
 起点课堂会员权益
起点课堂会员权益想入门AI,机器学习你知多少了?
有意转行AI行业的PM们,需要对机器学习了解多深?机器学习跟无监督学习、半监督学习、神经网络、深度学习、强化学习、迁移学习等是什么关系?各自之间又有什么区别和关系?本文作为一篇扫盲篇将给你一一梳理。

01 机器学习(Machine Learning)
1. 什么是机器学习
机器学习与人工智能的关系:机器学习是实现人工智能的一种工具;而监督学习、无监督学习、深度学习等只是实现机器学习的一种方法。
机器学习与各种学习方法之间的关系:
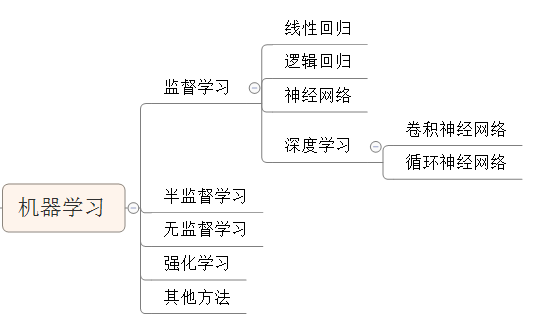
注:这里把神经网络和深度学习归到监督学习下面可能不是很恰当,因为维度不一样,只能说有些监督学习的过程中用到神经网络的方法。
而在半监督学习或无监督学习的过程中也可能会用到神经网络,这里只在监督学习的模式下介绍神经网络。
机器学习就是让机器自己有学习能力,能模拟人的思维方式去解决问题。
机器学习目的不只是让机器去做某件事,而是让机器学会学习。就像教一个小孩,我们不能教他所有的事,我们只是启蒙他,他学会用我们教他的东西去创造更多的东西。
人解决问题的思维方式:

遇到问题的时候,人会根据过往的经历、经验、知识,来做决定。
机器模拟人的思维方式:
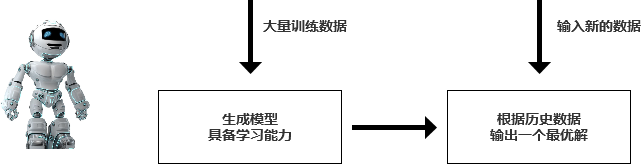
先用大量的数据训练机器,让机器有一定的经验,再次输入新的问题时,机器可以根据以往的数据,输出一个最优解。
所以,机器学习就是让机器具备学习能力,像人一样去思考和解决问题。
2. 怎么实现机器学习
实现机器学习的三个步骤:

举个例子:我们现在要做一个预测房价的模型,假设影响房价的因素只有住房面积:
第一步:定义模型
假设:y=房价,x=住房面积
则定义模型:y=a*x+b
其中x为特征变量,a、b为参数。因此我们的目的就是利用训练数据(Training Data),去确定参数a、b的值。
第二步:定义怎样才是最好的(定义代价函数)
在第一步定义好模型之后,接下来我们要告诉机器,满足什么样条件的a和b才是最好的模型,即定义代价函数。
假设测试的数据(x1、y1)、(x2、y2)、(x3、y3)…;
假设测试数据到直线的距离之和为J;
则J²=1/M∑(x-xi)²+(y-yi)²之和,其中xi、yi表示每点的测试数据,M表示测试数据的个数。
因此我们定义最好的就是:使得J的值最小时,就是最好的。
第三步:找出最好的模型
根据第二步,我们知道什么是最好的了,接下来就是想办法求解出最好的解。
常用的就是梯度下降法,求最小值。剩下的就是输入数据去训练了,训练数据的量和数据源的不同,就会导致最终的参数a、b不一样。
这三步中基本上就是转化为数学问题,后面会单独写一篇文章说明如何将一个AI模型转化为数学的求解问题,其中主要涉及的一些专称有:预测函数、代价函数、误差、梯度下降、收敛、正则化、反向传播等等,感兴趣的同学可以关注下。
02 监督学习(Supervised Learning)
监督学习是从已标记的训练数据来推断一个功能的机器学习任务,主要特点就是训练数据是有标签的。
比如说图像识别:当输入一张猫的图片时,你告诉机器这是猫;当输入一张狗的图片时,你告诉机器这是狗;如此训练。

