
 起点课堂会员权益
起点课堂会员权益租赁大数据看板建设过程中数据清洗及程度思考
 产品经理软技能是指如逻辑分析、文字表达、语言表达、学习能力、总结能力、创新力、好奇心、情绪态度和团队合作等。
产品经理软技能是指如逻辑分析、文字表达、语言表达、学习能力、总结能力、创新力、好奇心、情绪态度和团队合作等。编辑导读:数据清洗是指发现并纠正数据文件中可识别的错误的最后一道程序,包括检查数据一致性,处理无效值和缺失值等。本文作者从自身工作经历出发,以租赁大数据看板建设过程中的数据清洗为例,进行分析,与你分享。

最近在接触学习BI(Business Intelligence,商业智能)相关的内容,抽取了部分租赁的业务数据导入BI软件进行分析,由于数据的年份跨度较大,且都来源于线下录入,早期字段约束较少、业务审核相关机制不健全,导致部分字段统计经常报错,或者与理想情况差距过大。遇到这种情况时就要引进“数据清洗”流程,将不对劲的数据进行排除。

数据清洗是指发现并纠正数据文件中可识别的错误的最后一道程序,包括检查数据一致性,处理无效值和缺失值等。与问卷审核不同,录入后的数据清理一般是由计算机而不是人工完成。
——某度词条
但是数据清洗过程中,如果仅仅是做一些常规判断,例如租赁订单中的用户支付金额,理应大于0元,房子的面积不能为0平方米等等,经过简单处理之后,能解决很多异常问题,但还是会有数据异常的情况,例如只约束了订单金额不能为0元,万万没想到确有负数金额的订单以及金额为空的订单,最终导致计算出来的平均数据、各区域业绩数据排行等产生异常。以下将以数据清洗的普遍流程来讨论清洗“程度”如何衡量。
