
 起点课堂会员权益
起点课堂会员权益数据分析实战|人人都是产品经理网站(中篇):读者视角
本篇作者将以读者视角来分析这些数据,从4万多篇文章中,找出对于读者最有帮助最有价值的文章。enjoy~
一. 前篇回顾
前篇《数据分析实战|人人都是产品经理网站(上篇):平台视角》中,详细地介绍了从人人都是产品经理官网(以下简称人人)返回的首页数据中,以平台运营者的角度来分析:网站目前的内容是否可以支持网站的正常运营。
到本篇则会换一个视角,以读者视角来分析这些数据,从4万多篇文章中,找出对于读者最有帮助最有价值的文章。当然一千读者有一千个哈姆雷特,每个人对文章的价值都有着自己的判断,而本文只是从数据统计的角度来分析那些对大多数读者能够有帮助的文章。解决的问题如下:
Q1. 阅读量、收藏量、点赞量和评论量分别的Top10是哪些文章
Q2. 有哪些文章值得收藏?
Q3. 有哪些作者值得关注?
二. 各种Top 10
在Youtube的各种节目中,各种盘点Top 10节目很受观众欢迎。所以这里也按俗套剧情先偷个懒,直接把上一期整理好的数据排排坐,分别按照阅读量、收藏量、点赞量和评论量来进行排个序,看看各种Top的文章是哪些。还没有学习的同学也可以对本篇点击一波收藏,之后可以导航深入学习。
1. 阅读量
(1)99.2万阅读量
- 《小白产品经理看产品:什么是互联网产品》
- 发表:2016-01-29
- 作者:华章图书
- 分类:产品经理
(2)70.9万阅读量
- 《推荐几个H5页面制作工具,自己选一下吧》
- 发表:2015-12-22
- 作者:刘子丰
- 分类:产品运营
(3)60.1万阅读量
- 《如何绘制业务流程图》
- 发表:2012-06-27
- 作者:Heidixie
- 分类:产品设计
(4)56.8万阅读量
- 《产品需求文档(PRD)模板下载(附完整案例)》
- 发表:2012-06-21
- 作者:老曹
- 分类:干货下载
(5)53.1万阅读量
- 《Axure教程 axure新手入门基础(2)》
- 发表:2013-08-19
- 作者:小楼
- 分类:原型设计
(6)52.5万阅读量
- 发表:2012-08-06
- 作者:老曹
- 分类:业界动态
(7)52.1万阅读量
- 《产品需求文档的写作(四) – 撰写文档(PRD文档)》
- 发表:2014-04-18
- 作者:唐杰
- 分类:产品设计
(8)52.0万阅读量
- 《[干货]如何构建用户画像》
- 发表:2014-09-23
- 作者:小核桃
- 分类:产品经理
(9)51.5万阅读量
- 《【干货下载】Axure 元件库- 常用元素1056枚下载》
- 发表:2014-10-13
- 作者:人人都是产品经理