测试时,当你输入一张机器以前没见过的照片,机器能辨认出这张图片是猫还是狗。

监督学习的训练数据是有标签的,即输入时告诉机器这是什么,通过输入是给定标签的数据,让机器自动找出输入与输出之间的关系。
其实现在我们看到的人工智能,大多数是监督学习。
监督学习优缺点:
- 优点:算法的难度较低,模型容易训练;
- 缺点:需要人工给大量的训练数据打上标签,因此就催生了数据标签师和数据训练师的岗位。
03 线性回归(Linear Regression)
我们前面举的预测房价的例子就是一个线性回归的问题,我们要找一条线去拟合这些测试数据,让误差最小。
如果我们要误差最小,即要每一个测试点到直线的距离之和最小。(具体步骤可以参考我们前面介绍的实现机器学习的三个步骤)。
但是在现实问题中,可能房价跟住房面值不是单纯的直线关系,当住房面积到一定大的时候,房价的增幅就会变缓了;或者说当数据量不够大时,我们得到的模型跟测试数据太拟合了,不够通用。
为了解决这些问题,我们就需要正则化,就是让模型更加的通用。
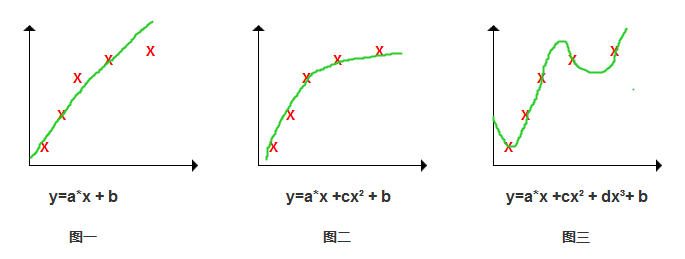
图一:如果我们按y=a*x+b这个模型去训练,那得到的就会像图一这样的曲线,而当住房面积比较大时,可能预测效果就不好了;
图二:我们加入了一个二次项,拟合效果就很不错了,输入新数据时,预测效果比较好,所以这就是比较好的模;
那这么说就是拟合程度越高越好?并不是,我们的目的不是在训练数据中找出最拟合的模型,而是找出当输入新数据时,预测效果最好的。因此,这个模型必须具体通用性。
图三:我们加入了更高的三次项,模型跟训练数据拟合度太高,但不具备通用性,当你输入新数据时,其实预测效果也不好。因此需要通过正则化后,找到比较理想的通用模型。
线性回归的特点:
- 主要解决连续值预测的问题;
- 输出的是数值。
04 逻辑回归(Logistic Regression)
逻辑回归输出的特点:
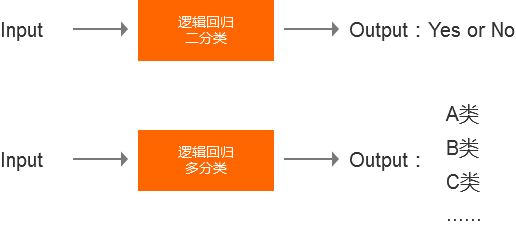
逻辑回归主要解决的是分类的问题,有二值分类和多分类。
1. 二分类
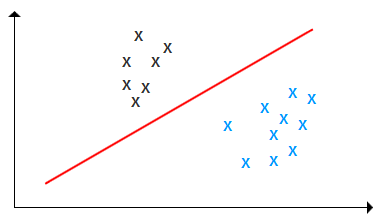
如上图,我们要做的事情就是找一条线,把黑色的点和蓝色的点分开,而不是找一条线去拟合这些点。
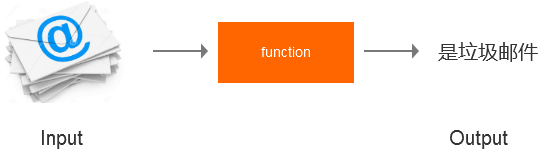
比如说做拦截垃圾邮件的模型,就把邮件分为垃圾邮件和非垃圾邮件两类。输入一封邮件,经过模型分析,若是垃圾邮件则拦截。
2. 多分类
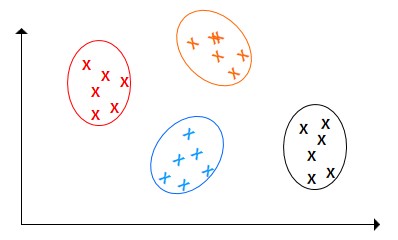
如上图,要做的是把不同颜色的点各自归为一类,其实这也是由二分类变换而成的。
比如说让机器阅读大量的文章,然后把文章分类。
线性回归与逻辑回归的举例说明,以预测天气为例:
- 如果要预测明天的温度,那就是线性回归问题;
- 如果要预测明天是否下雨,那就是二分类的逻辑回归问题;
- 如果要预测明天的风级(1级、2级、3级…),那就是多分类的逻辑回归问题。
05 神经网络(Neural Networks)
1. 为什么需要神经网络?