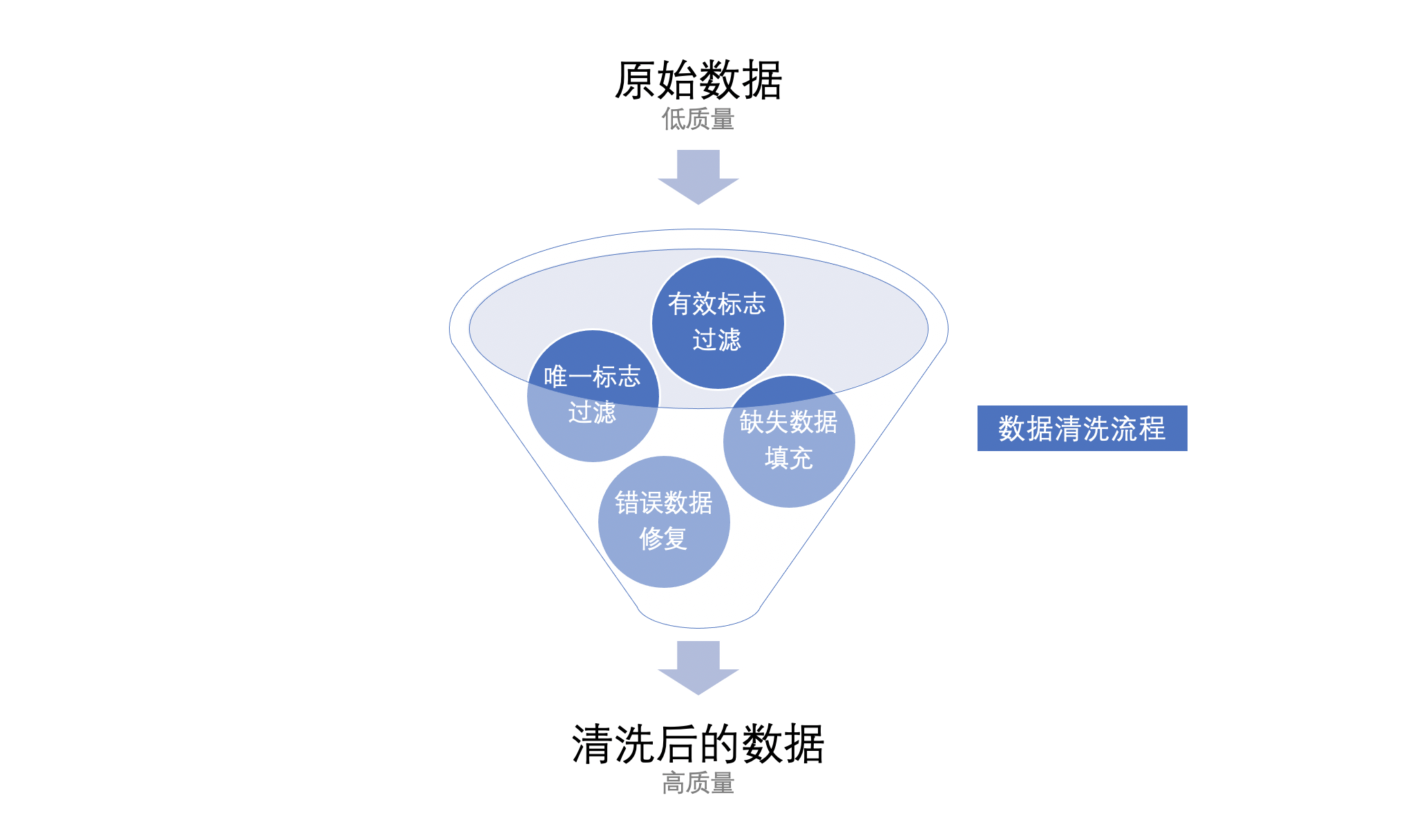
一、数据有效标志
有效标志是指一条数据为有效数据的关键标志,一般即为该数据的状态字段,如支付订单的支付状态、用户信息的注册状态、商品信息的是否删除等,对字段对数据是否可采纳起着决定性作用。
有条件的话最好对原始数据做一次统计(SQL里的group by、Excel里的筛选功能等),看看一共存在几种状态,不同状态的数据量有多少。然后对照业务流程,对数据有效标志进行筛选,可以有效减少不必要的数据及其中潜在的问题,提高后续数据分析的速度和结果质量。
如果被过滤掉的异常状态的数据量超过订单的1%,则要与负责技术开发或者数据分析的同事一起,研究数据源记录的时候是不是就有问题,甚至是存在不知道的需求或潜在bug等。
例如我们的租赁订单,有多种租赁状态:
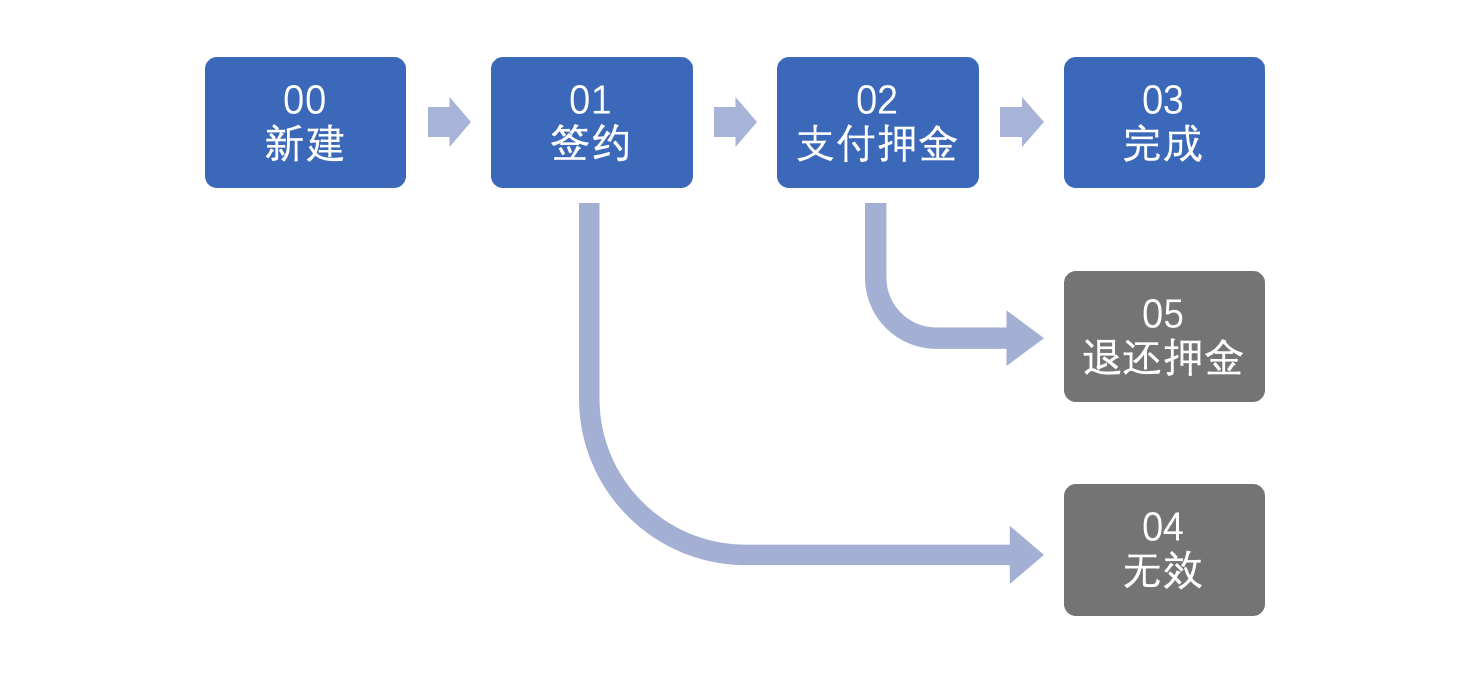
如果要分析过往已完成的租赁交易情况,那就只需要筛选其中状态码为03或状态值为“完成”的数据,其他状态的数据一概不需要理。
但如果要分析过往所有发生过的交易情况,则需要筛选状态码为00-05状态的订单,其他状态为Null、空值、-1、或其他无法理解,及N年没用遗留的业务已经废弃不再使用的值的数据,可以考虑全部过滤掉不需要。
