实时决策,VLA和VLM在硬件与模型参数上正在疯狂“堆料”:
- 巅峰算力:小鹏第二代VLA搭载了具备2250 TOPS有效算力的图灵AI芯片,为环境处理提供了强大的底座。
- 性能飞跃:模型推理效率提升了12倍,参数规模从10B扩展至72B,验证了性能随数据增长的“规模法则”。
- 毫秒级响应:这种进化带来的直接结果就是更高精度的场景理解和近乎零延迟的实时反馈。
三、攻克“长尾场景”:它比你更懂复杂路况
自动驾驶最难的不是跑高速,而是处理那些奇葩的“长尾场景”。
- 高难度场景覆盖:在车道线模糊、路口盲区、积水路面等复杂环境下,VLA表现优异。例如,小鹏VLA已能实现“小路之王”般的顺畅通行。
- 越开越聪明的AI:通过强化学习,模型能够记录并学习用户的操作,逐步实现个性化驾驶风格的适配,真正实现人机共驾的进化。
四、行业大整合:一套模型,驱动万物

VLA的影响力正在溢出汽车领域,向更广阔的机器人生态延伸:
- 一体化架构:通过深度整合视觉/语言编码器与动作解码器,实现多模态输入的高效处理。
- 跨界落地:小鹏提出的“一套模型、多维落地”战略,让同一套VLA模型能同时驱动AI汽车、Robotaxi及机器人。
- 巨头博弈:理想、英伟达等企业正密集布局。理想计划在2026年落地基于英伟达Thor芯片的封闭式VLA模型,其目前的VLM应用已将复杂场景接管里程提升了2.5倍。
最后
从文字理解到控制指令,从实验室走向全场景覆盖,VLA与VLM的深度融合标志着自动驾驶已经进入了高阶智能的决胜期。
当算力不再是瓶颈,当模型学会了自主进化,我们距离“真正解放双手”的那一天,或许比想象中更近。
本文由 @OpenAIer 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