假设我们现在做的是房价是升还是降的分类问题,我们之前假设影响房价的因素只有住房面积,但是实际上可能还需要考虑楼层、建筑时间、地段、售卖时间、朝向、房间的数量等等,可能影响因素是成千上万的。并且各因素之间可能存在关联关系的。
如果用回归问题解,则设置函数:
y=(a1*X1 + a2*X2 + a3*X3 + a4*X4…)+=(b1*X1X2 + b2*X1*X3 + b3*X1X4 …)+(三次项的组合)+(n次项的组合)
普通回归模型:
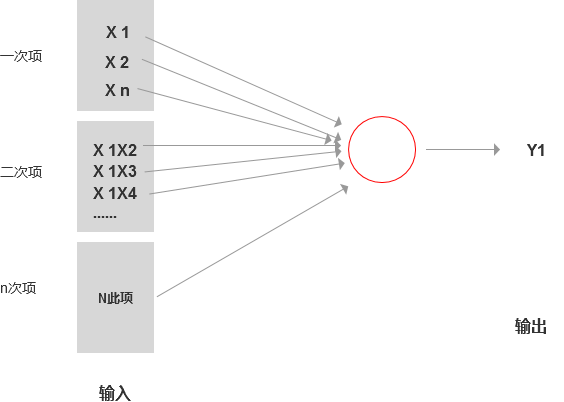
对于该模型来说,每个特征变量的之间的相互组合(二次项或三次项)都变成新的特征变量,那么每多一个高次项时,特征变量就会数量级的变大,当特征变量大于是数千个的时候,用回归算法就很慢了。而我们转换为神经网络去求解,就会简单得多。
神经网络模型:
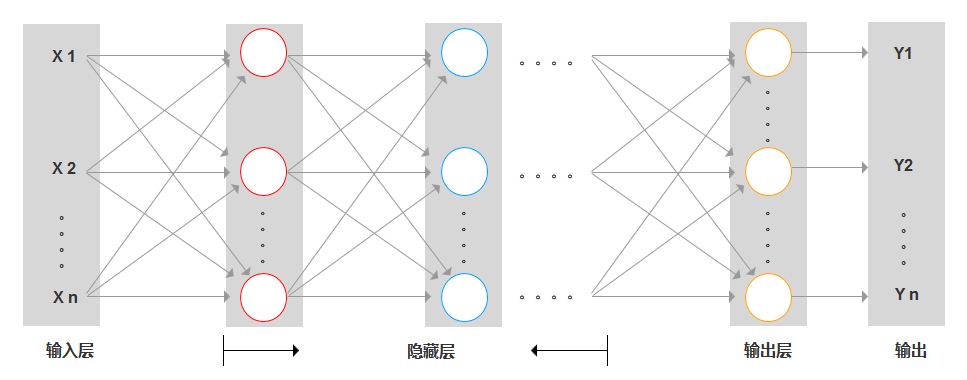
2. 为什么叫做神经网络?
先看下人类神经元的链接方式:
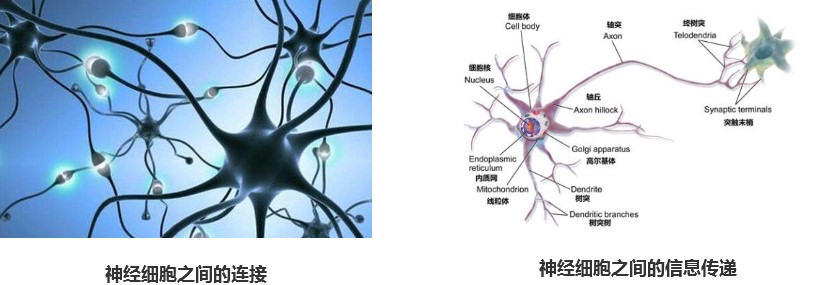
人的神经细胞连接是错综复杂的,一个神经元接受到多个神经元的信息,经过对信息处理后,再把信息传递给下一个神经元。
神经网络的设计灵感就是来源于神经细胞之间的信息传递,我们可以把神经网络中的每个圆圈看成是一个神经元,它接受上一级网络的输入,经过处理后,再把信息传递给下一级网络。
3. 为什么要模拟人类的神经网络?人类的神经网络有什么神奇的地方?