不同分析场景下,对于数据的需求是不一样的,不要一味的最求数据的数量,如果想着就算暂时用不上也先放着,这样很可能会加重后期数据分析中筛选的工作量,占用电脑资源卡顿、甚至死机白搞了等等。
其他:生产环境上或多或少的存在用于测试的“生产验证”数据,其中可能包含一些极端场景数值,但是此类数据未实际发生过,所以一般要在数据清洗过程中去掉。
二、数据唯一性标志
就像订单要有订单号,用户要有uuid,商品有skuid一样,系统中的数据一般都需要有唯一的ID用于进行数据的检索和区分。
但是由于bug或者子订单逻辑、不同的状态的影响,可能会出现唯一性标志重复情况,此时可能会对数据分析造成一定的影响。
例如某系统中支持用户自定义域名复用的逻辑,如果一个用户注销了账号,那么其他人就可以使用此域名,如果要分析系统一共有多少个子域名时,如果单纯统计子域名记录的数量,就会有问题,此时应该先进行子域名去重,再统计数量才对。订单位数设计较短、没有设置随机值时,也很可能出现订单号重复的问题,还有员工工号重复等问题。
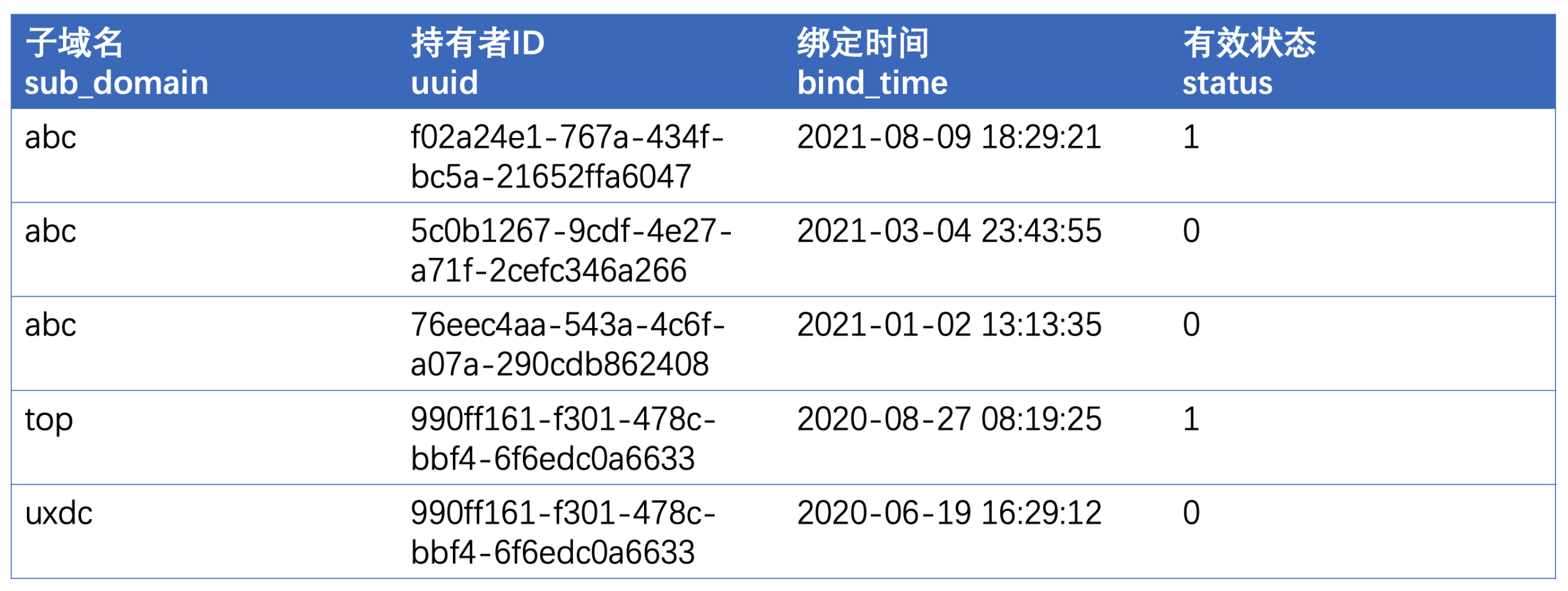
但既然是“唯一”的标志,那就应该挑出重复项,并按业务需求看是否需要修复原始数据,或决定重复项的取舍方案:
- 只保存最新产生的一条
- 最保存最早产生的一条
- 保存其他字段完善度更高的一条等等