- 分类:产品设计
(10)51.0万阅读量
- 《【干货】H5页面制作免费工具大集合》
- 发表:2015-05-26
- 作者:木木老贼
- 分类:产品设计
2. 收藏量
(1)4274收藏量
- 《Word产品需求文档,已经过时了》
- 发表:2015-09-29
- 作者:臻龙
- 分类:原型设计
(2)2407收藏量
- 《在面试时候,如何简明扼要简述产品流程(附思维导图下载)》
- 发表:2016-04-06
- 作者:粤Fun享越快樂
- 分类:产品设计
(3)2407收藏量
- 《如何去做一份竞品分析报告》
- 发表:2016-02-18
- 作者:梁嘉琪JackieLiang
- 分类:分析评测
(4)2298收藏量
- 《你会写报告?产品体验报告的思路应该是这样的!》
- 发表:2016-01-14
- 作者:休言万事转头空
- 分类:分析评测
(5)2237收藏量
- 《产品经理面试习题大汇总》
- 发表:2016-11-25
- 作者:留言
- 分类:职场攻略
(6)2120收藏量
- 《绝密原型档案:看看专业产品经理的原型是什麽样》
- 发表:2015-04-20
- 作者:GaraC
- 分类:原型设计
(7)1932收藏量
- 《三个步骤教你如何做好后台产品设计》
- 发表:2015-11-16
- 作者:方东东
- 分类:产品经理
(8)1832收藏量
- 《如何优雅的用Axure装逼?高保真原型心得分享》
- 发表:2016-02-14
- 作者:ygg
- 分类:原型设计
(9)1779收藏量
- 《干货流出|腾讯内部几近满分的项目管理课程PPT》
- 发表:2015-12-26
- 作者:傅老师
- 分类:产品经理
(10)1774收藏量
- 《全面解读流程图|附共享单车摩拜ofo案例分析》
- 发表:2017-10-18
- 作者:臻龙
- 分类:产品设计
3. 点赞量
(1)2181次点赞
- 《Word产品需求文档,已经过时了》
- 发表:2015-09-29
- 作者:臻龙
- 分类:原型设计
(2)1886次点赞
- 《绝密原型档案:看看专业产品经理的原型是什麽样》
- 发表:2015-04-20
- 作者:GaraC
- 分类:原型设计
(3)1730次点赞
- 《产品需求文档(PRD)模板下载(附完整案例)》
- 发表:2012-06-21
- 作者:老曹
- 分类:干货下载
(4)1556次点赞
- 《Axure 7.0 汉化版下载》
- 发表:2013-07-07
- 作者:Nairo
- 分类:干货下载
(5)1406次点赞
- 《交互设计初体验(iUED)》
- 发表:2014-11-24
- 作者:朱帝
- 分类:交互体验