神经系统科学家做过一个有趣的实验,把一个动物的听觉皮层切下来,移植到另一个动物的大脑上,替换其视觉皮层,这样从眼睛收到的信号将传递给移植过来的听觉皮层,最后的结果表明这个移植过来的听觉皮层也学会了“看”。
还有很多有趣的实验:
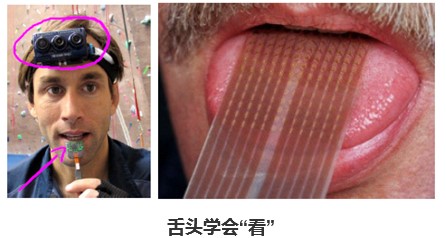
上图是用舌头学会“看”的一个例子,它能帮助失明人士看见事物。
它的原理是在前额上带一个灰度摄像头,摄像头能获取你面前事物的低分辨率的灰度图像。再连一根线到安装了电极阵列的舌头上,那么每个像素都被映射到你舌头的某个位置上。电压值高的点对应一个暗像素,电压值低的点对应于亮像素,这样舌头通过感受电压的高度来处理分辨率,从而学会了“看”。
因此,这说明了动物神经网络的学习能力有多惊人。也就是说你把感器的信号接入到大脑中,大脑的学习算法就能找出学习数据的方法并处理这些数据。
从某种意义上来说如果我们能找出大脑的学习算法,然后在计算机上执行大脑学习算法或与之相似的算法,这就是我们要机器模拟人的原因。
4. 神经网络跟深度学习之间有什么关系?
1)相同:
都采用了分层结构(输入层、隐藏层、输出层)的多层神经结构。
2)不同:
- 层数不同,通常层数比较高的我们叫做深度学习,但具体多少层算高,目前也没有有个统一的定义,有人说10层,有人说20层;
- 训练机制不同,本质上的区别还是训练机制的不同。
传统的神经网络采用的是back propagation的方式进行,这种机制对于7层以上的网络,残差传播到最前面就变得很小了,所谓的梯度扩散。
而深度学习采用的训练方法分两步,第一步是逐层训练,第二步是调优。
深度学习中,最出名的就是卷积神经网络(CNN)和循环神经网络(RNN)。
关于深度学习,在这里就不展开了,之后会单独写一篇文章讨论深度学习,感兴趣的同学可以关注下。
06 半监督学习(Semi-supervised Learning)
半监督学习主要特点是在训练数据中,有小部分数据是有标签,而大部分数据是无标签的。
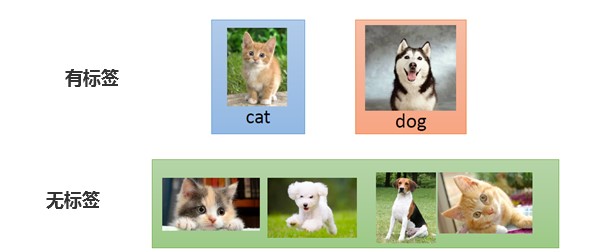
半监督学习更加像人的学习方式,就像小时候,妈妈告诉你这是鸡,这是鸭,这是狗,但她不能带你见过这个世界上所有的生物;下次见到天上飞的,你可能会猜这是一只鸟,虽然你不知道具体这只鸟叫什么名字。
其实我们不缺数据,缺的是有多样标签的数据。因为你要想数据很简单,就放一个摄像头不断拍,放一个录音机不断录,就有大量数据了。
简单说一个半监督学习的方式:
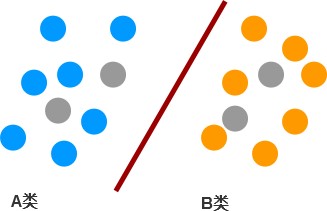
假设蓝色的和黄色的是有标签的两类数据,而灰色的是无标签的数据,那么我们先根据蓝色和黄色的数据划了分类,然后看灰色的数据在哪边,再给灰色的数据分别标上蓝色或黄色的标签。
所以半监督学习的一个重要思想就是:怎么用有标签的数据去帮助无标签的数据去打上标签。