另外由于bug、生产环境测试、或其他不知名的问题,还可能造成订单ID为Null、空值、-1,或不规范的订单号,这些一般都伴随有其他字段数据的残缺不全等问题。
我所分析的租赁订单中,存在有订单ID为空的记录,但是极为少数,考虑到这些数据年代久远已经不可考证了,所以直接筛选保留订单ID不为空的即可。
三、字段缺失
字段缺失是数据清洗中最常见的问题之一,造成此问题的原因也多种多样,甚至可能是导出数据时分隔符设置的不对,导致把数据csv、xls等导入分析系统或Excel后造成的错误分隔导致的。
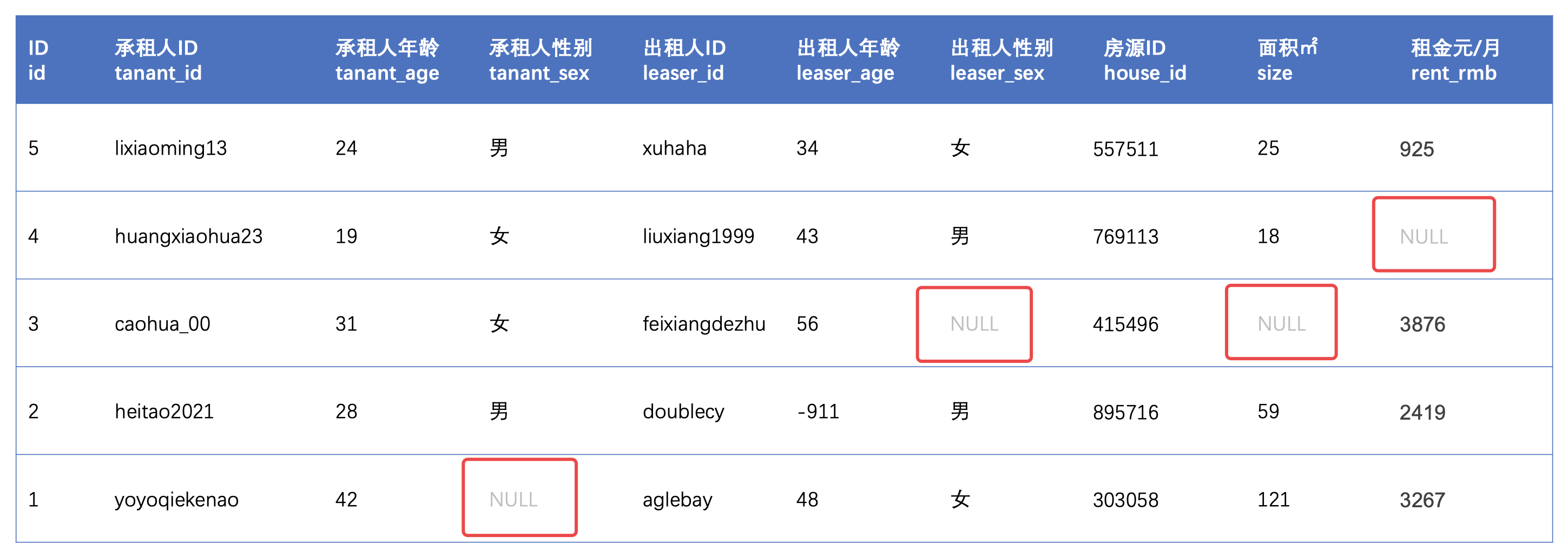
1. 检查缺失字段的比例
如果某个字段数据缺失严重,则要考虑是否存在程序bug,或者导入导出的流程是否有问题。
2. 对缺失字段的数据进行处理
删除数据:
一旦发现数据中存在一个或多个关键数据缺失的,就把这条数据删了不采用。这种一刀流的做法比较适合数据字段比较少,且缺的都是关键数据的场景,例如订单中金额为空,用户的账号为空等情况。
部分采纳:
该字段只用在部分分析结果中时,例如做租赁租金的行政区县分布时,一条数据包含了租金、房子所在的行政区,但是承租人的性别为空,此时字段缺失并不影响分析结果,此场景可以考虑保留此数据。
但是要做不同性别的人租房租金偏好分析时,此数性别为空,则应不予采纳。
数据填充:
例如公司要做宣传物料,其中有要求租赁市场成交面积统计,但是系统中成交的租赁记录里,有超过5%记录房屋面积都为空没登记(与早期为非必填有关),此时就需要进行数据填充。数据填充有几种方法论可以参考:
- 根据有数据的记录平均值填充。优点:简单粗暴快速;缺点:可靠性不高
- 建立对应的数据模型,预测缺失字段的数值并填充。例如根据没问题的数据计算对应缺失了面积的记录所在区域,类似户型、租金水平的房屋面积,然后填充到缺失字段中。优点:精准度高,有据可依;缺点:难度大速度慢效率低
- 进阶版:通过平均值/模型数据的方法,增加测算误差值,然后随机生成平均值±误差值中间的数据进行缺失字段填充。
- 人工经验填充。此方案只针对少量数据或缺失数据特别重要时,可以根据业务人员经验填充,数据量大时不合适。
无论是根据平均值、模型数据、人工经验进行缺失字段填充,讲究的都是有据可依,不是瞎填充数据。如果缺失的字段随机性或不确定性比较高,不适合常规的数据填充的话,如果没有更好的方法论可以采用,建议删除/不采纳此条数据。
不同的业务场景和分析需求,对于缺失数据的处理是不一样的:
追求更漂亮的数据和业绩:
理应最大化的保留数据,通过合理的方法进行数据补全。
业务发展:
可以采用部分采纳或者删除字段缺失数据的方式,最好同时配合每个字段的缺失率情况,对于业务价值高的数据,数据本身的完善程度和数据分析结果一样重要,需要从源头上解决此问题。
只是看看:
如果只是想客观看看市场行情,或者该字段并不是太重要的数据,只是走势有参考作用,则可以考虑删除对应的数据,以免造成困扰,避免空值导致计算结果偏差或报错。
四、错误数据
错误数据也是一个常见的问题,除了bug导致的错误数据外,主要出自非系统统计的,人工填写的数据上,由于缺乏有效的限制手段、审核手段,导致个别数据可能出现异常离谱的问题,从而影响到看板数据的正常统计。
例如租赁记录中,就有出租面积为20000万平方米,租金才500块的记录存在,在全局而言由于正确数据足够多,这笔订单影响微乎其微,但是如果只看这一个楼盘、商圈,那就对当地的平均租金、户型平均面积等统计都会造成重大影响,然后做排行榜的时候,这个楼盘、商圈就会突出重围排名特别靠前。
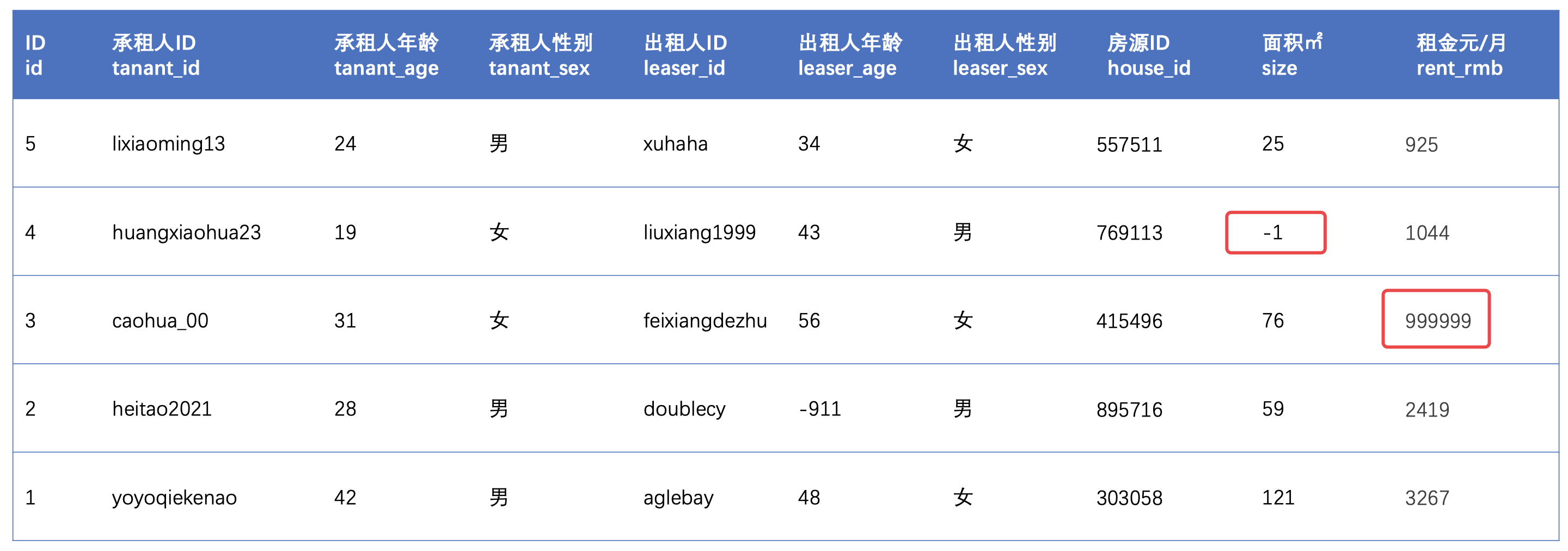
数据错误的前提是,首先知道什么是正确的,错误是相对于正确的定义而言的:
1. 符合格式规范的数据
例子:要求填写阿拉伯数字
正确:123456
错误:拾贰万叁仟肆佰伍拾陆、123,456
2. 符合大家共识的合理范围
例子:房屋租金,单位为元/月
正确:2000
错误:-911、999999999
3. 看似不合理,但是可以通过其他内容佐证的数据
一个城市平均租赁的房屋的面积都是几十平方米,但是突然有条租赁记录是2000平方米,不过价格为10万元/月,业主、承租人、位置等信息都完整,我们觉得就有可能是正确的,大概率是租了个厂房一栋楼。但是几百平米以上的房子只要几百块甚至不要钱,很明显就不合理了。