(6)1330次点赞
- 《axure 7.0正式版发布(附下载地址和汉化包)》
- 发表:2013-12-19
- 作者:欧阳俊杰
- 分类:干货下载
(7)1328次点赞
- 《放大你的格局,你的人生将不可思议》
- 发表:2014-11-18
- 作者:大城小蛙
- 分类:产品经理
(8)1111次点赞
- 《Axure 8.0中文版下载(支持windows和Mac)》
- 发表:2015-08-14
- 作者:欧阳俊杰
- 分类:干货下载
(9)1026次点赞
- 《#woshiPM训练营#深圳站总结入口页:对怀孕妈妈的关怀》
- 发表:2014-07-02
- 作者:游某
- 分类:人人专栏
(10)1002次点赞
- 《支付风控系统设计:支付风控场景分析(一)》
- 发表:2016-12-12
- 作者:凤凰牌老熊
- 分类:产品设计
4. 评论量
(1)1014次评论
- 《Word产品需求文档,已经过时了》
- 发表:2015-09-29
- 作者:臻龙
- 分类:原型设计
(2)848次评论
- 《绝密原型档案:看看专业产品经理的原型是什麽样》
- 发表:2015-04-20
- 作者:GaraC
- 分类:原型设计
(3)723次评论
- 《一套出自设计师之手的Axure组件库,让你的原型不再LOW》
- 发表:2016-05-30
- 作者:原型不low
- 分类:干货下载
(4)456次评论
- 《我的从0到1产品路》
- 发表:2016-12-08
- 作者:luyao93
- 分类:产品经理
(5)373次评论
- 《万字干货|产品经理知识体系之需求管理(二)》
- 发表:2017-01-09
- 作者:记小忆
- 分类:产品经理
(6)319次评论
- 《豆瓣APP产品体验报告》
- 发表:2015-11-30
- 作者:天天向辉
- 分类:分析评测
(7)307次评论
- 《分享PRD:「我是红人」产品需求文档》
- 发表:2017-01-13
- 作者:Bass小南
- 分类:分析评测
(8)236次评论
- 《系列文章|产品经理知识体系之idea管理(一)》
- 发表:2017-01-04
- 作者:记小忆
- 分类:产品经理
(9)234次评论
- 《Axure 8.0中文版下载(支持windows和Mac)》
- 发表:2015-08-14
- 作者:欧阳俊杰
- 分类:干货下载
(10)233次评论
- 《从需求与业务流程来聊一聊,产品经理刚接手TO B产品时该怎么做?》
- 发表:2017-02-27
- 作者:记小忆
- 分类:产品经理
三. 筛选优质文章