07 无监督学习(Unsupervised Learning)
无监督学习的主要特点是训练数据是无标签的,需要通过大量的数据训练,让机器自主总结出这些数据的结构和特点。
就像一个不懂得欣赏画的人去看画展,看完之后,他可以凭感觉归纳出这是一类风格,另外的这些是另一种风格,但他不知道原来这是写实派,那些是印象派。
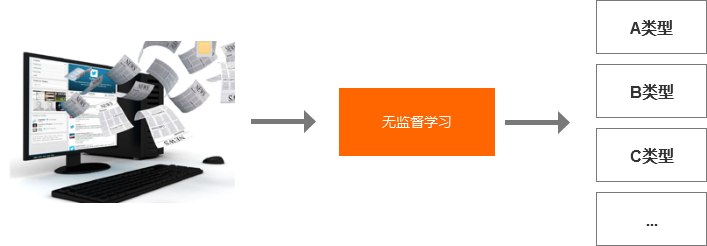
比如说给机器看大量的文章,机器就学会把文章分类,但他并不知道这个是经济类的、文学类的、军事类的等等,机器并不知道每一类是什么,它只知道把相似的归到一类。
无监督学习主要在解决分类和聚类问题方面的应用比较典型,比如说Googel和头条的内容分类。
08 强化学习(Reinforcement Learning)
先来聊聊强化学习跟监督学习有什么不同。

监督学习是每输入一个训练数据,就会告诉机器人结果。就像有老师手把手在教你,你每做一道题老师都会告诉你对错和原因。
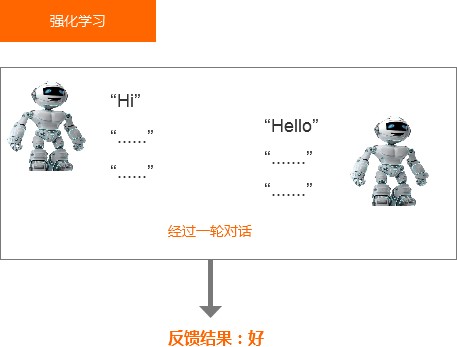
强化学习是进行完一轮对话之后,才会跟机器人说这一轮对话好还是坏,具体是语气不对,还是回答错误,还是声音太小,机器不知道,它只知道结果是不好的。就像你高考,没有老师在你身边告诉你每做的一道题是对或错吧,最终你只会得到一个结果:得了多少分。
强化学习模型:
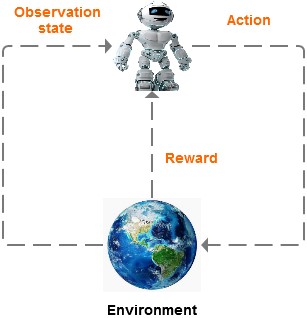
首先机器会观察它所处的环境,然后做出行动;机器的行动会改变环境;接着机器再次观察环境,再次做出行动,如此循环。
每一次训练结束,机器都会收到一个回馈,机器根据回馈,不断调整模型。
以Alpha Go为例:
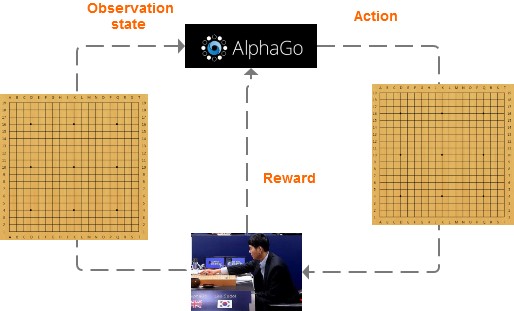
首先AlphaGo会观察棋盘的情况,然后决定下一步落子;待对方落子后,AlphaGo再次根据棋盘的情况再次进行下一步。直到分出胜负之后,AlphaGo得到的reward是赢或输。经过这样大量的训练之后,AlphaGo就学会了,怎样做才更有可能赢。
强化训练的特点:
- 反馈机制,根据反馈不断调整自己的策略;
- 反馈有延迟,不是每次动作都会得到反馈;比如说AlphaGo,不是每一次落子都会有反馈,而是下完一整盘才得到胜负的反馈。
在此就介绍完了机器学习常见的内容,若文中有不恰当的地方,欢迎各路大神批评指正。
本文由 @Jimmy 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自Unsplash,基于CC0协议。









题主辛苦了,你的这几篇文章都看了,写得确实很通俗;
介绍的很好啊,我刚做数据标签几天,也是刚入这行,你说的这些我大概都能理解,就是具体数据上理解还有有些困难。但是看了让我对这行有了更深入的了解,很感谢,希望我以后能在这行有所发展吧。
你是自学的么
嗯嗯,最近忙,好久没来这里逛了