4. 可以溯源,事实如此的数据
分析师就是这笔订单的当事人,合同、现场照片甚至视频监控一应俱全……
对于错误数据,若无法有其他有效证据佐证的数据,就要结合分析场景进行处理,以免干扰分析结果。
1)根据错误类型进行划分
- 格式类错误:例如数字写成了中文字,数字中有小写逗号,年月日yyyy.mm.dd写成yyyy年m月d日,或者其他不按规范填写的内容,当有大量的数据为同样类型的错误时,可以考虑通过编写代码/脚本或者导出使用Excel等工具搜索替换,从而进行批量修正。
- 范围类错误:应结合其他字段数据,参考缺失字段的填充方式进行数据重设。
2)根据字段意义进行划分
- 核心字段:即做业绩报表用的,那就得溯源、考证、根据实际情况进行修正,无法修正时,结合其他字段进行数据重设,重设为一个合理范围内的数值。
- 非核心字段:先统计一下错误数据的比例,如果比例不高,如低于1%,可以考虑直接删除或不采纳对应数据,影响小效率高。如果数据占比高,再根据错误类型决定具体修正方案。
五、清洗结果分析
通过对数据进行清洗后,需要统计清洗前后的数据,看清洗是否达到了目的。
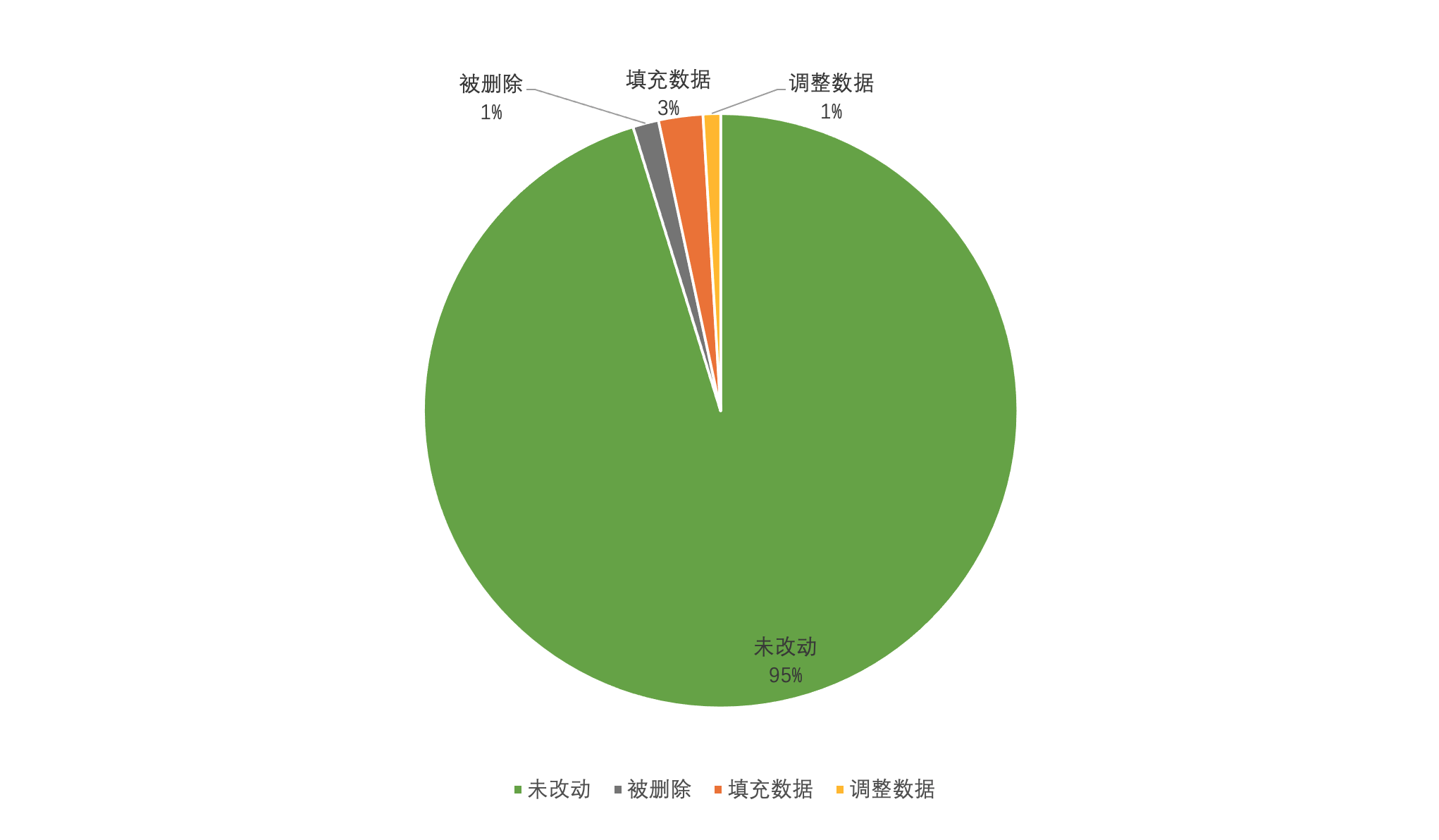
1)数据损失评估
例如清洗前有关联的原始数据有10万,清洗后数据剩下了9.5万条,损失了5%的数据,如果数据分析的目的是做市场分析而不是财务报表,那么这个损失程度我们会认为在可接受范围内。