对我来说,一年收藏个几百篇文章到我的材料库中是非常正常的,之前的这点Top 10根本不够看,但如果拉长相应的名单又会有很多投机取巧的文章混在其中。人人经过这么多年的发展,已经沉淀了不少佳作。所以,作为一个有点贪婪的人,如何把这些优质内容一网打尽,是我接下来想要考虑的事情。
1. 四个属性分布
还是之前的数据,我们先再次看一下所有文章属性中,有价值的数据总览:
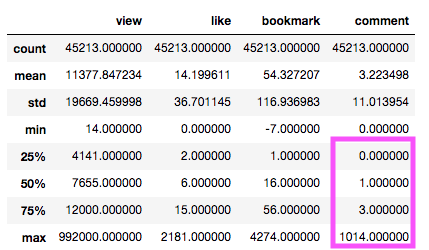
评论这一项相比于其它属性来说,因为值分布得比较极端,比较适合按类型进行区分,大于25%的文章评论数量为0,大于25%的文章数量评论数大于3,评论数1~2的小于50%。依次可以将其由数值型属性转化为分类类型。因为代码上的处理,这里由低到高的命名为Low,Mid,High。这样我们可以将原本需要XYZ三个轴再加上空间上点大小的三维散点图转化为二维。
根据上面的View(浏览量),like(点赞),bookmark(收藏数),comment(点评数)分别做为散点图的点取值,x轴,y轴,及点的类型,绘制如下:
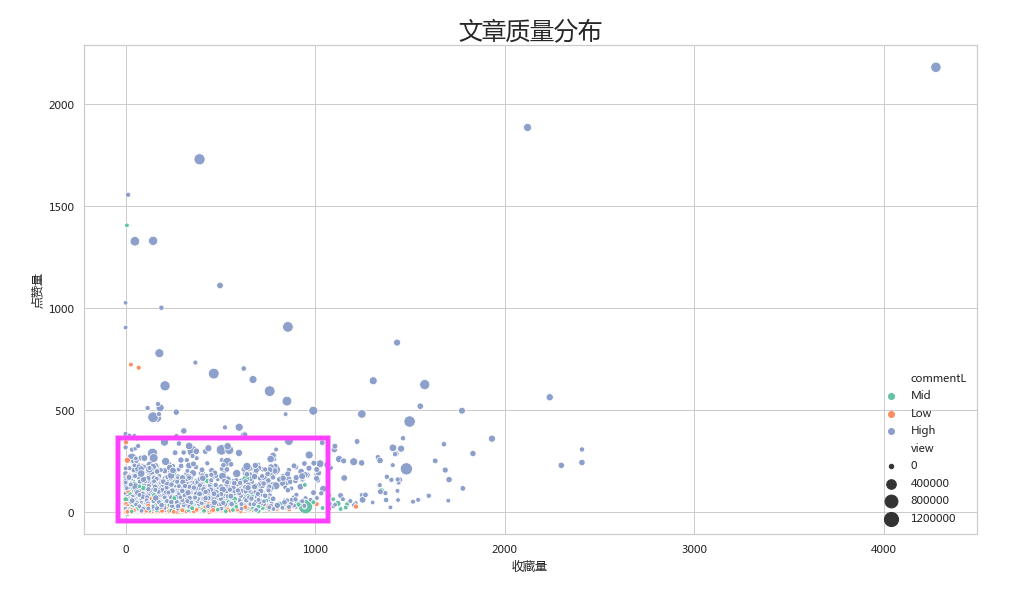
2. 属性分析
(1)从上图中,凭肉眼观察就能发现约95%以上的文章都集中在左下角的紫色方块区域内;
(2)虽然紫色方块区域都是以High为主的蓝色居多,但这是将4万篇文章堆叠在一起的结果,展示上效果有些问题,但从整体比例来说High,Mid,Low也都应该主要集中在这块区域;
(3)实际对四个属性的相关性求解也是两两之间基本都在0.5以下。虽然是正相关,但属于比较弱的相关,所以并不能以某一个属性做为单一的换算比例来“消元”;
(4)四万多条数据挤在紫色小方块里,可以在一定程度上将他们在此区间看成是均匀分布的;可以暂时不考虑四个属性之间的加权问题。
3. 评分计算公式
所以综上所叙,大致的计算流程如下:
(1)为了四个属性的值能够相加起来比较方便,所有值都需要按照[0,1]之间进行等比换算,让他们能够保持在一个维度;
(2)为了避免某些文章的属性因为值过大产生干扰,需要进行一定的修饰。当文章属性中的值已经大于其它95%的文章时,则只取1。排除掉此部分的值之后,再根据第1条进行换算;
(3)经过上述处理之后,四个值相加则为此篇文章的打分,取值范围一定是[0~4]。
4. 结果一览
经过上面如此一番折腾,还能够打4分的文章还有438篇之多。但对比于全站45000+篇文章来说,1%左右的筛选结果还是可以让我满意的。
因为筛选结果有400多篇,所以下面是按时间节选截图。大家也可以一起来验证一下我的筛选成果,是不是一些精华中的精华。
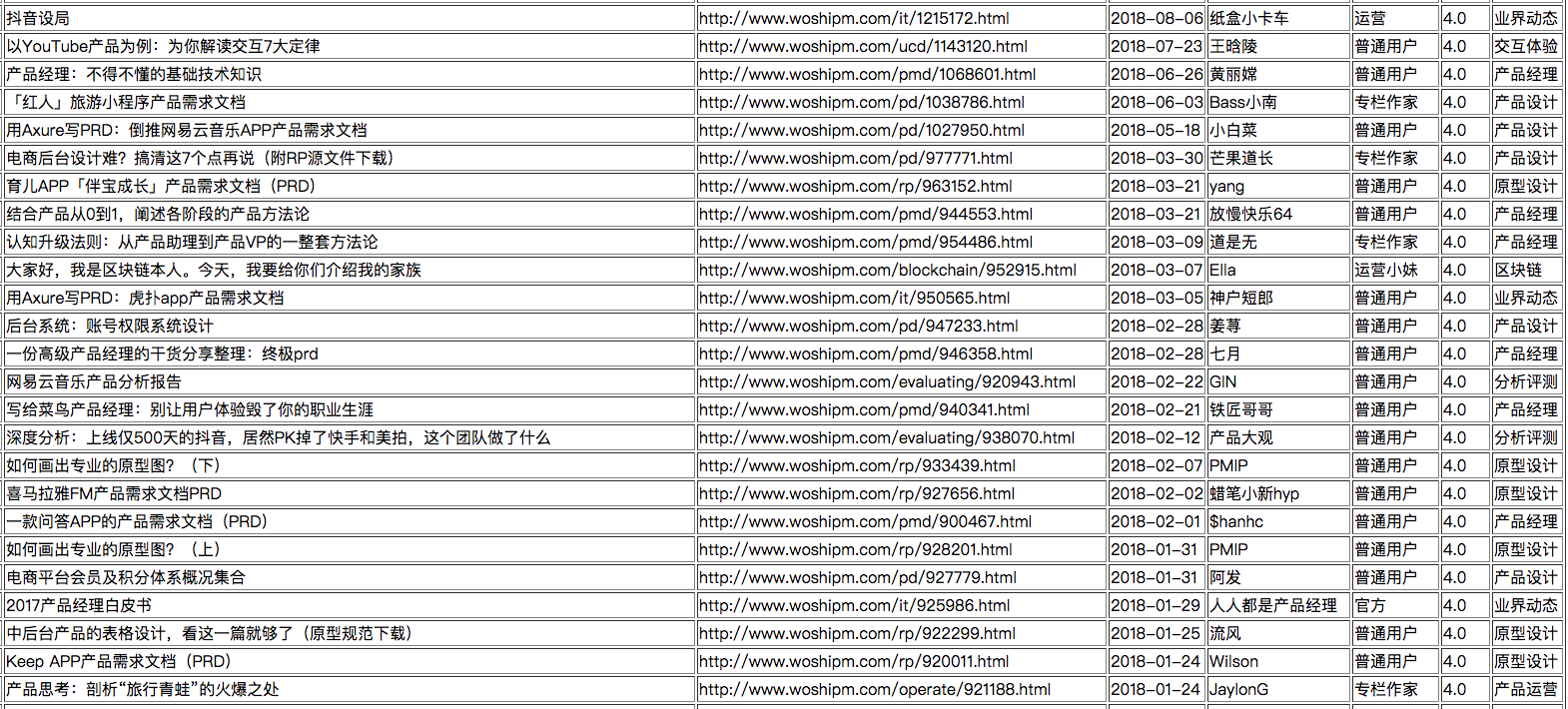
(右击,在新标签页中打开即可查看大图)
四. 哪些作者值得关注?