如果清洗完发现剩下不到5万条数据,就需要去思考这个清洗是否有效,是否导致重要数据被漏掉了。
2)数据失真评估
对于结果要求可靠性高的分析,如财务报表,需要对填充、调整的数据量进行评估,填充的数据加上因为非格式问题导致的数据调整,一般不能超过数据总量的5%,且最终数据的平均值,应该与清洗前完全没问题的数据平均值基本一致,相差±1%,这样填充/调整操作才可信度高。具体比例因人而异,但是填充、调整过的数据量太多,可信度会大幅下降。
数据可信度越高,代表数据失真度越低,失真度越低的数据用于业务发展规划、分析时,得出的结论可靠程度才更高。
六、总结
通过对数据清洗过程的分析,其实如何进行数据清洗,这其中的“度”量,与分析目的和场景息息相关,同一份数据,不同的分析场景,可能需要不同的清洗方案,从而现成不同的数据集合。
由于清洗方式不一样,得出的数据结论也会有小微的偏差,但是总体方向应该是一致的。
#专栏作家#
iCheer,公众号:云主子,人人都是产品经理专栏作家。房地产/物业行业产品经理,Python编程爱好者,养猫发烧友。
本文原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议

















别吹啦,一直在三流公司进进出出
你这些年干成啥了啊?除了吹牛有一件事拿的出手吗?不要脸
辛苦了