相信大家也能看到在人人的官网和手机APP中是有作者推荐的。但这个推荐的模型和依据并没有告诉读者他们是如何筛选出来的。所以在这里我们利用手上现有的资源做完这点分析,来看看人人上有哪些优秀的作者。
首先,他应该有一定的产量,因为如果作品数量太少,可能会导致较大偏差值,而产生较高的个人分数。所以先排除掉投稿数量低于5篇的作者;
其次,自然就是文章的质量了,结合前文的打分,取当前作者所有作品的平均值即可。下表中为了展示各作者的区别,把分项目的打分也显示出来。
如此,这些作者就已经有了极大的区分度,而且根据各自的分数,其实在一定稳定上是可以分辨得出此作者的投稿偏好和类型的。如果还没有关注他们,就赶紧关注一波吧~
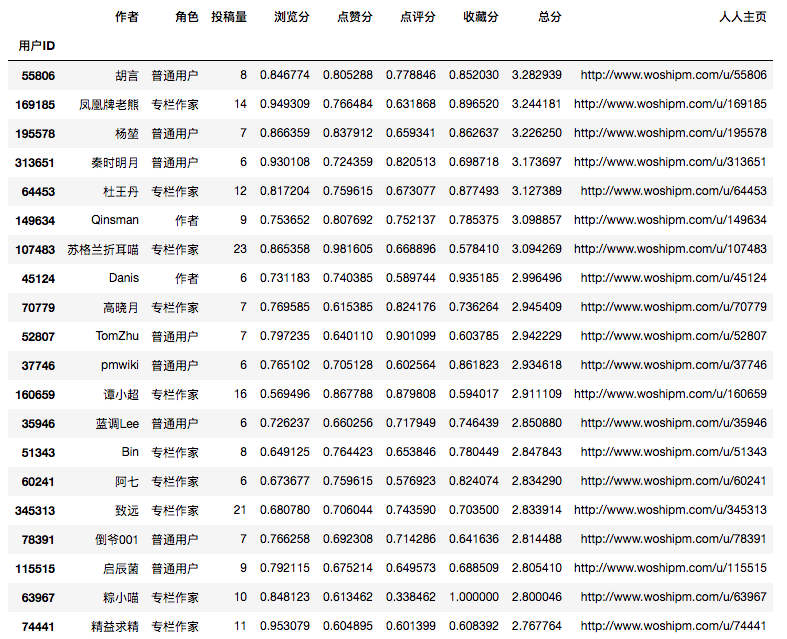
补充一点在于,作者的水平描述在人人的体系下,还有打赏、订阅量和关注量这些纬度可以让这个打分模型更具有说服力。但限于篇幅觉得已经够说明问题就不再追加数据了。
下期预告
以上便是本篇读者视角的数据分析的全部内容,希望大家喜欢。有建议和想法的同学可以在下面的评论区留言讨论。
下一期就是本次分析的最终篇,作为作者,取一个什么样的标题会火!将会从数据分析到数据挖掘建立相应的模型,可以进行预测。
相关阅读
本文由 @ 核桃壳 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Pixabay,基于 CC0 协议









本系列的相关代码可以在http://walnut-shell.com/ipython-notebook/ 中找到
期待最终篇!
很赞的数据分析文章,个人提一点小建议:1 阅读量是否可以考虑时效性因素,也就是一篇文章在多长时间内达到多少的阅读量/收藏量/点赞量;2 指标体系中的指标有权重差异;3 评价特征除了发文量 阅读量 收藏量 点赞量之外,还得考虑他们的稳定性(方差),如某位作者保持稳定的频率在一段时间内的发文频率等
上文中输出的所有精文章:
http://walnut-shell.com/2018/09/19/%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%9C%20%E4%BA%BA%E4%BA%BA%E9%83%BD%E6%98%AF%E4%BA%A7%E5%93%81%E7%BB%8F%E7%90%86/
不明觉厉,专门注册给你点赞
感谢支持,请期待第三篇 😉
写的很赞,阅读量Top10的有点出入,是不是做阅读量还原的时候单位M的忽略了,现在最高的应该是《绝密原型档案:看看专业产品经理的原型是什麽样》http://www.woshipm.com/rp/149653.html,2.5m的量,一共应该有3篇过百万的。再次拜读 😉
检测了下代码确实m单位的处理当成10万了,感谢~ 😎